






学习内容:B站 刘二大人 《pytorch深度学习实践》课程系列
问题引入:之前我们的梯度是根据公式求导得到的,但是实际神经网络中,每两层之间都有权重,而且权重的数量不再是一个w,所以我们需要一种方法来自动求Loss对w的导数。我们根据链式求导法则,从后往前求Loss对w导数的过程,称为“反向传播”。
反向传播
原理:将神经网络看作是一个计算图,在图上传播梯度,最后根据链式法则求得:Loss对w得导数。
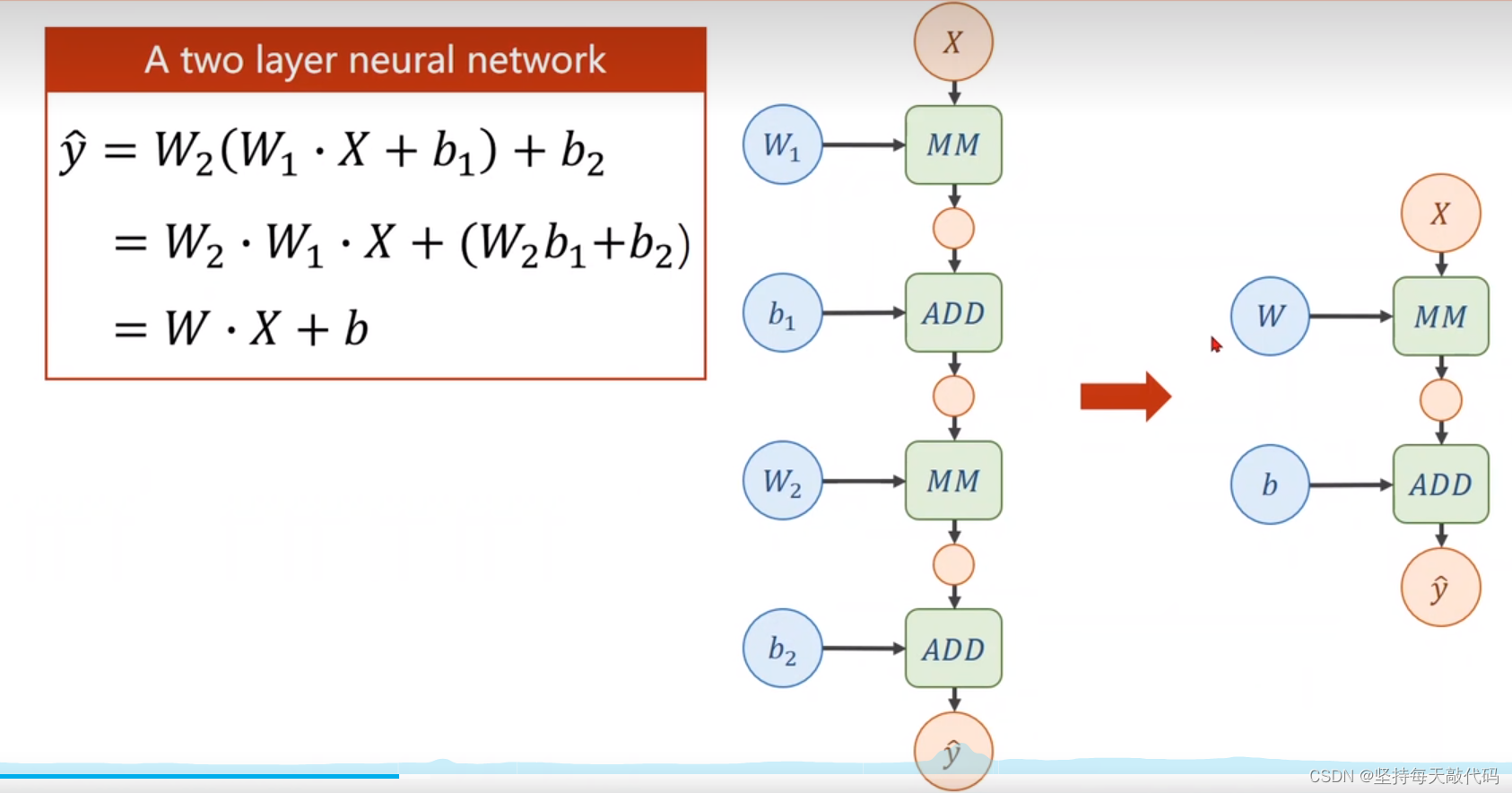
嵌套多层线性变换,不论嵌套多少层,都相当于一个线性变换,没有任何意义。所以我们在每个线性变化之后都做一个非线性变换。具体来说就是对线性函数输出的向量中每一个值都应用一个非线性函数,比如sigmoid函数
Forward与Backward
Forward:就是从输出到输出计算y_hat、loss的过程
Backward:就是从后往前求梯度,最后求出 loss对w的导数,然后就能用这个做更新。
原理过程:
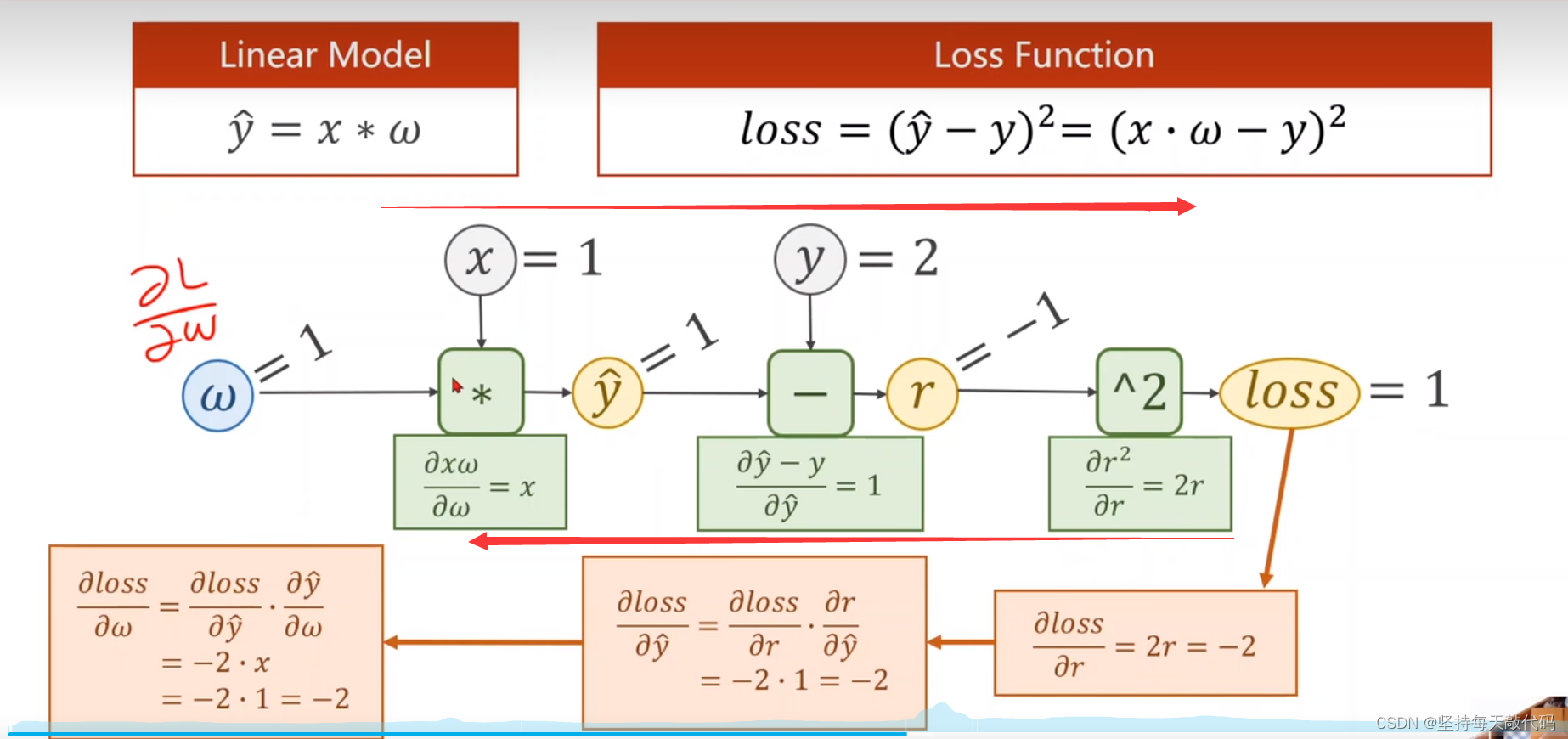
在Pytorch中如何使用backward
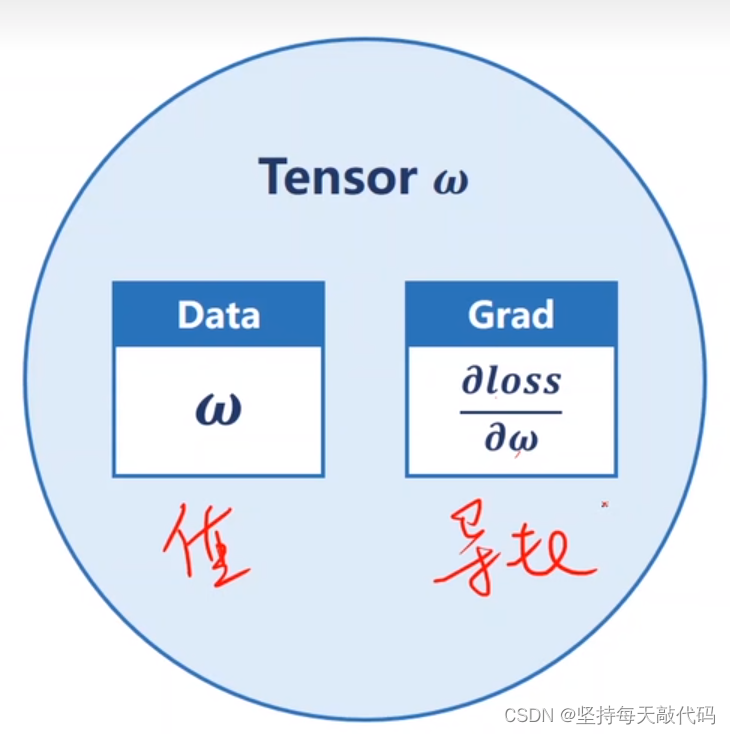
张量w:包含两个:本身数值w.data,该张量的梯度w.grad(tensor)。可以使用w.grad.data来更新w,防止产生计算图。如果张量只有一个值,可以使用w.grad.item()转化为python中的标量,总结:张量不要轻易做计算,否则会产生计算图。
代码:
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.Tensor([1.0])
w.requires_grad = True #需要计算梯度,在计算图前馈过程中能够保留w的梯度
#构建计算图
def forward(x):
return x*w #这里x会自动类型转化为tensor
def loss(x,y):
return (forward(x) - y)**2
print('Predict before training:',4,forward(4).item())
for epoch in range(100):
for x,y in zip(x_data, y_data):
l = loss(x,y)
l.backward()
print('\tgrad:',x,y,w.grad.item())
w.data = w.data - 0.01* w.grad.data
w.grad.data.zero_()
print("epoch:",epoch,l.item())
print('Predict after training:',4,forward(4).item())记住:
- 每次调用loss函数的时候,就会构建如图所示的计算图。
- 每次调用loss.backward()就会计算loss路径上所有的梯度,并且释放计算图,下次计算loss的时候会创建新的计算图。
- 每次需要对w.grad进行清零,因为下次在计算w的梯度,会加在原有的梯度上,这样梯度就不准确了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









