







第十二周:深度学习基础
摘要
本文首先阐述了多头注意力(Multi-Head Attention)的基本原理和计算方法,然后探讨了自注意力(Self-Attention)机制在多种任务中的应用,并与传统的神经网络结构——卷积神经网络(CNN)和循环神经网络(RNN)进行了比较。此外,文章还通过一个具体的案例——爬取微博评论,详细说明了网络爬虫的基本步骤和实施过程。
Abstract
This article first elucidates the fundamental principles and computational methods of Multi-Head Attention, followed by an exploration of the applications of Self-Attention mechanisms across various tasks. It also provides a comparative analysis with traditional neural network architectures, namely Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). Furthermore, the article delves into the basic steps and implementation process of web scraping through a specific case study—harvesting comments from Weibo.
1. 多头注意力机制
上周已经学习了基础的自注意力机制,并分析了其计算方法。现在以双头注意力对注意力机制的进阶版本——多头注意力机制进行学习。
多头注意力机制的使用很广泛。针对不同的任务,其需要多少头的注意力,这是一个超参数,需要在实际任务中进行比较、调整。
1.1多头注意力的计算
注意力的“头”可以理解为关系的种类和形式,可能输入间的相关性有多种,所以需要多个“头”来表述其不同的相关性。
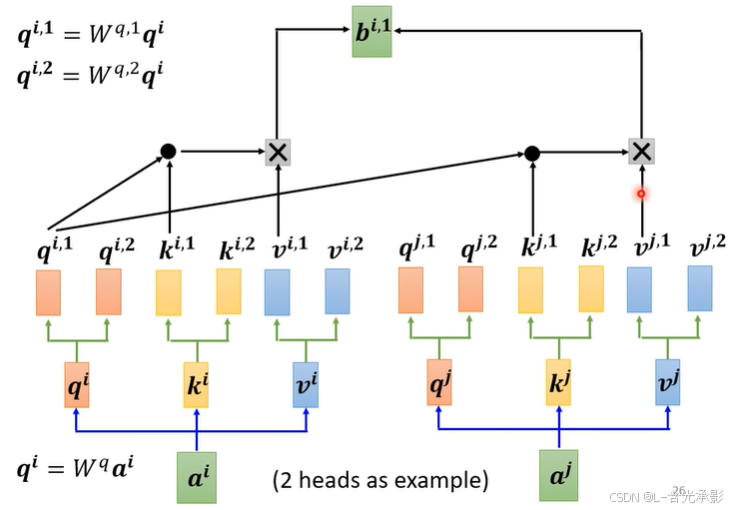
“多头”对应多个 q,k,v ,在计算时,每组的 q,k,v 单独计算,如上图中的 b i , 1 b^{i,1} bi,1 就是用第一组的 q,k,v 计算得到的,类似的, b i , 2 b^{i,2} bi,2 的计算如下:
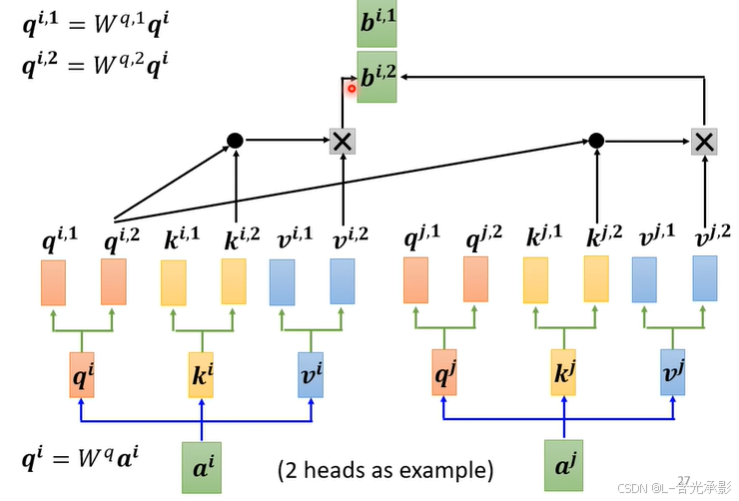
“多头”的计算其实就是在普通注意力的计算中,多计算几组。

将不同“头”得出的输出结果乘上一个矩阵,得到最终的输出结果。
1.2 位置信息
目前所学的自注意力层,都没有考虑到输入的位置信息。但对于某些任务中,位置信息也是值得考虑的,如词性标注任务中,动词很少会出现在句首。所以对于某些任务,需要加入位置信息。
位置信息的加入需要转化成位置编码。将位置编码加上输入作为自注意力层的输入。
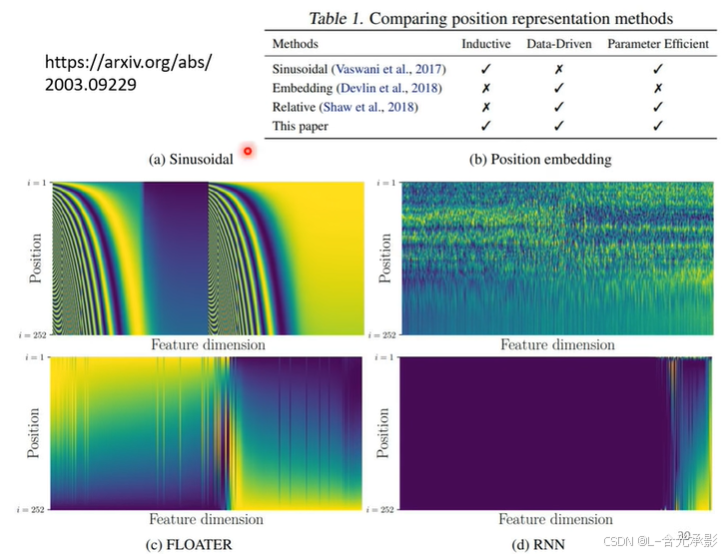
位置编码可以是人为设置的,也可以根据数据学习得来,下面是一篇论文中对几种位置编码方式的对比。
1.3 自注意力机制在语音识别上的应用

对于语音识别任务,其使用自注意力机制的一个问题就是输入太多庞大,导致其注意力矩阵也相当庞大,计算量非常大,且需要较大的存储空间存放注意力矩阵。对于这个问题,解决办法是不考虑整个输入序列,只考虑固定长度的附近序列,这样的话就可以减少注意力矩阵的尺寸,减少计算量。这种注意力方法是 Truncated Self-attention .
1.4 自注意力机制在图像上的应用
自注意力机制的输入是一系列向量,对于图像,每个像素点的不同通道可以看作是一个向量,向量长度为通道数,向量个数就是图像的长*宽。如此,图像也可以表示成一系列的向量,在输入形式上满足了自注意力机制的条件。
下面对比一下图像任务上,CNN和自注意力机制的关系。

CNN在的卷积计算是考虑了感受野(receptive field)的信息,而自注意力机制可以考虑所有的信息,所以说在图像任务上,CNN是自注意力机制的简化,自注意力可以看作是感受野可以学习的CNN,是CNN的复杂版本。CNN是自注意力机制的特例,自注意力只要设置合适的参数,就可做到与CNN一样的效果。

CNN的模型是自注意力模型的简化,在小的数据量上,自注意力比CNN更易过拟合,因为CNN模型的复杂度较小。下面是一篇论文中在不同的训练数据量上对二者的比较:

在训练数据较少时,CNN的效果优于自注意力,随着训练数据量的增加,自注意力的效果要优于CNN,这是因为自注意力的复杂性较高,在训练数据量较大时,其模型的效果较好。
1.5 自注意力与RNN
自注意力可以同时考虑输入序列中所有的信息,而单向RNN只能考虑序列中时间步前面的信息,双向RNN虽然也可以考虑整个序列,但其信息是通过时间步一步步传递到的,可能有丢失,而自注意力对输入序列的所有信息“同时”考虑。另外一个主要区别是,RNN对输入序列的每个时间步的预测是有先后顺序的,是一步步来的,不能并行产生输出,而自注意力机制是并行产生输出的。

1.6 自注意力在图上的应用
图由节点和边组成

在图结构中,可以用节点来和边来构造注意力矩阵,其中,节点间没有边的attention score直接设为0,不需要训练,节点间有边的 attention score 是需要训练的。如此,可以构成一种图神经网络(Graph Neural Network,GNN).
自注意力的变形
因为self-attention最早是用在transformer上,所以广义的 transformer 指的就是 self-attention。自注意力机制的运算量很大,所以有很多变形。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









