







目录
摘要
本文详细介绍了负采样技术的具体实施方法,并与上周讨论的Skip-Gram模型进行了计算效率的对比分析,从而突出了负采样在计算效率方面的优势。此外,文章还深入解释了Sigmoid函数和Softmax函数,并探讨了它们在不同应用场景下的差异。最后,本文介绍了一个简单的循环神经网络(RNN)分类任务案例,并阐述了其实现流程和关键步骤。
Abstract
This article provides a detailed introduction to the specific implementation methods of negative sampling and conducts a comparative analysis of computational efficiency with the Skip-Gram model discussed last week, thereby highlighting the advantages of negative sampling in terms of computational efficiency. In addition, the article offers an in-depth explanation of the Sigmoid and Softmax functions and explores their differences in various application scenarios. Finally, the paper introduces a simple case of a recurrent neural network (RNN) classification task and elaborates on its implementation process and key steps.
1. 负采样
上周学习到 Skip-Gram模型的计算上,softmax 由于需要求指数和累和,会导致计算非常缓慢,负采样就是解决这个问题的一个方法。
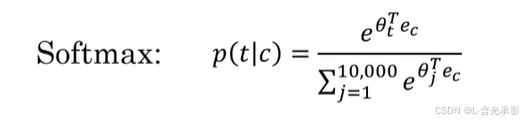
负采样(Negative Sampling)是一种训练技术,主要用于处理分类问题,特别是在二分类问题中。它的核心思想是从所有可能的负样本(即非正类的样本)中选择一个小的负样本子集,以便在训练过程中提高计算效率并减少内存消耗。
在负采样中需要构造一个新的监督学习问题,简单来说就是给定一对词,比如orange和juice,我们要去预测这是否是一对上下文词-目标词(context-target) 。
在这个算法中,首先需要选一个上下文词,并在窗口内选取一个目标词,然后用相同的上下文词和词典中随机选取的单词(不管随机选取的单词是否在上下文词的窗口之内)组成的单词对作为负样本,正样本就是单词对是上下文词-目标词,而负样本说明单词对不是上下文词-目标词。
举个例子,假设在句子“I want a gass of orange juice to go along with my cereal” 中,选取的上下文词-目标词为orange-juice,这对单词就是正样本,则在训练数据中这对单词的标签为‘1’,然后在词典中随机选取 k 个单词与目标词orange搭配作为负样本,每对单词的标签为‘0’。注意,其中of出现在orange的前面,但是这对单词也是负样本。

接下来需要构造一个新的监督学习问题,输入为 context-word ,输出为target,即判断输入的一对词是不是上下文词-目标词,输出结果为0或1,监督学习的任务就是学习输入到输出的映射。
对于k的选取,小数据集一般取k为5-20,对于大数据集,k的取值小一些更合适,一般取2-5,这并没有理论上的解释,是算法的作者通过实验得出的。
学习从输入x映射到输出y的监督学习模型如下:
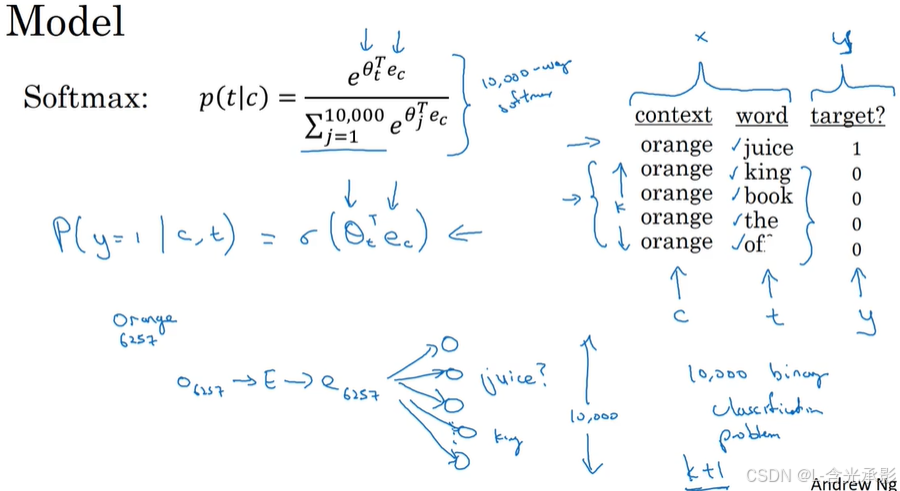
为了定义模型,使用记号 表示上下文词,记号
表示可能的目标词,用取值为0或1的
来表示是否是一对上下文-目标词。现在要做的就是定义一个逻辑回归模型,给定输入的
,
对的条件下,
的概率,其计算方法为:
这个模型基于逻辑回归模型,但不同的是使用 Sigmoid 函数,参数和之前的softmax计算中是一样的。对每一个可能的目标词有一个参数向量 和另一个参数向量
,即每一个可能上下文词的嵌入向量。
将模型表示成网络,如上图中输入orange的嵌入向量可以得到10,000个可能的逻辑回归分类问题,这些分类器就是用来判断orange的目标词是否可能是某单词,比如其中一个分类器就是判断juice是否是orange的目标词。但并不是每次迭代都是训练全部的分类器,对于每个上下文词,会训练其中的k=1个分类器,就是一个正样本和k个负样本对应的分类器。这样就极大地降低了运算量。选取并利用负样本来训练模型是算法的精髓所在,这就是算法为什么叫负采样的原因。
对于如何选取负样本,有两种极端的方法,一种是按语料中的词频来采样,但问题是这会导致在like、the、of、and等意义不大的词上有很高的频率。另一种极端的方法就是在词典中均匀且随机地抽取负样本,这对于英文单词的分布是非常没有代表性的。算法的提出者根据经验提出,既不用经验频率,也就是实际观察到的英文文本的分布,也不用均匀分布,采用以下方式:
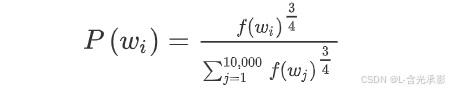
进行采样,其中 是单词
在语料中的词频,通过
次方的计算,使其处于完全独立的分布和训练集的观测分布两个极端之间。 这也是很多研究者用的方法。
2. sigmoid函数和softmax函数对比
sigmoid函数和softmax函数都是激活函数,也都可以用在分类任务中,但是二者在使用上是有差别的。
2.1 sigmoid函数
Sig
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









