




 该博客讨论了两个计算机科学相关的问题:一是实现图书信息管理系统的A*搜索算法解决九宫重排问题,二是通过线性表和二叉排序树实现低频词过滤系统并比较效率。实验内容包括输入英文文章,统计单词频率,删除低频词,输出结果,并计算平均查找长度。此外,还提供了两种方法的详细代码实现,以及菜单驱动的用户交互界面。
该博客讨论了两个计算机科学相关的问题:一是实现图书信息管理系统的A*搜索算法解决九宫重排问题,二是通过线性表和二叉排序树实现低频词过滤系统并比较效率。实验内容包括输入英文文章,统计单词频率,删除低频词,输出结果,并计算平均查找长度。此外,还提供了两种方法的详细代码实现,以及菜单驱动的用户交互界面。
实验一 图书信息管理系统的设计与实现
(一)实验内容
设计并实现一个图书信息管理系统。根据实验要求设计该系统的菜单和交互逻辑,并编码实现增删改查的各项功能。 该系统至少包含以下功能:
根据指定图书个数,逐个输入图书信息;
逐个显示图书表中所有图书的相关信息;
能根据指定的待入库的新图书的位置和信息,将新图书插入到图书表中指定的位置;
根据指定的待出库的旧图书的位置,将该图书从图书表中删除;
能统计表中图书个数;
实现图书信息表的图书去重;
实现最爱书籍查询;
图书信息表按指定条件进行批量修改;
利用快速排序按照图书价格降序排序;
实现最贵图书的查找;
(二)实验设计过程
本实验的图书信息定义三个方面的内容,采用结构体设计如下:
//图书信息的定义:
typedef struct {
char no[8]; //8位书号
char name[20]; //书名
float price; //价格
}Book;
本实验采用带头尾指针的单链表来储存图书信息,链表的结构体定义如下:
//链表的定义:
typedef struct LNode{
Book data; //数据域
struct LNode *next; //指针域
}LNode,*LinkList;
功能一和三、根据指定图书个数,逐个输入图书信息及指定位置插入图书
步骤:新建一个结点,存储图书的相关信息,未指定位置默认加在链表后面
//(1)读入相应的图书数据来完成图书信息表的创建,在尾结点插入图书信息
void BookLinkList:: Creat()
{
bool flag=true;
//新建一个结点,储存新插入的图书的信息
LNode *p;
p=new LNode;
while(flag)
{
cin>>p->data.no;
if(strcmp(p->data.no,“0 0 0”))
{
flag=false;
}
else
{
cin>>p->data.name;
cin>>p->data.price;
p->next=NULL;
//将新建的结点插入链表中
rear->next=p;
//更新尾指针
rear=p;
length++;
sum+=p->data.price;
average=sum/length;
}
}
}
功能三实现:指定位置插入代码
//(3)在指定位置插入图书信息
void BookLinkList:: Location_Index()
{
int location;
cin>>location;
if(location<=0 || location>length)
{
cout<<“抱歉,入库位置非法!\n”;
}
else
{
//新建一个结点,储存新插入的图书的信息
LNode *p;
p=new LNode;
cin>>p->data.no;
cin>>p->data.name;
cin>>p->data.price;
int cout=location-1;
LNode *s;
s=head;
//将新建的结点插入指定位置
while(cout>0)
{
s=s->next;
cout--;
}
LNode *q=s->next;
//将新结点插入
s->next=p;
p->next=q;
length++;
}
}
功能二、逐个显示图书表中所有图书的相关信息;
//(2)逐个显示图书表中所有图书的相关信息
void BookLinkList::OutPut()
{
cout<<"**************************************************"<<’\n’;
cout<<“图书表中的图书个数:”<<length<<’\n’;
LNode *p;
p=head->next;
cout<<fixed<<setprecision(2);//保留小数点后两位
while(p != NULL)
{
cout<<p->data.no<<" ";
cout<<p->data.name<<" ";
cout<<p->data.price<<endl;
p=p->next;
}
}
功能四、根据指定的待出库的旧图书的位置,将该图书从图书表中删除;
//(4)将图书从图书表中删除
void BookLinkList::Delete()
{
cout<<“输入要删除的图书在图书表中的位置:”;
int location;
cin>>location;
if(location<=0 || location>length)
{
cout<<“出库失败,未找到此书\n”;
}
else
{
LNode *p;
LNode *q=head;//遍历链表找到删除结点的位置
int i=1;
while(i<location)
{
q=q->next;
i++;
}
p=q->next;//找到位置
q->next=p->next;
delete p;
length–;
}
}
功能六、实现图书信息表的图书去重;
使用两个指针变量遍历链表,删除书号相同的图书,保留第一个
具体代码实现如下:
//(6)实现图书信息表的图书去重
void BookLinkList::Remove()
{
LNode *p=head->next;
LNode *q=p;
while (p != rear)
{
q=p;
while(q != NULL)
{
if(strcmp(p->data.no,q->next->data.no) == 0)
{
LNode *s=q->next;
q->next=s->next;
length–;
delete s;
if(q->next == NULL)
{
rear=q;
break;
}
}
q=q->next;
}
p=p->next;
}
return;
}
功能七和十、实现最爱书籍查询及最贵图书查找;
原本实验要求折半查找,但是折半查找还需将链表排序,所以直接采用遍历单链表的方式更为方便时间复杂度O(n)
具体代码如下:
//(7)实现最爱书籍查询
void BookLinkList::SearchFavourite()
{
LNode *q=head->next;
int count=0;//统计有多少最爱图书数目
char favourite[20]; //书名
cin>>favourite;
//遍历链表找最喜爱的书
while(q != NULL)
{
if(favourite == q->data.name)
{
count++;
cout<<q->data.no<<" ";
cout<<q->data.name<<" ";
cout<<q->data.price<<endl;
}
q=q->next;
}
if(count == 0)
{
cout<<"抱歉,没有你的最爱!";
}
}
最贵图书可能不止一本,想过采用保存最贵图书的结点,最后输出,可是由于最贵图书可能不止一本就比较麻烦,还是采用遍历单链表直接找出最贵的价格,然后遍历链表直接输出与最高价格相同的图书
//(10)实现最贵图书的查找
void BookLinkList::SearchMExpensive()
{
LNode *q=head->next;
int count=0;//统计最贵书的数量
int mexpensive=q->data.price;
//遍历链表找最大数
while(q != NULL)
{
q=q->next;
if(mexpensive<q->data.price)
{
mexpensive=q->data.price;
}
}
q=head->next;
//遍历链表输出最贵的图书
while(q != NULL)
{
if(mexpensive == q->data.price)
{
count++;
cout<<q->data.no<<" ";
cout<<q->data.name<<" ";
cout<<q->data.price<<endl;
}
q=q->next;
}
}
功能八、图书信息表按指定条件进行批量修改;
输入所有要改价格的图书进行批量修改,然后输出修改价格后的图书信息
//(8)图书信息表按指定条件进行批量修改
void BookLinkList::Change()
{
LNode *p=head->next;
//循环链表中所有图书,修改价格
while(p != NULL)
{
if(p->data.price<average)
{
p->data.price=p->data.price*1.2;//将所有低于平均价格的图书价格提高20%
sum+=p->data.price*0.2;
average=sum/length;
}
else
{
p->data.price=p->data.price*1.1;//所有高于或等于平均价格的图书价格提高10%
sum+=p->data.price*0.1;
average=sum/length;
}
p=p->next;
}
//输出修改价格后的图书表
LNode *s;
s=head->next;
cout<<fixed<<setprecision(2);
while(s != NULL)
{
cout<<s->data.no<<" ";
cout<<s->data.name<<" ";
cout<<s->data.price<<endl;
s=s->next;
}
}
功能九、利用快速排序按照图书价格降序排序;
由于单链表不支持下标访问,所以采用快排的基本思想稍稍修改的思路。
以单链表中第一个元素为基准进行排序,使用i,j对链表进行遍历。如果链表只有两个数直接排序交换,如果多个数,则将小于key的数放在i与j之间。再对key左右的元素进行左右递归。无序时的时间复杂度为O(nlogn),有序时的时间复杂度下降到O(n^2)。
第一次找位置的时候对 i 不进行i=i->next的操作,为了后面便于找到第一次快排后左子链的尾结点。流程如图所示:
具体代码实现如下:
//基于快排思想稍稍修改的排序
void BookLinkList::Quicksort(LinkList shead, LinkList srear)
{
int jlocation=0;
int ilocation=0;
LinkList key=shead;
LinkList i;
i=key;
LinkList j=i;
//如果只有两个数,直接交换,提前结束
if(shead->next == srear)
{
j=j->next;
if(j->data.price>i->data.price)
{
swap(j->data.no,i->data.no);
swap(j->data.name,i->data.name);
swap(j->data.price,i->data.price);
}
return;
}
//若多个数采用快排,两个指针遍历
while(j !=srear)
{
if(j==shead && j->next->data.price>key->data.price)
{
//如果j下一个数比key的值大,则交换,确保i与j之间的数比key小
swap(j->next->data.no,i->next->data.no);
swap(j->next->data.name,i->next->data.name);
swap(j->next->data.price,i->next->data.price);
}
else if(j->next->data.price>key->data.price)
{
//如果j下一个数比key的值大,则交换,确保i与j之间的数比key小
i=i->next;
ilocation++;
swap(j->next->data.no,i->next->data.no);
swap(j->next->data.name,i->next->data.name);
swap(j->next->data.price,i->next->data.price);
}
j=j->next;
jlocation++;
}
swap(key->data.no,i->next->data.no);
swap(key->data.name,i->next->data.name);
swap(key->data.price,i->next->data.price);
//对右边子链递归
if(jlocation-ilocation>1)
Quicksort(i->next->next,j);
//对左边子链进行递归
if(ilocation>0)
Quicksort(shead,i);
}
//(9)利用快速排序按照图书价格降序排序
void BookLinkList::Sort()
{
if(length == 0 && length == 1)
{
return;
}
Quicksort(head->next,rear);
return;
}
(三)实验完整代码
booklinklist.h头文件
#pragma once
#ifndef BOOKINFORMATION_H
#define BOOKINFORMATION_H
#include
#include
#include
using namespace std;
//图书信息的定义:
typedef struct {
char no[8]; //8位书号
char name[20]; //书名
float price; //价格
}Book;
//链表的定义:
typedef struct LNode {
Book data; //数据域
struct LNode* next; //指针域
}LNode, * LinkList;
//基于链式存储结构的图书信息表
class BookLinkList
{
public://声明
BookLinkList();//建立一个带头结点的单链表
void Creat();//读入相应的图书数据来完成图书信息表的创建
void Location_Index();//指定位置插入图书信息
void OutPut();//输出信息
void Delete();//将图书从图书表中删除
void GetLength();//得到图书表中图书的个数
void Remove();//图书信息表的图书去重
void SearchFavourite();//实现最爱书籍查询,根据书名进行折半查找
void Change();//图书信息表的修改
void Sort();//利用快速排序按照图书价格降序排序
void Quicksort(LinkList shead, LinkList srear);//快排关键代码
void SearchMExpensive();//实现最贵图书的查找
~BookLinkList();//释放所有结点
private:
LNode* head;//头指针
LNode* rear;//尾指针
int length;
float sum;//计算总价格
float average;//计算平均价格;
};
#endif // BOOKINFORMATION_H
booklinklist.cpp文件
#include “booklinklist.h”
//建立一个带头结点的单链表
BookLinkList::BookLinkList()
{
length = 0;
sum = 0;
average = 0;
head = new LNode;
rear = head;
rear->next = NULL;
}
//(1)读入相应的图书数据来完成图书信息表的创建,在尾结点插入图书信息
void BookLinkList::Creat()
{
cout << "若想要结束,则输入:";
cout << "0 0 0\n";
while (true)
{
//新建一个结点,储存新插入的图书的信息
LNode* p;
p = new LNode;
cout << "请输入书本号:";
cin >> p->data.no;
cout << "请输入书本名:";
cin >> p->data.name;
cout << "请输入书本价格:";
cin >> p->data.price;
p->next = NULL;//指向空
if (!strcmp(p->data.no, "0") && !strcmp(p->data.name, "0") && p->data.price == 0)
{
return;//规范
}
else
{
//将新建的结点插入链表中
rear->next = p;
//更新尾指针
rear = p;
length++;//链表长度加一
sum += p->data.price;//总价格
average = sum / length;//计算平均
}
}
}
//(2)逐个显示图书表中所有图书的相关信息
void BookLinkList::OutPut()
{
cout << “**************************************************” << ‘\n’;
cout << “图书表中的图书个数:” << length << ‘\n’;
LinkList p;
p = head->next;//头指针的下一个
cout << fixed << setprecision(2);//保留小数点后两位
while (p != NULL)
{
cout <<"书号为:"<< p->data.no << " 书名为: 《" << p->data.name
<< "》 价格为: " << p->data.price << endl;//输出自己的信息
p = p->next;//下一个
}
cout << '\n';
}
//(3)在指定位置插入图书信息
void BookLinkList::Location_Index()
{
int location;//位置
cout << "请输入你要插入的位置:" << endl;
cin >> location;
if (location <= 0 || location > length)//判断位置是否合理
{
cout << "抱歉,入库位置非法!\n";
}
else
{
//新建一个结点,储存新插入的图书的信息
LNode* p;
p = new LNode;//结点
cout << "请输入书本号:";
cin >> p->data.no;
cout << "请输入书本名:";
cin >> p->data.name;
cout << "请输入书本价格:";
cin >> p->data.price;
int cout = location - 1;//次数
LNode* s;
s = head;//头指针
//将新建的结点插入指定位置
while (cout > 0)
{
s = s->next;
cout--;
}
LNode* q = s->next;
//将新结点插入
s->next = p;
p->next = q;
length++;
}
cout << '\n';
}
//(4)将图书从图书表中删除
void BookLinkList::Delete()
{
cout << “输入要删除的图书在图书表中的位置:”;
int location;//位置
cin >> location;
if (location <= 0 || location > length)//判断位置是否合理
{
cout << “出库失败,未找到此书\n”;
}
else
{
LNode* p;
LNode* q = head;//遍历链表找到删除结点的位置
int i = 1;
while (i < location)
{
q = q->next;//指针移位
i++;
}
p = q->next;//找到位置
q->next = p->next;
length–;//长度减一
sum -= p->data.price;
average = sum / length;
delete p;
}
}
//(5)得到图书表中图书的个数
void BookLinkList::GetLength()
{
cout << “图书个数为:” << length << ‘\n’;//链表长度
}
//(6)实现图书信息表的图书去重
void BookLinkList::Remove()
{
LNode* p = head->next;
LNode* q = p;
while (p != rear)
{
q = p;
while (q != NULL)
{
if (strcmp(p->data.no, q->next->data.no) == 0)
{
LNode* s = q->next;
q->next = s->next;
length–;
delete s;
if (q->next == NULL)
{
rear = q;
break;
}
}
q = q->next;
}
if(p->next!=NULL) //否则p指针会指向NULL
p = p->next;
}
return;
}
//(7)实现最爱书籍查询
void BookLinkList::SearchFavourite()
{
LNode* q = head->next;
int count = 0;//统计有多少最爱图书数目
char favourite[20]; //书名
cout << “输入最喜爱的书的书名:”;
cin >> favourite;
//遍历链表找最喜爱的书
while (q != NULL)
{
if (strcmp(favourite, q->data.name) == 0)//
{
count++;
cout << q->data.no << " ";
cout << q->data.name << " ";
cout << q->data.price << endl;
}
q = q->next;
}
if (count == 0)
{
cout << "抱歉,没有你的最爱!";
}
}
//(8)图书信息表按指定条件进行批量修改
void BookLinkList::Change()
{
LNode* p = head->next;
//循环链表中所有图书,修改价格
while (p != NULL)
{
if (p->data.price < average)
{
p->data.price = p->data.price * 1.2;//将所有低于平均价格的图书价格提高20%
sum += p->data.price * 0.2;
average = sum / length;
}
else
{
p->data.price = p->data.price * 1.1;//所有高于或等于平均价格的图书价格提高10%
sum += p->data.price * 0.1;
average = sum / length;
}
p = p->next;
}
//输出修改价格后的图书表
LNode* s;
s = head->next;
cout << fixed << setprecision(2);
while (s != NULL)//遍历 不为空则输出
{
cout << s->data.no << " ";
cout << s->data.name << " ";
cout << s->data.price << endl;
s = s->next;
}
}
//基于快排思想稍稍修改的排序
void BookLinkList::Quicksort(LinkList shead, LinkList srear)
{
int jlocation = 0;
int ilocation = 0;
LinkList key = shead;
LinkList i;
i = key;
LinkList j = i;
//如果只有两个数,直接交换,提前结束
if (shead->next == srear)
{
j = j->next;
if (j->data.price > i->data.price)
{
swap(j->data.no, i->data.no);
swap(j->data.name, i->data.name);
swap(j->data.price, i->data.price);
}
return;
}
//若多个数采用快排,两个指针遍历
while (j != srear)
{
if (j == shead && j->next->data.price > key->data.price)//价格的判断比较
{
//如果j下一个数比key的值大,则交换,确保i与j之间的数比key小
swap(j->next->data.no, i->next->data.no);
swap(j->next->data.name, i->next->data.name);
swap(j->next->data.price, i->next->data.price);
}
else if (j->next->data.price > key->data.price)
{
//如果j下一个数比key的值大,则交换,确保i与j之间的数比key小
i = i->next;
ilocation++;
swap(j->next->data.no, i->next->data.no);
swap(j->next->data.name, i->next->data.name);
swap(j->next->data.price, i->next->data.price);
}
j = j->next;
jlocation++;
}
swap(key->data.no, i->next->data.no);
swap(key->data.name, i->next->data.name);
swap(key->data.price, i->next->data.price);
//对右边子链递归
if (jlocation - ilocation > 1)
Quicksort(i->next->next, j);
//对左边子链进行递归
if (ilocation > 0)
Quicksort(shead, i);
}
//(9)利用快速排序按照图书价格降序排序
void BookLinkList::Sort()
{
if (length == 0 && length == 1)
{
return;
}
Quicksort(head->next, rear);
return;
}
//(10)实现最贵图书的查找
void BookLinkList::SearchMExpensive()
{
LNode* q = head->next;
int count = 0;//统计最贵书的数量
int mexpensive = q->data.price;
//遍历链表找最大数
while (q != NULL)
{
q = q->next;
if (mexpensive < q->data.price)
{
mexpensive = q->data.price;
}
}
q = head->next;
//遍历链表输出最贵的图书
while (q != NULL)
{
if (mexpensive == q->data.price)
{
count++;
cout << q->data.no << " ";
cout << q->data.name << " ";
cout << q->data.price << endl;
}
q = q->next;
}
}
//(11)释放所有结点
BookLinkList::~BookLinkList()
{
LNode* p;
LNode* q = head;
while (length != 0)
{
while (q->next != rear)
{
q = q->next;
}
p = q->next;
rear = q;// 尾指针等于头指针
delete p;
length–;
}
}
main.cpp代码
#include “booklinklist.h”
int main()
{
int number = 0;
bool flag = true;
BookLinkList book;
cout <<" ------------------ 图书管理系统-------------------" << endl;
cout << “该图书信息管理系统包含如下功能:\n”;
cout << “1 根据指定图书个数,逐个输入图书信息;\n”;
cout << “2 逐个显示图书表中所有图书的相关信息;\n”;
cout << “3 能根据指定的待入库的新图书的位置和信息,将新图书插入到图书表中指定的位置;\n”;
cout << “4 根据指定的待出库的旧图书的位置,将该图书从图书表中删除;\n”;
cout << “5 能统计表中图书个数;\n”;
cout << “6 实现图书信息表的图书去重;\n”;
cout << “7 实现最爱书籍查询;\n”;
cout << “8 图书信息表按指定条件进行批量修改;\n”;
cout << “9 利用快速排序按照图书价格降序排序;\n”;
cout << “10 实现最贵图书的查找;\n”;
cout << “若要实现以上任一功能,”;
while (flag)
{
cout << "请输入操作代码:\n";
cin >> number;
switch (number)
{
case 1:
book.Creat();
book.OutPut();;
break;
case 2:
book.OutPut();;
break;
case 3:
book.Location_Index();
book.OutPut();
break;
case 4:
book.Delete();
book.OutPut();
break;
case 5:
book.GetLength();
break;
case 6:
book.Remove();
book.OutPut();
break;
case 7:
book.SearchFavourite();
break;
case 8:
book.Change();
break;
case 9:
book.Sort();
book.OutPut();
break;
case 10:
book.SearchMExpensive();
break;
default:
cout << "输入数字无效";
flag = false;
return(true);
}
}
book.~BookLinkList();
}
实验二 隐式图的搜索问题
(一)实验内容:
编写九宫重排问题的启发式搜索(A*算法)求解程序。
在3х3组成的九宫棋盘上,放置数码为1~8的8个棋子,棋盘中留有一个空格,空格周围的棋子可以移动到空格中,从而改变棋盘的布局。
根据给定初始布局和目标布局,编程给出一个最优的走法序列。
输出每个状态的棋盘
测试数据:
初始状态:123456780 目标状态:012345678
【输入格式】
输入包含三行,每行3各整数,分别为0-8这九个数字,以空格符号隔开,标识问题的初始状态。0表示空格,例如:
2 0 3
1 8 4
7 6 5
(二)实验设计过程:
1、思路:对于九宫重排问题的解决,首先要考虑是否有答案。每一个状态可认为是一个1×9的矩阵,问题即通过矩阵的变换,可以变换为目标状态对应的矩阵。由数学知识可知,可计算这两个有序数列的逆序值,如果两者都是偶数或奇数,则可通过变换到达,否则,这两个状态不可达。这样,就可以在具体解决问题之前判断出问题是否可解,从而可以避免不必要的搜索。
如果初始状态可以到达目标状态,那么采取什么样的方法呢?常用的状态空间搜索有深度优先和广度优先。广度和深度优先搜索有一个很大的缺陷就是他们都是在一个给定的状态空间中穷举。这在状态空间不大的情况下是很合适的算法,可是当状态空间十分大,且不预测的情况下就不可取了。他的效率实在太低,甚至不可完成。由于九宫重排问题状态空间共有9!个状态,如果选定了初始状态和目标状态,有9!/2个状态要搜索,考虑到时间和空间的限制,在这里要求采用A算法求解。
A算法是启发式搜索算法,启发式搜索就是在状态空间中对每一个搜索分支进行评估,得到最好的分支,再从这个分支进行搜索直到目标。这样可以省略大量无畏的搜索路径,提到了效率。在启发式搜索中,利用当前与问题有关的信息作为启发式信息指导搜索,这些信息能够有效省略大量无谓的搜索路径,大大提高了搜索效率。
启发式搜索算法定义了一个估价函数f(n),与问题相关的启发式信息都被计算为一定的 f(n) 的值,引入到搜索过程中。f(n) = g(n) +h(n)其中f(n) 是节点n的估价函数,g(n)是在状态空间中从初始节点到节点n的实际代价,h(n)是从节点n到目标节点最佳路径的估计代价。 在九宫重排问题中,显然g(n)就是从初始状态变换到当前状态所移动的步数,估计函数h(n)估计的是节点n到目标节点的距离,我们可以用欧几里德距离、曼哈顿距离或是两节的状态中数字的错位数来估计。
2、实验设计:
(1)存储结构的定义
long total;
typedef char board[SIZE][SIZE];
board target = { 1,2,3,4,5,6,7,8,0 }; // 目标状态
typedef struct mynode {
board data; //存放状态
struct mynode* parent; //存放父节点地址
struct mynode* child[4]; //存放子节点地址,最多4个
struct mynode* next; //索引指针
int f, h, g, how; //how中记录了其父节点如何移动生成该节点
}Node, * List;
(2)启发式搜索算法的描述:
①把初始节点S0 放入Open表中,f(S0)=g(S0)+h(S0);
②如果Open表为空,则问题无解,失败退出;
③把Open表的第一个节点取出放入Closed表,并记该节点为n;
④考察节点n是否为目标节点。若是,则找到了问题的解,成功退出;
⑤若节点n不可扩展,则转到第②步;
⑥扩展节点n,生成子节点ni(i=1,2,……),计算每一个子节点的估价值f(ni) (i=1,2,……),并为每一个子节点设置指向父节点的指针,然后将这些子节点放入Open表中;
⑦根据各节点的估价函数值,对Open表中的全部节点按从小到大的顺序重新进行排序;
⑧转到第②步。
启发式搜索算法的工作过程: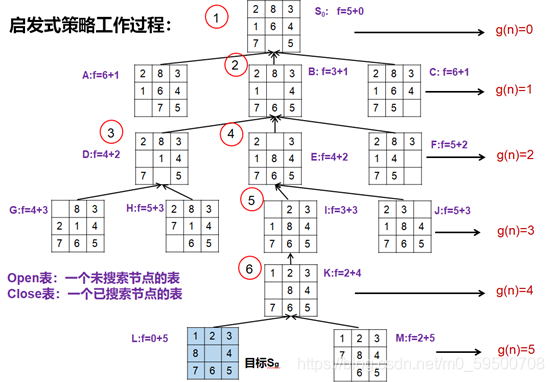
(三)、实验完整代码
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
#include<string.h>
#include<math.h>
#define SIZE 3
#define SIZESQR 9
long total;
typedef char board[SIZE][SIZE];
board target = { 1,2,3,4,5,6,7,8,0 }; // 目标状态
typedef struct mynode {
board data; //存放状态
struct mynode* parent; //存放父节点地址
struct mynode* child[4]; //存放子节点地址,最多4个
struct mynode* next; //索引指针
int f, h, g, how; //how中记录了其父节点如何移动生成该节点
}Node, * List;
void Nodeini(Node* nodep);
int geth();
int cansolve(Node* start);
int goal(board temp);
Node* head;
Node* stack[50], * p;
int top = 0;
void Nodeini(Node* nodep)//初始化
{
memset(nodep, 0, sizeof(Node));
}
int geth(Node* nodep)//计算h值(h值为每个将牌与其目标位的总和)
{
int i, j, x, y, h = 0;
for (i = 0; i < SIZE; i++)
for (j = 0; j < SIZE; j++)
for (x = 0; x < SIZE; x++)
for (y = 0; y < SIZE; y++)
if (target[x][y] == nodep->data[i][j] && target[x][y])
h += abs(x - i) + abs(y - j);
return h;
}
void push(Node* stack[], Node* p, int* top)
{
stack[(*top)++] = p;
}
Node* pop(Node* stack[], int* top)
{
return stack[–(*top)];
}
int cansolve(Node* start) // 搜索前判断是否可解,如果逆序的奇偶性相同则可解,反之则不可解
{
long i, j, k1, k2;
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
{
if (!start->data[i][j])
{
start->data[i][j] = SIZESQR;
k1 = (SIZE - 1 - i) + (SIZE - 1 - j);
}
if (!target[i][j])
{
target[i][j] = SIZESQR;
k2 = (SIZE - 1 - i) + (SIZE - 1 - j);
}
}
}
for (i = 0; i < SIZESQR; i++)
{
for (j = i + 1; j < SIZESQR; j++)
{
if (start->data[i / SIZE][i % SIZE] > start->data[j / SIZE][j % SIZE]) k1++;
if (target[i / SIZE][i % SIZE] > target[j / SIZE][j % SIZE]) k2++;
}
}
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
{
if (start->data[i][j] == SIZESQR) start->data[i][j] = 0;
if (target[i][j] == SIZESQR) target[i][j] = 0;
}
}
return (k1 % 2) == (k2 % 2) ? 1 : 0;
}
//判断temp状态是否是目标状态
int goal(board temp)
{
if (memcmp(temp, target, sizeof(target)))
return 0;
return 1;
}
//返回0所在的坐标
void getxy(Node* temp, int* x, int* y)
{
int i, j;
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
if (!temp->data[i][j])
{
x = i;
y = j;
}
}
}
void new_node(Node p, int index, int how, int x, int y, int xi, int yi)//移动操作(节点指针,子节点序号,移动方向,x,y,x偏移量,y偏移量)
{
int i, j, k;
char tmp;
i = (index);
p->child[i] = (List)malloc(sizeof(Node));
Nodeini(p->child[i]);
for (k = 0; k < SIZE; k++)
{
for (j = 0; j < SIZE; j++)
{
p->child[i]->data[k][j] = p->data[k][j];
}
}
tmp = p->child[i]->data[x][y];
p->child[i]->data[x][y] = p->data[x + xi][y + yi];
p->child[i]->data[x + xi][y + yi] = tmp;
p->child[i]->parent = p;
p->child[i]->h = geth(p->child[i]);
p->child[i]->g = p->g + 1;
p->child[i]->how = how;
p->child[i]->f = p->child[i]->h + p->child[i]->g;
i++;
total++;
index = i;
}
//扩展p所指向的节点
void expand(Node p) {
int x, y, i = 0, j = 0, k = 0;
Node temp, * lasttemp;
getxy(p, &x, &y);
//y!=0(左边有节点)并且how!=4(不是父节点右移得到的),进行左移
if (y != 0 && p->how != 4)
new_node(p, &i, 1, x, y, 0, -1);
if (y != 2 && p->how != 1)
new_node(p, &i, 4, x, y, 0, 1);
if (x != 0 && p->how != 3)
new_node(p, &i, 2, x, y, -1, 0);
if (x != 2 && p->how != 2)
new_node(p, &i, 3, x, y, 1, 0);
//插入open表
for (j = 0; j < i; j++)
{
if (!head || (head->f >= p->child[j]->f))
{
temp = head;
head = p->child[j];
p->child[j]->next = temp;
}
else
{
temp = head;
lasttemp = temp;
while (temp && (temp->f < p->child[j]->f))
{
lasttemp = temp;
temp = temp->next;
}
if (!lasttemp->next)
p->child[j]->next = NULL;
else
p->child[j]->next = temp;
lasttemp->next = p->child[j];
}
}
p->next = head;
}
void main()
{
Node begin;
Node* start, * temp, * tempn;
int a[SIZESQR];
int i, j, k, ix, jx;
char ch;
while (1)
{
total = 1;
//输入原始状态
Nodeini(&begin);
start = &begin;
printf("┏━━━━━┓\n");
printf("┃ 菜单 ┃\n");
printf("┃1.手动输入┃\n");
printf("┃2.随机生成┃\n");
printf("┃0.退出程序┃\n");
printf("┗━━━━━┛\n");
scanf(" %c", &ch);
if (ch == '0')
break;
else if (ch == '1')
{
printf("\n请输入初始状态:\n");
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
{
scanf("%ld", &k);
start->data[i][j] = k;
}
}
}
else
{
srand((unsigned)time(NULL)); //随机时间种子
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
{
k = (int)(rand()) % SIZESQR;
start->data[i][j] = k;
a[i * SIZE + j] = k;
for (k = 0; (k < i * SIZE + j) && (i + j); k++)
if (start->data[i][j] == a[k]) { j--; break; }
}
}
}
printf("\n初始状态为:\n");
printf("┏━━━┓\n");
for (i = 0; i < SIZE; i++)
{
printf("┃");
for (j = 0; j < SIZE; j++)
printf("%d ", start->data[i][j]);
printf("┃");
printf("\n");
}
printf("┗━━━┛\n");
printf("\n目标状态为:\n");
printf("┏━━━┓\n");
for (i = 0; i < SIZE; i++)
{
printf("┃");
for (j = 0; j < SIZE; j++)
printf("%d ", target[i][j]);
printf("┃");
printf("\n");
}
printf("┗━━━┛\n");
printf("是否要修改目标状态?(y/n):\n");
scanf(" %c", &ch);
if (ch == 'Y' || ch == 'y')
{
printf("请输入新的目标状态:\n");
for (i = 0; i < SIZE; i++)
{
for (j = 0; j < SIZE; j++)
{
scanf("%ld", &k);
target[i][j] = k;
}
}
}
//判断是否能到目标状态
if (!cansolve(start))
{
printf("This puzzle is not solvable.\n");
continue;
}
//对原始状态节点进行初始化
start->g = 0;
start->how = 0;
start->h = geth(start);
start->f = start->h + start->g;
head = start;
//加入open表,head为头指针
while (1)
{
if (goal(head->data))
break;
//将tempn(原来的head)从open表中删除
tempn = head;
head = head->next;
//扩展tempn
expand(tempn);
//对open表进行排序
i = 0;
while (tempn->child[i] && (i < 4)) i++;
}
j = -1;
top = 0;
//输出结果
while (head)
{
push(stack, head, &top);
head = head->parent;
j++;
}
while (top)
{
p = pop(stack, &top);
printf("┏━━━┓\n");
for (ix = 0; ix < SIZE; ix++)
{
printf("┃");
for (jx = 0; jx < SIZE; jx++)
printf("%d ", p->data[ix][jx]);
printf("┃");
printf("\n");
}
printf("┗━━━┛\n");
if (top)printf(" \\/ \n");
}
printf("总共%d步!\n", j);
printf("生成节点数:%8ld\n", total);
start = start->next;
while (start)
{
temp = start;
start = start->next;
free(temp);
}
printf("\n是否继续?(y/n):");
scanf(" %c", &ch);
if (ch == 'n' || ch == 'N') break;
}
}
实验三 基于线性表和二叉排序树的低频词过滤系统
(一)实验内容
- 对于一篇给定的英文文章,分别利用线性表和二叉排序树来实现单词频率的统计,实现低频词的过滤,并比较两种方法的效率。具体要求如下:
- 读取英文文章文件(Infile.txt),识别其中的单词。
- 分别利用线性表和二叉排序树构建单词的存储结构。当识别出一个单词后,若线性表或者二叉排序树中没有该单词,则在适当的位置上添加该单词;若该单词已经被识别,则增加其出现的频率。
- 统计结束后,删除出现频率低于五次的单词,并显示该单词和其出现频率。
- 其余单词及其出现频率按照从高到低的次序输出到文件中(Outfile.txt),同时输出用两种方法完成该工作所用的时间。
- 计算查找表的ASL值,分析比较两种方法的效率。
- 系统运行后主菜单如下:
当选择1后进入以下界面:
其中选择2时显示利用线性表来实现所有功能所用的时间。
当在主菜单选择2二叉排序树后,进入的界面与上图类同。
(二)实验设计过程:
1、在统计的过程中,分词时可以利用空格或者标点符号作为划分单词依据,文章中默认只包含英文单词和标点符号。
2、对单词进行排序时,是按照字母序进行的,每个结点还应包含该单词出现的频率。
3、存储结构的定义
typedef struct node1 { //单链表节点
char data[20];
int count;
struct node1* next;
}LNode, * LinkList;
typedef struct node2//排序二叉树节点
{
char data[20];
int count;
struct node2* left;
struct node2* right;
}BSTNode, * BSTree;
BSTree T, nT;
4、实现过程可线性表和二叉排序树的相关算法。
(三)实验完整代码
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<string.h>
#include <time.h>
typedef struct node1 { //单链表节点
char data[20];
int count;
struct node1* next;
}LNode, * LinkList;
typedef struct node2//排序二叉树节点
{
char data[20];
int count;
struct node2* left;
struct node2* right;
}BSTNode, * BSTree;
BSTree T, nT;
typedef struct stack//非递归中序遍历写入文件outFile.txt
{
BSTree data[1000];
int top;
}seqstack;
/***************************************************************************************///单链表
void swap(LinkList x, LinkList y)
{
char a[20];
strcpy(a, x->data);
int b = x->count;
strcpy(x->data, y->data);
x->count = y->count;
strcpy(y->data, a);
y->count = b;
}
void sort_slist(LinkList& L)
{
LinkList p, q, temp;
p = L->next;
while §
{
q = p->next;
while (q)
{
if (p->count < q->count)
{
swap(p, q);
}
else
q = q->next;
}
p = p->next;
}
}
void InitList(LinkList& L)
{
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL;
}
void InsertList(LinkList& L, char* a)//先将每一元素存入线性链表中,然后统计个数
{
int flag = 0;
LinkList P;
LinkList Q;
Q = L->next;
while (Q != NULL)
{
if (!strcmp(a, Q->data))
{
Q->count++;
flag = 1;
break;
}
Q = Q->next;
}
if (!flag)
{
P = (LinkList)malloc(sizeof(LNode));
strcpy(P->data, a);
P->count = 1;
P->next = L->next;
L->next = P;
}
}
void LNodeprint(LinkList& L)
{
LinkList P;
P = L->next;
printf(“单词 个数统计\n”);
while (P != NULL)
{
printf("%-10s %d\n", P->data, P->count);
P = P->next;
}
}
void fprint1(LinkList& L)
{
LinkList P;
FILE* out;
out = fopen(“outFile.txt”, “a+”);//建立输出文件
fprintf(out, “单链表删除个数<5的单词:\n”);
P = L->next;
while §
{
fprintf(out, “%s (%d)\t”, P->data, P->count);
P = P->next;
}
fclose(out);
}
void single_distinguish_count1()
{
FILE* in;
char a[20], c;
LinkList L;
InitList(L);
in = fopen(“inFile.txt”, “r”);//打开输入文件
while (!feof(in))//直到碰见文件结束符结束循环
{
int i = 0;
memset(a, 0, sizeof(a));
while ((c = fgetc(in)) != EOF && !(c == ‘,’ || c == ‘.’ || c == ‘!’ || c == ‘?’ || c == ’ ’ || c == ‘(’ || c == ‘)’))
{
a[i++] = c;
}
if (a[0])
InsertList(L, a);
}
sort_slist(L);
LNodeprint(L);
fclose(in);//关闭文件
}
void deletenode(LinkList& L)
{
LinkList P, Q;
FILE* out;
out = fopen(“outFile.txt”, “w+”);//建立输出文件
P = L->next;
while (P && P->count >= 5)
{
P = P->next;
}
while §
{
Q = P;
P = P->next;
printf(“删除节点: %-10s %d\n”, Q->data, Q->count);
free(Q);
}
}
void single_delete1()
{
FILE* in;
int j = 1;
char a[20], c;
LinkList L;
InitList(L);
in = fopen(“inFile.txt”, “r”);//打开输入文件
while (!feof(in))//直到碰见文件结束符结束循环
{
int i = 0;
memset(a, 0, sizeof(a));
while ((c = fgetc(in)) != EOF && !(c == ‘,’ || c == ‘.’ || c == ‘!’ || c == ‘?’ || c == ’ ’ || c == ‘(’ || c == ‘)’))
{
a[i++] = c;
}
if (a[0])
{
InsertList(L, a);
}
}
sort_slist(L);
printf(“删除低频词汇\n”);
deletenode(L);
}
void outnode(LinkList& L)
{
LinkList P, Q;
FILE* out;
out = fopen(“outFile.txt”, “w+”);//建立输出文件
P = L->next;
printf(“删除低频率单词后\n单词 个数统计\n”);
while (P && P->count >= 5)
{
printf("%-10s %d\n", P->data, P->count);
fprintf(out, “%s(%d)\t”, P->data, P->count);
P = P->next;
}
printf(“写入文件outFile.txt成功\n”);
}
void single_output1()
{
FILE* in;
int j = 1;
char a[20], c;
LinkList L;
InitList(L);
in = fopen(“inFile.txt”, “r”);//打开输入文件
while (!feof(in))//直到碰见文件结束符结束循环
{
int i = 0;
memset(a, 0, sizeof(a));
while ((c = fgetc(in)) != EOF && !(c == ‘,’ || c == ‘.’ || c == ‘!’ || c == ‘?’ || c == ’ ’ || c == ‘(’ || c == ‘)’))
{
a[i++] = c;
}
if (a[0])
{
InsertList(L, a);
}
}
sort_slist(L);
outnode(L);
fclose(in);//关闭文件
}
int sumNode(LinkList& L)
{
int sum = 0;
LinkList p;
p = L->next;
while §
{
sum++;
p = p->next;
}
return sum;
}
void single_ASL1()
{
FILE* in;
int sum;
char a[20], c;
LinkList L;
InitList(L);
in = fopen(“inFile.txt”, “r”);//打开输入文件
while (!feof(in))//直到碰见文件结束符结束循环
{
int i = 0;
memset(a, 0, sizeof(a));
while ((c = fgetc(in)) != EOF && !(c == ‘,’ || c == ‘.’ || c == ‘!’ || c == ‘?’ || c == ’ ’ || c == ‘(’ || c == ‘)’))
{
a[i++] = c;
}
if (a[0])
{
InsertList(L, a);
}
}
sum = sumNode(L);
printf(“单词总个数:%d\n”, sum);
fclose(in);//关闭文件
printf(“ASL = %.2f \n”, double(3 * (sum + 1) / 4.0));
}
void continue_to_finish1()
{
single_distinguish_count1();
single_delete1();
single_output1();
single_ASL1();
}
void show_time1()
{
double star, finish;
star = (double)clock();//获取当前时间
single_distinguish_count1();
single_delete1();
single_output1();
single_ASL1();
finish = (double)clock();//获取结束时间
printf(“执行时间:%.2f ms\n”, (finish - star));//得到的是运行for语句所用的时间,时间单位了毫秒
}
/**************************************************************************///排序二叉树
void insertNode(BSTree& T, char a)
{
if (T == NULL)
{
T = (BSTree)malloc(sizeof(BSTNode));
strcpy(T->data, a);
T->left = NULL;
T->right = NULL;
T->count = 1;
}
else
{
if (strcmp(a, T->data) < 0)
{
insertNode(T->left, a);
}
else if (strcmp(a, T->data) == 0)
{
T->count++;
}
else
{
insertNode(T->right, a);
}
}
}
void printTree(BSTree T)//中序遍历二叉排序树,得到有序序列
{
if (T)
{
printTree(T->left);
printf("%-10s %d\n", T->data, T->count);
printTree(T->right);
}
}
void fprint2(BSTree T)
{
FILE out;
seqstack S;
S.top = -1;
out = fopen(“outFile.txt”, “a+”);//建立输出文件
fprintf(out, “排序二叉树删除个数 < 5 的单词:\n”);
while (T || S.top != -1)
{
while (T)
{
S.top++;
S.data[S.top] = T;
T = T->left;
}
if (S.top > -1)
{
T = S.data[S.top];
S.top–;
fprintf(out, “%s (%d)\t”, T->data, T->count);
T = T->right;
}
}
fclose(out);
}
void single_distinguish_count2()
{
FILE in;
T = NULL;
in = fopen(“inFile.txt”, “r”);//打开输入文件
char a[20], c;
while (!feof(in))//直到碰见文件结束符结束循环
{
int i = 0;
memset(a, 0, sizeof(a));
while ((c = fgetc(in)) != EOF && !(c == ‘,’ || c == ‘.’ || c == ‘!’ || c == ‘?’ || c == ’ ’ || c == ‘(’ || c == ‘)’))
{
a[i++] = c;
}
if (a[0])
insertNode(T, a);
}
printf(“中序遍历二叉排序树\n”);
printf(“单词 个数统计\n”);
printTree(T);
}
BSTree insertTree(BSTree& nT, BSTree T)//中序遍历二叉排序树,得到有序序列
{
if (nT == NULL)
{
nT = (BSTree)malloc(sizeof(BSTNode));
strcpy(nT->data, T->data);
nT->count = T->count;
nT->left = NULL;
nT->right = NULL;
}
else
{
if (strcmp(T->data, nT->data) < 0)
{
insertTree(nT->left, T);
}
else
{
insertTree(nT->right, T);
}
}
return nT;
}
void newBSTree(BSTree T)//中序遍历二叉排序树,得到有序序列
{
if (T)
{
newBSTree(T->left);
if (T->count >= 5)
{
insertTree(nT, T);
}
newBSTree(T->right);
}
}
void single_delete2()
{
printf(“删除<5的二叉排序树中序遍历:\n”);
nT = NULL;
newBSTree(T);
printf(“单词 个数统计\n”);
printTree(nT);
}
void single_output2()
{
printf(“单词 个数统计\n”);
printTree(nT);
printf(“写入文件outFile.txt成功\n”);
fprint2(nT);
}
int calculateASL(BSTree T, int s, int j, int i) /计算平均查找长度/
{
if (T)
{
i++; *s = *s + i;
if (calculateASL(T->left, s, j, i))
{
(*j)++;
if (calculateASL(T->right, s, j, i))
{
i–; return(1);
}
}
}
else return(1);
}
void single_ASL2()
{
int s = 0, j = 0, i = 0;
calculateASL(T, &s, &j, i);
printf(“ASL = %d / %d \n”, s, j);
}
void continue_to_finish2()
{
single_distinguish_count2();
single_delete2();
single_output2();
single_ASL2();
}
void show_time2()
{
double star, finish;
star = (double)clock();//获取当前时间
single_distinguish_count2();
single_delete2();
single_output2();
single_ASL2();
finish = (double)clock();//获取结束时间
printf(“执行时间:%.2f ms\n”, (finish - star));//得到的是运行for语句所用的时间,时间单位了毫秒
}
/*******************************************************************************///菜单设置
void print1()
{
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n”);
printf(“★ 主菜单 ★ \n”);
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n\n”);
printf(" ☆ 1.线性表\n");
printf(" ☆ 2.二叉排序树\n");
printf(" ☆ 3.退出系统\n");
printf(“请输入你的选择:”);
}
void print2()
{
printf(" ☆ 1.连续执行至完毕\n");
printf(" ☆ 2.显示执行时间\n");
printf(" ☆ 3.单步执行:识别并统计单词\n");
printf(" ☆ 4.单步执行:删除并显示出现频率低的单词\n");
printf(" ☆ 5.单步执行:输出其余单词及其频率\n");
printf(" ☆ 6.单步执行:计算并输出ASL\n");
printf(" ☆ 7.返回主菜单\n");
printf(“请输入你的选择:”);
}
void mainmenu();
void Link()
{
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n”);
printf(“★ 线性表选择菜单 ★ \n”);
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n\n”);
print2();
int n;
scanf("%d", &n);
while (!(n == 1 || n == 2 || n == 3 || n == 4 || n == 5 || n == 6 || n == 7))
{
printf(“输入有误,请重新输入\n”);
scanf("%d", &n);
}
system(“cls”);
switch (n)
{
case 1:
continue_to_finish1();
Link();
break;
case 2:
show_time1();
Link();
break;
case 3:
single_distinguish_count1();
Link();
break;
case 4:
single_delete1();
Link();
break;
case 5:
single_output1();
Link();
break;
case 6:
single_ASL1();
Link();
break;
case 7:
mainmenu();
break;
}
}
void Tree()
{
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n”);
printf(“★ 二叉排序树选择菜单 ★ \n”);
printf(“★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★\n\n”);
print2();
int n;
scanf("%d", &n);
while (!(n == 1 || n == 2 || n == 3 || n == 4 || n == 5 || n == 6 || n == 7))
{
printf(“输入有误,请重新输入\n”);
scanf("%d", &n);
}
system(“cls”);
switch (n)
{
case 1:
continue_to_finish2();
Tree();
break;
case 2:
show_time2();
Tree();
break;
case 3:
single_distinguish_count2();
Tree();
break;
case 4:
single_delete2();
Tree();
break;
case 5:
single_output2();
Tree();
break;
case 6:
single_ASL2();
Tree();
break;
case 7:
mainmenu();
break;
}
}
void mainmenu()
{
print1();
int n;
scanf("%d", &n);
while (!(n == 1 || n == 2 || n == 3))
{
printf(“输入有误,请重新输入\n”);
scanf("%d", &n);
}
system(“cls”);
switch (n)
{
case 1:
Link();
mainmenu();
break;
case 2:
Tree();
mainmenu();
break;
case 3:
printf(“退出系统\n”);
exit(0);
}
}
int main()
{
mainmenu();
}

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









