







一、Redis
- 1、Redis是一个高性能的基于Key-Value结构存储的NoSql开源数据库。
- 2、一般大型公司都采用Redis来实现分布式缓存,从而提高数据的检索效率。
二、Redis的特点
- 1、Redis是基于内存存储,在进行数据IO操作时,能够10WQPS。
- 2、Redis提供了丰富的数据存储结构,如String、List、Hash、Set、ZSet等。
- 3、Redis底层采用单线程实现数据的IO,所以在数据算法表层并不需要考虑并发安全性,所以底层算法上的时间复杂度基本上都是常量。
- 4、Redis虽然是内存存储,但是它也可以支持持久化,避免因为服务器故障导致数据丢失问题。
基于这些特点,Redis一般用来实现分布式缓存,从而降低应用程序对关系型数据库检索带来的性能影响。除此之外,Redis还可以实现分布式锁、分布式队列、排行榜、查找附近的人等功能,为复杂应用提供便捷且成熟的解决方案。
三、Redis常见问题
- 一、为什么Redis这么快?
影响Redis的因素:网络、CPU、内存
- 1、网络
Redis采用的是多路复用设计的,提高了并发处理的连接数,Servers端的所以IO操作都由同一个主线程完成。(所以也可以认为Redis数据处理是单线程的。)
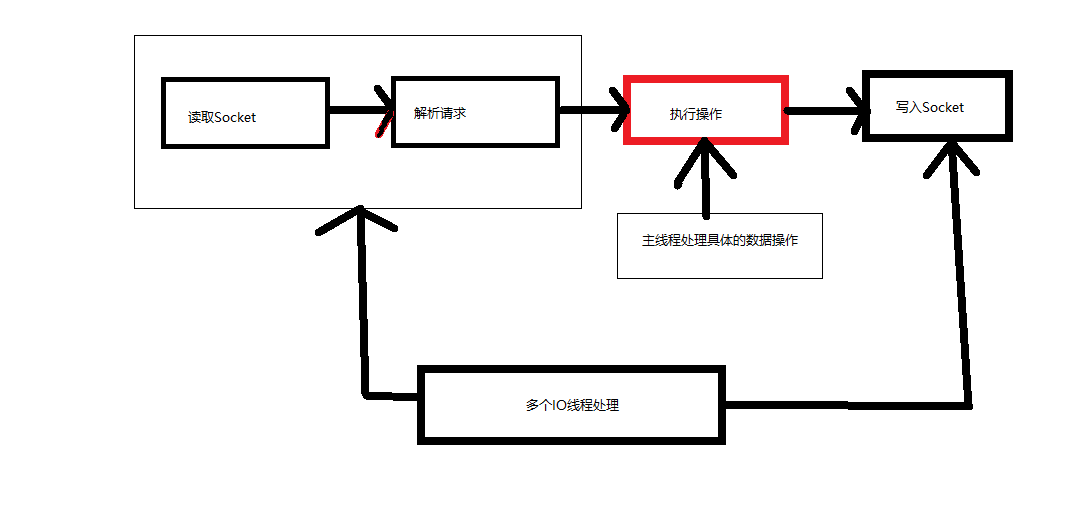
-
2、CPU
从cpu层面来说,Redis只需要采用单线程即可,原因有两个:-
1、如果采用多线程,对于Redis中的数据操作,都需要通过同步的方式来保证线程安全性,反而会降低Redis性能。
-
2、在Linux系统上Redis通过pipelining可以处理100W个请求/s,而应用程序的计算复杂度主要是O(N)或O(logN),不会消耗太多CPU。
-
-
3、内存
- Redis本身就是一个内存数据库,内存的IO速度本身就很快,所以内存的瓶颈只是受限于内存大小。
- 二、Redis和MySql如何保证数据一致性?
-
1、一般情况下,Redis用来实现和数据库之间读操作的缓存层,主要目的是减少数据库IO,提高数据的IO性能。
-
2、当应用程序需要去读取某个数据的时候,首先会尝试去Redis里面加载,如果命中就直接返回。若没有命中,就从数据库查询,查询到数据后再把这个数据缓存到Redis里面。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









