






 本文探讨了卷积神经网络在分类任务中的应用,重点关注编码器和分类器的作用。作者指出,通常关注的是网络的全连接层输出,但度量学习提出了一种新的思路——优化编码器生成的特征。通过度量学习,相似的图像将有相似的特征表示,从而提高分类效果。尽管度量学习在某些任务中可能计算量大且不稳定,但它仍然是机器学习领域的一个强大工具。
本文探讨了卷积神经网络在分类任务中的应用,重点关注编码器和分类器的作用。作者指出,通常关注的是网络的全连接层输出,但度量学习提出了一种新的思路——优化编码器生成的特征。通过度量学习,相似的图像将有相似的特征表示,从而提高分类效果。尽管度量学习在某些任务中可能计算量大且不稳定,但它仍然是机器学习领域的一个强大工具。
2021SC@SDUSC
代码位置:https://github.com/tensorflow/similarity/blob/master/tensorflow_similarity/layers.py
# Copyright 2021 The TensorFlow Authors
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Specialized Similarity `keras.layers`"""
from typing import Dict
import tensorflow as tf
from tensorflow.keras.layers import Layer
from tensorflow.keras import layers
from .types import FloatTensor
@tf.keras.utils.register_keras_serializable(package="Similarity")
class MetricEmbedding(Layer):
def __init__(self, unit: int):
"""L2 Normalized `Dense` layer usually used as output layer.
Args:
unit: Dimension of the output embbeding. Commonly between
32 and 512. Larger embeddings usually result in higher accuracy up
to a point at the expense of making search slower.
"""
self.unit = unit
self.dense = layers.Dense(unit)
super().__init__()
# FIXME: enforce the shape
# self.input_spec = rank2
def call(self, inputs: FloatTensor) -> FloatTensor:
x = self.dense(inputs)
normed_x: FloatTensor = tf.math.l2_normalize(x, axis=1)
return normed_x
def get_config(self) -> Dict[str, int]:
return {'unit': self.unit}通常如何进行分类
在我们深入研究度量学习之前,首先了解分类任务通常是如何解决的实际上是一个好主意。 当今实用计算机视觉最重要的思想之一是卷积神经网络,它们由两部分组成:编码器和头部(在本例中为分类器)。
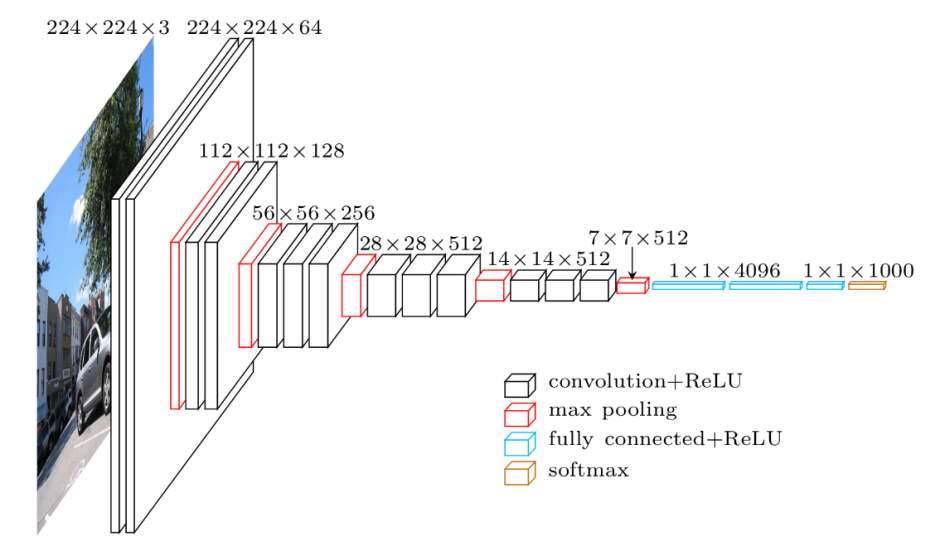
首先——你拍摄一张图像并计算一组特征来捕捉该图像的重要品质。这是使用卷积和池化操作完成的(这就是为什么它被称为卷积神经网络)。之后——您将这些特征解压缩到单个向量中,并使用常规的全连接神经网络来执行分类。在实践中,您采用一些在大型数据集(如 ImageNet)上进行预训练的模型(例如 ResNet、DenseNet、EfficientNet 等),并在您的任务(仅最后一层或整个模型)上对其进行微调)。
但是,这里有几件事情需要注意。首先,通常你只关心网络FC部分的输出。也就是说,您获取其输出,并将它们提供给损失函数以保持模型学习。换句话说,你并不真正关心网络中间发生了什么(例如,来自编码器的特征)。其次,(同样,通常)你用一些基本的损失函数来训练这整个事情,比如交叉熵。
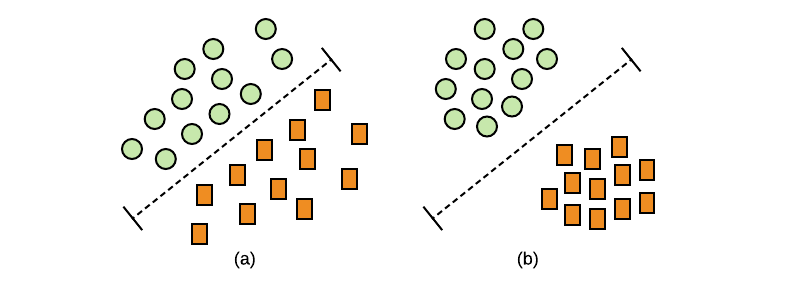
为了更好地理解这个 2 步过程(编码器 + FC),您可以这样考虑:编码器将图像映射到某个高维空间(例如,在 ResNet18 的情况下,我们谈论的是 512 维, 和 Resnet101-2048)。 之后,FC 的目标是在这些代表样本的点之间画一条线,以便将它们映射到类。 而这两件事是同时训练的。 因此,您正在尝试联合优化特征和“在高维空间中画线”。
这种方法有什么问题? 嗯,没什么,真的。 它实际上工作得很好。 但这并不意味着没有其他方法。
度量学习
现代机器学习中最有趣的想法之一(至少对我个人而言)称为度量学习(或深度度量学习)。 简单来说:如果我们不去寻找 FC 层的输出,而是仔细研究由编码器生成的特征会怎样。 如果我们设法用一些损失函数来优化这些特征,而不是从网络末端的 logits 呢? 这实际上就是度量学习的意义所在:使用编码器生成良好的特征(嵌入)。
但它是什么意思——“好”? 好吧,如果您考虑一下,在计算机视觉的情况下,您希望相似的图像具有相似的特征,而完全不同的图像具有非常不同的特征。
最后的想法
度量学习是一个非常强大的东西。 但是,我很难达到常规 CE/LabelSmoothing 可以提供的准确度水平。 此外,它也可能在训练期间计算量大且不稳定。 我在各种任务上测试了 SupCon 和其他度量损失(分类、分布外预测、对新类的泛化等),使用 SupCon 之类的东西的优势尚不清楚。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









