






 本文详细介绍了Java中的FileInputStream和BufferedInputStream的区别。FileInputStream每次读取一个字节,效率较低,而BufferedInputStream使用内部缓冲区,减少IO操作,提高效率。通过实例分析,解释了BufferedInputStream如何通过批量读取和填充缓冲区提升性能。
本文详细介绍了Java中的FileInputStream和BufferedInputStream的区别。FileInputStream每次读取一个字节,效率较低,而BufferedInputStream使用内部缓冲区,减少IO操作,提高效率。通过实例分析,解释了BufferedInputStream如何通过批量读取和填充缓冲区提升性能。
文章目录
前言
Java中的FileInputStream(字节输入流)和BufferedInputStream(字节缓冲输入流),二者都是将数据读入内存。但BufferedInputStream的效率要高的多。
区别
1.创建出一个FileInputStream的对象后,调用它的read()方法,就是每次由这个对象从磁盘文件中读入一个字节到内存:(源代码如下)
public int read() throws IOException { return read0(); } private native int read0() throws IOException; /** * Reads a subarray as a sequence of bytes. * @param b the data to be written * @param off the start offset in the data * @param len the number of bytes that are written * @exception IOException If an I/O error has occurred. */当建了一个 FileInputStream对象,调用它的read()方法从磁盘上读取取文件时,此时会调用一个native本地方法read0(),然后由这个方法到磁盘中一个字节一个字节的读取数据。此方法返回的是读取到的字节的内容,它是一个0-255之间的数。这种方法就相当于是一个字节一个字节的读取。就像相当于是摘樱桃,从树上摘一颗下来,送到一个地方,然后在爬上 树,再摘一颗下来,送到一个地方...。效率非常低!read()方法被重载过,源代码如下:
public int read(byte b[]) throws IOException { return readBytes(b, 0, b.length); } private native int readBytes(byte b[], int off, int len) throws IOException;这个read()方法允许传入一个字节数组,当调用read()方法读取数据时,read()方法会一次把这个数组“读满”,然后输入到内存。这样显然效率要高一些!此时read()方法返回的是读到的字节的个数。所以除非是最后一次,其余的均是把字符数组b读满,这种方法就相当于是拿着 一个小篮子去摘樱桃。每次把这个小篮子装满,然后送到一个地方。然后再去摘 ,直到树上的樱桃被摘完了,那么最后一次篮子可能装不满,哈哈!
BufferedInputStream通过一个内部缓冲数组实现,此数组的默认长度是8192;当调用read()方法读取文件时,BufferedInputStream会将该输入流的数据分批填入到缓冲区数组中,当此数组中的内容被读完时,会调用fill()方法,把这个字符数组填满。然后再继续调用read()方法读取。这样就相当于是有人把樱桃摘好,放在一个大容器里,而你只需要到容器里去拿樱桃,不需要自己爬到树上去摘。当容器里的樱桃被拿完时,fill()方法自动再把这个容器填满。直到樱桃被摘完。也就是直到读完输入流数据。这样就大大的减少了Io操作,效率高的多!(源代码如下)
public synchronized int read() throws IOException { if (pos >= count) { fill(); if (pos >= count) return -1; } return getBufIfOpen()[pos++] & 0xff; } /** * Read characters into a portion of an array, reading from the underlying * stream at most once if necessary. */ private void fill() throws IOException { byte[] buffer = getBufIfOpen(); if (markpos < 0) pos = 0; /* no mark: throw away the buffer */ else if (pos >= buffer.length) /* no room left in buffer */ if (markpos > 0) { /* can throw away early part of the buffer */ int sz = pos - markpos; System.arraycopy(buffer, markpos, buffer, 0, sz); pos = sz; markpos = 0; } else if (buffer.length >= marklimit) { markpos = -1; /* buffer got too big, invalidate mark */ pos = 0; /* drop buffer contents */ } else if (buffer.length >= MAX_BUFFER_SIZE) { throw new OutOfMemoryError("Required array size too large"); } else { /* grow buffer */ int nsz = (pos <= MAX_BUFFER_SIZE - pos) ? pos * 2 : MAX_BUFFER_SIZE; if (nsz > marklimit) nsz = marklimit; byte nbuf[] = new byte[nsz]; System.arraycopy(buffer, 0, nbuf, 0, pos); if (!bufUpdater.compareAndSet(this, buffer, nbuf)) { // Can't replace buf if there was an async close. // Note: This would need to be changed if fill() // is ever made accessible to multiple threads. // But for now, the only way CAS can fail is via close. // assert buf == null; throw new IOException("Stream closed"); } buffer = nbuf; } count = pos; int n = getInIfOpen().read(buffer, pos, buffer.length - pos); if (n > 0) count = n + pos; }总结
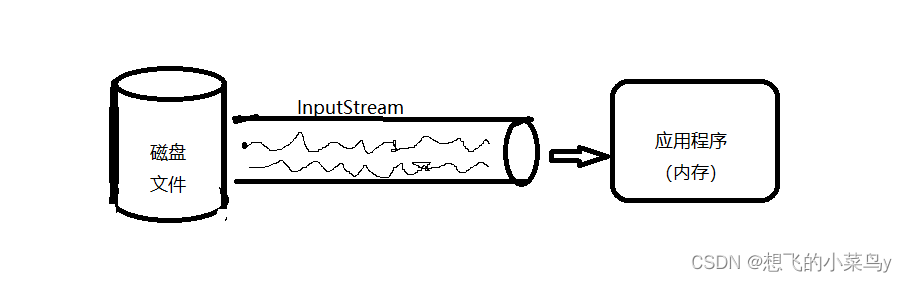
FileInputStream是直接从磁盘中将数据读入内存,IO操作频繁,效率低,它与磁盘文件的和程序的关系如下:
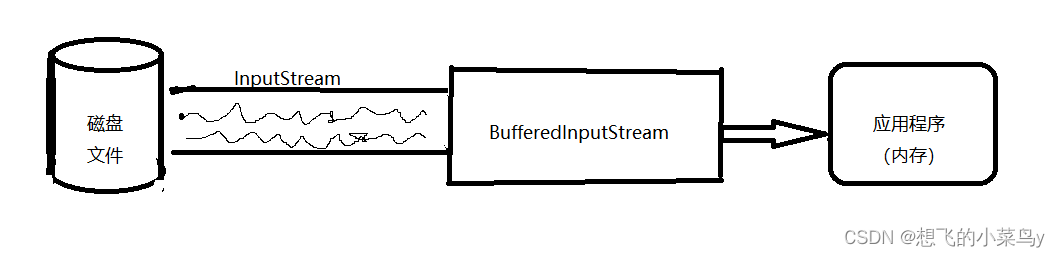
BufferedInputStream是包装在FileInputStream外面。在读入数据时提供了缓冲功能。应用程序通过 字节缓冲输入流 来完成数据的读取,而缓冲流又通过底层的字节输入流与磁盘文件进行关联。由于直接从内存中读取数据,而大大的减少了IO操作,所以效率高!如下:


















 2291
2291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











