






摘要
本文主要包括两个部分,第一部分内容是Transformer编码器中的部分结构,其中包括Embedding、层归一化和Muti-Head Attention。第二部分的内容是transformer解码器的工作原理,在本文中阐述了自回归解码器的工作原理,自回归解码器是比较常见的解码器。它的核心思想是在生成目标语言序列时,每一步的生成都依赖于之前已经生成的序列部分。这种机制确保了生成的序列在语言上是连贯的,并且能够捕捉到长距离的依赖关系。
Abstract
This article is mainly consists of two parts. The first part covers some of the structures in the Transformer encoder, including Embedding, Layer Normalization and Muti-Head Attention.The content of the second part is about the working principle of the transformer decoder. In this article, the working principle of the autoregressive decoder is explained, which is a common decoder. Its core idea is that each step in generating the target language sequence depends on the previously generated sequence parts. This mechanism ensures that the generated sequence is linguistically coherent and can capture long-range dependencies.
编码器
在上周的对transformer 编码器部分的学习过程中,对于很多知识点都不太熟悉,在本周的学习过程中对其进行一一的复习。
Embedding
embedding(嵌入)概念: 是一种将高维数据(如文本、图像或其他类型的数据)映射到低维空间的技术。这种方法的主要目的是将数据的特征转换为一种更加紧凑且易于处理的表示形式,同时尽量保留数据之间的相似性和结构。它会给每一个词汇一个向量,而这个向量是有语义的信息。它可以表示不同向量间的联系
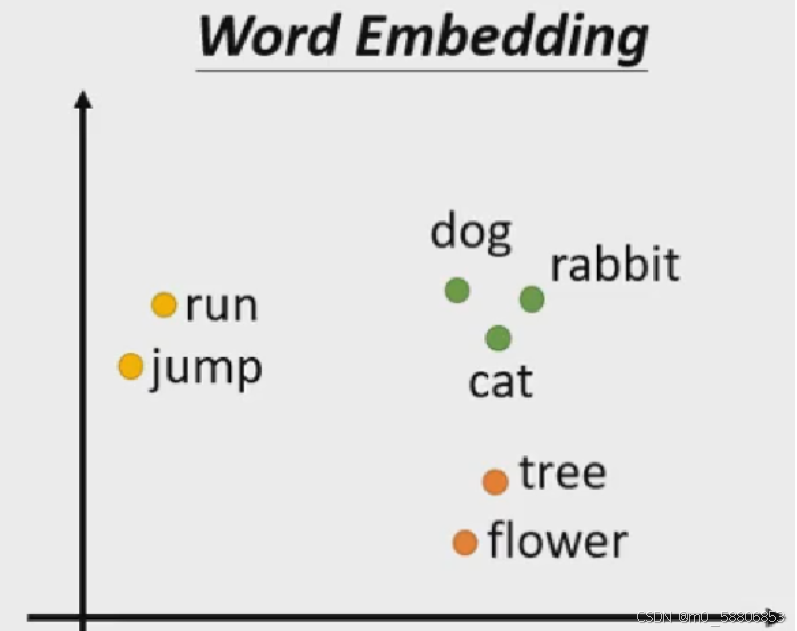
embedding的主要类型:
(1)文本嵌入
文本嵌入是将单词、短语或整个句子转换为向量表示的方法。例如在Word2Vec中利用上下文信息来生成单词的向量表示。
GloVe: 基于词频统计信息生成的词向量。
FastText: 类似于Word2Vec,但考虑了单词的字形特征(n-grams),使得它对拼写错误和形态变化更具鲁棒性。
BERT: 一种上下文感知的嵌入方法,能够理解单词在句子中的上下文。
(2)图像嵌入
在计算机视觉中,图像嵌入是将图像转换为向量的一种方法,常见的技术有:
卷积神经网络(CNN): 通过多层卷积和池化操作提取图像特征,并将其转化为固定长度的向量。
预训练模型: 如VGG、ResNet等,可以提取图像的深层特征作为嵌入。
(3)图嵌入
用于将图数据(如社交网络、知识图谱等)映射到向量空间,以便进行图的分析和处理。
embedding是机器学习和深度学习中一种重要的技术,能够有效地将复杂的数据类型转化为易于处理的形式。
层归一化
(1)为什么进行归一化?
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量)。例如下图中的x6被认为是奇异样本数据。因为其与其他样本数据差距较大。
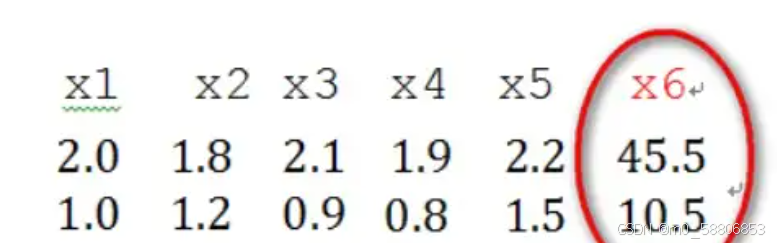
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
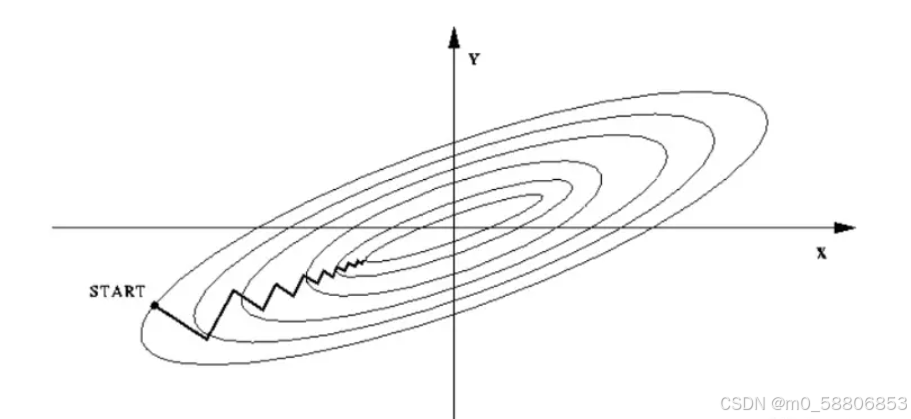
如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。
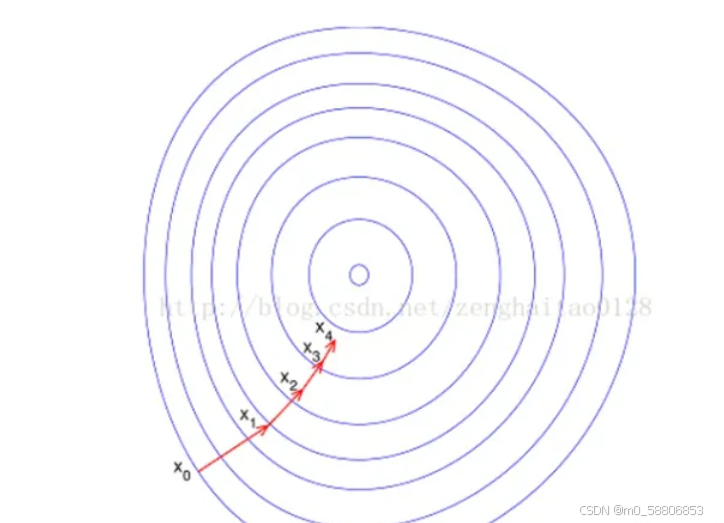
如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
(2)层归一化的计算步骤

下图是做完层归一化的前后对比的一个示例,在做层归一化前,数据都是离散且没有规律的分布的,在做完层归一化后,数据几乎不重叠且规律的分布与同一平面中并且该平面垂直于所有维度为1相连所代表的直线。这将会大大提高训练的速度。
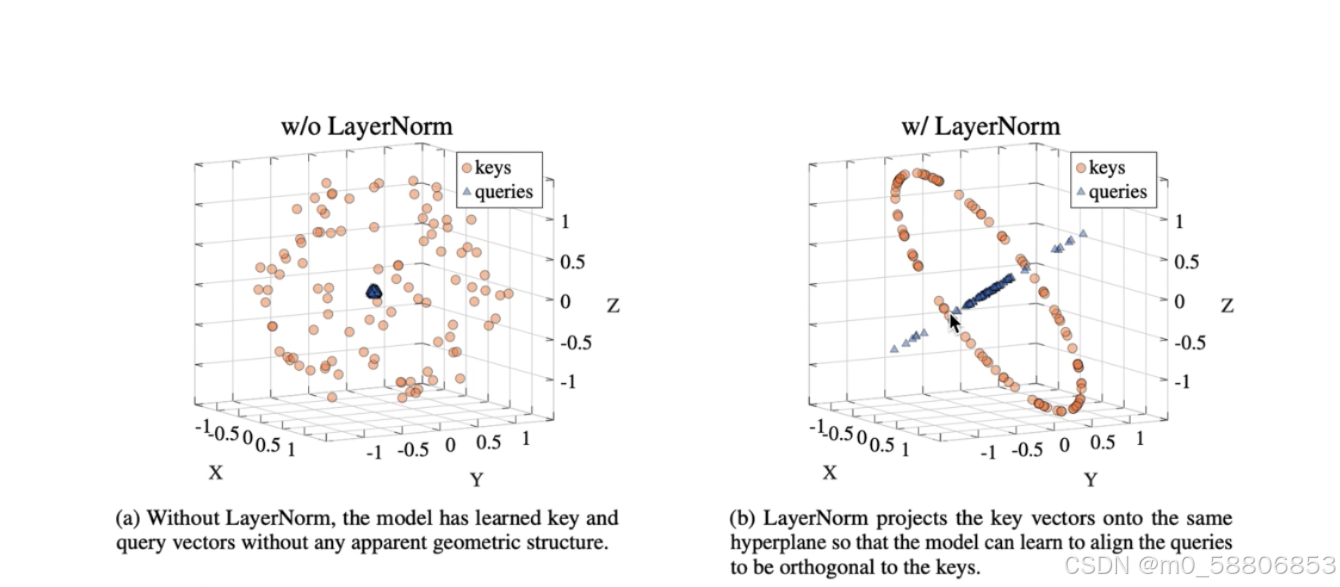
注:图片来源论文On the Expressivity Role of LayerNorm in Transformers’ Attention.
Muti-Head Attention
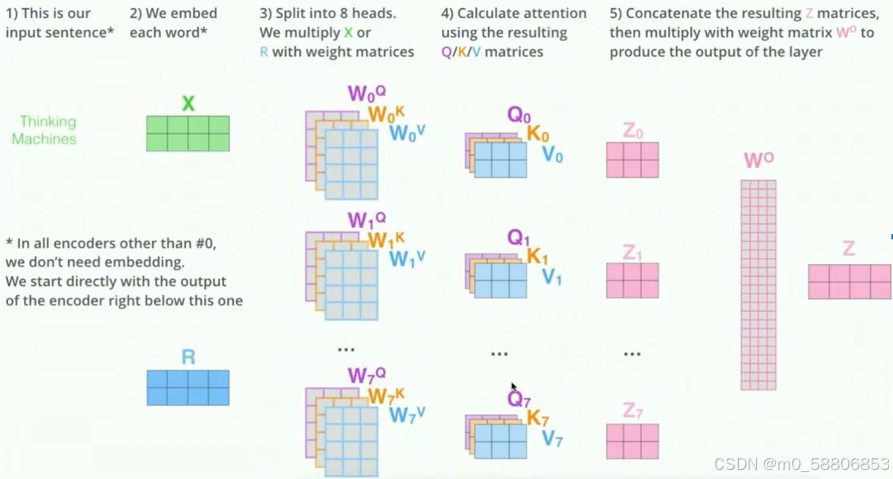
Muti-Head Attention在十一周周报中有进行学习,所以本次复习对其概念不做详写,只进行相关的回顾复习,在理论上,Muti-Head Attention中的每一个头都需要乘上不同的Wq,Wk,Wv,下图是八头注意力机制处理的一个示例,步骤如下:
1)输入序列
2)使用Embedding进行数据转换映射
3)将其分成8个头,用权重矩阵乘以X或R
4)使用所得的Q/K/V矩阵计算注意力
5) 将得到的Z矩阵连接起来,然后与权重矩阵W相乘,得到该层的输出
但在实际处理过程中,我们并不会对每个头都使用不同的矩阵Wq,Wk,Wv,以二头注意力机制为例,

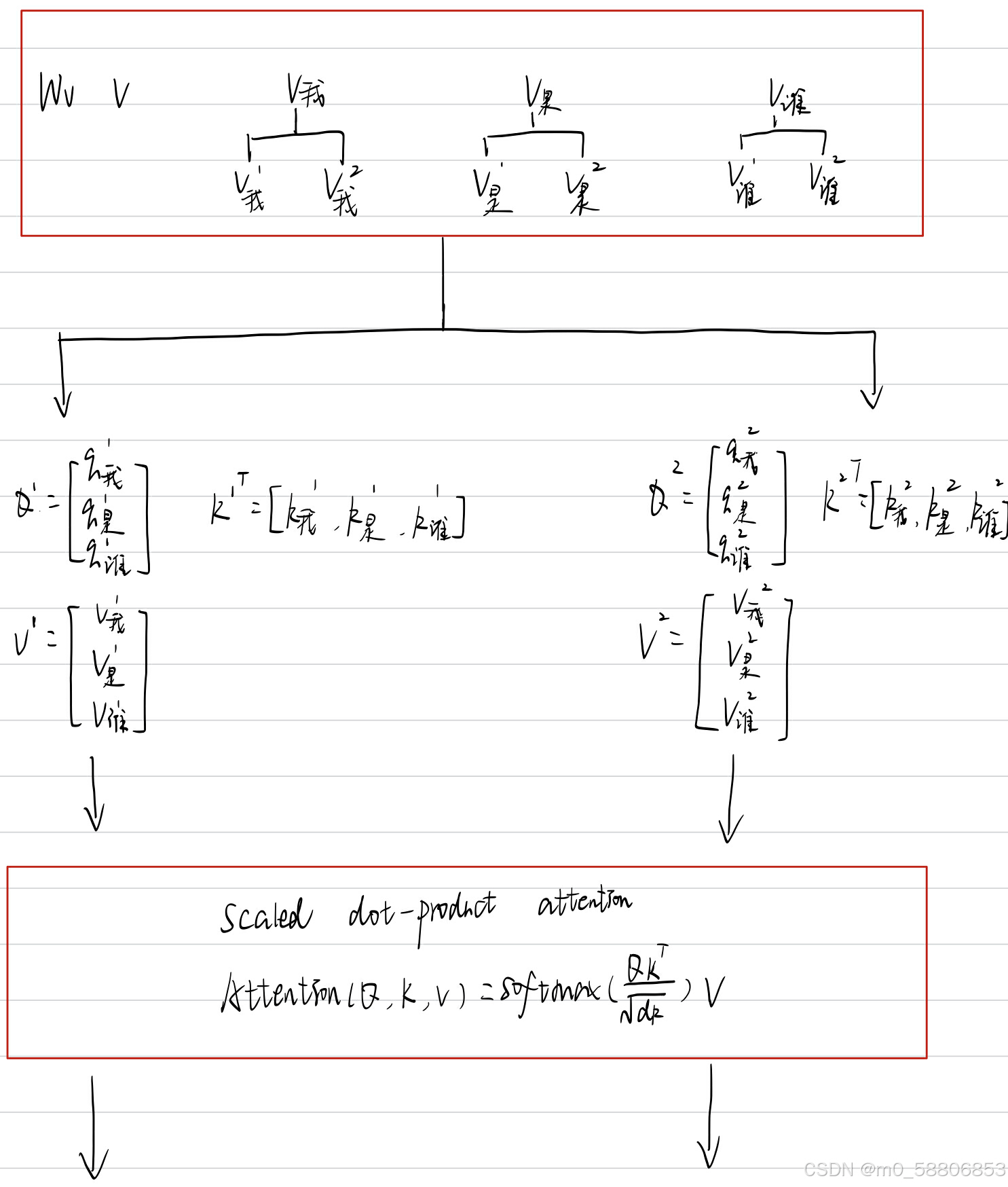

多头保证了attention可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。在使用自注意力计算相关性的时候,就是用q去找相关的k。但是相关有很多种不同的形式,所以也许可以有多个 q,不同的q 负责不同种类的相关性。
自回归解码器
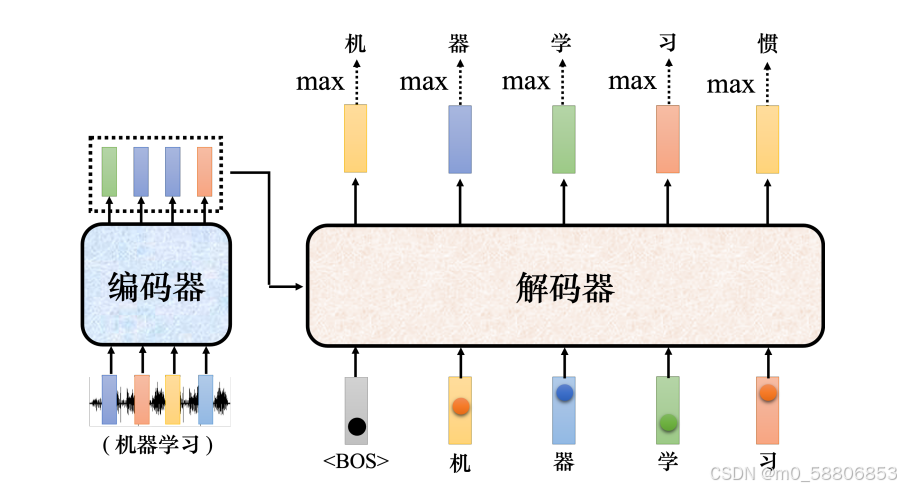
解码器比较常见的称为自回归的(autoregressive)解码器,以语音识别为例,输入一段声音,输出一串文字。把一段声音(“机器学习”)输入给编码器,输出会变成一排向量。接下来解码器产生语音识别的结果,解码器把编码器的输出先“读”进去。
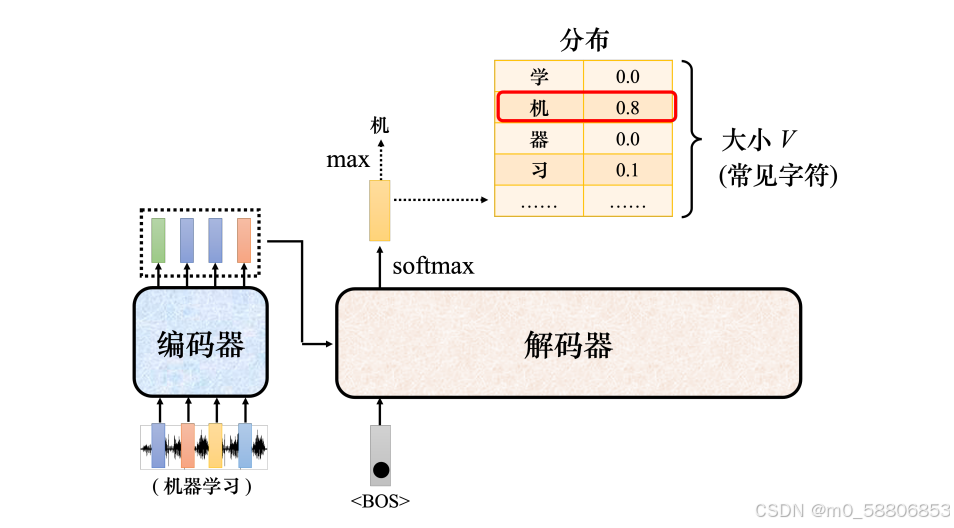
要让解码器产生输出步骤如下:
1)首先要先给它一个代表开始的特殊符号BOS,即Begin Of Sequence,这是一个特殊的词元(token)。
2)在词表(vocabulary)里面,在本来解码器可能产生的文字里面多加一个特殊的符号BOS。
在机器学习中,假设要处理自然语言处理的问题,每一个词元都可以用一个独热的向量来表示。独热向量其中一维是 1,其他都是 0,所以 BOS也是用独热向量来表示,其中一维是 1,其他是 0。
3)解码器会输出一个向量,该向量的长度跟词表的大小是一样的。
在产生这个向量之前,跟做分类一样,通常会先进行一个softmax操作。这个向量里面的分数是一个分布,该向量里面的值全部加起来,总和是 1。这个向量会给每一个中文字一个分,分数最高的中文字就是最终的输出。“机”的分数最高,所以“机”就当做是解码器的第一个输出。
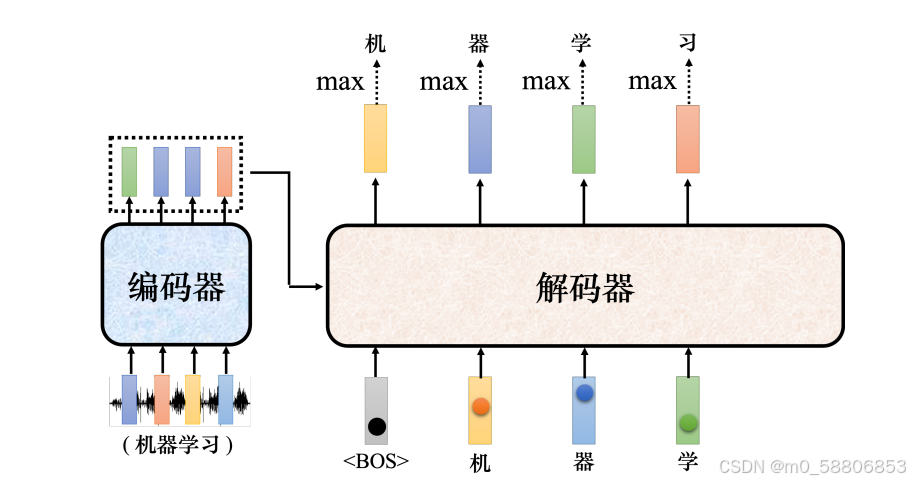
4)接下来把“机”当成解码器新的输入。根据两个输入:特殊符号BOS和“机”,解码器输出一个蓝色的向量。蓝色的向量里面会给出每一个中文字的分数,假设“器”的分数最高,“器”就是输出。解码器接下来会拿“器”当作输入,其看到了BOS、“机”、“器”,可能就输出“学”。解码器看到BOS、“机”、“器”、“学”,它会输出一个向量。这个向量里面“习”的分数最高的,所以它就输出“习”。这个过程就反复地持续下去。
到此我们可能有个问题:解码器输出的单位是什么?
假设做的是中文的语音识别,解码器输出的是中文。词表的大小可能就是中文汉字的数量。不同的语言,输出的单位不一定会不一样,这取决于对语言的理解。比如英语,选择输出英语的字母。但字母作为单位可能太小了,有人可能会选择输出英语的词汇,英语的词汇是用空白作为间隔的。但如果都用词汇当作输出又太多了,有一些方法可以把英语的字首、字根切出来,拿字首、字根当作单位。中文通常用中文汉字来当作单位,这个向量的长度就跟机器可以输出汉字的数量是一样多的。每一个中文的字都会对应到一个数值。
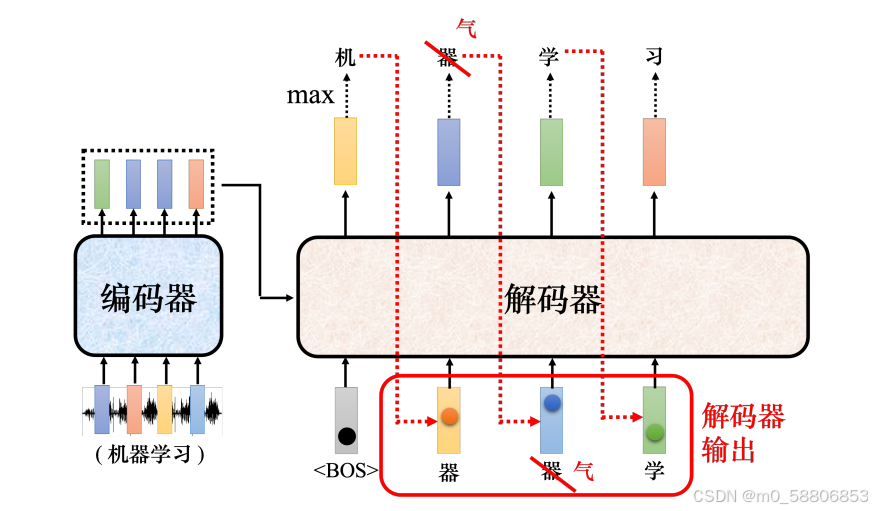
解码器的输入是它在前一个时间点的输出,其会把自己的输出当做接下来的输入,因此当解码器在产生一个句子的时候,它有可能看到错误的东西。如上图所示,如果解码器有语音识别的错误,它把机器的“器”识别错成天气的“气”,接下来解码器会根据错误的识别结果产生它想要产生的期待是正确的输出,这会造成误差传播的问题,一步错导致步步错,接下来可能无法再产生正确的词汇。
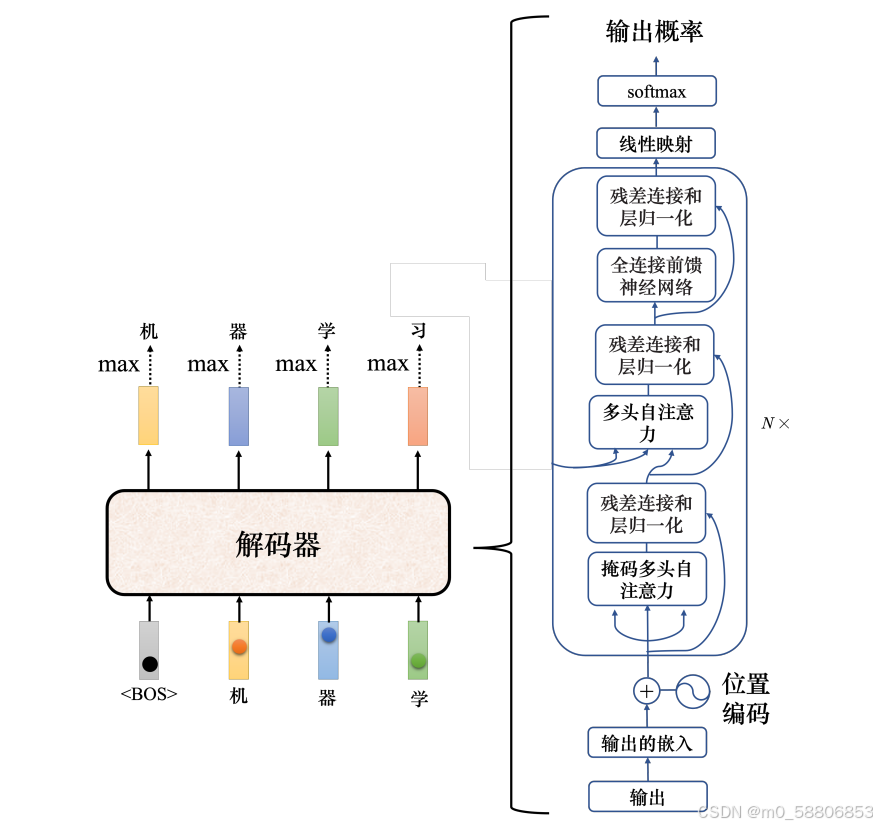
解码器的内部结构:
Transformer 里面的解码器内部的结构如下图所示。类似于编码器,解码器也有多头注意力、残差连接和层归一化、前馈神经网络。解码器最后再做一个 softmax,使其输出变成一个概率。此外,解码器使用了掩蔽自注意力,掩蔽自注意力可以通过一个掩码(mask)来阻止每个位置选择其后面的输入信息。
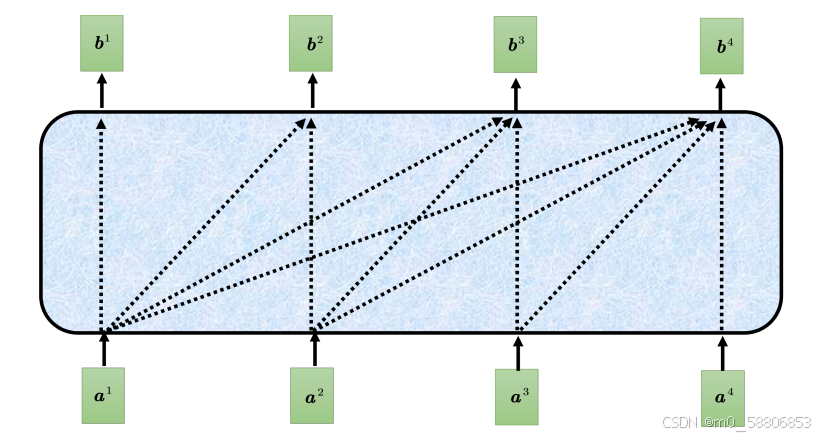
原来的自注意力输入一排向量,输出另外一排向量,这一排中每个向量都要看过完整的输入以后才做决定。根据 a1到 a4所有的信息去输出b1。而掩蔽自注意力的不同点是不能再看右边的部分,产生吧b1的时候,只能考虑a1的信息,不能再考虑a2、a3、a4。产生b2的时候,只能考虑a1、a2的信息,不能再考a3、a4
的信息。b3,b4以此类推。
掩蔽自注意力的计算过程如下图所示,我们只拿q2和k1、k2计算注意力,最后只计算v1跟v2的加权和。不管a2右边的地方,只考虑 a1、a2、q1、q2、k1以及k2。输出b2的时候,只考虑了a1 和a2,没有考虑a3和 a4。
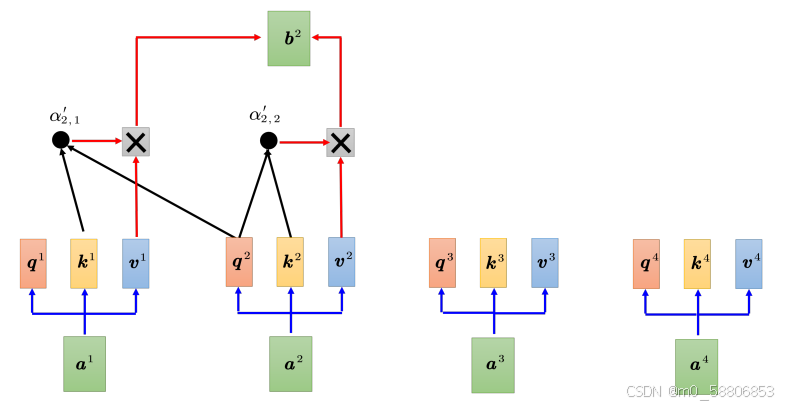
需要在注意力中加入mask的原因:
一开始解码器的输出是一个一个产生的,所以是先有a1再有a2,再有a3,再有a4。这跟原来的自注意力不一样,原来的自注意力a1跟a4是一次整个输进去模型里面的。编码器是一次把 a1跟a4都整个都读进去。但是对解码器而言,先有a1才有a2,才有a3才有a4。所以实际上当我们有a2,要算b2 的时候,没有a3跟a4的,所以无法考虑a3和a4。解码器的输出是一个一个产生的,所以只能考虑其左边的东西,没有办法考虑其右边的东西。
了解了解码器的运作方式,但这还有一个非常关键的问题:实际应用中输入跟输出长度的关系是非常复杂的,我们无法从输入序列的长度知道输出序列的长度,因此解码器必须决定输出的序列的长度。给定一个输入序列,机器可以自己学到输出序列的长度。但在目前的解码器运作的机制里面,机器不知道什么时候应该停下来,如下图所示,机器产生完“习”以后,还可以继续重复一模一样的过程,把“习”当做输入,解码器可能就会输出“惯”,接下来就一直持续下去,永远都不会停下来。
要让解码器停止运作,需要特别准备一个特别的符号EOS。产生完“习”以后,再把“习”当作解码器的输入以后,解码器就要能够输出EOS,解码器看到编码器输出的嵌入、EOS、“机”、“器”、“学”、“习”以后,其产生出来的向量里面EOS的概率必须是最大的,于是输出 EOS,整个解码器产生序列的过程就结束了。

总结
transformer是非常重要的模块,现在的学习还远远不够,在后续的时间里我会继续对其进行相关的学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









