










文章末尾,添加公众号,领取完整代码
当我们在使用YOLO算法进行训练数据的时候,会遇到字体无法下载或者无法使用的问题,本人在使用的过程中也是遇到过这样的麻烦,如下图所示
Downloading https://ultralytics.com/assets/Arial.ttf to /home/zelan/.conf根据报错信息可得:这是因为我们在下载字体的时候出现了网络问题,具体原因可以在genera.py中进行查看。
那么解决这个问题有以下几种办法(查了很多资源,都没有一个可靠的解决办法)。本人根据自己的摸索共计总结了以下几点(亲测可用)。觉得有用点个赞关注就行!
1、通用的方法
所谓通用的方法就是出现什么问题解决问题。既然是下载不了,那就想办法下载
1.1 magic,具体不细讲。
1.2 根据下面这个链接下载到本地,然后该放哪儿放哪儿。
下载链接 https://ultralytics.com/assets/Arial.ttf
2、针对于YOLOV5 5.0\6.0
找到plot.py文件,大约在64行左右
class Annotator:
if RANK in (-1, 0):
check_font() # download TTF if necessary
# YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
self.pil = pil or not is_ascii(example) or is_chinese(example)
if self.pil: # use PIL
self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
self.draw = ImageDraw.Draw(self.im)
self.font = check_font(font='Arial.Unicode.ttf' if is_chinese(example) else font,
size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
else: # use cv2
self.im = im
self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width将下面的代码注释掉,完事。
# if RANK in (-1, 0):
# check_font() # download TTF if necessary
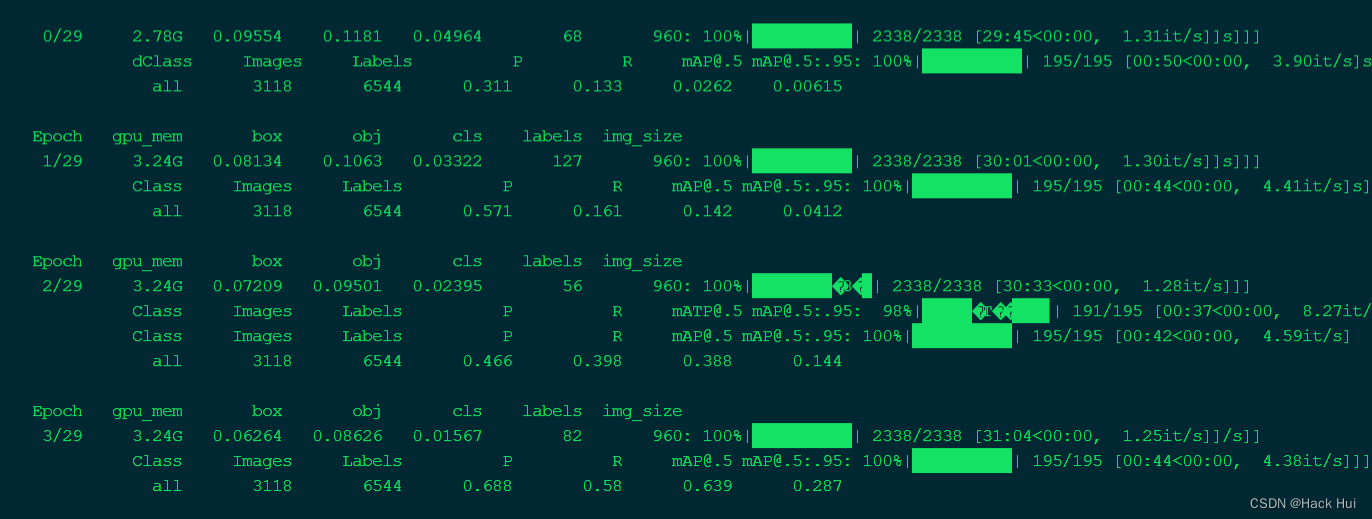
成功运行啦,哇哈哈哈!




















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











