






 这篇博客详细介绍了Pandas中的Series和DataFrame操作,包括根据列表和数组创建Series,DataFrame的创建、列操作、行操作、添加操作、排序、转置、分组和数据合并等,涵盖了从基础到进阶的多种功能。
这篇博客详细介绍了Pandas中的Series和DataFrame操作,包括根据列表和数组创建Series,DataFrame的创建、列操作、行操作、添加操作、排序、转置、分组和数据合并等,涵盖了从基础到进阶的多种功能。
1.创建Series
1.1 根据列表创建
# 根据列表创建
list=["a","b","c"]
s=pd.Series(list)
s.index # 输出0 1 2
s.values # 输出a b c
# 将第二个值修改为d
s[1]="d"1.2 根据数组创建
# 根据字典创建
dic = {"a":1,"b":2,"c":3}
s=pd.Series(dic)
s.index # 输出a b c
s.values # 输出1 2 31.3 切片
s1= pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
s1["b":"d"] #输出b c d 行
s1[1:3] # 输出b c 行1.4 删除与添加
s = pd.Series(np.random.rand(5),index=list("abcde"))
# 删除a那一行
s1 = s.drop("a",inplace=True)
# 增加a那一行
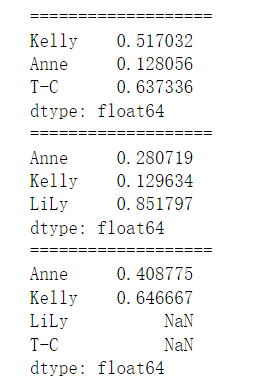
s["a"]=100 ps.s1+s2执行的是对齐运算
s1 = pd.Series(np.random.rand(3), index=["Kelly","Anne","T-C"])
s2 = pd.Series(np.random.rand(3), index=["Anne","Kelly","LiLy"])
print("===================")
print(s1)
print("===================")
print(s2)
print("===================")
print(s1+s2) ##对不齐的地方补null结果:
2.DataFrame
2.1 DataFrame的创建
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
index = ["rank1", "rank2", "rank3", "rank4"]
df = pd.DataFrame(data, index=index)2.2 列操作
# 添加新的一列名为socore
df.insert(1,column='score',value=[80,70,90,100])
# 删除指的的列
del df['score'] ##单独删除该行2.3 行操作
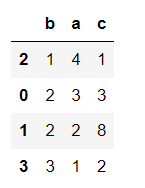
创建数据表:
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},
index=["2","0","1","3"]
) 
#### 选取某行
data.loc["2"]
data.iloc[0]
#选取第0行,第1行
df.iloc[[0,1]]
#选取第0行第1列
df.iloc[0,1]
#选取所有行,第一列,第二列
df.iloc[:,[0,1]]
df.loc["2":"1"]
df.loc[["2","1"],"b"] 2.4 添加操作
df1=pd.DataFrame({"a":[1,2,3],
"b":[4,5,6],
"c":[7,8,9]
})
df2=pd.DataFrame({"a":[4,5,6],
"b":[7,8,9],
"d":[10,11,12]
})
df1.append(df2,ignore_index=True) # 重新索引 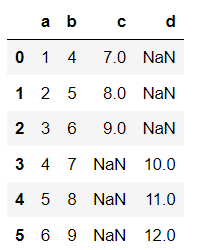
2.5 排序
df.sort_index() #默认按行索引排序
df.sort_index(axis=1) #按列索引排序 

(1)原表格 (2)行索引排序 (3)列索引排序
# 将b列从小到大排序
df.sort_values(by="b")
# 将3行升序排列
df.sort_values(by=3,axis=1) # axis=1不能省
# 先按a升序,再按b降序
df.sort_values(by=["b","a"],ascending=[True,False])2.6 转置操作
df.T2.7 分组操作
已知表格:
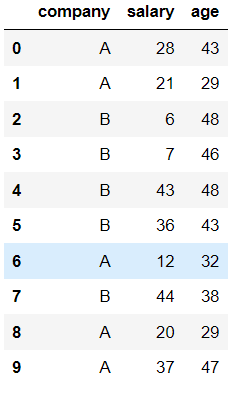
# 按照公司进行分组
data = data.groupby("company") 
# 先分组,再聚合
data = data.groupby("company").agg({"salary":"median","age":"mean"}) 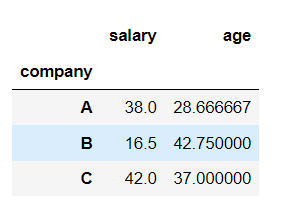
# 求各个公司的平均薪水并添加为新的一列
data["salary_avg"]=data.groupby("company")["salary"].transform("mean")# 求每个公司最老的员工
def oldest_emp(x):
data= x.sort_values(by="age")
return data.iloc[-1]
oldest = data.groupby("company").apply(oldest_emp)
oldest2.8 数据合并
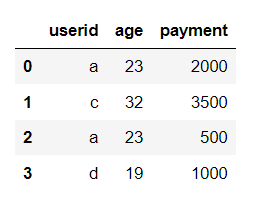
已知两个表格:
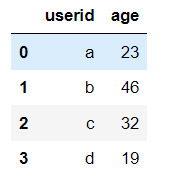

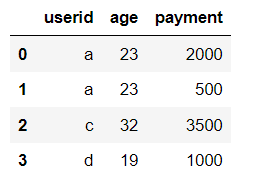
# 内连接
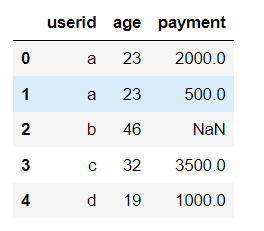
pd.merge(df1, df2, on="userid")
# 左连接
pd.merge(df1,df2,how="left",on="userid")
# 右连接
pd.merge(df1,df2,how="right",on="userid")
# 外连接
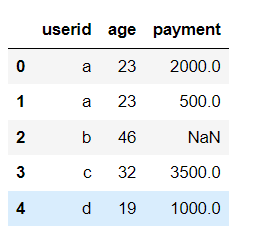
pd.merge(df1,df2,how="outer",on="userid")
从左到右依次为内/左/右/外连接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









