







二、数据预处理
前两节加载数据后,可能需要对数据进行数据预处理操作,不同格式分开展示。
将原始数据转换为适合分析和建模的格式,提高数据质量,确保模型的准确性和可靠性。
2、时间序列数据预处理。
有可能需要补缺失值、去噪、调整数据格式等,以下为调整数据格式为所需格式,timeseries_dataset_from_array()会返回一个Dataset实例。
tf.keras.preprocessing.timeseries_dataset_from_array(
data,
targets,
sequence_length,
sequence_stride=1,
sampling_rate=1,
batch_size=128,
start_index=None,
end_index=None,
shuffle=False,
seed=None,
dtype=None
)
参数说明:
data:接收int、float类型值,表示要转换的原始时间序列数据,里面的每个叫做一个timestep。
targets: 接收int、float类型值,(如果不处理标签只处理数据,传入targets=None)表示目标值,和data长度一样。
sequence_length: 接收int类型值,一个输出序列sequence的长度,即有多少个timestep。
sequence_stride:接收int类型值,表示连续输出序列的周期。
sampling_rate: 接收int类型值,连续timestep之间的时间间隔
batch_size: 每个批次中的时间序列样本数。
shuffle:bool类型,表示随机输出样本还是按时间顺序输出样本。
seed:int类型,表示随机种子。
start_index: int类型,数据点早于start_index不输出。
end_index: int类型,数据点晚于end_index不输出。
第一种:不传递targets:
import tensorflow as tf
import numpy as np
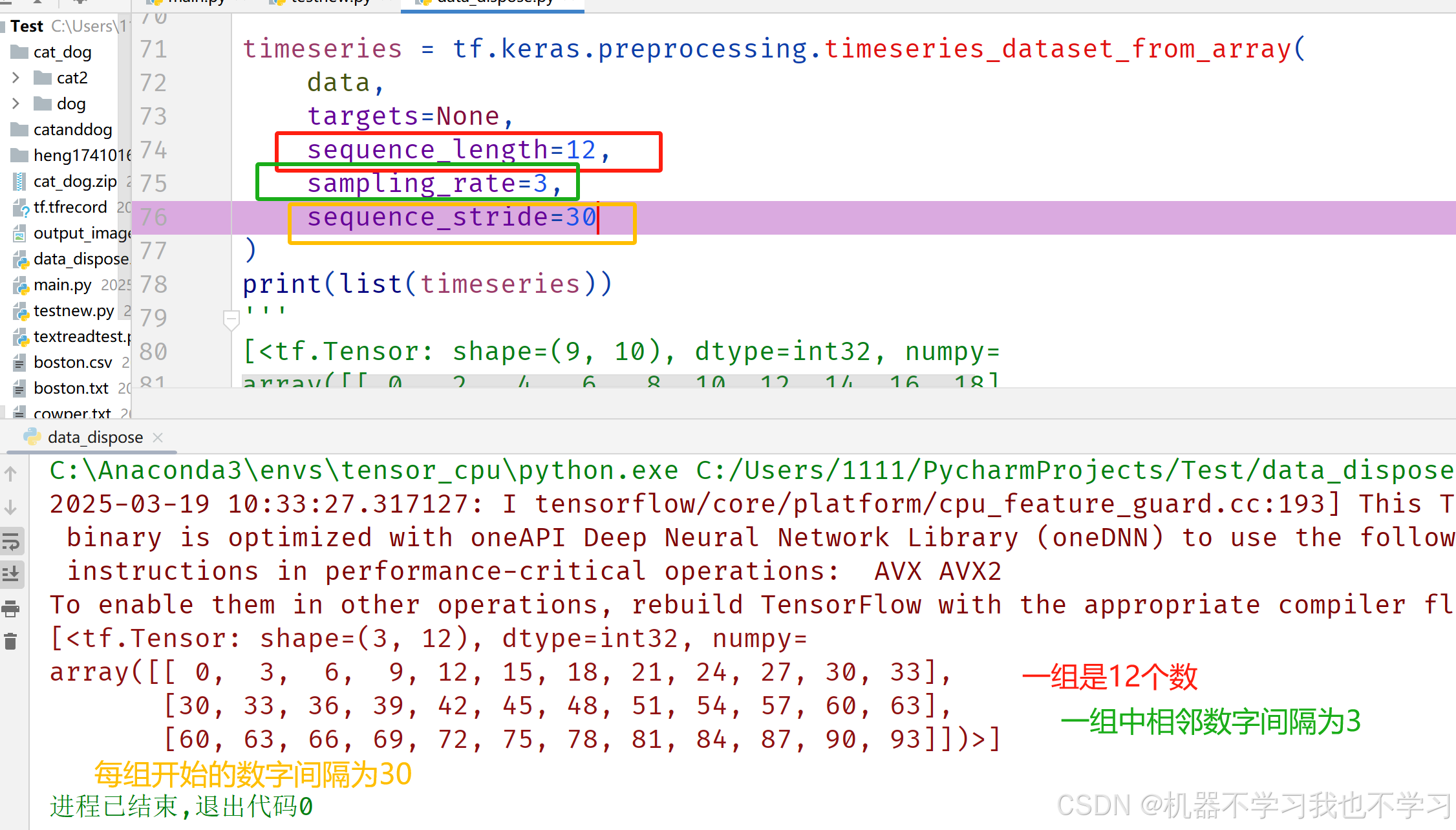
data = np.array([i for i in range(100)]) # [0,1,...,99]
timeseries = tf.keras.preprocessing.timeseries_dataset_from_array(
data,
targets=None,
sequence_length=12,
sampling_rate=3,
sequence_stride=30
)
print(list(timeseries))
结果如下:
第二种:传递targets
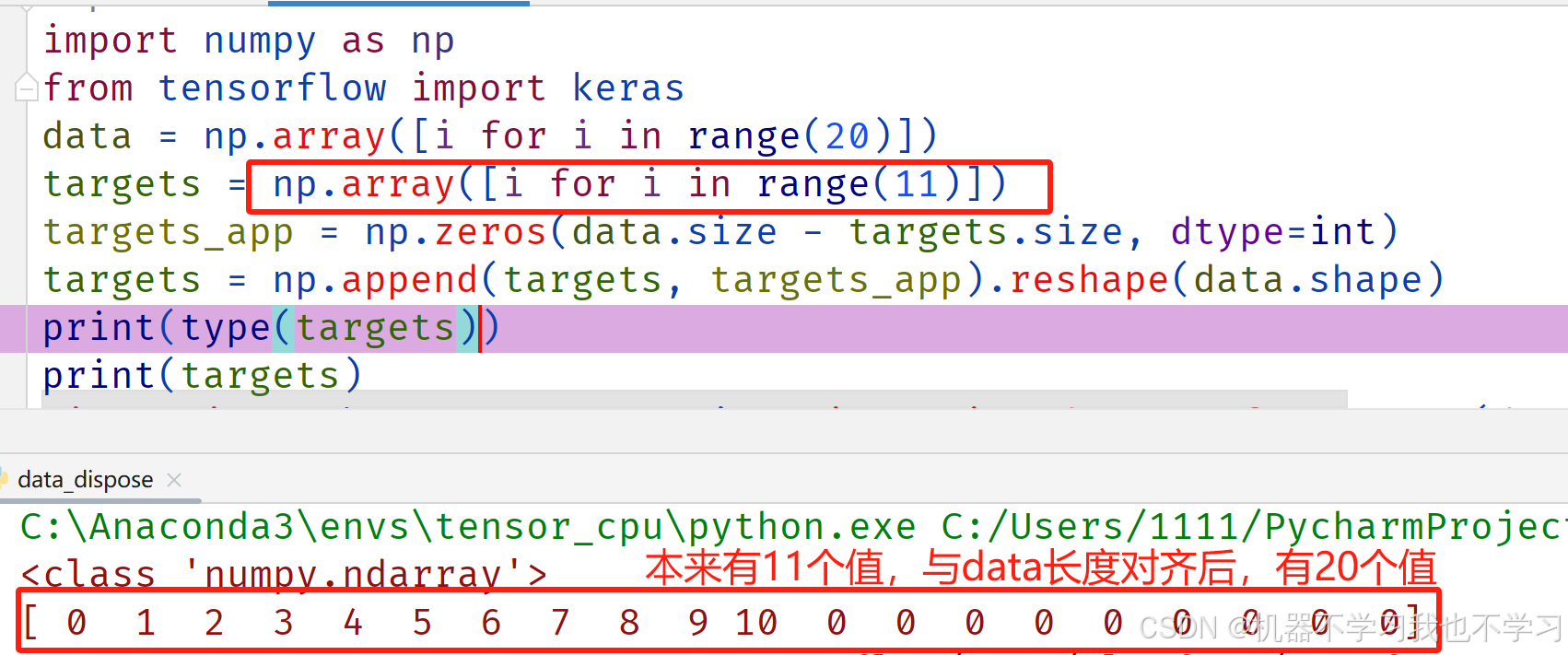
import numpy as np
from tensorflow import keras
data = np.array([i for i in range(20)])
targets = np.array([i for i in range(11)])
targets_app = np.zeros(data.size - targets.size, dtype=int)
#为保证每个样本均有一个对应的标签,需要调整targets与data的长度一致
targets = np.append(targets, targets_app).reshape(data.shape)
print(type(targets))
print(targets)
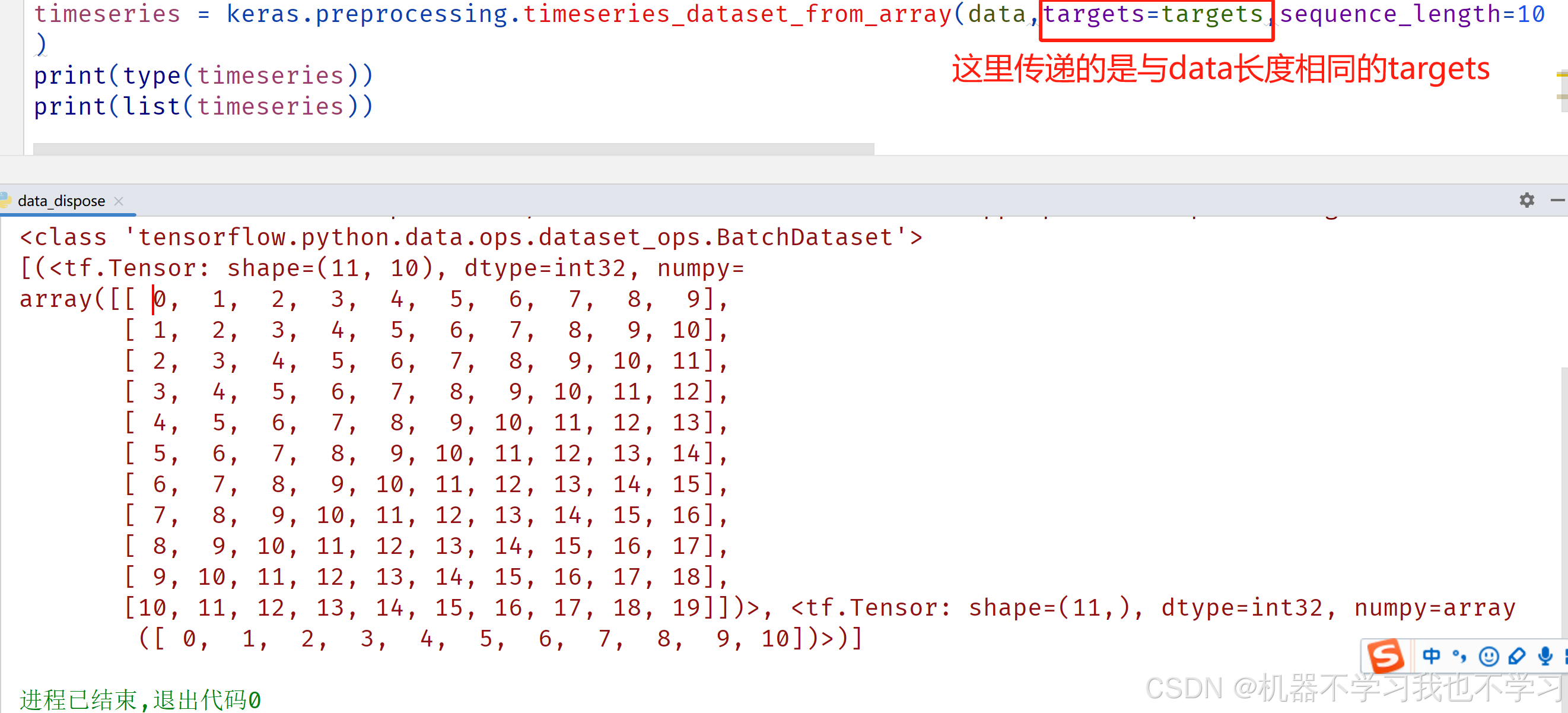
timeseries = keras.preprocessing.timeseries_dataset_from_array(data,targets=targets,sequence_length=10
)
print(type(timeseries))
print(list(timeseries))
结果如下:

















 5020
5020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









