






前言:随着互联网时代的不断发展,每个人或事物产生的数据也在不断增加。在这个基础上,人们对数据的清洗与储存的需求也越来越高。在这个时候,hadoop生态圈的提出极大的解决了这些问题。hadoop作为现在主流的分布式文件存储系统,其具有高可用、高扩展、高容错、低成本等一系列优点。本文将从虚拟机的部署开始来直至hadoop的搭建成功。后续还会不断更新hadoop生态圈中的其他组件。
目录
一 准备工作:
软件:windows系统下的vmvare。用于虚拟机的搭建与系统配置。
Windows系统下的xshell传输工具,用于Windows本机系统与虚拟机间文件传输
hadoop搭建中各软件包:
centos虚拟镜像
链接:https://pan.baidu.com/s/1GKBDbZB_H7dd-DyIylGizg
提取码:1949
java软件包
链接:https://pan.baidu.com/s/1HrryTCBvWDDFpF3YBHOI-w
提取码:1949
hadoop软件包
链接:https://pan.baidu.com/s/1pWZJBTmE5JdMYO0PH3iK8g
提取码:1949
首先使用Vmvare搭配centos镜像搭建出一个虚拟机hadoop130并设置最小化配置。并且在安装过程中设置一个将用户,本文将用bbu来使用。详细流程查看我的虚拟机安装文章。
二 虚拟机网络配置
克隆虚拟机hadoop130两次,并分别命名为hadoop131、hadoop132
查看linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
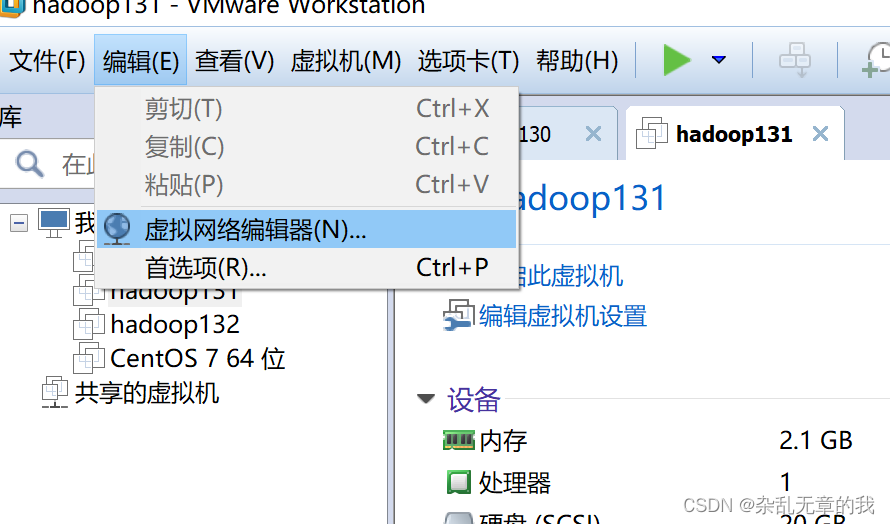
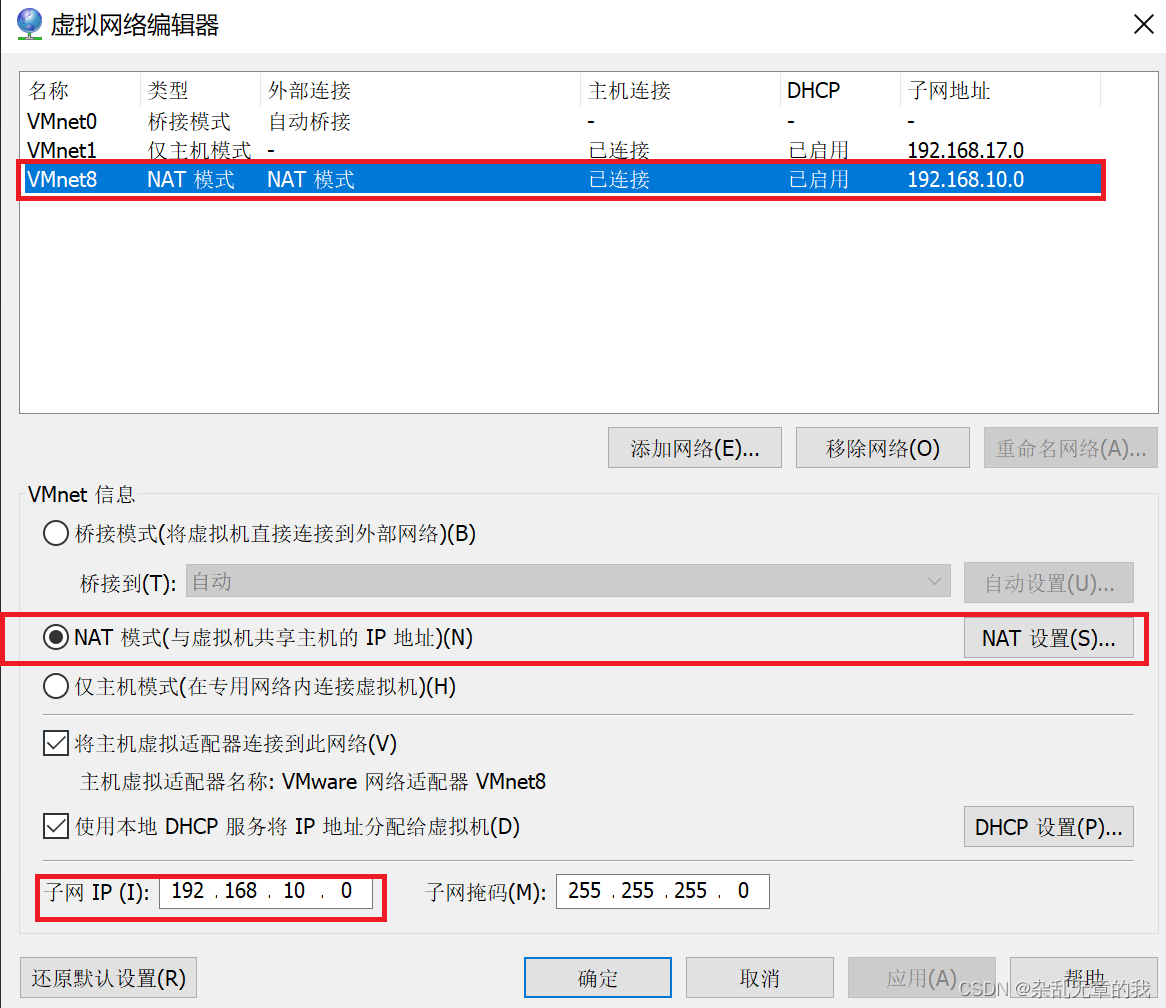
一定要记住自己的子网ip,后面的虚拟机网络ip设置必须在该网关下。本文设置为192.168.10.0。
接着进入NAT设置中将网关ip设置在同一网段
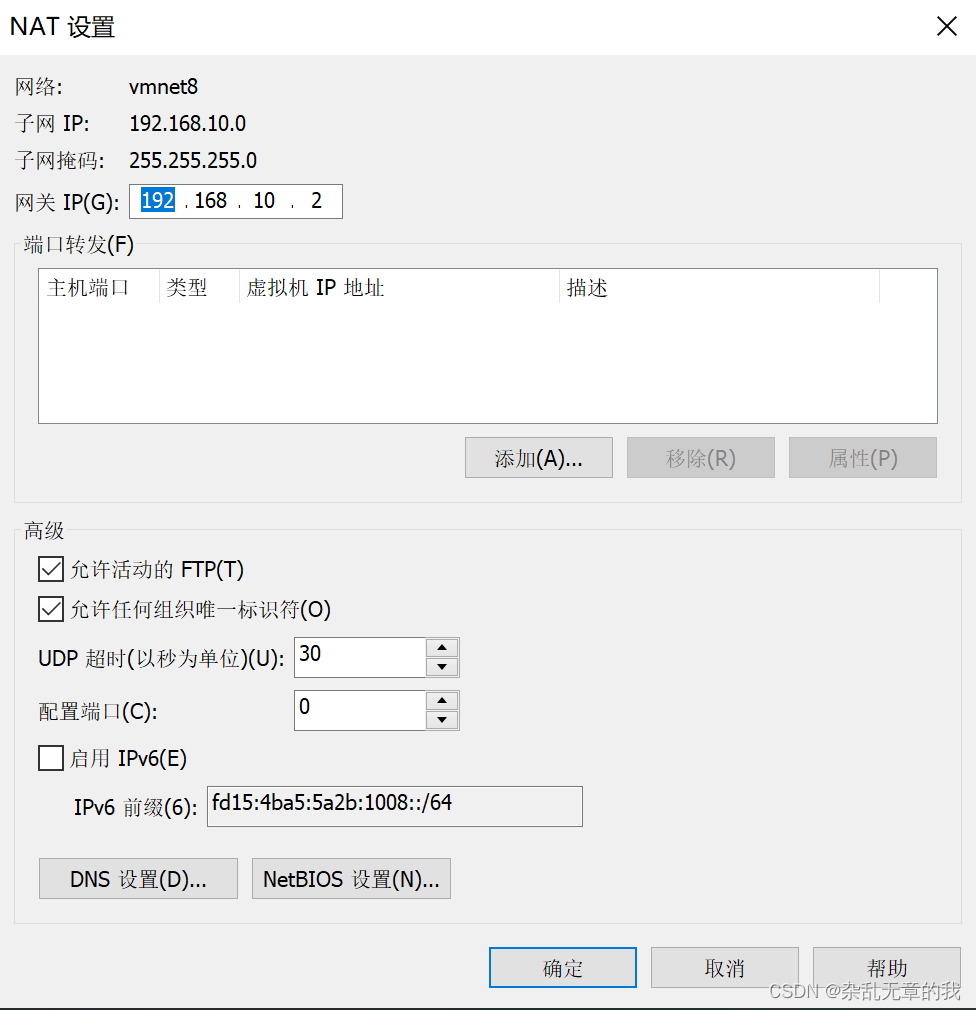
点击确认虚拟机网段就设置完毕。
配置本机电脑Windows下的网络:
设置->网络和Internet->更改适配器选项->VMnet8
双击对VMnet8进行设置
VMnet8->属性->ipv4对其默认网关进行设置,设置为跟虚拟机的一致。192.168.10.2
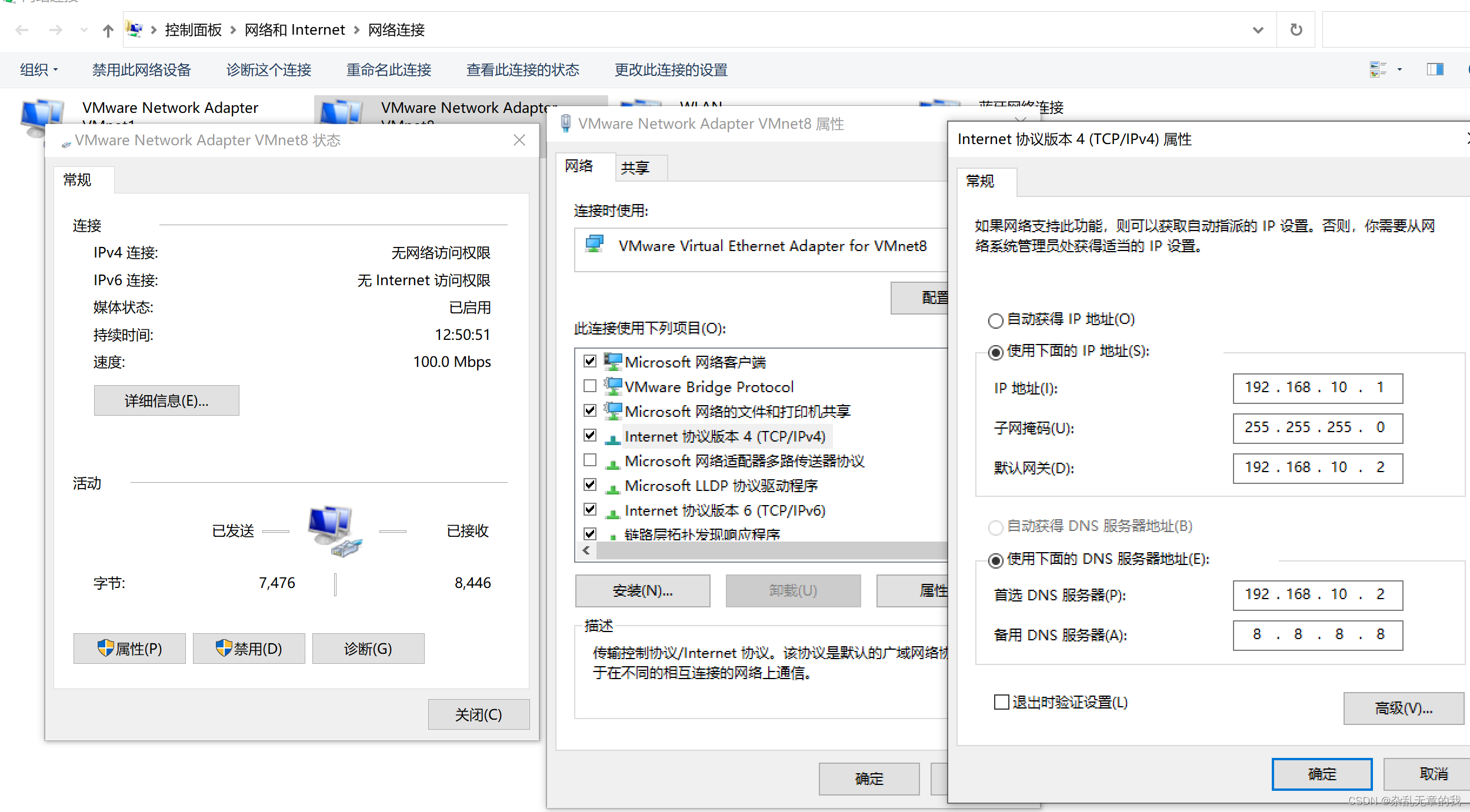
现在对网络的配置已经初步完成,接下来对虚拟机网络文件进行更改。
三 虚拟机网络配置文件修改
启动虚拟机,并且切换用户为root。打开终端,使用命令查看用户网络名称
su root
#该命令用于切换root用户,且运行该命令后。密码的输入不是明文显示,屏幕不会出现任何变化。
ifconfig
# ifconfig 命令用来查看和配置网络设备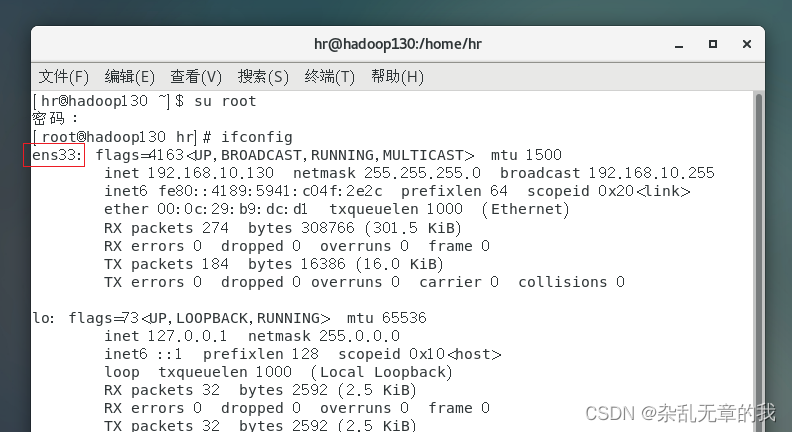
可以查看到该设备网络设备名称为ens33。
进入ens33网络配置文件对其进行修改。
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#vim用于编辑ifcfg-ens33文件,进入文件后点击i键对文件进行修改。
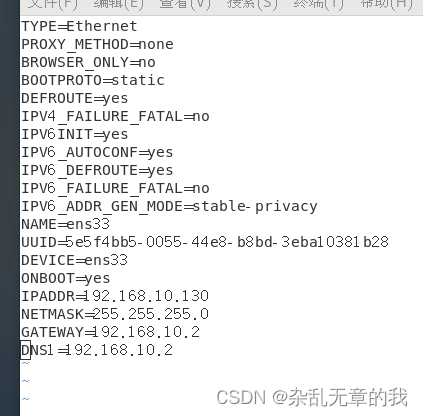
命令执行后将看到如下配置,对标注红线的部分进行修改。
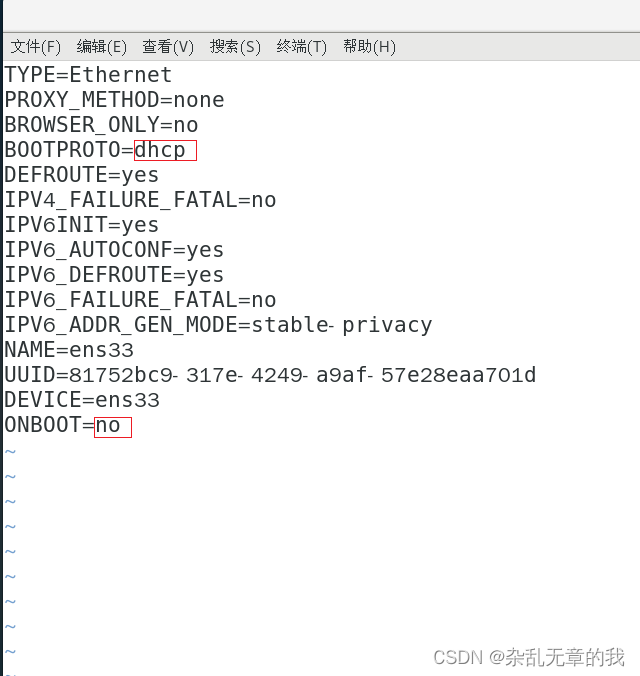
BOOTPROTO=dhcp是指在每一个重启时会动态给其分配一个ip地址。将其修改为static。
ONBOOT=no是用于系统启动的时候网络接口是否有效(yes/no)。将其修改为yes
接下来对其添加如下配置:
#ip地址
IPADDR=192.168.10.130
#子网掩码
NETTASK=255.255.255.0
#网关
GATEWAY=192.168.10.2
#域名解析器
DNS1=192.168.10.2修改后的文件保存后退出(退出vim编辑器,首先点击esc,然后wq 保存退出)
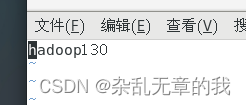
配置主机名称:
vim /etc/hostname我的主机名称都是跟ip地址一致,我设置为hadoop130
重启虚拟机
reboot测试是否能ping通外网
ping www.baidu.com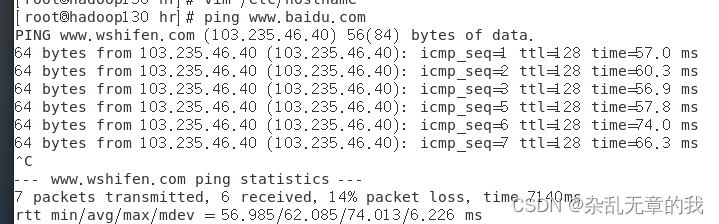
可以成功ping通外网,说明网络设置成功。
hadoop131与hadoop132与上述过程基本相同。在ip地址设置时分别设置为192.168.10.131与192.168.10.132。同时设置对应的主机名称。
四 JDK安装
(1)卸载现有JDK
注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK。如果系统本身就是最小化安装,则不需要进行卸载。直接安装即可。
(2)创建文件存储位置
本文是在opt下创建的software用于存储软件,在opt下创建的module用于存储解压后的文件
首先将对应使用的java文件包与hadoop文件包通过xshell传输至虚拟机上。
(3)文件解压与安装
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
#解压jdk-8u212-linux-x64.tar.gz文件至opt/module目录下。
当解压缩完毕后,配置对应jdk环境变量。
为了防止用户配置的环境变量与系统环境变量冲突。用户可以在profile.d文件夹中创建自己的文件配置环境变量。
cd /etc/profile.d/
#进入profile.d文件中
sudo vim my_env.sh
#my_env.sh是用户自己确定的名字,名称不影响后续使用。进入my_env.sh文件后,添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin配置完后要重启一下服务
source /etc/profile然后输入Java命令查看是否安装成功。
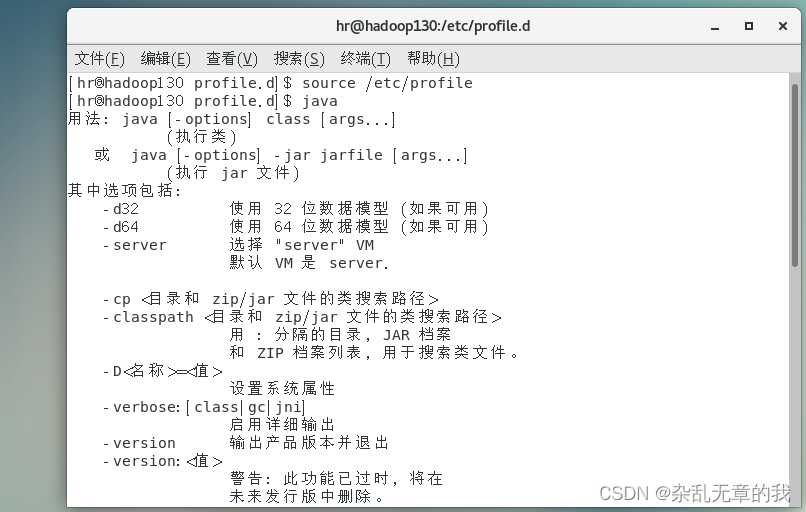
出现此页面即说明Java安装成功。
五 hadoop安装
解压hadoop至文件夹module中
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
#解压hadoop-3.1.3.tar.gz文件至opt/module目录下。
配置hadoop环境变量,仍然在my_env.sh中进行添加
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin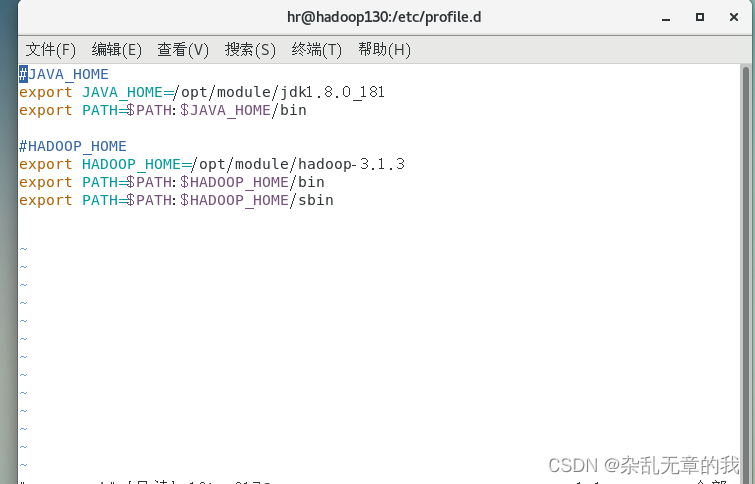
配置完毕后,退出文件重启服务
source /etc/profile重启后再命令行输入hadoop查看是否安装成功。
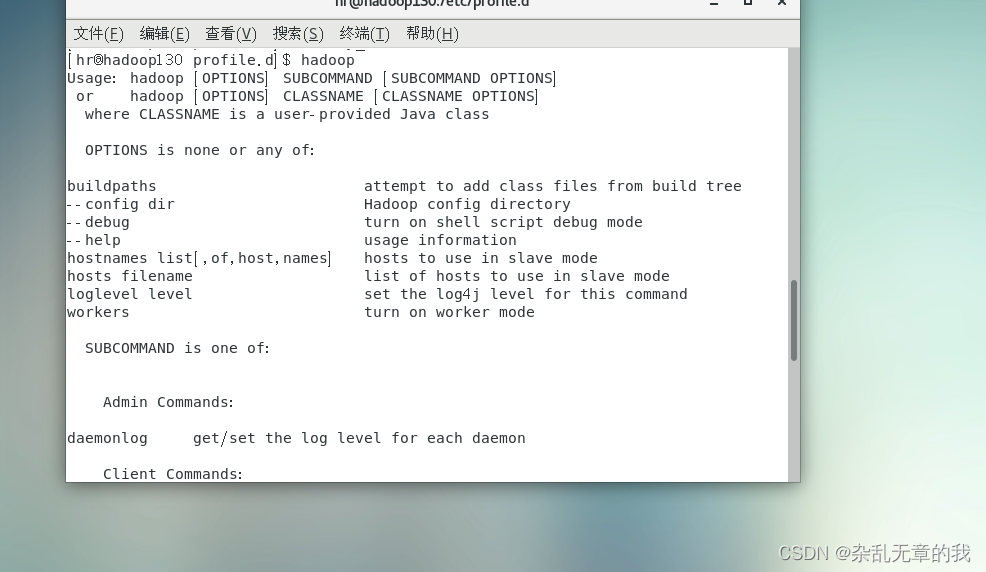
出现如上图一样的效果则说明安装成功。
后续集群配置与安装将不断持续更新。如果有什么问题可以在评论区留言。谢谢观看。


















 2553
2553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











