






关于 GaussDB 数据库中 MERGE INTO 操作
一、什么是 MERGE INTO?
MERGE INTO 是 GaussDB 提供的一种高效数据整合操作,用于将两个表(源表和目标表)的数据根据匹配条件进行合并。其核心功能是 插入、更新或删除目标表中的数据,从而实现数据的同步、去重或增量加载。
该操作特别适合以下场景:
数据仓库的 ETL 流程:将多个源表的数据合并到目标表。
增量数据同步:仅更新目标表中发生变化的数据。
去重与合并:合并重复数据并保留最新或特定条件下的数据。
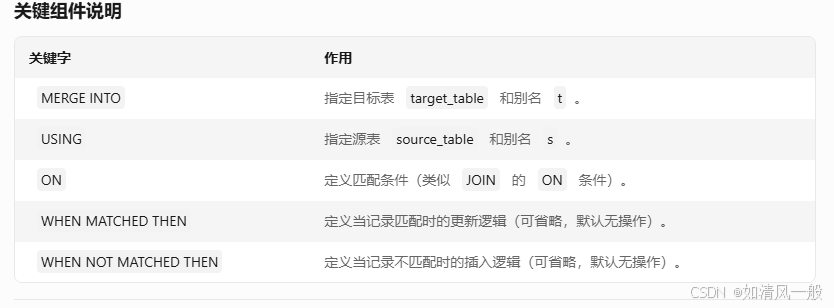
二、语法结构
GaussDB 的 MERGE INTO 语法与标准 SQL 及 Oracle 类似,但需注意其分布式特性对语法的影响:
基本语法
MERGE INTO target_table AS t
USING source_table AS s
ON t.key_column = s.key_column
WHEN MATCHED THEN
UPDATE SET t.column1 = s.column1, t.column2 = s.column2, ...
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...) VALUES (s.column1, s.column2, ...);
三、应用场景与示例
1. 数据同步(全量覆盖)
场景:将 orders_source 表的数据同步到 orders_target 表,覆盖所有冲突记录。
MERGE INTO orders_target AS t
USING orders_source AS s
ON t.order_id = s.order_id
WHEN MATCHED THEN
UPDATE SET t.amount = s.amount, t.status = s.status
WHEN NOT MATCHED THEN
INSERT (order_id, amount, status) VALUES (s.order_id, s.amount, s.status);
2. 增量数据加载
场景:仅更新目标表中存在的订单(保留最新数据)。
MERGE INTO inventory_target AS t
USING inventory_source AS s
ON t.product_id = s.product_id
WHEN MATCHED THEN
UPDATE SET t.stock = s.stock
WHEN NOT MATCHED THEN
INSERT (product_id, stock) VALUES (s.product_id, s.stock);
3. 去重与保留特定条件
场景:合并两个用户表,保留年龄最大的用户记录。
MERGE INTO users_target AS t
USING users_source AS s
ON t.user_id = s.user_id
WHEN MATCHED THEN
-- 如果源表中的年龄更大,则更新
UPDATE SET t.age = s.age WHERE s.age > t.age
WHEN NOT MATCHED THEN
INSERT (user_id, name, age) VALUES (s.user_id, s.name, s.age);
四、分布式环境下的优化
1. 分区表处理
GaussDB 支持对分区表执行 MERGE INTO,建议按分区键过滤源表数据以减少扫描范围:
MERGE INTO sales_target PARTITION BY (sale_month)
USING sales_source PARTITION (sale_month BETWEEN '2023-01' AND '2023-12')
ON t.sale_id = s.sale_id;
2. 并行执行
通过设置并行度参数(如 SET max_parallel_workers_per_gather=4)加速合并操作。
3. 避免全表扫描
索引优化:在 ON 条件的字段上创建索引(如 B 树或哈希索引)。
CREATE INDEX idx_order_id ON orders_target (order_id);
过滤条件:在 USING 子句中添加 WHERE 条件缩小源表数据量:
MERGE INTO t ...
USING s WHERE s.region = 'Asia' ... ;
五、注意事项
1. 锁争用
行级锁:MERGE INTO 默认对匹配的行加锁,高并发场景下可能导致阻塞。
解决方案:
使用低隔离级别(如 READ COMMITTED)。
将大事务拆分为小批次操作。
2. 数据倾斜
问题:分布式节点间的数据分布不均可能导致部分节点负载过高。
解决方案:
检查分区键设计是否合理。
使用 HASH 或 RANGE 分区分散热点数据。
3. 日志与监控
WAL 日志:MERGE INTO 会产生大量日志,需确保磁盘空间充足。
执行计划分析:通过 EXPLAIN 查看操作是否使用了索引:
EXPLAIN (ANALYZE, BUFFERS)
MERGE INTO t ... ;
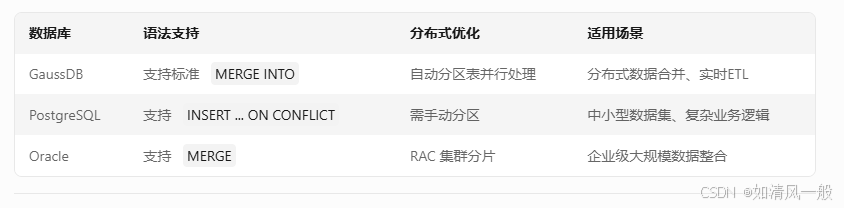
六、与其他数据库的对比
七、总结
MERGE INTO 是 GaussDB 中高效整合数据的利器,尤其在分布式场景下可通过分区表、并行执行和索引优化显著提升性能。企业需结合业务需求选择匹配的合并策略,并通过监控工具持续优化执行效率。对于超大规模数据同步,建议结合 GaussDB 的 物化视图 或 流计算服务 实现更低延迟的数据管道。

















 3315
3315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









