






慢SQL发现基于数据库的历史SQL语句,通过对历史SQL语句的执行表现进行总结归纳,将之再用于推断新的未知业务上。由于短时间内数据库SQL语句执行时长不会有太大的差距,SQLdiag可以从历史数据中检测出与已执行SQL语句相似的语句结果集,并基于SQL向量化技术和模板化方法预测SQL语句执行时长。慢SQL发现不需要SQL语句的执行计划,对数据库性能不会有任何的影响。慢SQL发现的时序执行图如下:
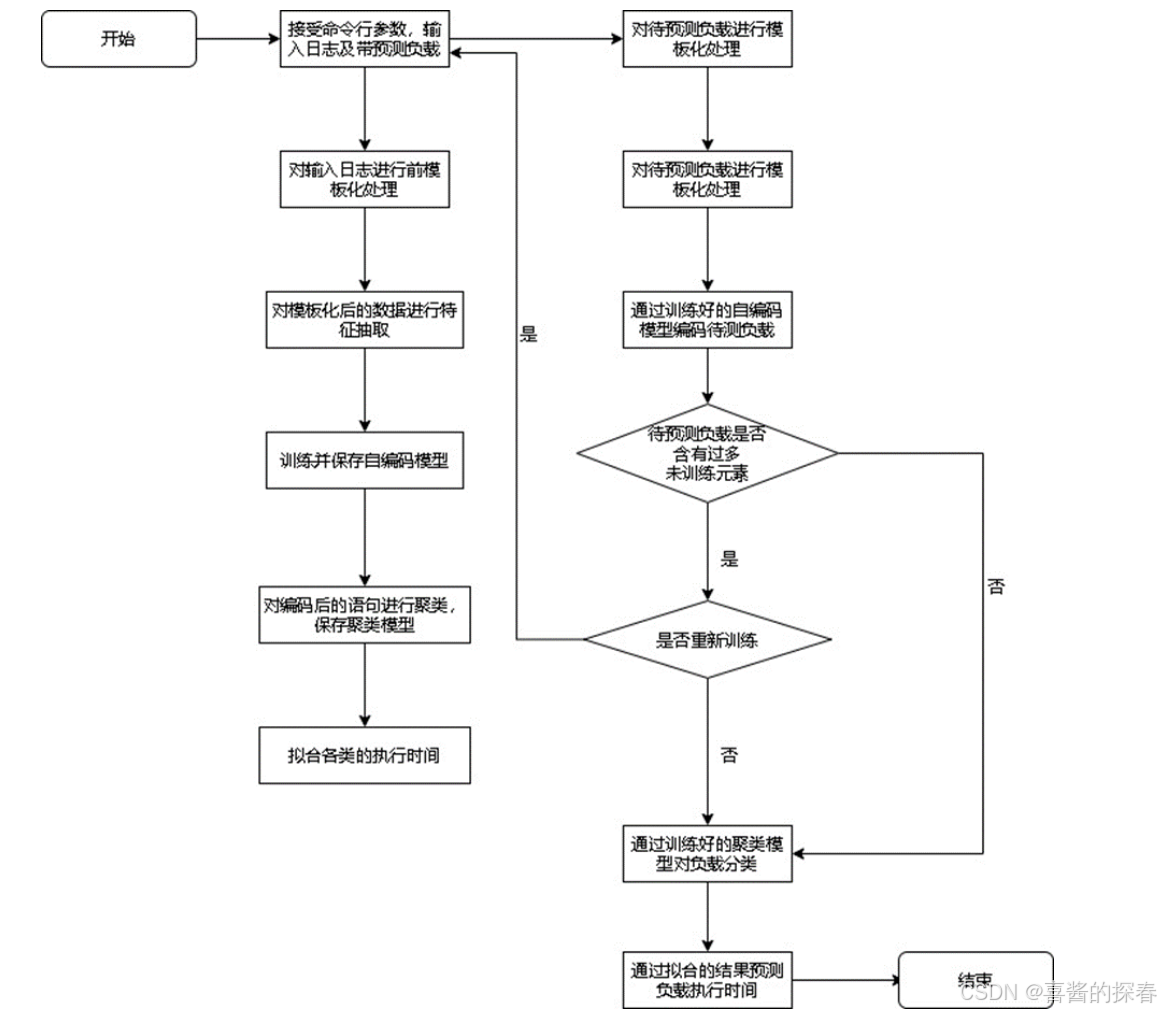
在整个慢sql发现过程中,存在两个主要步骤:训练阶段:通过用户输入的日志地址导入历史sql数据,训练自编码模型,聚类模型及执行时间序列模型。
预测阶段:用户输入待预测负载,系统根据训练阶段生成的自编码模型对待预测负载进行编码,之后根据训练阶段生成的聚类模型进行分类,进而根据每类的历史信息预测执行时间。
慢SQL发现中的训练阶段和预测阶段的详细设计如下:
(1)训练阶段前提条件:用户已导入数据,准备好自己的典型业务SQL历史记录,且输入格式为:(SQL执行时长,SQL语句,SQL锁等待时长),其中锁等待时长和SQL执行时长二者必须保证至少有一个不为0. 每一行通过跳格(TAB)分隔。 用户在Console页面输入历史日志文件的路径与希望模型文件保存的路径。前处理模块首先对日志进行前处理,抽取初级特征并对语句进行模板化,然后将模板化后的语句进行向量化处理,保存向量化过程所使用的字典。将数据集向量传入自编码模块。自编码模块对数据集数据进行自编码训练,保存自编码模型并将编码后的数据集传给聚类模块。聚类模块对编码后的数据集进行聚类,保存聚类模型。数据集在分类后,每类分别抽取所有类语句的历史执行时间记录,建立时间序列预测模型。
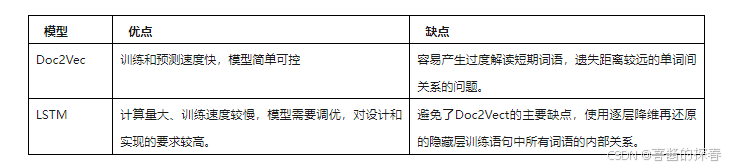
(2)预测流程前提条件:训练阶段已完成,并且用户输入的待预测负载格式正确。用户在页面输入待预测负载文件路径与结果文件保存路径。与训练阶段同样,前处理模块会对待预测负载模板化,随后读取保存的字典将模板化后的语句向量化。在此步骤中,如果前处理模块捕捉到新元素的数量大于用户设定的重训练阈值,会提示用户该情况并询问用户是否重新训练。如果选是,则会重新开始训练阶段,否则继续执行预测阶段;如果前处理模块捕捉到新元素的数量不大于用户设定的重训练阈值,执行预测阶段。读取训练阶段生成的自编码模型及聚类模型,对待预测负载进行编码后分类。使用各类的时间序列预测模型,预测待预测负载的执行时间,保存至用户指定路径。自编码器在设计时,可以采用2种不同的模型,分别为:Doc2vec:着重于前后文特征关系的文本向量化编码器。LSTM:着重于训练样本本身特征关系的向量化自编码器。模型对比如下表所示:
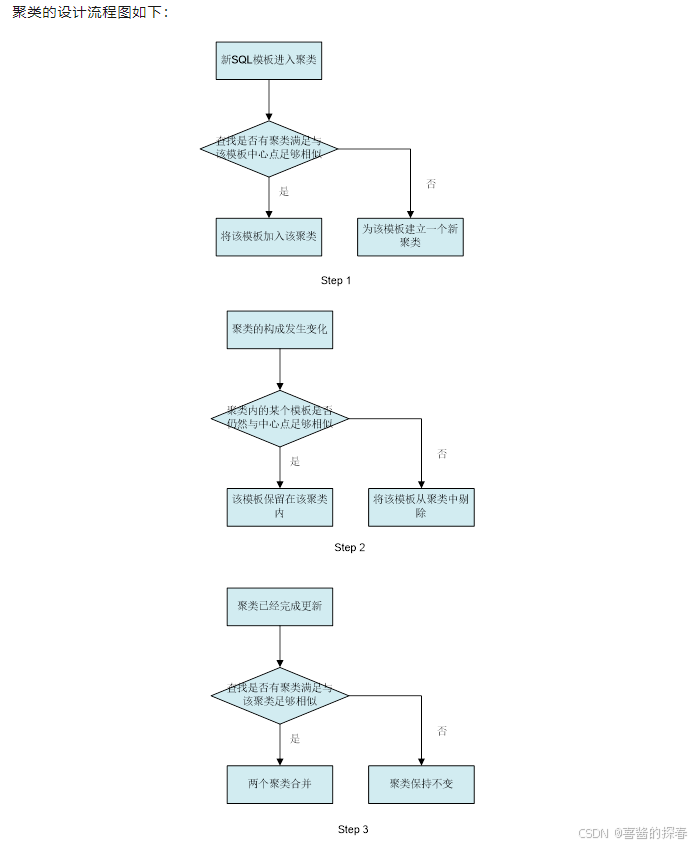
对任意一个新SQL模板,计算它的访问频次历史与现有聚类中心的距离,判断是否超过阈值。检测已聚类的模板与聚类中心点的距离,如果相似度低于阈值,则移除当前聚类。计算聚类中心之间的距离,如果超过阈值,则合并两个聚类。通过以上三个步骤可以确保该online聚类算法能够对数据做到自适应,并且确保聚类中的模板与聚类中心始终是相似的。
预测模型采用3种不同出发点的模型,分别为:线性:线性意味着假定输入与输出之间存在一定线性关系。记忆:模型是否能够综合输入与它从历史数据中保存下的信息来预测未来。核函数:模型支持核函数就可以对非线性关系进行分析。
通常,线性模型能够有效的避免过拟合,并且对计算资源和训练数据要求较低,在预测较近的未来时间时表现较好。具有记忆性的模型可以挖掘数据的动态行为信息,但是增加了训练的复杂性与模型对数据的依赖。较好的一个方案是采用ENSEMBE方法,将多个模型进行合并做平均预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









