






 本文通过实例讲解了SQL中的分组查询(GROUP BY)和聚合函数(COUNT())的应用。讨论了为何在计数时选择COUNT(id)而非COUNT(name),并解释了GROUP BY如何处理数据去重,以及在实际操作中如何避免数据库错误。通过逻辑表展示了解决问题的过程,帮助读者理解统计特定条件下各地址出现的次数的方法。
本文通过实例讲解了SQL中的分组查询(GROUP BY)和聚合函数(COUNT())的应用。讨论了为何在计数时选择COUNT(id)而非COUNT(name),并解释了GROUP BY如何处理数据去重,以及在实际操作中如何避免数据库错误。通过逻辑表展示了解决问题的过程,帮助读者理解统计特定条件下各地址出现的次数的方法。
Group by 普通意思其他文章都有,不做过多描述
直接上例子:
表1:
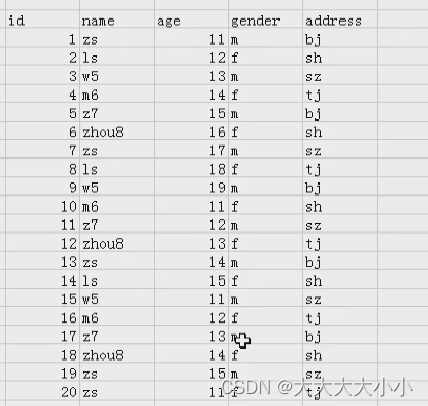
首先先匹配一下name=zs的结果,如表2显示:
表2:
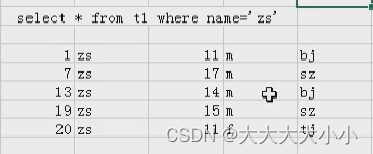
如果我想统计一下name=zs在各个address中有多少个?
该怎么弄呢?
首先我们应该弄个以address为组而站队的表
select address,count(id) from t1 where name='zs' group by address;
要注意为什么要选择count(id)而不选择count(name)?
因为count(id)在这个表中是唯一的。那group by 是如何处理的呢?
首先对address进行distinct,distinct简单来说就是去重,分组
会生成一下的逻辑表:

为啥说这个是个逻辑表呢?因为mysql中,只能承载一个数据,不能承载多个数据,是不存在的。
如下逻辑表:

结果会显示成:
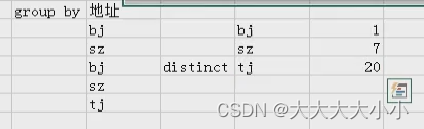
这一看就不对,一看就出错
所以这让mysql很难办,险些要翻桌子
为了不让mysql翻桌子,我们只能用:count(id) 另辟蹊径,意思是:符合address=tj的id有多少个
结果如图:

结果显而易见。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











