







本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6&share_source=copy_web&vd_source=404581381724503685cb98601d6706fb
上节课学习字符串的常用方法(1和2),格式化字符串的三种方式和format详细格式控制,本节课学习字符串的编码和解码,数据验证的方法,字符串的处理(字符串的拼接操作和字符串的去重操作)。
一、字符串的编码和解码
首先思考为什么要编码和解码:
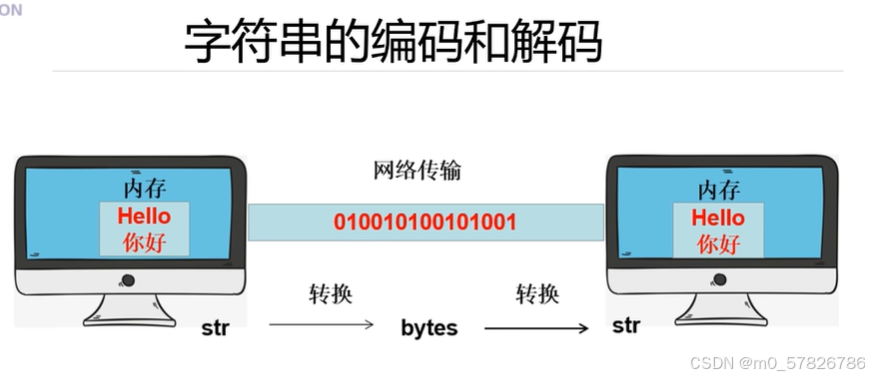 当字符串需要在两台电脑之间传输,要以二进制的形式进行编码,而从字符串形式str转为bytes叫编码,从bytes转为str叫解码。下面是字符串的编码和解码的语法:
当字符串需要在两台电脑之间传输,要以二进制的形式进行编码,而从字符串形式str转为bytes叫编码,从bytes转为str叫解码。下面是字符串的编码和解码的语法:
 注意编码和解码的格式要一致,比如要用utf-8编码,就要用utf-8解码,要用GBK编码就要用GBK解码。下面是实例:
注意编码和解码的格式要一致,比如要用utf-8编码,就要用utf-8解码,要用GBK编码就要用GBK解码。下面是实例:
解释一下,ignore表示对于报错直接忽略掉没法编码的(或解码)的部分,replace表示对于报错用?替代没法编码(或解码)的部分,strict表示对于没法编解码的直接报错(这个方法会使得后面的程序不再进行)。
代码以及解释如下:
s='伟大的中国梦'#数一下是6个汉字
#编码str->bytes,使用encode()
scode=s.encode(errors='replace')#默认是utf-8,报错方式是replace
print(scode)#结果发现默认是utf-8,根据中文占3个字节,一共18个
scode_gbk=s.encode('gbk',errors='replace')#指定转为gbk
print(scode_gbk)#中文占两个字节,所以最后有12个字符
#编码中的出错问题()
s2='耶✌'
scode_error=s2.encode('gbk',errors='ignore')#用gbk的方式去编码,ignore是指如果出错就忽略,结果是直接不显示✌部分b'\xd2\xae'
'''
scode=s2.encode('gbk',errors='strict')#用gbk的方式去编码,strict是指如果出错就报错
scode=s2.encode('gbk',errors='replace')#用gbk的方式去编码,replace是指如果出错就用?代替,结果:b'\xd2\xae?'
'''
print(scode_error)
#解码过程bytes->str
print(bytes.decode(scode_gbk,'gbk'))
print(bytes.decode(scode,'utf-8'))结果如下:
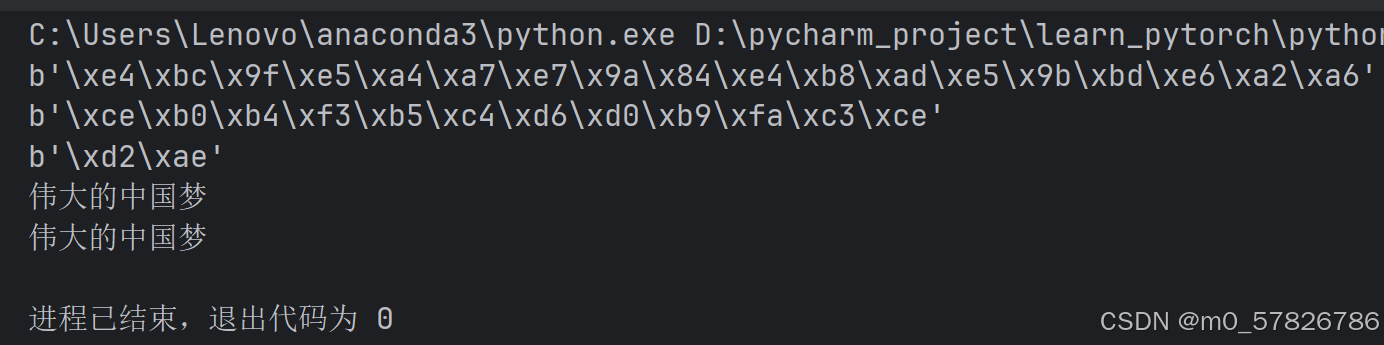
其中strict报错的情况是这样的:

二、数据的验证
数据的验证就是,比如说在登录某个网站的时候需要识别数入的内容合规与否
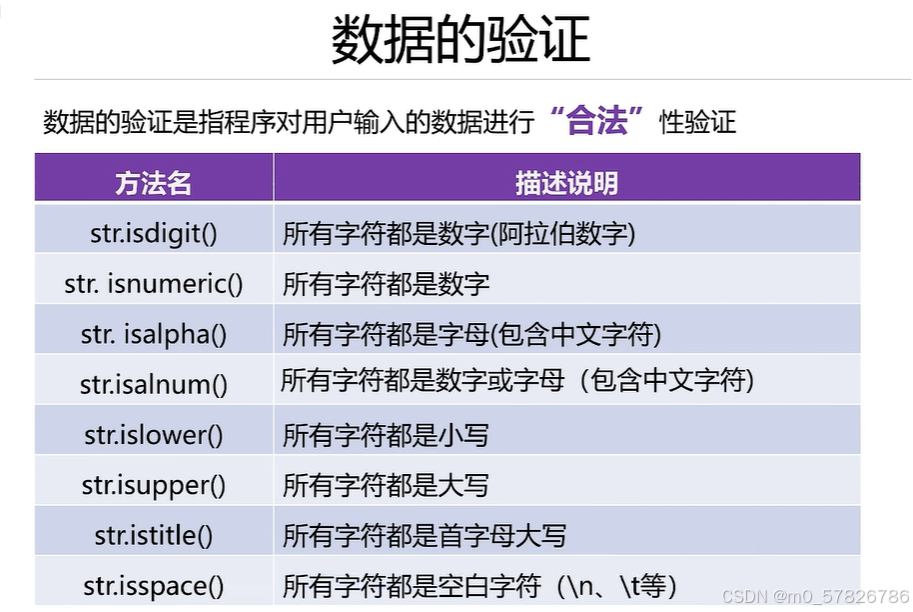
将上面每一个函数都运行一下,注意,汉字在里面被识别为字母类,而且既是大写字母又是小写字母。运行代码如下:
#isdigit()是判断前面这个是否是十进制的阿拉伯数字(返回True和False)
print('123'.isdigit())
print('一二三'.isdigit())#发现“一二三”不是阿拉伯数字就判错
print('0b1010'.isdigit())#发现“0b1010”不完全是阿拉伯数字就判错
print('ⅢⅢⅢ'.isdigit())#发现罗马数字“ⅢⅢⅢ”不是阿拉伯数字就判错
print('-'*50)
#isnumeric()是判断所有字符是否都是数字(返回True和False)
print('123'.isnumeric())
print('一二三'.isnumeric())#只要是数字它都认为对
print('ⅢⅢⅢ'.isnumeric())#只要是数字它都认为对
print('壹贰叁'.isnumeric())#只要是数字它都认为对
print('-'*50)
#isalpha()是判断所有字符是否都是字母,包括中文字符(返回True和False)
print('hello你好'.isalpha())#True,说明它认为中文也算的
print('hello你好123'.isalpha())#出现了阿拉伯数字认为是错
print('hello你好一二三'.isalpha())#True,因为一二三是汉字
print('hello你好ⅢⅢⅢ'.isalpha())#出现了罗马数字认为是错
print('hello你好壹贰叁'.isalpha())#True
print('-'*50)
#所有字符都是数字或字母(返回True和False)
print('hello你好'.isalpha())#True,说明它认为中文也算的
print('hello你好123'.isalpha())#出现了阿拉伯数字认为是错
print('hello你好一二三'.isalpha())#True,因为一二三是汉字
print('hello你好ⅢⅢⅢ'.isalpha())#出现了罗马数字认为是错
print('hello你好壹贰叁'.isalpha())#True,因为壹贰叁是汉字
print('-'*50)
#所有字符都是数字或字母(包括汉字)(返回True和False)
print('hello你好'.isalnum())#True,说明它认为中文也算的
print('hello你好123'.isalnum())#出现了阿拉伯数字认为是错
print('hello你好一二三'.isalnum())#True,因为一二三是汉字
print('hello你好ⅢⅢⅢ'.isalnum())#出现了罗马数字认为是错
print('hello你好壹贰叁'.isalnum())#True,因为壹贰叁是汉字
print('-'*50)
#islower()判断字符是否全是小写字母,包括汉字(返回True和False)
print('HelloWorld'.islower())#False
print('helloworld'.islower())#True
print('hello你好'.islower())#True
print('-'*50)
#isupper()判断字符是否全是大写字母,包括汉字(返回True和False)
print('HelloWorld'.isupper())#False
print('HELLOWORLD'.isupper())#True
print('hello你好'.isupper())#True
print('-'*50)
#istitle()判断是否所有字符都是首字母大写
print('Hello'.istitle())#True
print('HelloWorld'.istitle())#False,因为除了首字母也有大写的字符
print('helloworld'.istitle())#False
print('Hello World'.istitle())#True
print('Hello world'.istitle())#True
print('你好Hello'.istitle())#True,汉字既是大写又是小写
print('-'*50)
#isspace()判断是否都是空白字符,是的话返回True,否的话返回Flase
print('\t'.isspace())#True
print(' '.isspace())#True
print('\n'.isspace())#True运行结果如下:
True
False
False
False
--------------------------------------------------
True
True
True
True
--------------------------------------------------
True
False
True
False
True
--------------------------------------------------
True
False
True
False
True
--------------------------------------------------
True
True
True
True
True
--------------------------------------------------
False
True
True
--------------------------------------------------
False
True
False
--------------------------------------------------
True
False
False
True
False
True
--------------------------------------------------
True
True
True
进程已结束,退出代码为 0
三、字符串的处理1--拼接操作
字符串的拼接处理之前我们学过两个字符串之间加上+,这里学习更多的处理方式:
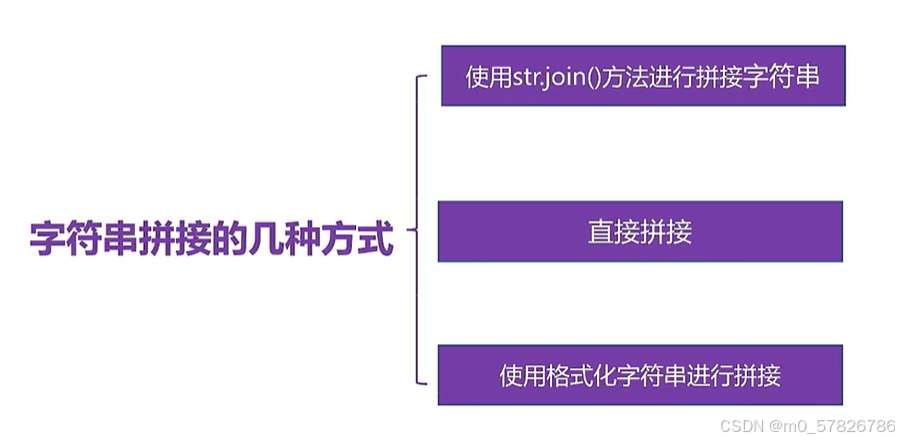
代码演示以及解释如下:
s1='hello'
s2='world'
#(1)使用+进行拼接
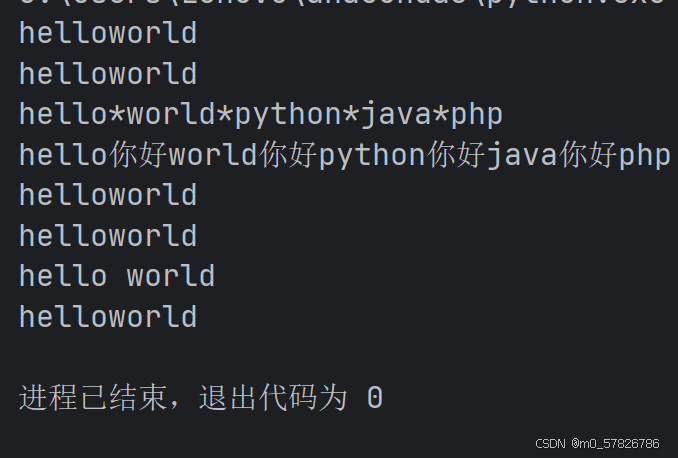
print(s1+s2)
#(2)使用字符串的join()方法,语法是将想要拼接的按照顺序放在同一个列表里
print(''.join([s1,s2]))#注意这里的''中应该是希望两个字符串中间隔着什么,这里我们希望无缝衔接就啥也没填
print('*'.join(['hello','world','python','java','php']))#这里''中间填上想要衔接的字符
print('你好'.join(['hello','world','python','java','php']))#这里''中间填上想要衔接的字符
#(3)直接拼接
print('hello''world')
#(4)使用格式化字符串进行拼接
print('%s%s'%(s1,s2))
print(f'{s1} {s2}')#使用上节课的知识,花括号占位符
print('{0}{1}'.format(s1,s2))运行结果如下:
四、字符串的处理2--去重操作
除了拼接还有一个重要的操作就是去重。
有三种方法分别是(1)字符串拼接以及not in(2)使用索引以及not in(3)利用集合的不重复性,但是这样没有顺序了,所以变成集合以后还要进行列表的排序。
代码以及相关解释如下:
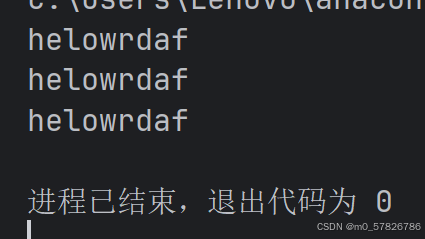
s='helloworldhelloworldadfdfdoodllffe'
#(1)字符串拼接以及not in
new_s=''
for i in s:#遍历s中的字符
if i not in new_s:#如果i在要加进去的字符不存在
new_s+=i#拼接操作,就把这些不重复的字符拼接进去
print(new_s)
#(2)使用索引以及not in
new_s2=''
for i in range(len(s)):#遍历s的字符串的长度的下标
if s[i] not in new_s2:#如果s中索引为i的元素在new_s2中不存在
new_s2+=s[i]#拼接操作,就把这些不重复的字符拼接进去
print(new_s2)
#(3)通过集合去重,但是这样产生的集合集合无序,所以需要加上一个列表的排序操作
new_s3=set(s)
lst=list(new_s3)
lst.sort(key=s.index)
print(''.join(lst))结果如下:
本节完


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









