







1.HashMap集合简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
补充:将链表转换成红黑树前会判断,即使阈值大于8,但是数组长度小于64,此时并不会将链表变为红黑树。而是选择进行数组扩容。
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考 treeifyBin方法。
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
小结:
特点:
1.存取无序的
2.键和值位置都可以是null,但是键位置只能是一个null
3.键位置是唯一的,底层的数据结构控制键的
4.jdk1.8前数据结构是:链表 + 数组 jdk1.8之后是 : 链表 + 数组 + 红黑树
5.阈值(边界值) > 8 并且数组长度大于64,才将链表转换为红黑树,变为红黑树的目的是为了高效的查询。
2.HashMap集合底层的数据结构
2.1HashMap底层的数据结构存储数据的过程

1.面试题:HashMap中hash函数是怎么实现的?还有哪些hash函数的实现方式?
对于key的hashCode做hash操作,无符号右移16位然后做异或运算。
还有平方取中法,伪随机数法和取余数法。这三种效率都比较低。而无符号右移16位异或运算效率是最高的。
2.面试题:当两个对象的hashCode相等时会怎么样?
会产生哈希碰撞,若key值内容相同则替换旧的value.不然连接到链表后面,链表长度超过阈值8就转换为红黑树存储。
3.面试题:何时发生哈希碰撞和什么是哈希碰撞,如何解决哈希碰撞?
只要两个元素的key计算的哈希码值相同就会发生哈希碰撞。jdk8前使用链表解决哈希碰撞。jdk8之后使用链表+红黑树解决哈希碰撞。
4.面试题:如果两个键的hashcode相同,如何存储键值对?
hashcode相同,通过equals比较内容是否相同。
相同:则新的value覆盖之前的value
不相同:则将新的键值对添加到哈希表中
5.在不断的添加数据的过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
6.通过上述描述,当位于一个链表中的元素较多,即hash值相等但是内容不相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度(阀值)超过 8 时且当前数组的长度 > 64时,将链表转换为红黑树,这样大大减少了查找时间。jdk8在哈希表中引入红黑树的原因只是为了查找效率更高。
但是这样的话问题来了,传统hashMap的缺点,1.8为什么引入红黑树?这样结构的话不是更麻烦了吗,为何阈值大于8换成红黑树?
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。 当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。
3.HashMap继承关系
HashMap继承关系如下图所示:
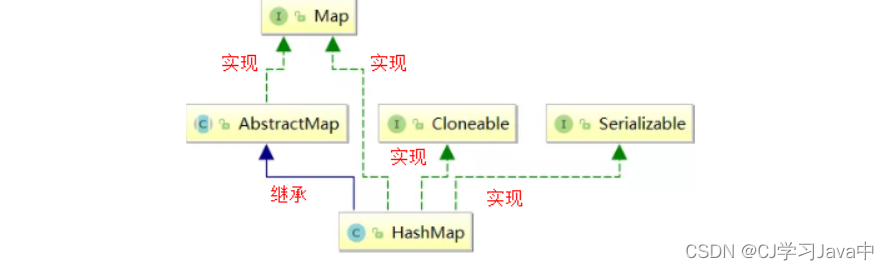
说明:
-
Cloneable 空接口,表示可以克隆。 创建并返回HashMap对象的一个副本。
-
Serializable 序列化接口。属于标记性接口。HashMap对象可以被序列化和反序列化。
-
AbstractMap 父类提供了Map实现接口。以最大限度地减少实现此接口所需的工作。
补充:通过上述继承关系我们发现一个很奇怪的现象, 就是HashMap已经继承了AbstractMap而AbstractMap类实现了Map接口,那为什么HashMap还要在实现Map接口呢?同样在ArrayList中LinkedList中都是这种结构。
据 java 集合框架的创始人Josh Bloch描述,这样的写法是一个失误。在java集合框架中,类似这样的写法很多,最开始写java集合框架的时候,他认为这样写,在某些地方可能是有价值的,直到他意识到错了。显然的,JDK的维护者,后来不认为这个小小的失误值得去修改,所以就这样存在下来了。
4.HashMap集合类的成员
4.1成员变量
1.序列化版本号
private static final long serialVersionUID = 362498820763181265L;
2.集合的初始化容量( 必须是二的n次幂 )
//默认的初始容量是16 -- 1<<4相当于1*2的4次方---1*16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
问题: 为什么必须是2的n次幂?如果输入值不是2的幂比如10会怎么样?
HashMap 容量为2次幂的原因,就是为了数据的的均匀分布,减少hash冲突,毕竟hash冲突越大,代表数组中一个链的长度越大,这样的话会降低hashmap的性能
如果创建HashMap对象时,输入的数组长度是10,不是2的幂,HashMap通过一通位移运算和或运算得到的肯定是2的幂次数,并且是离那个数最近的数字。
3.默认的负载因子,默认值是0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4.集合最大容量
//集合最大容量的上限是:2的30次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
5.当链表的值超过8则会转红黑树(1.8新增)
//当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
6.当链表的值小于6则会从红黑树转回链表
//当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
7.当Map里面的数量超过这个值时,表中的桶才能进行树形化 ,否则桶内元素太多时会扩容,而不是树形化 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD (8)
//桶中结构转化为红黑树对应的数组长度最小的值
static final int MIN_TREEIFY_CAPACITY = 64;
8、table用来初始化(必须是二的n次幂)(重点)
//存储元素的数组
transient Node<K,V>[] table;
table在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组,jdk8之前数组类型是Entry<K,V>类型。从jdk1.8之后是Node<K,V>类型。只是换了个名字,都实现了一样的接口:Map.Entry<K,V>。负责存储键值对数据的。
9、用来存放缓存
//存放具体元素的集合
transient Set<Map.Entry<K,V>> entrySet;
10、 HashMap中存放元素的个数(重点)
//存放元素的个数,注意这个不等于数组的长度。
transient int size;
11、 用来记录HashMap的修改次数
// 每次扩容和更改map结构的计数器
transient int modCount;
12、 用来调整大小下一个容量的值计算方式为(容量*负载因子)
// 临界值 当实际大小(容量*负载因子)超过临界值时,会进行扩容
int threshold;
13、 哈希表的加载因子(重点)
// 加载因子
final float loadFactor;
说明:
1.loadFactor加载因子,是用来衡量 HashMap 满的程度,表示HashMap的疏密程度,影响hash操作到同一个数组位置的概率,计算HashMap的实时加载因子的方法为:size/capacity,而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
当HashMap里面容纳的元素已经达到HashMap数组长度的75%时,表示HashMap太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。,所以开发中尽量减少扩容的次数,可以通过创建HashMap集合对象时指定初始容量来尽量避免。
同时在HashMap的构造器中可以定制loadFactor。
5.遍历HashMap集合几种方式
1、分别遍历Key和Values
2、使用Iterator迭代器迭代
3、通过get方式(不建议使用) 说明:根据阿里开发手册,不建议使用这种方式,因为迭代两次。keySet获取Iterator一次,还有通过get又迭代一次。降低性能。
4.jdk8以后使用Map接口中的默认方法:
default void forEach(BiConsumer<? super K,? super V> action)
BiConsumer接口中的方法:
void accept(T t, U u) 对给定的参数执行此操作。
参数
t - 第一个输入参数
u - 第二个输入参数
6.HashMap中容量的初始化
当我们已知HashMap中即将存放的KV个数的时候,容量设置成多少为好呢?
initialCapacity/ 0.75F + 1.0F

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









