







1.算法类参数优化
开启对count(distinct )的自动优化
set hive.optimize.countdistinct=true
开启自动mapjoin
set hive.auto.convert.join = true;
大表小表的阈值设置(默认25M一下认为是小表)
set hive.mapjoin.smalltable.filesize=26214400;
默认值是true,当选项设定为true时,开启map端部分聚合 map端聚合,降低传给reduce的数据量
set hive.map.aggr=true;
设置严格模式,默认值是nonstrict非严格模式。严格模式下会禁止以下3种类型不合理查询,即以下3种情况会报错
set hive.mapred.mode=strict;
设置map端执行前合并小文件
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
关闭CBO优化,默认值true开启,可以自动优化HQL中多个JOIN的顺序,并选择合适的JOIN算法
set hive.cbo.enable=false;
CTE优化,这个参数在默认情况下是-1(关闭的);当开启(大于0),比如设置为2,则如果with…as语句被引用2次及以上时,会把with…as语句生成的table物化,从而做到with…as语句只执行一次,来提高效率。
set hive.optimize.cte.materialize.threshold =2;
2.压缩类参数优化
2.1 map端压缩
设置hive多个map-reduce中间数据压缩
set hive.exec.compress.intermediate=true;
开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
2.2 reduce端压缩
设置hive的最终查询结果输出是否进行压缩
set hive.exec.compress.output=true;
设置MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
3.资源类参数优化
一个 Map Task 可使用的内存上限(单位:MB),默认为 1024。如果 Map Task 实际使用的资源量超过该值,则会被强制杀死。
set mapreduce.map.memory.mb = 4096
一个 Reduce Task 可使用的资源上限
set mapreduce.reduce.memory.mb = 4096
每个 Maptask 可用的最多 cpu core 数目, 默认值: 1
set mapreduce.map.cpu.vcores =1
每个 Reducetask 可用最多 cpu core 数目默认值: 1
set mapreduce.reduce.cpu.vcores=1
Map Task 的 JVM 参数
set mapreduce.map.java.opts = -Xmx3800m
reduce Task 的 JVM 参数
set mapreduce.reduce.java.opts = -Xmx3800m
4.公共类参数优化
–执行DML语句时,收集表级别的统计信息
set hive.stats.jautogather=true;
–执行DML语句时,收集字段级别的统计信息
set hive.stats.column.autogather=true;
–计算Reduce并行度时,从上游Operator统计信息获得输入数据量
set hive.spark.use.op.stats=true;
–计算Reduce并行度时,使用列级别的统计信息估算输入数据量
set hive.stats.fetch.column.stats=true
5.并行度参数优化
最优解估算Reduce的并行度 min(ceil( 2 * 输入ReduceTask的数据量 / bytePerReducer(每个Reducer处理的数据量)),maxReducers(默认1009))
hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer 默认 256M
hive.exec.reducers.max的值为maxReducers 默认1009
Hive并行编译 各个会话可以同时编译查询,提高团队工作效率。否则如果在UDF中执行了一段HiveQL,或者多个用户同时使用的话, 就会锁住。
set hive.driver.parallel.compilation = true
0或负值为无限制,可根据团队人员和硬件进行修改,以保证同时编译查询。
set hive.driver.parallel.compilation.global.limit = 10
设置动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=50000;
set hive.exec.max.dynamic.partitions.pernode=10000;
设置jvm重用
set mapreduce.job.jvm.numtasks=5
开启向量 相当于从原本的map逐行处理数据变成了批量处理数据,从处理一行到一次性处理多行,减少了cpu指令和cpu上下文切换
set hive.vectorized.execution.enabled = true;
并行执行
打开任务并行执行
set hive.exec.parallel=true;
同一个sql允许最大并行度,默认值为8。
默认情况下,Hive一次只会执行一个阶段。
开启并行执行时会把一个sql语句中没有相互依赖的阶段并行去运行,这样可能使得整个job的执行时间缩短。
提高集群资源利用率,不过这当然得是在系统资源比较空闲的时候才有优势,否则没资源,并行也起不来。
set hive.exec.parallel.thread.number=16;
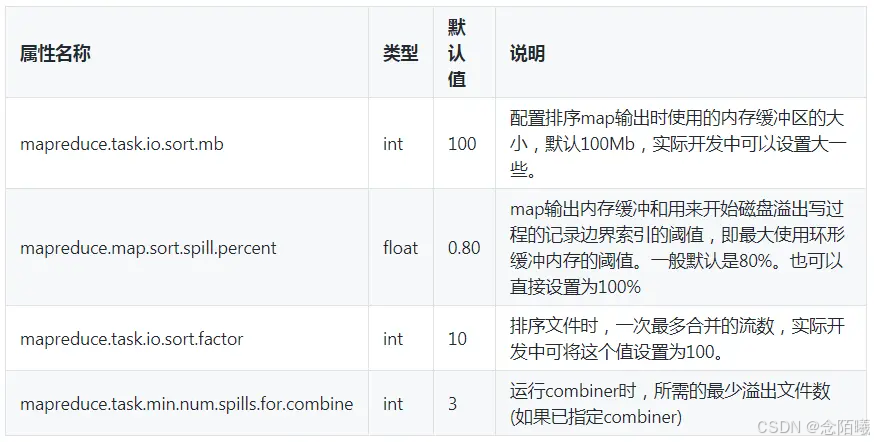
6.map端参数优化
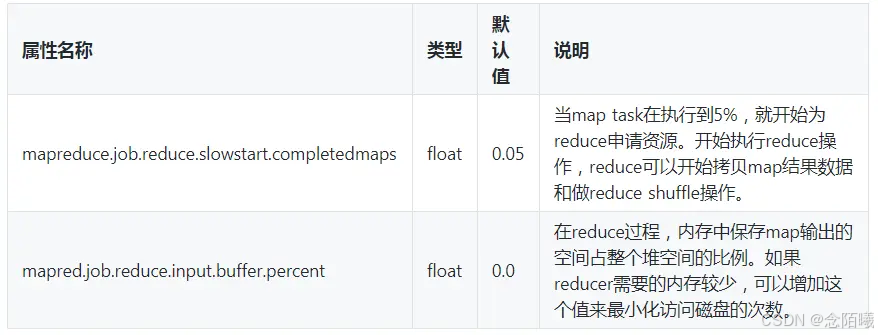
7.reduce端参数优化
8.shuffle端参数优化

9.数据倾斜优化
默认值是false,当有数据倾斜的时候进行负载均衡,生成的查询计划有两个MapReduce任务,第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作
set hive.groupby.skewindata = ture;
join导致的数据倾斜的参数优化
set hive.optimize.skewjoin=true; 启用倾斜连接优化
set hive.skewjoin.key=200000; 超过20万行就认为该键是偏斜连接键
distinct 导致的数据倾斜的参数优化
set hive.optimize.countdistinct = true;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









