









目录
项目地址: https://github.com/liwook/PublicReview
缓存穿透
是指客户端请求的数据都不存在于缓存和数据库中,这样Redis缓存就是个摆设了,这些请求都会打到数据库。
那么,缓存穿透会发生在什么时候呢?一般来说,是有两种情况。
- 业务层误操作:缓存中的数据和数据库中的数据都被误删除了,所以缓存和数据库中都没有数据
- 恶意攻击:专门访问数据库中没有的数据
常用的解决方法有3种:
缓存空值或缺省值
针对查询的数据,在Redis中缓存一个空值或者是和业务层协商确定的缺省值(比如,库存的缺省值可以设置为0)。紧接着,应用发送的后续请求再进行查询时,就可以直接从Redis中读取空值返回给应用了。
其优点实现简单,维护方便;缺点是额外的内存消耗,可能造成短期的不一致
布隆过滤
其是用来快速判断某元素是否存在与一个集合中的。
其原理是:其内是一个初始值都是0的bit数组。当一个元素被加入集合时候,通过N个hash函数将这个元素映射成bit数组中的N个点,并把它们置为1。当检索时候,就判断该元素的哈希值后对应的N个点是否都是1,若都是1,则存在,否则不存在。
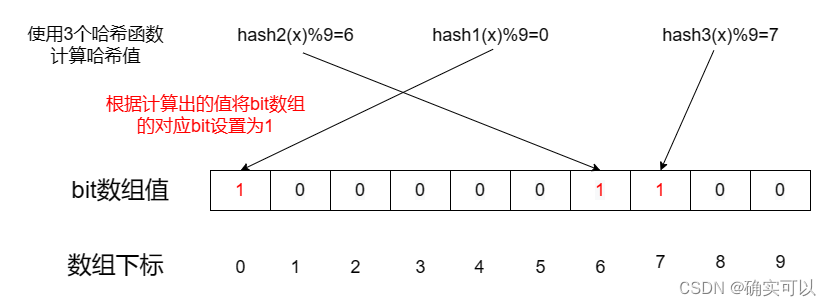
所以基于布隆过滤器的快速检测特性,在把数据写入到数据库时,我们可以使用布隆过滤器做个标记。当缓存失效后,需要去查询数据库时,就可以通过查询布隆过滤器快速判断数据是否存在数据库中。若不存在,就不用去访问数据库,这样若是发生了缓存穿透, 大量的请求也只会去查询Redis和布隆过滤器,而不会挤压到数据库了。
其优点:对比缓存空值,其内存占用较少,没有多余key;
缺点:
- 实现相对复杂,当然也有成熟的组件供使用;
- 存在误判。当要查到的元素并没有在容器中,但是刚好hash之后得到的k个位置上值都是1,那就过滤器就会通过,所以使用它的场景需要允许一定非常小概率的误差。
- 删除困难。通过原理可知,在删除时,不能随便就修改byte数组的置1值,因为你无法确定那个位置的1是不是只有你这个值在使用,修改了就很可能会影响别的值。
在前端进行请求检测
缓存穿透的一个原因是有大量的请求访问不存在的数据。所以,可以在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求(比如请求参数不合理,参数是非法值)直接过来掉,不让他们访问后端。
我们这里实现的话,就用缓存空对象的方法来解决缓存穿透问题。
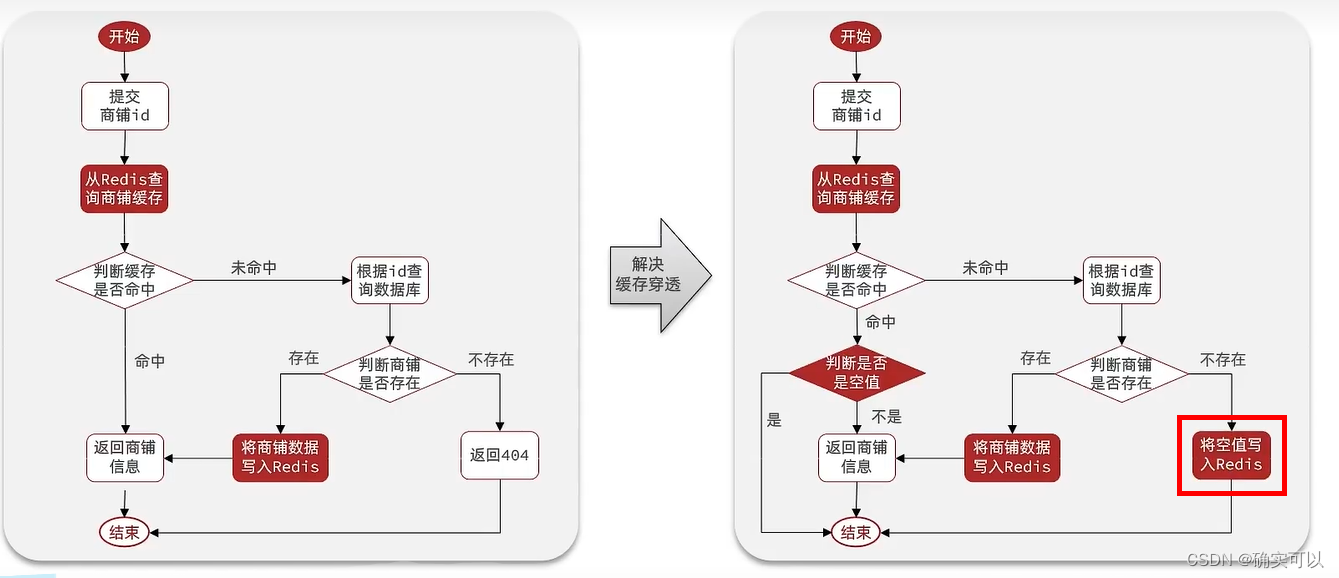
在QueryShopById方法中修改。
注意两点:
- 若是缓存命中就要判断是否是空值。
- 从mysql中判断商铺要是不存在,要将空值写入redis,并设置较短的过期时间
const (
............
CacheNullTTL = 10 * time.Minute
)
// 使用缓存空值来解决缓存穿透
func QueryShopById(c *gin.Context) {
id := c.Param("id") //获取定义的路由参数的值
//1.从redis查询商铺缓存,是string类型的
val, err := db.RedisClient.Get(context.Background(), ShopKeyPriex+id).Result()
if err == nil { //若redis存在该缓存,直接返回
//有缓存,但可能是空值,需要判断
if val == "" {
code.WriteResponse(c, code.ErrDatabase, "this shop not found")
return
}
var shop model.TbShop
sonic.Unmarshal([]byte(val), &shop)
code.WriteResponse(c, code.ErrSuccess, shop)
} else if err == redis.Nil { //2.若是redis没有该缓存,从mysql中查询
tbSop := query.TbShop
idInt, _ := strconv.Atoi(id)
shop, err := tbSop.Where(tbSop.ID.Eq(uint64(idInt))).First()
if err == gorm.ErrRecordNotFound {
//3.mysql若不存在该商铺,返回错误
//需要往redis中写入空值,防止缓存穿透,并设置较短的过期时间
_, _ = db.RedisClient.Set(context.Background(), ShopKeyPriex+id, "", CacheNullTTL).Result()
code.WriteResponse(c, code.ErrDatabase, "this shop not found")
return
}
//4.找到商铺,写回redis,并发送给客户端
//把shop进行序列化,不然写入redis会出错。序列化就是把该数据对象变成json,即是变成一个字符串
v, _ := sonic.Marshal(shop) //这里使用github.com/bytedance/sonic
_, err = db.RedisClient.Set(context.Background(), ShopKeyPriex+id, v, 0).Result()
} else { //若redis查询出错,返回错误
................
}
}
缓存雪崩
缓存雪崩是只在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求达到数据库,带来巨大压力。
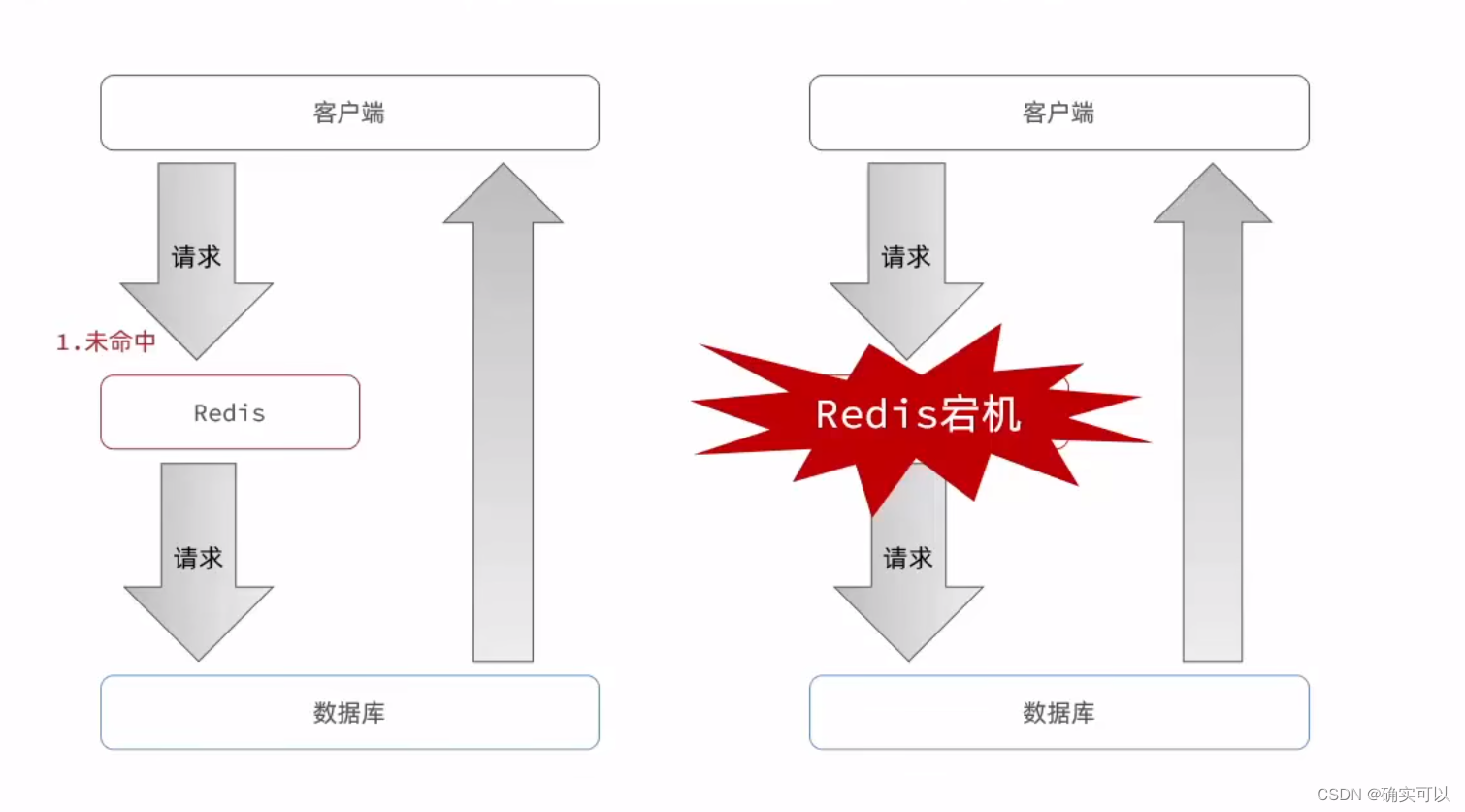
针对大量数据同时失效带来的缓存雪崩问题,可以有两种解决方案
- 给不同的key的过期时间添加随机值
- 服务降级
针对Redis实例宕机导致的雪崩问题,有两种解决方案
- 服务熔断
- 请求限流
给不同的key的TTL添加随机数
若业务层的确要求有些数据同时失效,在用 EXPIRE 命令给每个数据设置过期时间时,给这些数据的过期时间增加个较小的随机数(例如,随机增加 2~3 分钟)
服务降级
服务降级是指 当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。说白了,就是尽可能的把系统资源让给优先级高的服务。
举个例子:
- 当业务应用访问的是非核心数据(比如商品属性)时,就暂时停止从缓存中查询,而是直接返回预先定义的信息、空值或者错误信息;
- 当业务应用访问的是核心数据(比如商品库存)时,仍然运行访问缓存,或缓存失效,也允许可以继续访问数据库。
服务熔断
熔断一般是指依赖的外部接口出现故障的情况断绝和外部接口的关系。而这里Redis实例宕机,就暂停应用对缓存系统的接口访问,直接返回(返回错误或其他信息)。等到 Redis 缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。
在业务系统运行时,我们可以检测Redis缓存实例和数据库实例的负载指标,比如每秒请求数、CPU利用率、内存利用率等。若发现Redis缓存实例宕机了,而数据库实例的负载压力突增(比如每秒请求数突增),就可以认为发生了缓存雪崩。我们就可以开启熔断机制,暂停应用对缓存服务的访问,从而就可以降低对数据库访问压力。(这个检测、进行熔断,应该是有软件或组件可以自动实现的)。
请求限流
服务熔断暂停了整个缓存系统的访问,其实对业务应用的影响范围比较大的。为了尽量减少这种影响,我们可以进行请求限流,即是通过 请求入口前端 或者 后端服务 控制每秒进入系统的请求数,避免多过的请求被发送到数据库。
例如,假设业务系统正常运行时,允许每秒进入系统的请求是10000个,其中可以有2000个请求访问到数据库。而这时发送缓存雪崩,数据库的每秒请求数突然增加到每秒 8000个。此时,我们就可以启动请求限流机制,在请求入口前端或者后端服务的入口只允许每秒进入系统的请求数为 1000 个,再多的请求就会被直接拒绝服务。
还有一些其他的建议:就是提前预防,利用Redis集群提高服务的可用性。若Redis 缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
简单起见,我们这里就使用给TTL添加随机数的做法。
const (
CacheShopTTL = 2 * time.Hour
)
// post shop/:id
// 使用ttl是随机值来解决缓存雪崩
func QueryShopById(c *gin.Context) {
//1.从redis查询商铺缓存,是string类型的
val, err := db.RedisClient.Get(context.Background(), ShopKeyPriex+id).Result()
if err == nil { //若redis存在该缓存,直接返回
...................
} else if err == redis.Nil { //2.若是redis没有该缓存,从mysql中查询
//4.找到商铺,写回redis,并发送给客户端
//把shop进行序列化,不然写入redis会出错。序列化就是把该数据对象变成json,即是变成一个字符串
//添加随机的ttl,解决缓存雪崩
v, _ := sonic.Marshal(shop) //这里使用github.com/bytedance/sonic
_, err = db.RedisClient.Set(context.Background(), ShopKeyPriex+id, v, CacheShopTTL+time.Duration(rand.Int31n(10000))).Result()
..........
} else { //若redis查询出错,返回错误
...................
}
}缓存击穿
其也叫热点key问题,就是一个被高并发并访问且缓存重建业务比较复杂的key突然失效了,无数的请求放回会在瞬间给数据库该来巨大的冲击。
首先是最简单的办法:对于访问特别频繁的热点数据,我们就不设置过期时间。
对应设置过期时间的:
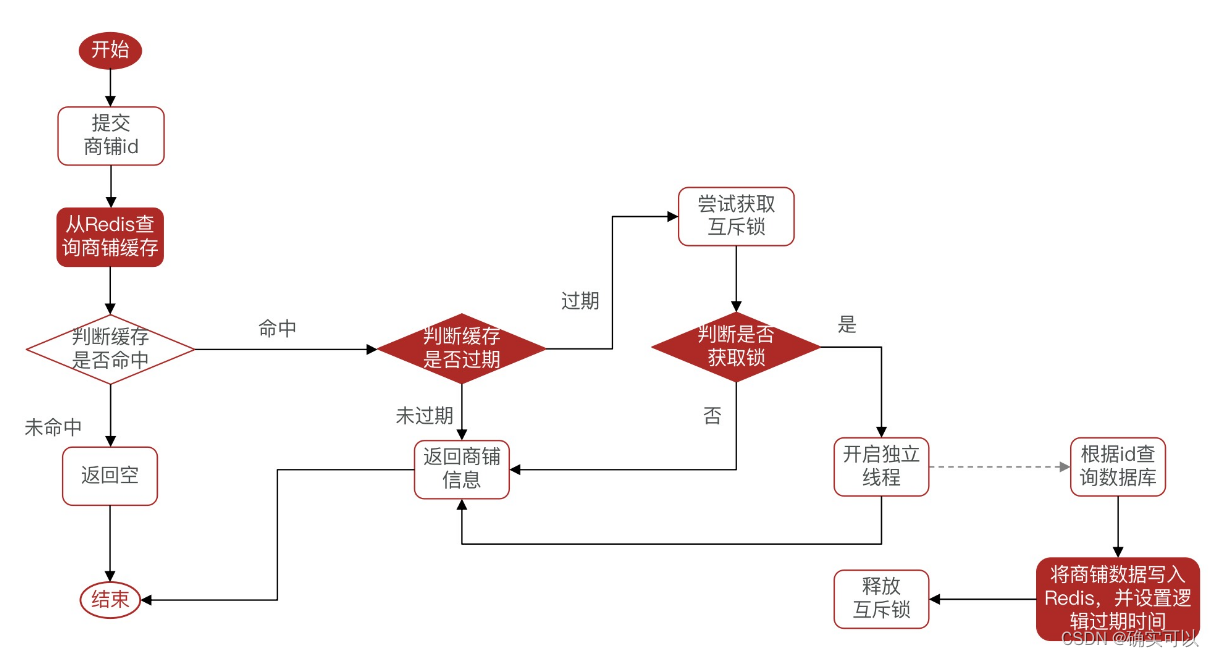
- 使用互斥锁:查询缓存未命中,获取互斥锁,获取到互斥锁的才能查询数据库重建缓存,将数据写入缓存中后,释放锁。
- 添加逻辑过期:查询缓存,发现逻辑时间已过期,获取互斥锁,开启新线程;在新线程中查询数据库重建缓存,讲数据写入到缓存后,释放锁;在释放锁之前,查询该数据时,都会将过期的时间返回。
互斥锁(时间换空间)
- 优点:内存占用小,一致性高,实现简单
- 缺点:性能较低,容易出现死锁
逻辑过期(空间换时间)
- 优点:性能高
- 缺点:内存占用较大,容易出现脏读
两者相比较,互斥锁更加易于实现,但是容易发生死锁,且锁导致并行变成串行,导致系统性能下降,逻辑过期实现起来相较复杂,且需要耗费额外的内存,但是通过开启子线程重建缓存,使原来的同步阻塞变成异步,提高系统的响应速度,但是容易出现脏读。
使用互斥锁
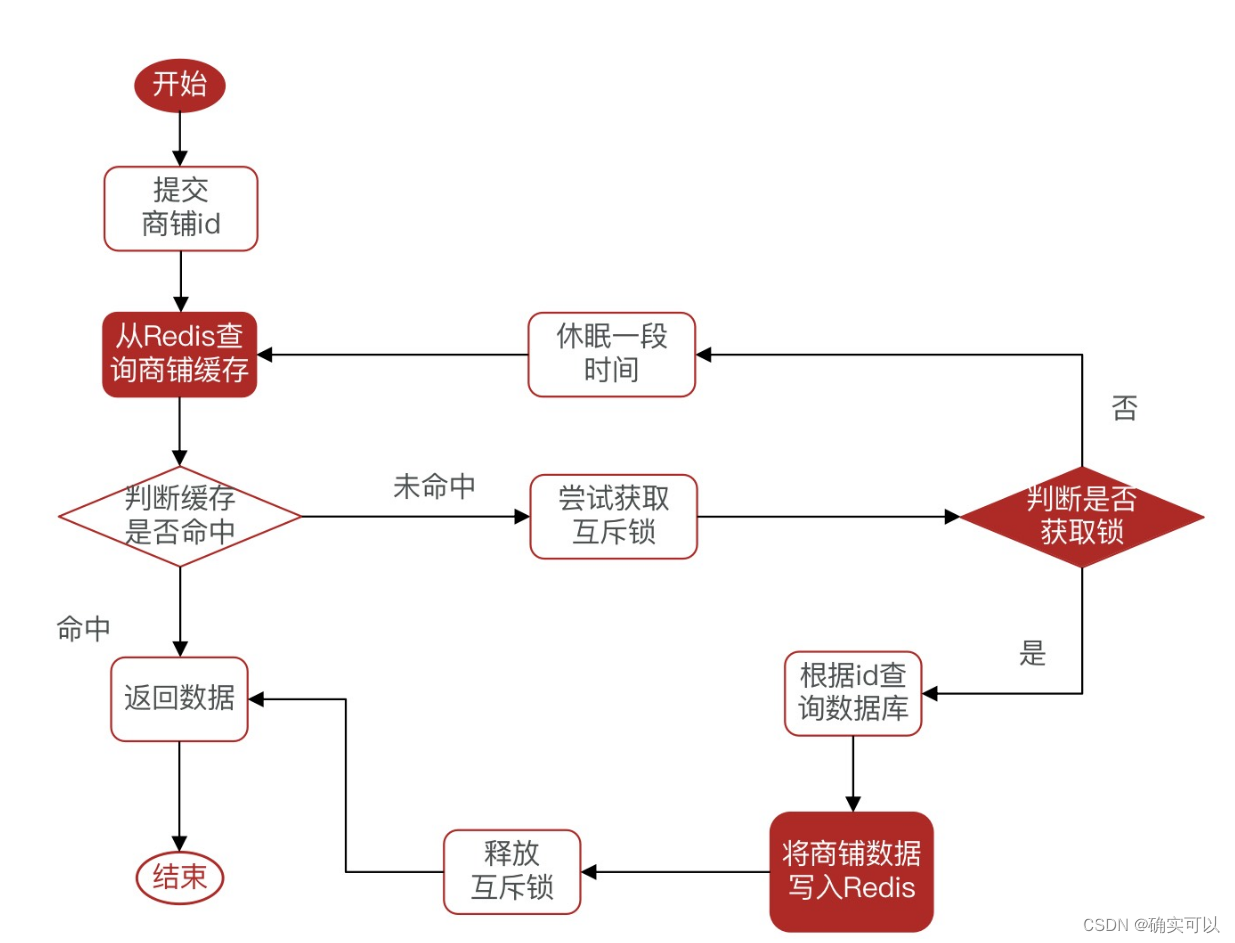
使用互斥锁的注意点
那首先我们会想到编程语言提供的互斥锁。比如Go语言的sync.Mutex。那容易想到是用就一个互斥锁去锁住所有用户访问所有key。但这就导致性能问题,完全变成串行。
那我们肯定是想 访问key a就获取key a对应的锁,访问key b就获取key b对应的锁,这样性能才不会太差。
问题1:
- 我们是访问一个key就加一个互斥锁,访问另外一个key就需要加另一个锁。那如何确定锁A是访问key1加的锁呢?假如在全局定义了个互斥锁数组,那我们也不能确定当前哪个key是持有哪个锁的。
- 更进一步,我们可以想到用map。就可以把访问的key作为map的键,map的value就是sync.Mutex。这样是可以快速通过访问的key去判断该互斥锁是否已被持有。
问题2:
- 因为我们不能预先知道所有的key,即是不能在客户访问之前就把所有key的互斥锁存入map中。那每次就需要判断map是否有该key。若是没有,就需要把该key的互斥锁添加到map中。
- 而map的写操作不是线程安全的,多线程写map,就需要加锁。而这时线程A写key1的互斥锁,线程B写key2的互斥锁,线程3写key3的锁,那这个时刻又回到多个线程访问key,都是使用同一个互斥锁(锁住map)了。而且那以后每次加锁的时候,都需要判断map中是否有该key的锁,也是麻烦。
所以,我们需要有另外的加锁方式。这个就可以使用Redis的string类型的setnx,其原理是该key不存在才能set成功,否则返回失败。这样当返回失败时候,我们就休眠一段时间,再去访问Redis。
而简单使用Redis的setnx命令来做互斥锁会遇到不少问题,企业中不会这么做,要使用的也是使用现在已有的成熟方案,比如go语言使用redsync。这种就会考虑到很多细节。这种是分布式锁。
逻辑过期
所谓的逻辑过期,类似于逻辑删除,并不是真正意义上的过期,而是新增一个字段,用来标记key的过期时间,这样能能够避免key过期而被自动删除,这样数据就永不过期了,从根本上解决因为热点key过期导致的缓存击穿。一般搞活动时,比如抢优惠券,秒杀等场景,请求量比较大就可以使用逻辑过期,等活动一过就手动删除逻辑过期的数据。
singleflight
该key被高并发并访问,即是在同一极短的时间段内被很多用户访问,都是访问同一个key,那我们可以只让一个请求去访问,而其他请求都在等待,返回数据后,其他请求也就获取到该数据了。
在go语言中有现成的组件,singleflight(golang.org/x/sync/singleflight包)。
它提供了重复函数调用抑制机制,使用它可以避免同时进行相同的函数调用。第一个调用未完成时后续的重复调用会等待,当第一个调用完成时则会与它们分享结果,这样以来虽然只执行了一次函数调用但是所有调用都拿到了最终的调用结果。
Do函数
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)我们把访问redis,判断redis是否有数据等操作封装成一个函数singleflightFunc。Do 执行并返回给定函数fn的结果,确保一次只有一个给定key在执行。如果进入重复调用,重复调用方将等待原始调用方完成并会收到相同的结果。返回值shared表示是否给多个调用方赋值 v。
注意:使用Do方法时,如果第一次调用发生了阻塞,那么后续的调用也会发生阻塞。在极端场景下可能导致程序hang住。
一般在高并发时候,就会多次执行singleflightFunc函数。而使用了Do函数,singleflightFunc函数被调用的次数就只有一次或者很少次。
使用singleflight处理缓存击穿
打印num,可以得到singleflightFunc函数的调用次数。
var sg singleflight.Group
// 根据商店id查找商铺缓存数据
// shop/:id
// 使用singleflight解决缓存击穿
func QueryShopById(c *gin.Context) {
id := c.Param("id") //获取定义的路由参数的值
if id == "" {
code.WriteResponse(c, code.ErrValidation, "id cannot be empty")
return
}
val, err, _ := sg.Do(ShopKeyPriex+id, func() (interface{}, error) {
return singleflightFunc(id)
})
if err != nil {
if err.Error() == "this shop not found" {
code.WriteResponse(c, code.ErrDatabase, "this shop not found")
return
}
code.WriteResponse(c, code.ErrDatabase, nil)
}
code.WriteResponse(c, code.ErrSuccess, val)
}
var num = 0 //用于测试有多少次请求会执行该函数,即有多少次请求会查询redis
func singleflightFunc(id string) (any, error) {
//1.从redis查询商铺缓存,是string类型的
val, err := db.RedisClient.Get(context.Background(), ShopKeyPriex+id).Result()
num++
fmt.Println(num)
if err == nil { //若redis存在该缓存,直接返回
//有缓存,但可能是控制,需要判断
if val == "" {
return "", nil
}
var shop model.TbShop
sonic.UnmarshalString(val, &shop)
return shop, nil
} else if err == redis.Nil { //2.若是redis没有该缓存,从mysql中查询
tbSop := query.TbShop
idInt, _ := strconv.Atoi(id)
shop, err := tbSop.Where(tbSop.ID.Eq(uint64(idInt))).First()
if err == gorm.ErrRecordNotFound {
//3.mysql若不存在该商铺,返回错误
//需要往redis中写入空值,防止缓存穿透,并设置较短的过期时间
_, _ = db.RedisClient.Set(context.Background(), ShopKeyPriex+id, "", CacheNullTTL).Result()
return "", fmt.Errorf("this shop not found")
}
if err != nil {
slog.Error("mysql find shop by id bad", "error", err)
return "", err
}
//4.找到商铺,写回redis,并发送给客户端
//把shop进行序列化,不然写入redis会出错。序列化就是把该数据对象变成json,即是变成一个字符串
//添加随机的ttl,解决缓存雪崩
v, _ := sonic.Marshal(shop) //这里使用github.com/bytedance/sonic
_, err = db.RedisClient.Set(context.Background(), ShopKeyPriex+id, v, CacheShopTTL+time.Duration(rand.Int31n(10000))).Result()
if err != nil {
slog.Error("redis set val bad", "error", err)
return "", err
}
return val, nil
} else { //若redis查询出错,返回错误
slog.Error("redis get val bad", "error", err)
return "", err
}
}测试
用go语言写个测试程序,查看服务端的函数调用次数。
var success int32 = 0 //请求的成功数
var send int32 = 0 //成功发起请求的次数(即是成功发送http请求的次数)
func main() {
num := pflag.IntP("num", "n", 500, "number of requests")
pflag.Parse()
fmt.Println("num:", *num)
var wg sync.WaitGroup
wg.Add(*num)
for i := 0; i < *num; i++ {
go func() {
client := &http.Client{Timeout: 10 * time.Second}
req, err := http.NewRequest("GET", "http://localhost:30000/shop/2", nil)
if err != nil {
fmt.Println("Error creating request: %v", err)
wg.Done()
return
}
resp, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request: %v", err)
wg.Done()
return
}
atomic.AddInt32(&send, 1)
defer resp.Body.Close()
_, err = io.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error reading response body: %v", err)
wg.Done()
return
}
if resp.StatusCode == 200 {
atomic.AddInt32(&success, 1)
}
wg.Done()
}()
}
wg.Wait()
fmt.Println("success:", success, " send:", send)
}总结
缓存出现问题的原因和解决方案如下:
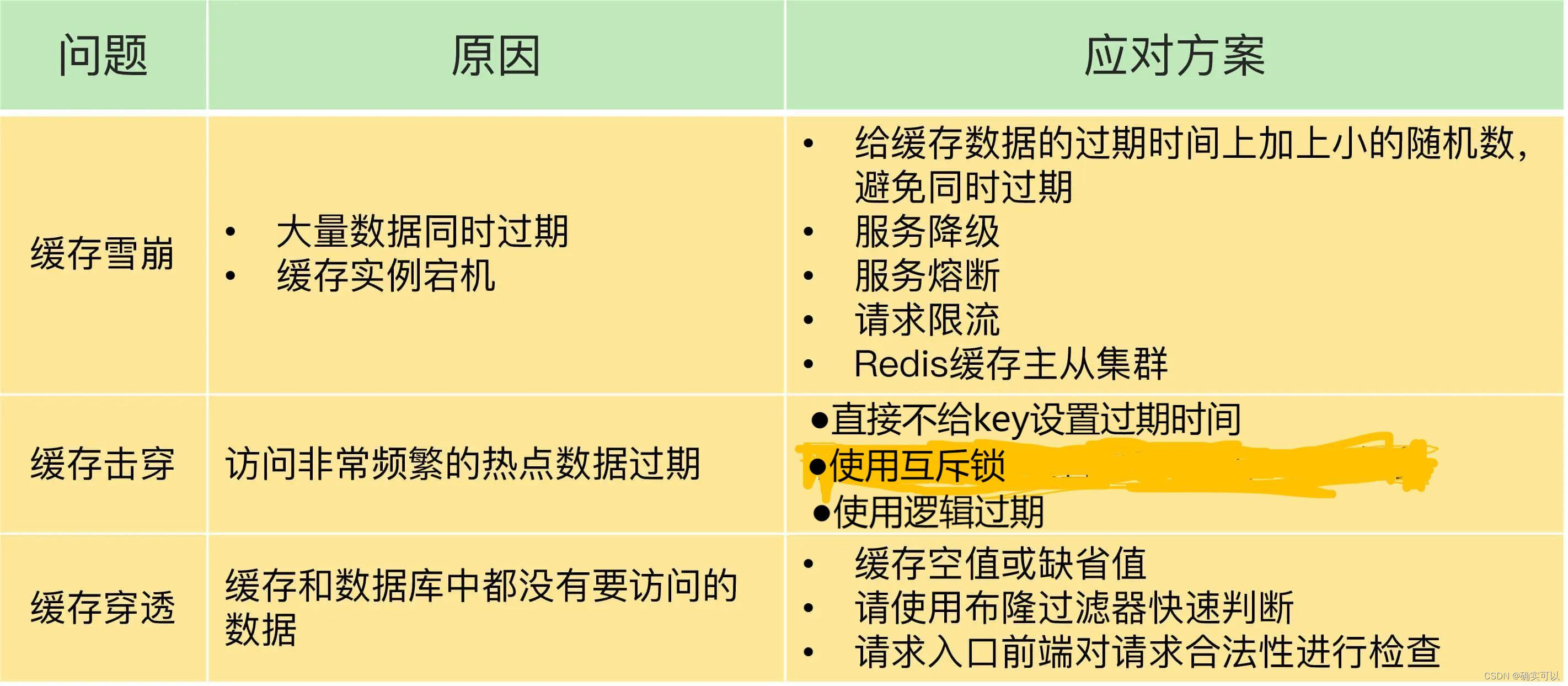
该图来自 极客时间专栏《Redis 核心技术与实战》,再经过一些修改
很明显,服务熔断、服务降级、请求限流都是属于"有损"方案,再保证数据库和整体系统稳定的同时,也是会对业务应用带来负面影响的,要是这些方案有好处又无损的话,平常时候怎么不使用呢。
- 使用服务降级,有部分数据的请求就只能返回错误信息,无法正常处理
- 使用服务熔断,那么整个缓存系统的服务都会被暂停,影响的业务范围是更大的。
- 使用限流机制后,整个业务系统的吞吐率会下降,即是能并发处理的用户请求会减少,那当然是会影响到用户体验。
所以, 尽量是使用预防式方案:
- 针对缓存雪崩:合理设置数据过期时间,以及搭建高可用缓存集群
- 针对缓存击穿:再缓存访问非常频繁的热点数据时,不要设置过期时间
- 针对缓存穿透:提前在入口前端实现恶意请求检查;或者规范数据库的数据删除操作,避免误删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









