标注数据:
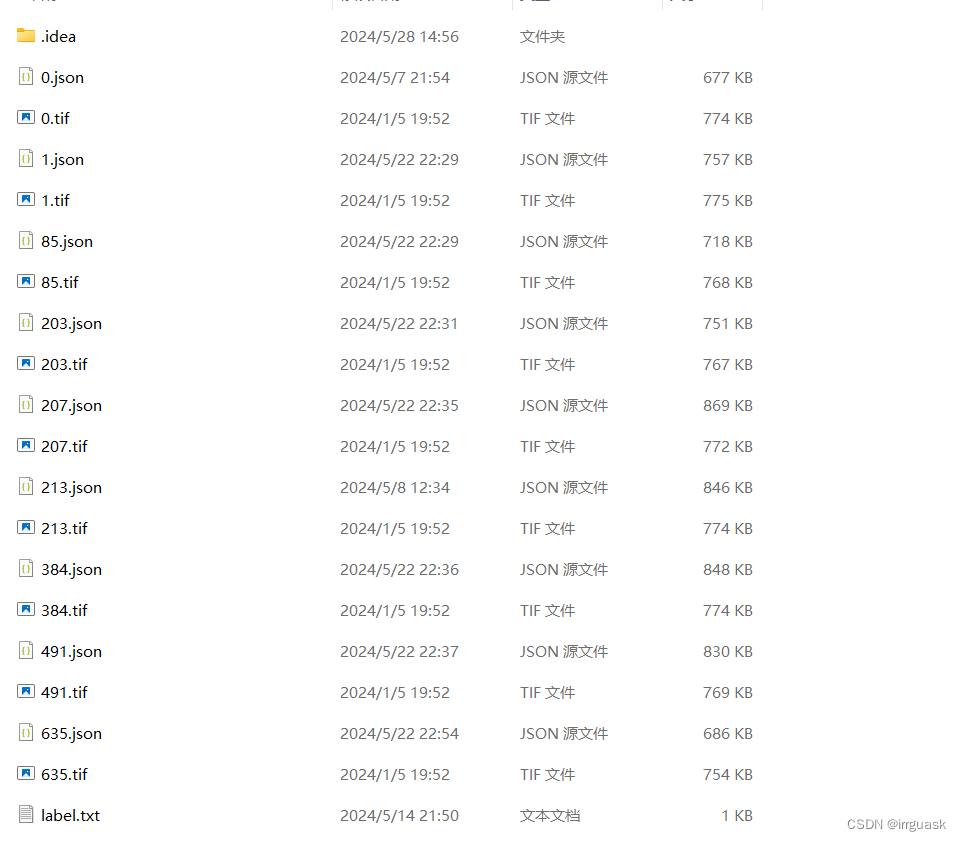
转换后数据:

1.创建虚拟环境,安装版本号为3.16.2的labelme。
具体操作步骤参考我另一篇博客,点击下方链接:
标注工具labelme安装及使用Win10_labelme使用指南 annotation-优快云博客文章浏览阅读1k次,点赞17次,收藏17次。Github上面有官方教程,我的安装过程供大家参考Github链接:GitHub - labelmeai/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point _labelme使用指南 annotation https://blog.youkuaiyun.com/m0_57324918/article/details/138353380
https://blog.youkuaiyun.com/m0_57324918/article/details/138353380
2.将labelme标注的img影像和json文件还有label.txt放在同一个文件夹,如下图所示。(注:我这里用的是遥感影像,大家可根据具体情况选择你的标注数据类型,一般是jpg格式的。)
3.将labelme标注结果转为PascalVOC语义分割的数据集的转换代码:
from __future__ import print_function
import argparse
import glob
import json
import os
import os.path as osp
import sys
import numpy as np
import PIL.Image
import base64
import labelme
from labelme import utils
from sklearn.model_selection import train_test_split
import xml.etree.ElementTree as ET
def main(args):
os.makedirs(args.output_dir, exist_ok=True)
os.makedirs(osp.join(args.output_dir, "JPEGImages"), exist_ok=True)
os.makedirs(osp.join(args.output_dir, "SegmentationClass"), exist_ok=True)
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"), exist_ok=True)
os.makedirs(osp.join(args.output_dir, "SegmentationClassVisualization"), exist_ok=True)
os.makedirs(osp.join(args.output_dir, "Annotations"), exist_ok=True) # 创建Annotations目录
saved_path = args.output_dir
os.makedirs(osp.join(saved_path, "ImageSets", "Segmentation"), exist_ok=True)
print('Creating dataset:', args.output_dir)
class_names = []
class_name_to_id = {}
with open(args.labels) as f:
for i, line in enumerate(f.readlines()):
class_id = i + 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == '__ignore__'
continue
elif class_id == 0:
assert class_name == '_background_'
class_names.append(class_name)
class_names = tuple(class_names)
print('class_names:', class_names)
out_class_names_file = osp.join(args.output_dir, 'class_names.txt')
with open(out_class_names_file, 'w') as f:
f.writelines('\n'.join(class_names))
print('Saved class_names:', out_class_names_file)
colormap = labelme.utils.label_colormap(255)
for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
print('Generating dataset from:', label_file)
try:
with open(label_file) as f:
data = json.load(f)
base = osp.splitext(osp.basename(label_file))[0]
out_img_file = osp.join(args.output_dir, 'JPEGImages', base + '.jpg')
img_data = data['imageData']
img = utils.img_b64_to_arr(data['imageData'])
img_shape = img.shape
PIL.Image.fromarray(img).save(out_img_file)
out_png_file = osp.join(args.output_dir, 'SegmentationClass', base + '.png')
lbl = labelme.utils.shapes_to_label(img_shape=img.shape, shapes=data['shapes'], label_name_to_value=class_name_to_id)
labelme.utils.lblsave(out_png_file, lbl)
out_viz_file = osp.join(args.output_dir, 'SegmentationClassVisualization', base + '.jpg')
viz = labelme.utils.draw_label(lbl, img, class_names, colormap=colormap)
PIL.Image.fromarray(viz).save(out_viz_file)
# Generate XML file
out_xml_file = osp.join(args.output_dir, 'Annotations', base + '.xml')
generate_xml(label_file, class_name_to_id, osp.join(args.output_dir, 'Annotations'))
except Exception as e:
print('这张图像有错误:', e)
continue
# Split files for txt
txtsavepath = os.path.join(saved_path, 'ImageSets', 'Segmentation')
ftrainval = open(os.path.join(txtsavepath, 'trainval.txt'), 'w')
ftest = open(os.path.join(txtsavepath, 'test.txt'), 'w')
ftrain = open(os.path.join(txtsavepath, 'train.txt'), 'w')
fval = open(os.path.join(txtsavepath, 'val.txt'), 'w')
total_files = os.listdir(osp.join(args.output_dir, 'SegmentationClass'))
total_files = [i.split("/")[-1].split(".png")[0] for i in total_files]
for file in total_files:
ftrainval.write(file + "\n")
train_files, val_files = train_test_split(total_files, test_size=0.1, random_state=42)
for file in train_files:
ftrain.write(file + "\n")
for file in val_files:
fval.write(file + "\n")
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
def generate_xml(label_file, class_name_to_id, out_dir):
# 构造XML文件的基础结构
root = ET.Element('annotation')
# 读取JSON文件以获取标注数据
with open(label_file, 'r') as f:
data = json.load(f)
img_name = osp.splitext(osp.basename(label_file))[0]
ET.SubElement(root, 'filename').text = f"{img_name}.jpg"
size = ET.SubElement(root, 'size')
ET.SubElement(size, 'width').text = str(data['imageWidth'])
ET.SubElement(size, 'height').text = str(data['imageHeight'])
if 'imageDepth' in data:
ET.SubElement(size, 'depth').text = str(data['imageDepth'])
else:
ET.SubElement(size, 'depth').text = '3' # 假设图像为三通道
# 遍历标注中的形状,并为每个形状生成XML对象
for shape in data['shapes']:
label = shape['label']
if label not in class_name_to_id:
continue # 如果类别名不在class_name_to_id字典中,则跳过
points = shape['points']
# 假设标注的形状是矩形,并提取其坐标
x1, y1 = points[0]
x2, y2 = points[1]
obj = ET.SubElement(root, 'object', {
'name': label,
'pose': 'Unspecified',
'truncated': str(shape.get('truncated', 0)),
'difficult': str(shape.get('difficult', 0))
})
bndbox = ET.SubElement(obj, 'bndbox')
ET.SubElement(bndbox, 'xmin').text = str(int(x1))
ET.SubElement(bndbox, 'ymin').text = str(int(y1))
ET.SubElement(bndbox, 'xmax').text = str(int(x2))
ET.SubElement(bndbox, 'ymax').text = str(int(y2))
# 将XML元素树写入文件
out_file = osp.join(out_dir, f"{img_name}.xml")
tree = ET.ElementTree(root)
tree.write(out_file)
if __name__ == '__main__':
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--input_dir', type=str, help='input annotated directory', required=False, default=r'O:\Browser\FirfoxDownLoad\labelmeproject2\img')
parser.add_argument('--output_dir', type=str, help='output dataset directory', required=False, default=r'O:\Browser\FirfoxDownLoad\labelmeproject2\labelmeSet_VOC')
parser.add_argument('--labels', type=str, help='labels file', required=False, default=r'O:\Browser\FirfoxDownLoad\labelmeproject2\img\label.txt')
argsInput = parser.parse_args()
main(argsInput)
在main声明里面输入自己的路径,运行就行了。

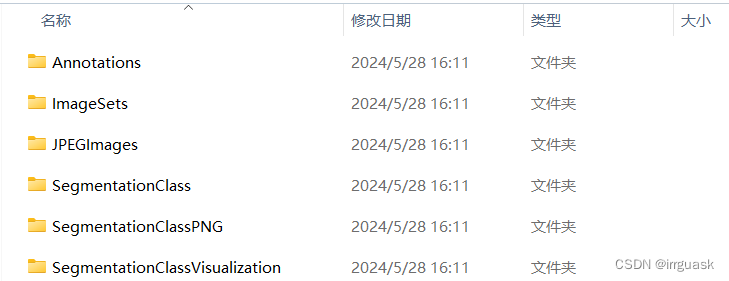
成功后即会生成以下目录:


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











