






回溯三部曲:
- 回溯函数模板返回值以及参数
- 回溯函数终止条件
- 回溯搜索的遍历过程
强调,回溯法中递归函数参数很难一次性确定下来,一般先写逻辑,需要啥参数了,填什么参数。
树的宽度就是集合的大小,树的深度就是递归的深度。
77. 组合
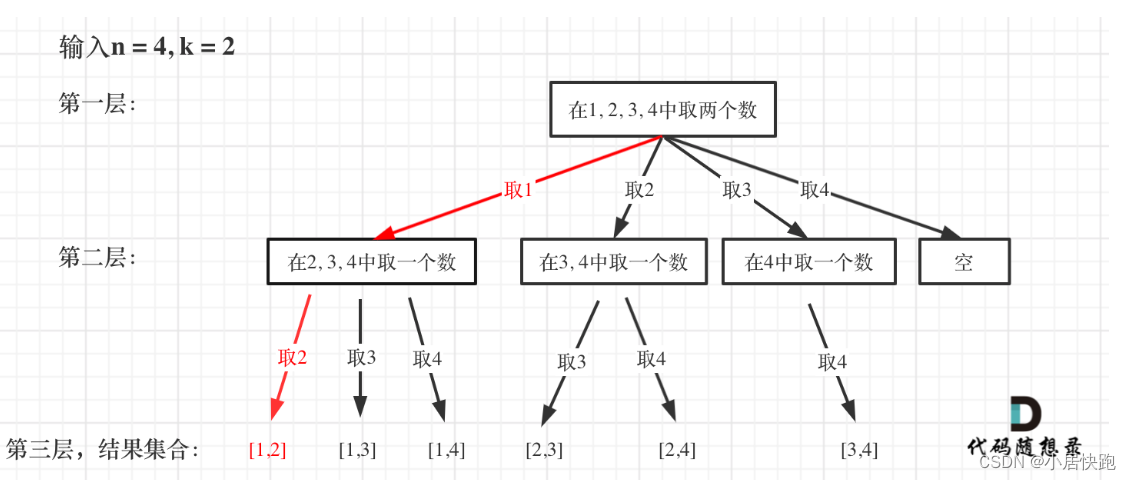
startIndex来记录下一层递归,搜索的起始位置。
如果没有startIndex,输出的结果将会是[[1,1],[1,2],[1,3],[1,4],[2,1],[2,2],[2,3],[2,4],[3,1],[3,2],[3,3],[3,4],[4,1],[4,2],[4,3],[4,4]]
剪枝:
已选择的元素个数:path.size(),还需要的元素个数:k - path.size(),在集合n中至多从i = n - (k - path.size()) + 1开始遍历:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++)
216.组合总和III
本题:传入sum
剪枝:
1、
if (sum > targetSum) { // 剪枝操作
return;
}
2、
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) { // 剪枝
17.电话号码的字母组合
1、把string放进path里可以用 path += string,可是怎么拿出来呢?pop_back()
也不用+=,用push_back(i),但这个i必须是char类型的
2、我的错误:当我尝试使用 digits[startIndex] 作为键时,实际上是用字符(如 ‘2’,‘3’ 等)而不是整数。因此需要先- ‘0’。
3、可以不用map,直接用数组
4、传入index:用来记录遍历到第几个数字,同时也表示树的深度。
5、终止条件必须是:
if (index == digits.size()) {
result.push_back(s);
return;
}
而不能是if (path.size() == index),否则一开始path.size()=0,index=0就是满足的,直接return了。
也不能是if (path.size() == index + 1)这样会数组越界,并且永远也不会成立。
39. 组合总和
集合内元素不重复,但是可以重复取用
1、我应该添加一个条件来确保递归调用在 sum 超过 target 时停止。否则会无限递归。
216.组合总和III这道题即使不加这个也不会无限递归,因为它的子集个数必须是k,而本题对子集个数没有限制。
2、虽然本题可以重复取值,但依然要用startIndex,因为它是保证树层上的去重的,而startIndex = i + 1才是树枝上去重的。
剪枝:(要先排序)
排序之后,如果下一层的sum(即本层的sum + candidates[i])大于target,就不进入下一层递归
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
如果只求情况个数,用动态规划法
40.组合总和II
集合中有重复元素,并且不可以重复取用
1、排序+used数组:保证没有两个组合是相同的
131. 分割回文串
本质上还是组合问题
1、切割线用什么表示?可以用i吗?不可以,就是用startIndex
2、切割的长度用什么表示?可以也用i吗?不可以,[startIndex, i]就是要截取的子串
3、递归如何终止?
优化:
动态规划思想:给定一个字符串s, 长度为n, 它成为回文字串的充分必要条件是s[0] == s[n-1]且s[1:n-1]是回文字串。
isPalindrome[i][j] 代表 s[i:j] (双边包括)是否是回文字串
93. 复原 IP 地址
1、pointNum:用于记录添加".“的数量,本题不需要真的切割出子串,在原本的字符串上添加”."即可
2、终止条件:本题不能用切割线切到最后为终止条件,因为字符串只会分为4段
3、如何判断每一段是否合法?
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 必须放在循环内,否则会int溢出
return false;
}
}
return true;
}
4、往字符串里加入、删除不用push_back、pop_back,因为不是单个字符,用insert、erase
5、在s中加入了’.',用i遍历时,需要修改其遍历的长度吗?不需要,因为i遍历到倒数第四个地方停止也没关系,if中会判断最后一段是否合法。
if (isValid(s, startIndex, s.size() - 1))中的s的长度是比原来长了3的
i = i + 2
78.子集
收集树形结构中每一个节点的结果,因此不需要任何剪枝!
1、怎么把根节点[]放进去?
把收集子集 result.push_back(path);放在终止条件的上面
2、终止条件:
if (startIndex >= nums.size()) {
return;
}
其实可以不加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
90. 子集 II
集合中有重复元素,并且不可以重复取用
491. 递增子序列
1、不排序也可以用used数组吗?不能!!使用set来对本层元素进行去重
为什么递归函数上面的uset.insert(nums[i]);,下面却没有对应的pop之类的操作?而used数组中就需要?
这是因为unordered_set uset; 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!而used数组一直是同一个。
2、怎么保证递增?
nums[i] >= path.back() 不是path.top()
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
3、终止条件:
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,因为要取树上的所有节点
}
优化:
不用set,用数组来做去重操作:
int used[201] = {0}; // 题目说数值范围[-100, 100]
数组,set,map都可以做哈希表,而且数组干的活,map和set都能干,但如果数值范围小的话能用数组尽量用数组。
46. 全排列
1、怎么不取上次已取的?怎么避免这种情况:[[0,0],[0,1],[1,0],[1,1]]
使用used数组,记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
这里的used数组和前面的排序+used数组的作用不一样。
47. 全排列 II
集合中有重复元素,并且不可以重复取用
1、怎么样把上面的used数组两种作用结合起来?
332. 重新安排行程
深度优先搜索
1、如何记录映射关系?
unordered_map<string, map<string, int>> targets:unordered_map<出发机场, map<到达机场, 航班次数>> targets
此时tickets已被映射到targets上,因此在回溯函数中不用传入tickets,而是传入tickets.size()
2、注意函数返回值我用的是bool!
因为我们只需要找到一个行程,就是在树形结构中唯一的一条通向叶子节点的路线
3、回溯的过程中,如何遍历一个机场所对应的所有机场呢?
for (pair<const string, int>& target : targets[result[result.size() - 1]])
4、为什么string前面必须加const?否则会报错
在 C++ 中,当你遍历一个 map 的时候,迭代器指向的元素类型是 pair<const KeyType, ValueType>。这里的 const表明键(key)是不可变的。这是因为std::map` 的基础实现是红黑树(一种自平衡二叉搜索树),在这种数据结构中,修改键的值可能会破坏树的排序,从而使整个数据结构无效。
因此,当你尝试使用非 const 引用(例如 pair<string, int>&)来绑定到这样的键值对时,编译器会报错,因为你试图绑定到一个带有 const 的键。
所以,正确的做法是使用 const 在引用类型中,如下所示:
for (const pair<const string, int>& target : targets[result[result.size() - 1]]) {
// ...
}
也可以使用 auto :
for (const auto& target : targets[result[result.size() - 1]]) {
// ...
}
这样做的好处是代码更简洁,并且避免了类型匹配错误。在这个例子中,auto 将自动推断为 const pair<const string, int>& 类型。
51. N 皇后
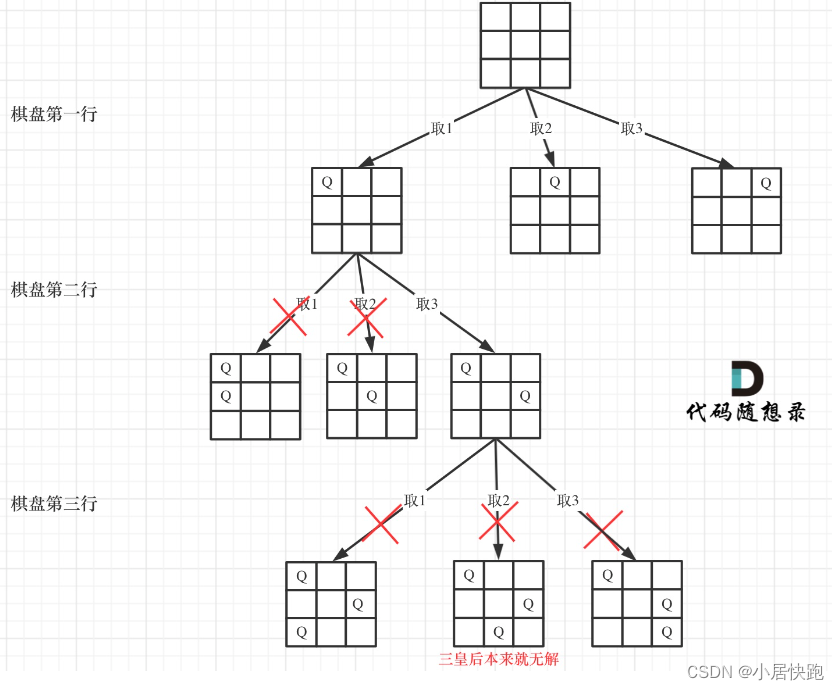
棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度
1、为什么没有在同行进行检查呢?
因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
2、chessboard如何初始化?
vector chessboard(n, string(n, ‘.’));
3、isValid中的遍历必须要倒着写,因为应该是从当前点发散去找它的同列、对角线
37. 解数独
二维递归,比n皇后多了一维
1、怎么判断九方格里是否重复
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
473. 火柴拼正方形
1、index代表当前遍历到那个值了
i的取值是0,1,2,3
edges代表每条边当前的长度
bool dfs(int index, vector<int> &matchsticks, vector<int> &edges, int len) {
if (index == matchsticks.size()) {
return true;
}
for (int i = 0; i < edges.size(); i++) {
edges[i] += matchsticks[index]; // 尝试放置当前火柴棒
if (edges[i] <= len) { // 只有当当前边的长度不超过限制时,才继续递归搜索
bool success = dfs(index + 1, matchsticks, edges, len); // 递归调用,尝试放置下一根火柴棒
if (success) {
return true; // 如果成功,直接返回
}
// 如果失败,进行回溯,即撤销之前的操作
}
edges[i] -= matchsticks[index]; // 回溯,撤销放置操作
}
return false; // 所有可能都尝试过,仍然无法成功,返回 false
}
2、返回的是bool
3、从大到小排序可以减少搜索量(?)
698. 划分为k个相等的子集
1、如果是划分为2个相等的子集就是01背包问题
2、使用上一题的方法会超时
3、优化方法:
- 使用一个 memo 数组来存储已经计算过的状态,避免重复计算。
- 加入了一些剪枝条件,例如跳过相同的数字,以及当一个桶为空时,不再继续尝试更多。
- 在 canPartitionKSubsets 函数中,我们检查了最大的数字是否大于目标值 len,如果是,则直接返回 false。
class Solution {
public:
bool canPartition(vector<int>& nums, int k, int start, int curSum, int targetSum, int& used, unordered_map<int, bool>& memo) {
if (k == 1) return true; // 只剩下一个子集时,剩下的数字一定可以填满它
if (curSum == targetSum) return canPartition(nums, k - 1, 0, 0, targetSum, used, memo); // 当前子集完成,继续下一个
if (memo.count(used)) return memo[used]; // 如果当前状态已探索过,直接返回结果
for (int i = start; i < nums.size(); i++) {
if (((used >> i) & 1) == 0 && curSum + nums[i] <= targetSum) { // 如果数字未被使用且可以放入当前子集
used |= 1 << i; // 标记为已使用
if (canPartition(nums, k, i + 1, curSum + nums[i], targetSum, used, memo)) return true; // 继续探索
used &= ~(1 << i); // 回溯,标记为未使用
}
}
memo[used] = false; // 记录当前状态
return false;
}
bool canPartitionKSubsets(vector<int>& nums, int k) {
int sum = accumulate(nums.begin(), nums.end(), 0);
if (sum % k != 0) return false;
int targetSum = sum / k;
sort(nums.begin(), nums.end(), greater<int>());
if (nums[0] > targetSum) return false; // 如果最大的数比目标值大,则不可能分割
int used = 0; // 用一个整数来表示哪些数字已经被使用过
unordered_map<int, bool> memo; // 使用哈希表来存储状态
return canPartition(nums, k, 0, 0, targetSum, used, memo);
}
};
组合问题:
如果是一个集合来求组合的话,就需要startIndex。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合
排列问题:
for不是从startIndex开始,而是从0开始了。
怎么不重复取本次排列里的元素?used数组
集合中有重复元素:
树枝去重:同一个组合内不能有重复的元素
树层去重:同一组合内可以重复,但两个组合不能相同(排序+used数组)
组合问题和分割问题:
收集叶子节点的结果
子集问题:
收集树的所有节点的结果
什么时候用bool、什么时候用void?
用bool的题目:473. 火柴拼正方形、698. 划分为k个相等的子集


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









