







一 简介
Adaboost(Adaptive Boosting, 自适应性增强),是一种集成学习模型,使用boosting的思想。它通过将多个简单模型(也称为弱学习器)组成一个复杂模型(强学习期器)来工作。
Adaboost在一系列应用场景中都表现出了显著的性能优势,从文本分类、图像识别到生物信息等领域都有广泛的应用
什么是Adaboost
Adaboost算法的核心思想是在每一轮的迭代中,通过增加上一轮弱学习器错误分类的样本权重,并减少那些被正确分类的样本权重,来“迫使”新的学习器更加关注那些“难以分类”的样本。随后,算法将所有弱学习器的预测结果进行加权平均或加权投票,以得到最终的强学习器
基础概念
在深入了解Adaboost算法前,有几个基础概念需要了解,方便理解Adaboost的工作原理和实际应用
-
集成学习(Emsemble Learning)
集成学习是一种机器学习范式,意在结合多个模型已改善单个模型无法达到的整体性能。这意味着将多个弱学习器(或基础模型)组合到一个强学习器
-
弱学习器和强学习器
- 弱学习器(Weak Learner):一个弱学习器是一个性能略优于随机猜测的机器学习算法。在二分类问题中,准确率略高于50%
- 强学习器(Strong Learner):相对于弱学习器,强学习器是一个在给定任务上性能表现非常好的模型,准确率远高于随机猜测
算法步骤
- 首先,初始化训练数据的权值分布D1,假设N个训练样本数据,则每一个训练样本最开始时,被赋予相同权重:w1 = 1/N
- 然后,训练弱分类器H1,具体训练过程是:如果某个训练样本在H1中分类错误,那么在构造下一个训练集中,它对应的权值要增大,相反,如果在H1中分类正确,那么在下一个训练中,其权重要减小。权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代下去
- 最后,将各个训练得到的弱分类器组合成一个强分类器。各个分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用
二 Adaboost算法过程
给定训练集:{(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)},其中yi属于{1,-1}用于表示训练样本的类别标签,i=1,…,N。Adaboost的目的就是从训练集数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器
-
相关符号定义

Adaboost算法流程:
-
首先,初始化训练数据的权值分布。每个训练样本开始时都被赋予相同的权值:w=1/N,这样训练样本集的初始权值分布Di(i):
D 1 ( i ) = ( w 1 , w 2 , . . . , w N ) = ( 1 N , 1 N , . . . , 1 N ) D_1(i)=(w_1,w_2,...,w_N)=(\frac{1}{N},\frac{1}{N},...,\frac{1}{N}) D1(i)=(w1,w2,...,wN)=(N1,N1,...,N1)
-
进行迭代t = 1,2,…, N
-
选取一个当前误差率最低的弱分类器h作为第t个基本分类器Ht,并计算弱分类器ht:X→{-1,1},该弱分类器在分布Di上的误差为:
$$
e_t = P(H_t(x_i)\neq y_i)=\sum_{i=1}^N {w_{ti}I(H_t(x_i)\neq y_i})$$
PS:由上述公式可知,Ht(x)在训练数据集上的误差率et就是被Ht(x)误分类样本的权值之和
-
计算该弱分类器在最终分类器中所占的权重(弱分类器权重用α表示):
α t = 1 2 ln ( 1 − e t e t ) \alpha_t = \frac{1}{2} \ln(\frac{1-e_t}{e_t}) αt=21ln(et1−et)
-
更新训练样本的权值分布Dt+1:
D t + 1 = D t ( i ) e x p ( − α t y t H t ( x i ) ) Z t D_{t+1} = \frac{D_t(i)exp(-\alpha_ty_tH_t(x_i))}{Z_t} Dt+1=ZtDt(i)exp(−αtytHt(xi))
其中,Zt为归一化常数:
Z t = 2 e t ( 1 − e t ) Z_t = 2\sqrt{e_t(1-e_t)} Zt=2et(1−et)
-
-
最后,按弱分类器权重αt组合各个弱分类器,即
f ( x ) = ∑ t = 1 T α t H t ( x ) f(x) = \sum_{t=1}^{T}\alpha_tH_t(x) f(x)=t=1∑TαtHt(x)
通过符号函数sign的作用,得到一个强分类器为:
H f i n a l = s i g n ( f ( x ) ) = s i n g ( ∑ t = 1 T α t H t ( x ) ) H_{final}=sign(f(x))=sing(\sum_{t=1}^{T}\alpha_tH_t(x)) Hfinal=sign(f(x))=sing(t=1∑TαtHt(x))
补充:

综上推导,可得样本分错与分对时,其权值更新的公式为:

三 Adaboost实例
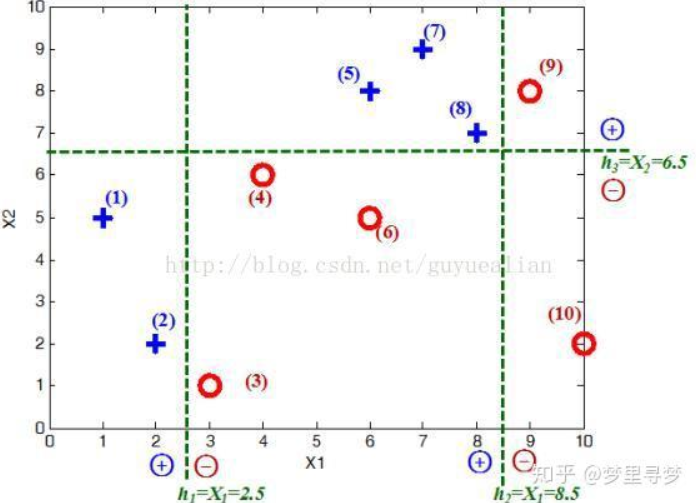
给定如图所示训练样本,弱分类器采用平行于坐标轴的直线,用Adaboost算法实现强分类过程
-
数据分析
将10个样本作为分类器,根据X和Y的对应关系,可以把这10个数据分为两类,图中用“+”表示类别1,用“O”表示类别-1。本例使用水平或者垂直的直线作为分类器,图中已经给出了三个弱分类器,即:
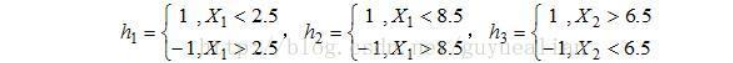
-
初始化
首先需要初始化训练样本数据的权值分布,每个训练样本最开始时都被赋予相同的权值:wi=1/N,这样训练样本集的初始值分布为D1(i):

-
第一次迭代 t=1:
初始的权值分布D1为1/N(10个数据,每个数据的权值皆初始化为0.1)
D1 = (0.1,0.1, 0.1, 0.1, 0.1, 0.1,0.1, 0.1, 0.1, 0.1)
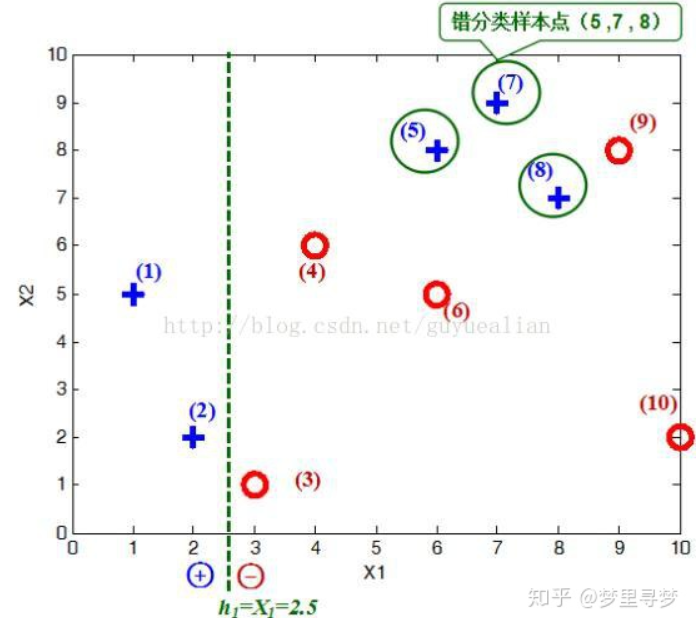
在权值分布D1的情况下,取已知的三个弱分类器h1,h2,h3中误差率最小的分类器作为第一个基本分类器H1(x)(三个弱分类器的误差率都是0.3,那就取第一个)
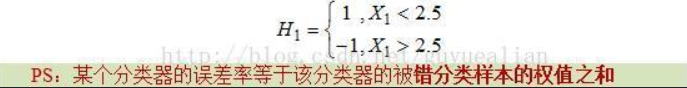
在分类器H(x)=h1情况下,样本点5/7/8被分错,因此基本分类器H1(x)的误差率为:

可见,被误分类样本的权值之和影响误差率e,误差率e影响基本分类器在最终分类器中所占的权重α
然后,更新训练样本数据的权值分布,用于下一轮迭代,对于正确分类的训练样本1/2/3/4/6/9/10(共7个)的权值更新为:
这样,第一轮迭代后,最后得到各个样本数据新的权值分布:
D2=(1/14,1/14,1/14,1/14,1/6,1/14,1/6,1/6,1/14,1/14)
这样样本数据5/7/8被H1(x)分错了,所以它们的权值由之前的0.1增大到1/6;而其他数据分类正确,它们的权值皆由之前的0.1减小到1/14,下表是权值分布的变换情况
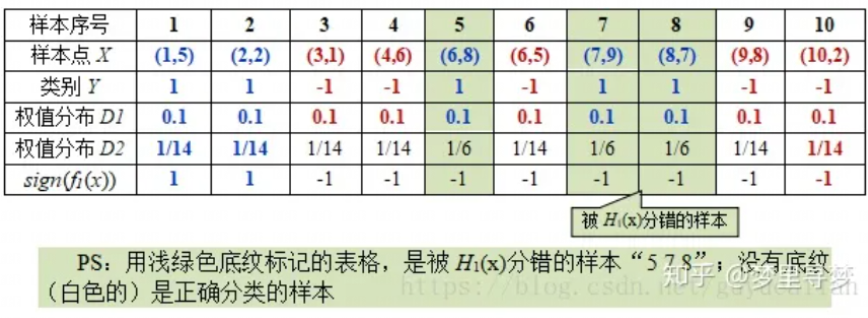
可得分类函数f1(x) = α1H1(X)=0.4236H1(x)。此时,组合一个基本分类器sign(f1(x))作为强分类器在训练数据集上有3个误分类点(即5/7/8),此时强分类器的训练错误为0.3
-
第二次迭代 t=2
在权值分布D2的情况下,再取三个弱分类器h1、h2、h3中误差率最小的分类器作为第二个基本分类器H2(x):
① 当取弱分类器h1=X1=2.5时,此时被错分的样本点为“5 7 8”:
误差率e=1/6+1/6+1/6=3/6=1/2;
② 当取弱分类器h2=X1=8.5时,此时被错分的样本点为“3 4 6”:
误差率e=1/14+1/14+1/14=3/14;
③ 当取弱分类器h3=X2=6.5时,此时被错分的样本点为“1 2 9”:
误差率e=1/14+1/14+1/14=3/14;
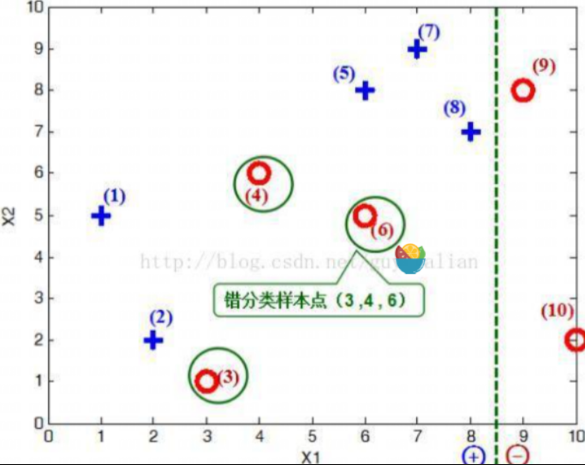
因此,取当前最小的分类器h2作为第二个基本分类器H2(x)
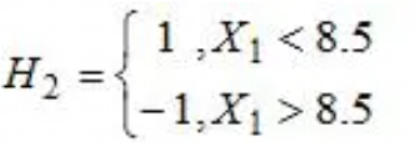
显然,H2(x)把3/4/6分错了,根据D2可知它们权值为D2(3)=1/14,D2(4)=1/14, D2(6)=1/14,所以H2(x)在训练数据集上的误差率:

这样,第二轮迭代后,最后得到各样本数据新的权值分布为:
D3=(1/22,1/22,1/6,1/6,7/66,1/6,7/66,7/66,1/22,1/22)
下表给出了权值分布的变换情况:
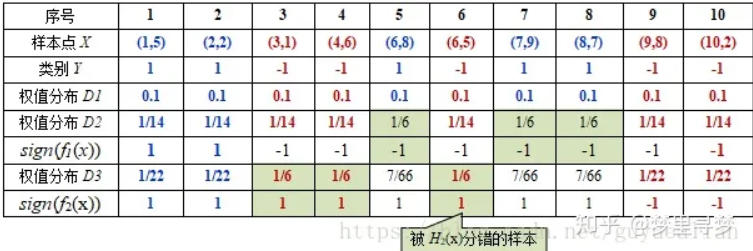
可得**分类函数:f2(x)=0.4236H1(x) + 0.6496H2(x)。此时,组合两个基本分类器sign(f2(x))作为强分类器在训练数据集上有3个误分类点(即3 4 6),此时强分类器的训练错误为:0.3
-
第三次迭代t=3
在权值分布D3的情况下,再取三个弱分类器h1、h2和h3中误差率最小的分类器作为第3个基本分类器H3(x):
① 当取弱分类器h1=X1=2.5时,此时被错分的样本点为“5 7 8”:
误差率e=7/66+7/66+7/66=7/22;
② 当取弱分类器h2=X1=8.5时,此时被错分的样本点为“3 4 6”:
误差率e=1/6+1/6+1/6=1/2=0.5;
③ 当取弱分类器h3=X2=6.5时,此时被错分的样本点为“1 2 9”:
误差率e=1/22+1/22+1/22=3/22;
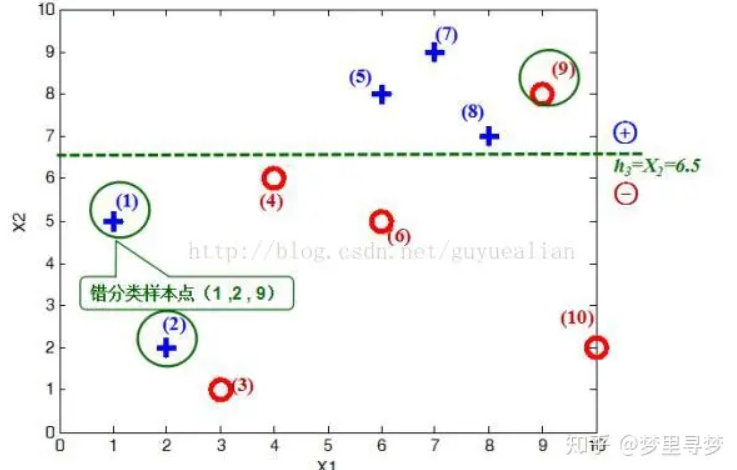
因此,取当前最小的分类器h3作为第3个基本分类器H3(x):

这样,第3轮迭代后,得到各个样本数据新的权值分布
D4=(1/6,1/6,11/114,11/114,7/114,11/114,7/114,7/114,1/6,1/38)
下表给出了权值分布的变换情况:
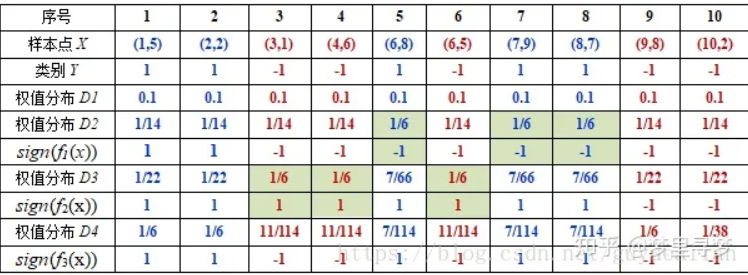
可得**分类函数:f3(x)=0.4236H1(x) + 0.6496H2(x)+0.9229H3(x)。此时,组合三个基本分类器sign(f3(x))作为强分类器,在训练数据集上有0个误分类点。至此,整个训练过程结束。
整合所有分类器,可得最终的强分类器为:
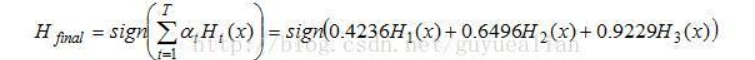
这个强分类器Hfinal对训练样本的错误率为0!
四 Ababoost的优点和缺点
优点:
- Ababoost提供一种框架,在框架内可以使用各种方法构建子分类器。可使用简单的弱分类器,不用对特征进行筛选,也不存在过拟合的现象
- Ababoost算法不需要弱分类器的先验知识,最后得到的强分类器的分类精度依赖于所有弱分类器,无论是应用于人造数据还是真实数据,Adaboost都能显著提高学习精度
- Ababoost算法不需要预先知道弱分类器的错误上线,且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,可以深挖分类的能力。Ababoost可以根据弱分类器的反馈,自适应地调整假定的错误率,执行的效率高
- Ababoost对同一个训练样本集训练不同的弱分类器,按照一定方法把这些弱分类器集合起来,构造一个分类能力很强的强分类器
缺点:
在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。此外,Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
Adaboost算法的某些特性是非常好的,这里主要介绍Adaboost的两个特性。(1)是训练的错误率上界,随着迭代次数的增加,会逐渐下降;(2)是Adaboost算法即使训练次数很多,也不会出现过拟合的问题。
参考文章:
http://blog.youkuaiyun.com/v_july_v/article/details/40718799

















 4214
4214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









