






 本文介绍了使用Pandas进行数据处理的多种方法,包括数据合并、重构、聚合等操作,并通过实例展示了如何运用concat、merge及groupby等函数来提高数据分析效率。
本文介绍了使用Pandas进行数据处理的多种方法,包括数据合并、重构、聚合等操作,并通过实例展示了如何运用concat、merge及groupby等函数来提高数据分析效率。
在前面我们已经学习了Pandas基础,第二章我们开始进入数据分析的业务部分,在第二章第一节的内容中,我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。
task_3 我们将学习数据重构
任务1
将数据合并
使用concat方法 合并
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()
这里的concat函数是panda的连接函数
这里参数设置axis=1 是使其横向连接,默认为纵向连接
拓展:
如果其中一个没有另外一个的列,其值将被设置为NaN
如果只想合并相同的列, 我们可以添加上join='inner’参数:
pd.concat([df1, df3], join='inner')
使用DataFrame自带的方法join方法和append的方法合并
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
result.head()

使用Pandas的merge方法和DataFrame的append方法
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()

换一个角度看数据
将我们的数据变为Series类型的数据
text = pd.read_csv('result.csv')
text.head()
# 代码写在这里
unit_result=text.stack().head(20)
unit_result.head()

这里的stack函数就是将行索引变成列索引 即这里的passen这一列 变成了更有层次的series
数据聚合与运算
学习这里先学习了groupby机制
groupby 是可以凭借索引将其重新分类 分组之后对同一个列名使用不同的函数
求和sun、最大值max、最小值min、均值mean、个数(size)
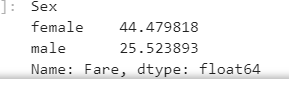
计算泰坦尼克号男性与女性的平均票价 ¶
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means
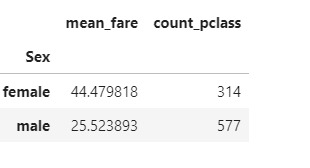
这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名
text.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns=
{'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
统计在不同等级的票中的不同年龄的船票花费的平均值
text.groupby(['Pclass','Age'])['Fare'].mean().head()

得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数)¶
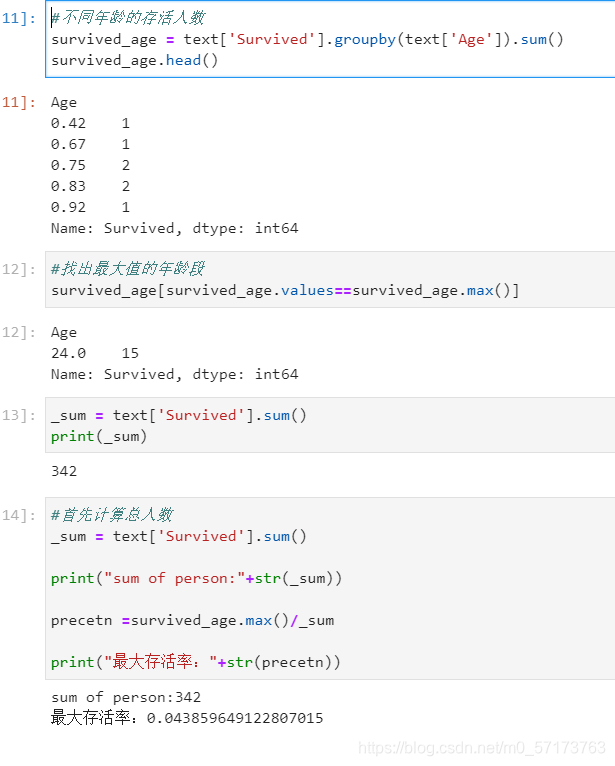
经过这次学习 对数据处理有了更深的了解 在为数据理解做准备 ,希望大佬们指正


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









