






定位问题:
最近一个困扰了我一周的bug,我在使用mamba进行编码时,出现了梯度爆炸的问题。当我独立使用 mamba 模块时,它不会输出任何 NaN 值。但是,当我将其集成到我的模型中时,NaN 值开始出现。有趣的是,它在一台服务器上运行良好,但是当我切换到另一台服务器时,会显示 NaN 值。两台机器都是 Docker 化的,所以我预计不会有任何环境问题,并且我还仔细检查了 nvcc 和相关配置等内容。
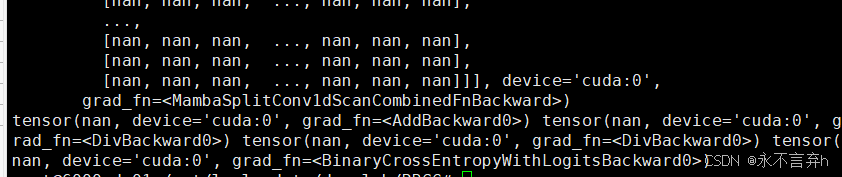

再后来我尝试将mamba源码,直接与我的模块拼接未直接调用mamba的三方库,发现编码依然出现nan值,我便一一查看mamba块的输入。
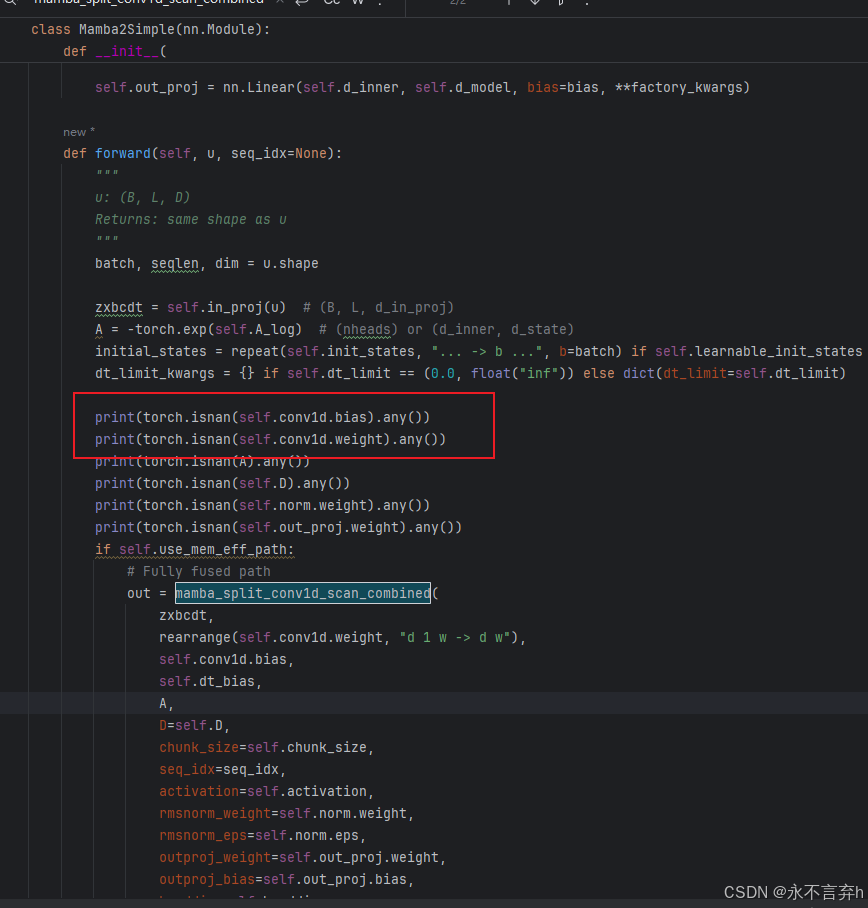
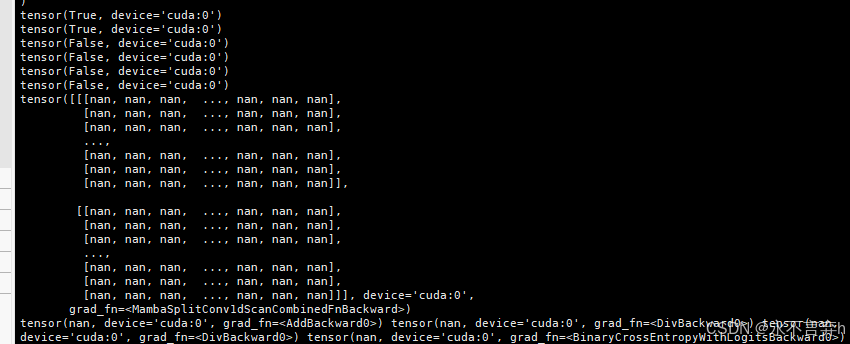 发现原来是卷积层在定义的时候,卷积层的权重中出现了nan值,虽然不清楚为什么,但是这个问题好解决。
发现原来是卷积层在定义的时候,卷积层的权重中出现了nan值,虽然不清楚为什么,但是这个问题好解决。
我在源码中将卷积层初始化即可,代码如下:
def __init__(
self,
d_model,
d_state=128,
d_conv=4,
conv_init=None,
expand=2,
headdim=64,
ngroups=1,
A_init_range=(1, 16),
dt_min=0.001,
dt_max=0.1,
dt_init_floor=1e-4,
dt_limit=(0.0, float("inf")),
learnable_init_states=False,
activation="swish",
bias=False,
conv_bias=True,
# Fused kernel and sharding options
chunk_size=256,
use_mem_eff_path=True,
layer_idx=None, # Absorb kwarg for general module
device=None,
dtype=None,
):
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.d_model = d_model
self.d_state = d_state
self.d_conv = d_conv
self.conv_init = conv_init
self.expand = expand
self.d_inner = self.expand * self.d_model
self.headdim = headdim
self.ngroups = ngroups
assert self.d_inner % self.headdim == 0
self.nheads = self.d_inner // self.headdim
self.dt_limit = dt_limit
self.learnable_init_states = learnable_init_states
self.activation = activation
self.chunk_size = chunk_size
self.use_mem_eff_path = use_mem_eff_path
self.layer_idx = layer_idx
# Order: [z, x, B, C, dt]
d_in_proj = 2 * self.d_inner + 2 * self.ngroups * self.d_state + self.nheads
self.in_proj = nn.Linear(self.d_model, d_in_proj, bias=bias, **factory_kwargs)
conv_dim = self.d_inner + 2 * self.ngroups * self.d_state
self.conv1d = nn.Conv1d(
in_channels=conv_dim,
out_channels=conv_dim,
bias=conv_bias,
kernel_size=d_conv,
groups=conv_dim,
padding=d_conv - 1,
**factory_kwargs,
)
if self.conv_init is not None:
nn.init.uniform_(self.conv1d.weight, -self.conv_init, self.conv_init)
# self.conv1d.weight._no_weight_decay = True
# self.conv1d.bias._no_weight_decay = True
if self.learnable_init_states:
self.init_states = nn.Parameter(torch.zeros(self.nheads, self.headdim, self.d_state, **factory_kwargs))
self.init_states._no_weight_decay = True
self.act = nn.SiLU()
# Initialize log dt bias
dt = torch.exp(
torch.rand(self.nheads, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
)
dt = torch.clamp(dt, min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
self.dt_bias = nn.Parameter(inv_dt)
# Just to be explicit. Without this we already don't put wd on dt_bias because of the check
# name.endswith("bias") in param_grouping.py
self.dt_bias._no_weight_decay = True
# A parameter
assert A_init_range[0] > 0 and A_init_range[1] >= A_init_range[0]
A = torch.empty(self.nheads, dtype=torch.float32, device=device).uniform_(*A_init_range)
A_log = torch.log(A).to(dtype=dtype)
self.A_log = nn.Parameter(A_log)
# self.register_buffer("A_log", torch.zeros(self.nheads, dtype=torch.float32, device=device), persistent=True)
self.A_log._no_weight_decay = True
# D "skip" parameter
self.D = nn.Parameter(torch.ones(self.nheads, device=device))
self.D._no_weight_decay = True
# Extra normalization layer right before output projection
assert RMSNormGated is not None
self.norm = RMSNormGated(self.d_inner, eps=1e-5, norm_before_gate=False, **factory_kwargs)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias, **factory_kwargs)
def forward(self, u, seq_idx=None):
"""
u: (B, L, D)
Returns: same shape as u
"""
batch, seqlen, dim = u.shape
zxbcdt = self.in_proj(u) # (B, L, d_in_proj)
A = -torch.exp(self.A_log) # (nheads) or (d_inner, d_state)
initial_states = repeat(self.init_states, "... -> b ...", b=batch) if self.learnable_init_states else None
dt_limit_kwargs = {} if self.dt_limit == (0.0, float("inf")) else dict(dt_limit=self.dt_limit)
print(torch.isnan(self.conv1d.bias).any())
print(torch.isnan(self.conv1d.weight).any())
print(torch.isnan(A).any())
print(torch.isnan(self.D).any())
print(torch.isnan(self.norm.weight).any())
print(torch.isnan(self.out_proj.weight).any())
if self.use_mem_eff_path:
# Fully fused path
out = mamba_split_conv1d_scan_combined(
zxbcdt,
rearrange(self.conv1d.weight, "d 1 w -> d w"),
self.conv1d.bias,
self.dt_bias,
A,
D=self.D,
chunk_size=self.chunk_size,
seq_idx=seq_idx,
activation=self.activation,
rmsnorm_weight=self.norm.weight,
rmsnorm_eps=self.norm.eps,
outproj_weight=self.out_proj.weight,
outproj_bias=self.out_proj.bias,
headdim=self.headdim,
ngroups=self.ngroups,
norm_before_gate=False,
initial_states=initial_states,
**dt_limit_kwargs,
)
# print(out)
else:
z, xBC, dt = torch.split(
zxbcdt, [self.d_inner, self.d_inner + 2 * self.ngroups * self.d_state, self.nheads], dim=-1
)
dt = F.softplus(dt + self.dt_bias) # (B, L, nheads)
assert self.activation in ["silu", "swish"]
# 1D Convolution
if causal_conv1d_fn is None or self.activation not in ["silu", "swish"]:
xBC = self.act(
self.conv1d(xBC.transpose(1, 2)).transpose(1, 2)
) # (B, L, self.d_inner + 2 * ngroups * d_state)
xBC = xBC[:, :seqlen, :]
else:
xBC = causal_conv1d_fn(
x=xBC.transpose(1, 2),
weight=rearrange(self.conv1d.weight, "d 1 w -> d w"),
bias=self.conv1d.bias,
activation=self.activation,
).transpose(1, 2)
# Split into 3 main branches: X, B, C
# These correspond to V, K, Q respectively in the SSM/attention duality
x, B, C = torch.split(xBC, [self.d_inner, self.ngroups * self.d_state, self.ngroups * self.d_state], dim=-1)
y = mamba_chunk_scan_combined(
rearrange(x, "b l (h p) -> b l h p", p=self.headdim),
dt,
A,
rearrange(B, "b l (g n) -> b l g n", g=self.ngroups),
rearrange(C, "b l (g n) -> b l g n", g=self.ngroups),
chunk_size=self.chunk_size,
D=self.D,
z=None,
seq_idx=seq_idx,
initial_states=initial_states,
**dt_limit_kwargs,
)
y = rearrange(y, "b l h p -> b l (h p)")
# Multiply "gate" branch and apply extra normalization layer
y = self.norm(y, z)
out = self.out_proj(y)
return out
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv1d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
if __name__ == '__main__':
from transformers import BertConfig
import utils
import os
import torch
params = utils.Params()
# Prepare model
bert_config = BertConfig.from_json_file(os.path.join(params.bert_model_dir, 'config.json'))
model = BertForRE.from_pretrained(config=bert_config,
pretrained_model_name_or_path=params.bert_model_dir,
params=params)
model.to(params.device)
"""
input_ids: (batch_size, seq_len)
attention_mask: (batch_size, seq_len)
rel_tags: (bs, rel_num)
potential_rels: (bs,), only in train stage.
seq_tags: (bs, 2, seq_len)
corres_tags: (bs, seq_len, seq_len)
ex_params: experiment parameters
"""
print(model)
model.encoder.mamba.initialize_weights()
input_ids = torch.randint(0, 10000, (params.train_batch_size, params.max_seq_length), dtype=torch.long).to('cuda')
attention_mask = torch.randint(0, 2, (params.train_batch_size, params.max_seq_length), dtype=torch.long).to('cuda')
rel_tags = torch.randint(0, params.rel_num, (params.train_batch_size, params.rel_num), dtype=torch.long).to('cuda')
potential_rels = torch.randint(0, 3, (params.train_batch_size,), dtype=torch.long).to('cuda')
seq_tags = torch.randint(0, 3, (params.train_batch_size, params.seq_tag_size, params.max_seq_length),
dtype=torch.long).to('cuda')
corres_tags = torch.randint(0, 2, (params.train_batch_size, params.max_seq_length, params.max_seq_length),
dtype=torch.long).to('cuda')
# print(attention_mask[0])
# # 每一个元素都是3*256的矩阵
# print(seq_tags[0])
attention_mask[:, 0] = 1
attention_mask = attention_mask.bool()
loss, loss_seq, loss_mat, loss_rel = model(input_ids, attention_mask=attention_mask, seq_tags=seq_tags,
potential_rels=potential_rels, corres_tags=corres_tags,
rel_tags=rel_tags,
ex_params=params)
print(loss,loss_seq, loss_mat, loss_rel)
但是不清楚会不会对结果产生印象,但是应该不会对实验结果产生影响


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









