







 本文详细介绍了Spark在Yarn模式下的配置,包括client和cluster模式的区别,以及配置步骤。同时,文章深入讲解了RDD的特点,如弹性、分区、只读性、依赖和缓存机制,还涵盖了RDD的创建、分区计算以及并行度的设置。通过实例展示了如何在Spark中编程操作RDD,提供了一种理解Spark核心概念的途径。
本文详细介绍了Spark在Yarn模式下的配置,包括client和cluster模式的区别,以及配置步骤。同时,文章深入讲解了RDD的特点,如弹性、分区、只读性、依赖和缓存机制,还涵盖了RDD的创建、分区计算以及并行度的设置。通过实例展示了如何在Spark中编程操作RDD,提供了一种理解Spark核心概念的途径。
spark
Yarn 模式
Yarn 模式概述
Spark 客户端可以直接连接 Yarn,不需要额外构建Spark集群。
有 client 和 cluster 两种模式,主要区别在于:Driver 程序的运行节点不同。
•client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
•cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)上, 适用于生产环境。
工作模式介绍:
Yarn 模式配置
步骤1: 修改 hadoop 配置文件 yarn-site.xml, 添加如下内容:
由于咱们的测试环境的虚拟机内存太少, 防止将来任务被意外杀死, 配置所以做如下配置.
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改后分发配置文件.
步骤2: 复制 spark, 并命名为spark-yarn
cp -r spark-standalone spark-yarn
步骤3: 修改spark-evn.sh文件
去掉 master 的 HA 配置, 日志服务的配置保留着.
并添加如下配置: 告诉 spark 客户端 yarn 相关配置
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
步骤4: 执行一段程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
http://hadoop202:8088
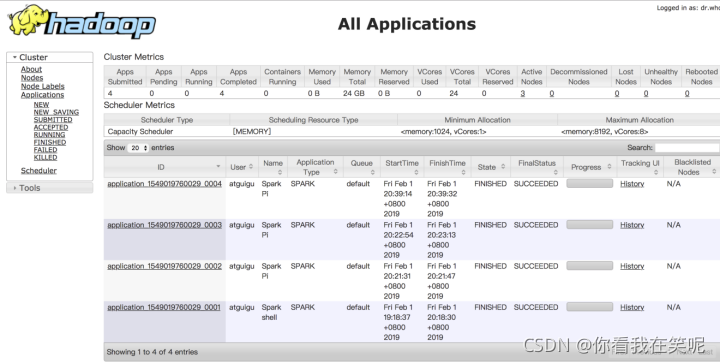
日志服务
在前面的页面中点击 history 无法直接连接到 spark 的日志.
可以在spark-default.conf中添加如下配置达到上述目的
spark.yarn.historyServer.address=hadoop103:18080
spark.history.ui.port=18080
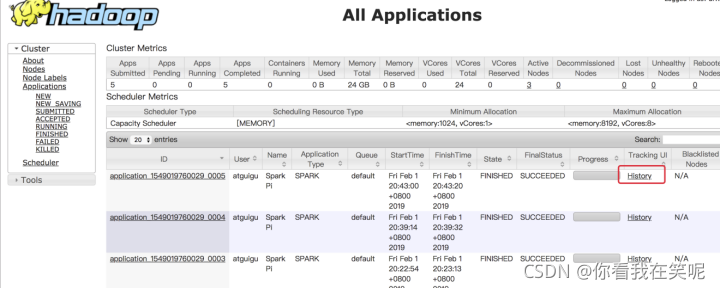
可能碰到的问题:
如果在 yarn 日志端无法查看到具体的日志, 则在yarn-site.xml中添加如下配置
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop201:19888/jobhistory/logs</value>
</property>
几种运行模式的对比
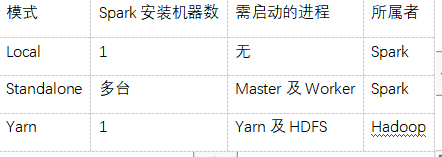
EXecuter&Core&并行度
package com.atguigu.bigdata.sparkcore.wc.test
import java.io.{
ObjectOutput, ObjectOutputStream, OutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
//连接服务器
val client1 =new Socket("localhost",9999)
val client2 =new Socket("localhost",8888)
val task=new Task()
val out1:OutputStream= client1.getOutputStream
val objOut1=new ObjectOutputStream(out1)
val subTask=new SubTask()
subTask.logic=task.logic
subTask.datas=task.datas.take(2)
objOut1.writeObject(subTask)
objOut1.flush()
objOut1.close()
client1.close()
val out2:OutputStream= client2.getOutputStream
val objOut2=new ObjectOutputStream(out2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









