







需要了解的前提:
1将文本转换为token id作输入用到的库
!pip install tiktoken
为什么 LLM 预训练 必须做 Tokenization(编码/标记化)
因为:
所有 LLM 接受的输入不是“词”也不是“字符”,而是 token 序列(即一串整数)
微调模型的时候,也是需要把数据集转换为token序列的2训练所需的环境
# PyTorch for deep learning functions and tensors
import torch
import torch.nn as nn
import torch.nn.functional as F
# Numerical operations and arrays handling
import numpy as np
# Handling HDF5 files
import h5py
# Operating system and file management
import os
# Command-line argument parsing
import argparse
# HTTP requests and interactions
import requests
# Progress bar for loops
from tqdm import tqdm
# JSON handling
import json
# Zstandard compression library
import zstandard as zstd
# Tokenization library for large language models
import tiktoken
# Math operations (used for advanced math functions)
import math验证gpu是否可用
import torch
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else "No GPU")
3数据集
# Download validation dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst
# Download the first part of the training dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst这个下载的训练集很大,10g左右,我们用不了这么多,处理一下
先放到文件夹里面
import os
import shutil
import glob
# Define directory structure
train_dir = "data/train"
val_dir = "data/val"
# Create directories if they don't exist
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# Move all train files (e.g., 00.jsonl.zst, 01.jsonl.zst, ...)
train_files = glob.glob("*.jsonl.zst")
for file in train_files:
if file.startswith("val"):
# Move validation file
dest = os.path.join(val_dir, file)
else:
# Move training file
dest = os.path.join(train_dir, file)
shutil.move(file, dest)
#Our dataset is in the .jsonl.zst format, which is a compressed file format commonly used for storing large datasets. It combines JSON Lines (.jsonl), where each line represents a valid JSON object, with Zstandard (.zst) compression. Let's read a sample of one of the downloaded files and see how it looks.
in_file = "data/val/val.jsonl.zst" # Path to our validation file
with zstd.open(in_file, 'r') as in_f:
for i, line in tqdm(enumerate(in_f)): # Read first 5 lines
data = json.loads(line)
print(f"Line {i}: {data}") # Print the raw data for inspection
if i == 2:
break打印一下数据集内容
import zstandard as zstd
import io
import json
file_path = "data/train/00.jsonl.zst"
# 正确的 zstandard 解压 + 文本流
with open(file_path, 'rb') as fh:
dctx = zstd.ZstdDecompressor()
with dctx.stream_reader(fh) as reader:
text_stream = io.TextIOWrapper(reader, encoding='utf-8')
for i, line in enumerate(text_stream):
data = json.loads(line)
print(f"Line {i}: {data}")
if i == 4: # 查看前5行
break
切分数据集,只要其中的一部分,训练集留60万条,测试集留10万条
import zstandard as zstd
import io
input_file = "data/train/00.jsonl.zst"
output_file = "data/train/00_sampled.jsonl.zst"
keep_lines = 600000
# 解压、截断、重压缩
with open(input_file, 'rb') as fin, open(output_file, 'wb') as fout:
dctx = zstd.ZstdDecompressor()
cctx = zstd.ZstdCompressor()
with dctx.stream_reader(fin) as reader, cctx.stream_writer(fout) as writer:
text_stream = io.TextIOWrapper(reader, encoding='utf-8')
for i, line in enumerate(text_stream):
if i >= keep_lines:
break
writer.write(line.encode('utf-8'))
print("✅ 已保存前 60 万行到:", output_file)
import zstandard as zstd
import io
input_file = "data/val/val.jsonl.zst"
output_file = "data/val/val_new.jsonl.zst"
keep_lines = 100000
# 解压、截断、重压缩
with open(input_file, 'rb') as fin, open(output_file, 'wb') as fout:
dctx = zstd.ZstdDecompressor()
cctx = zstd.ZstdCompressor()
with dctx.stream_reader(fin) as reader, cctx.stream_writer(fout) as writer:
text_stream = io.TextIOWrapper(reader, encoding='utf-8')
for i, line in enumerate(text_stream):
if i >= keep_lines:
break
writer.write(line.encode('utf-8'))
print("✅ 已保存前 10 万行到:", output_file)
记得将data文件夹中截断之前的数据集删掉
将数据集转换为h5格式
def process_files(input_dir, output_file):
"""
Process all .zst files in the specified input directory and save encoded tokens to an HDF5 file.
Args:
input_dir (str): Directory containing input .zst files.
output_file (str): Path to the output HDF5 file.
"""
with h5py.File(output_file, 'w') as out_f:
# Create an expandable dataset named 'tokens' in the HDF5 file
dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')
start_index = 0
# Iterate through all .zst files in the input directory
for filename in sorted(os.listdir(input_dir)):
if filename.endswith(".jsonl.zst"):
in_file = os.path.join(input_dir, filename)
print(f"Processing: {in_file}")
# Open the .zst file for reading
with zstd.open(in_file, 'r') as in_f:
# Iterate through each line in the compressed file
for line in tqdm(in_f, desc=f"Processing {filename}"):
# Load the line as JSON
data = json.loads(line)
# Append the end-of-text token to the text and encode it
text = data['text'] + "<|endoftext|>"
encoded = enc.encode(text, allowed_special={'<|endoftext|>'})
encoded_len = len(encoded)
# Calculate the end index for the new tokens
end_index = start_index + encoded_len
# Expand the dataset size and store the encoded tokens
dataset.resize(dataset.shape[0] + encoded_len, axis=0)
dataset[start_index:end_index] = encoded
# Update the start index for the next batch of tokens
start_index = end_index# Define tokenized data output directories
out_train_file = "data/train/pile_train.h5"
out_val_file = "data/val/pile_dev.h5"
# Loading tokenizer of (GPT-3/GPT-2 Model)
enc = tiktoken.get_encoding('r50k_base')
# Process training data
process_files(train_dir, out_train_file)
# Process validation data
process_files(val_dir, out_val_file)为什么转换为h5格式
HDF5 是大规模、可随机访问、支持压缩的数据格式
比普通的 txt/json/csv 更适合存放 token 序列
LLM 训练时,dataset 是 token stream,HDF5 能高效 slice、batch 化查看一下h5的内容
with h5py.File(out_val_file, 'r') as file:
# Access the 'tokens' dataset
tokens_dataset = file['tokens']
# Print the dtype of the dataset
print(f"Dtype of 'tokens' dataset: {tokens_dataset.dtype}")
# load and print the first few elements of the dataset
print("First few elements of the 'tokens' dataset:")
print(tokens_dataset[:10]) # First 10 token4介绍transformer流程
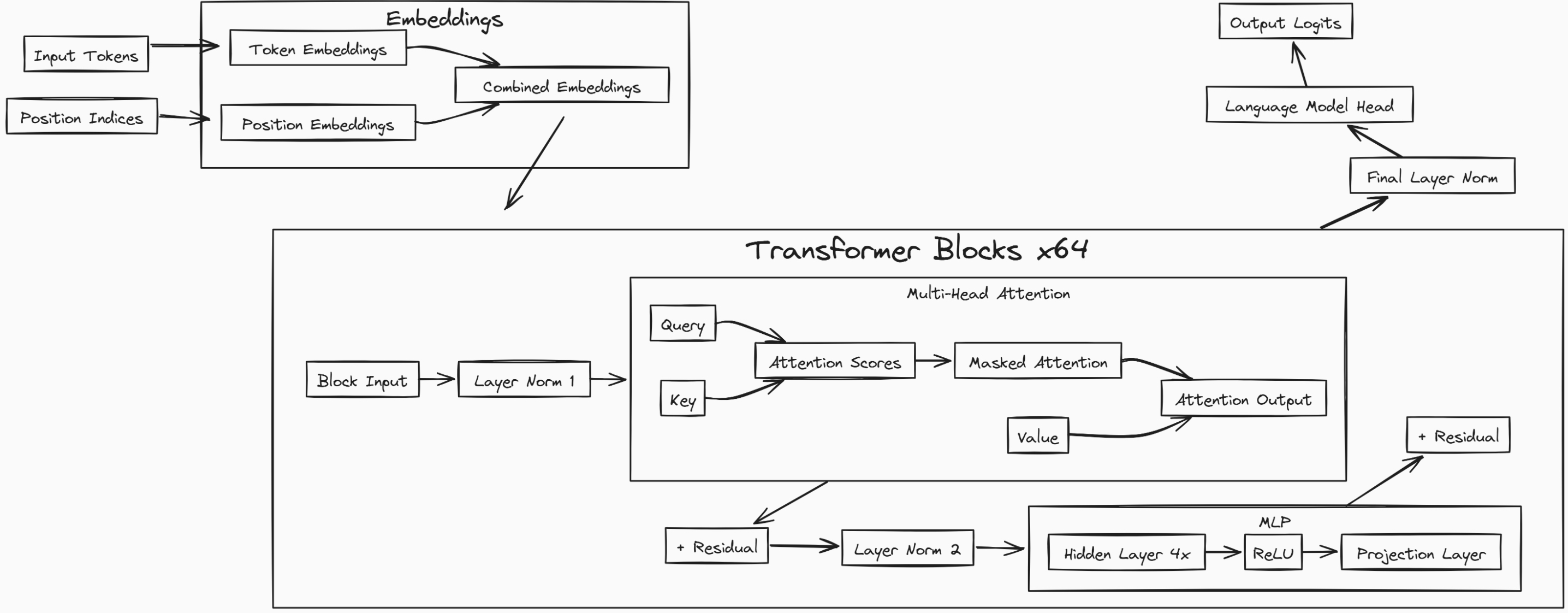
输入的 tokens 会被转换为 embeddings,并与位置(position)信息相结合。
模型包含 64 个相同的 Transformer block,这些 block 会依次顺序处理数据。
每个 block 首先会执行 多头注意力(Multi-Head Attention),用于分析 token 之间的关系。
接着,block 会将数据送入 MLP(前馈神经网络),该 MLP 会先将数据扩展 4 倍,再通过线性层压缩回去。
每一步都使用了 残差连接(Residual Connection),帮助信息在网络中顺利传播。
模型中广泛使用 Layer Normalization(层归一化)来稳定训练过程。
**注意力机制(Attention)**的作用是计算哪些 token 之间应当互相关注。
MLP 的作用是先将数据放大 4 倍,通过 ReLU 激活,再压缩回原始维度。
模型使用 16 个 Attention Head 来捕获不同类型的 token 关系。
最后的输出层会将处理后的特征转换成词表大小的 logits(每个词的预测得分)。
模型通过反复预测下一个最可能的 token,逐步生成完整的文本。

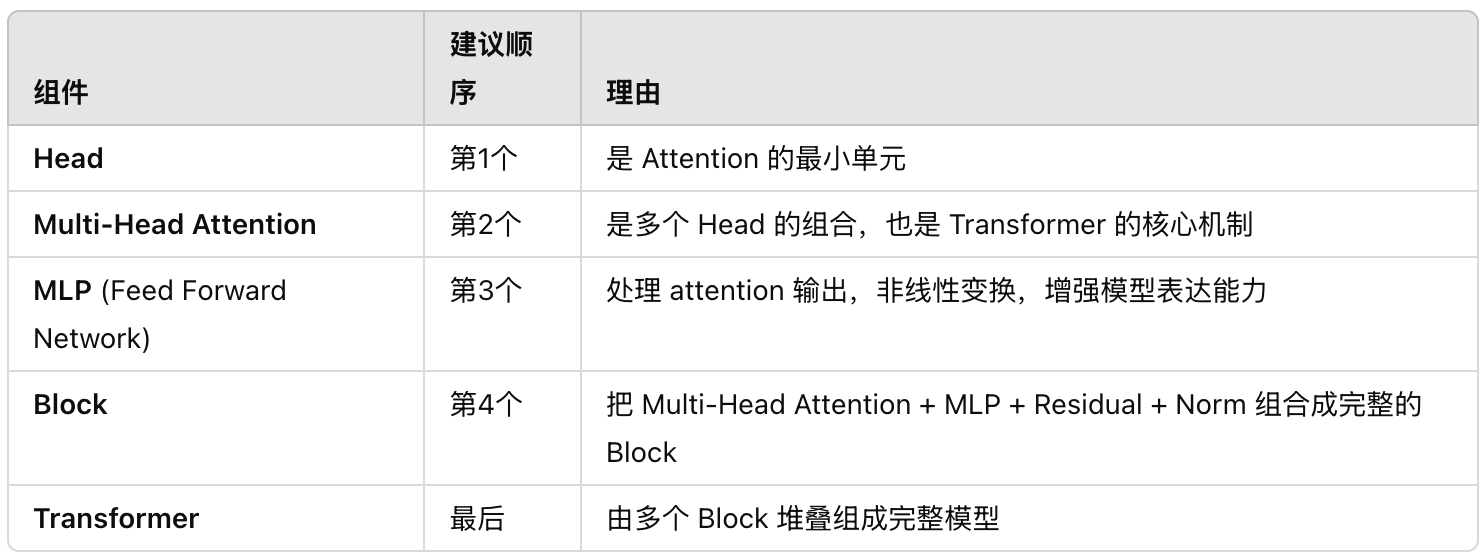
5.接下来我们按照下面的顺序讲解
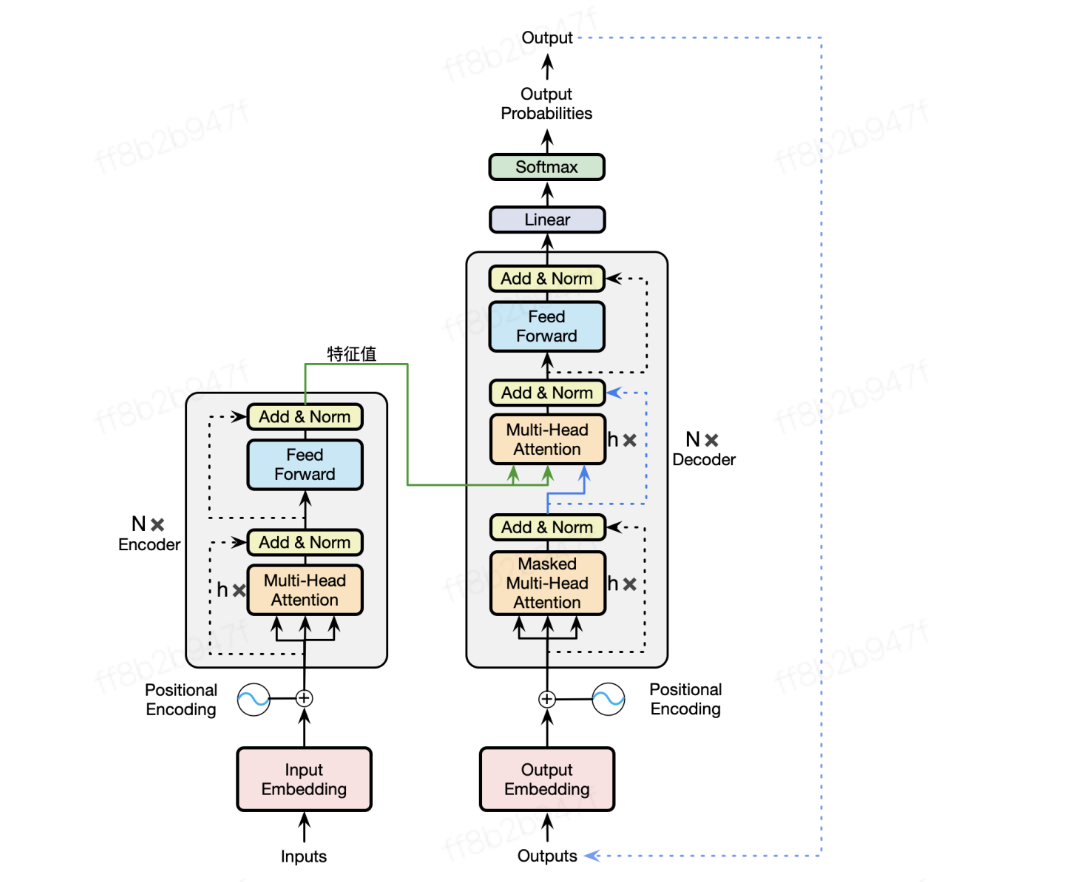
1)位置嵌入代码,在一会的transformer代码里面会展示,只有几行,我们先介绍Head
2)Head
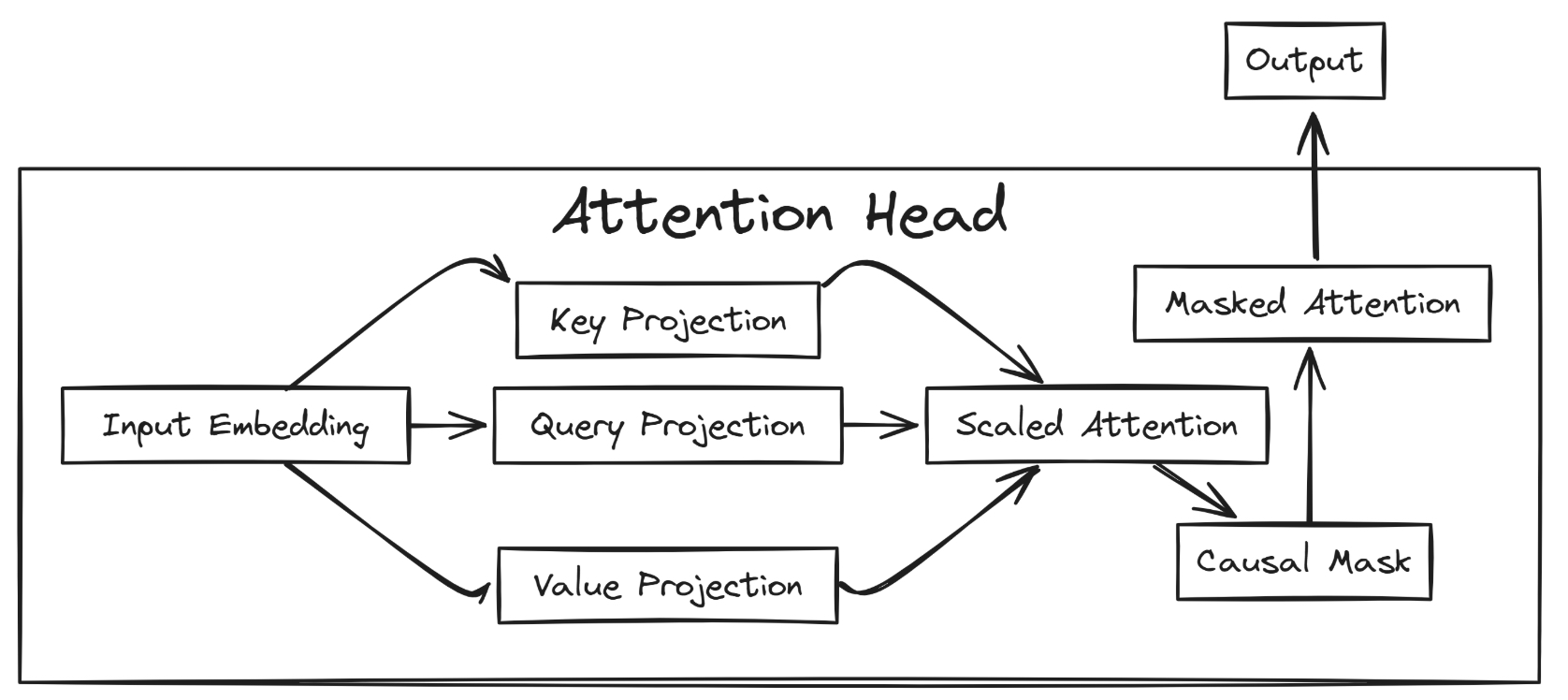
单头注意力(Single Head Attention)
Attention Head 是我们模型的核心模块,其主要作用是聚焦输入序列中的关键信息。在定义 Head 模块时,几个重要的超参数包括
head_size、n_embed和context_length。
head_size:决定了 Query(Q)、Key(K)和 Value(V)投影的维度大小,直接影响注意力机制的表示能力。
n_embed:表示输入 embedding 的维度,也是投影层的输入维度。
context_length:用于构建因果掩码(causal mask),确保模型在进行自回归预测时,只关注当前位置及其之前的 token,避免信息泄露。在 Head 中,通过无偏置(bias=False)的线性变换(
nn.Linear)分别实现了 Q、K、V 的投影。此外,注册了一个context_length x context_length的下三角矩阵(tril)作为 buffer,用于在前向传播时进行 causal masking,从而确保 attention 机制只关注历史信息,符合生成式语言建模的因果性要求。
# --- Attention Head Class ---
class Head(nn.Module):
"""
单个 Attention Head 模块
功能:
- 负责计算 Attention 分数
- 应用 Causal Masking 防止看到未来的信息(GPT 类模型所必需)
- 输出 Attention 加权后的 Value
"""
def __init__(self, head_size, n_embed, context_length):
super().__init__()
# 定义 Q、K、V 投影层
self.key = nn.Linear(n_embed, head_size, bias=False) # Q = W_q * X
self.query = nn.Linear(n_embed, head_size, bias=False) # K = W_k * X
self.value = nn.Linear(n_embed, head_size, bias=False) # V = W_v * X
# 构建一个下三角的掩码矩阵(Causal Mask)
# 确保每个 token 只能关注它左边的 token
self.register_buffer('tril', torch.tril(torch.ones(context_length, context_length)))
def forward(self, x):
"""
前向传播
输入:
x (torch.Tensor): 输入的 embedding,形状为 (batch_size, seq_len, embed_dim)
输出:
torch.Tensor: 经过 attention 计算后的特征 (batch_size, seq_len, head_size)
"""
B, T, C = x.shape # B=batch_size, T=序列长度, C=embedding维度
# 计算 Q 和 K
k = self.key(x) # shape: (B, T, head_size)
q = self.query(x) # shape: (B, T, head_size)
# 计算 Attention score
# (B, T, head_size) x (B, head_size, T) -> (B, T, T)
# 表示每个 token 对其他 token 的注意力分数
scale_factor = 1 / math.sqrt(C) # 防止 score 过大
attn_weights = q @ k.transpose(-2, -1) * scale_factor # shape: (B, T, T)
# 使用下三角矩阵进行 Causal Masking
# 保证只关注当前和之前的 token
attn_weights = attn_weights.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
# Softmax 得到注意力权重
attn_weights = F.softmax(attn_weights, dim=-1) # shape: (B, T, T)
# 计算 Value
v = self.value(x) # shape: (B, T, head_size)
# 应用 Attention 权重加权 Value
# (B, T, T) x (B, T, head_size) -> (B, T, head_size)
out = attn_weights @ v
return out
在 Attention Head 类中,__init__ 方法负责初始化 Key、Query 和 Value 的线性投影层,每个投影都将输入的 embedding(维度为 n_embed)映射到 head_size 维的子空间。同时,基于 context_length 构建了一个下三角矩阵作为 因果掩码(causal mask),用于阻止当前 token 关注到未来 token。
在 forward 方法中,首先通过 Query 和 Key 的点积计算 attention 分数,并进行缩放以稳定梯度;接着,应用因果掩码,防止模型在训练中看到未来的信息。随后,使用 softmax 将 attention 权重归一化,最后将该权重作用到 Value 上,得到加权和作为本 Head 的 attention 输出。
3)多头注意力机制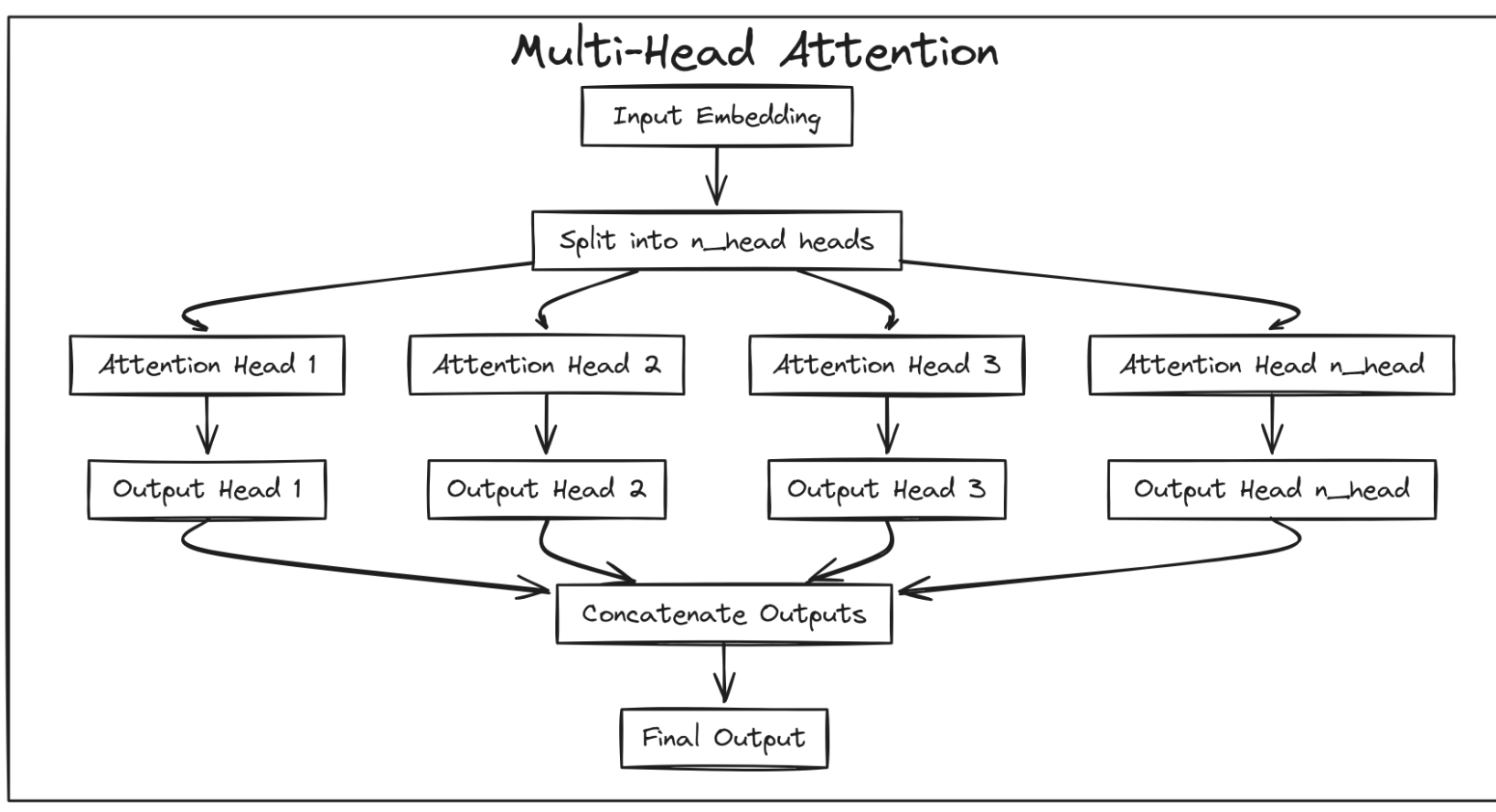
多头注意力(Multi-Head Attention)
为了捕捉输入序列中多样化的依赖关系,我们采用了 多头注意力(Multi-Head Attention) 机制。MultiHeadAttention 模块会同时管理多个独立的 attention head,并行处理输入信息。
其中最关键的参数是
n_head,它决定了并行的 attention head 的数量。同时,n_embed(输入 embedding 的维度)和context_length(序列最大长度)也是构建各个 attention head 所必需的参数。在实际操作中,每个 attention head 会独立地对输入进行处理,并将输入投影到一个低维的子空间,其维度为
n_embed // n_head。通过多个 head 的并行计算,模型能够在同一时刻关注输入序列的不同子结构和特征,从而提升对多样化上下文关系的建模能力。
# --- 多头注意力(Multi-Head Attention)模块 ---
class MultiHeadAttention(nn.Module):
"""
Multi-Head Attention 模块
功能:
- 该模块由多个独立的 Attention Head 组成(并行)
- 每个 Head 会独立计算 attention 分数和加权输出
- 所有 Head 的输出会在最后维度上进行拼接(concatenate)
- 输出作为下游 MLP 的输入
"""
def __init__(self, n_head, n_embed, context_length):
super().__init__()
# 初始化 n_head 个 Head,每个 Head 的 head_size = n_embed // n_head
# 保证所有 head 拼接后仍然保持原始 n_embed 维度
self.heads = nn.ModuleList([
Head(n_embed // n_head, n_embed, context_length)
for _ in range(n_head)
])
def forward(self, x):
"""
前向传播
输入:
x (torch.Tensor): 输入的 embedding 特征,形状为 (B, T, C)
B - batch size
T - 序列长度
C - embedding 维度
输出:
torch.Tensor: 拼接所有 head 输出的结果,形状为 (B, T, C)
"""
# 将每个 Head 的输出在最后一个维度上(即 embedding 维度)拼接
# [head1_out, head2_out, ..., head_n_out] -> concat -> (B, T, C)
x = torch.cat([h(x) for h in self.heads], dim=-1)
return x
现在我们已经定义了MultiHeadAttention类,它组合了多个注意力头,init方法初始化了一个Head实例列表(总共n_Head),每个实例的Head_size为n_embed//n_Head。正向方法将每个注意头应用于输入x,并沿最后一个维度连接它们的输出,合并每个注意头学习到的信息。
4)MLP
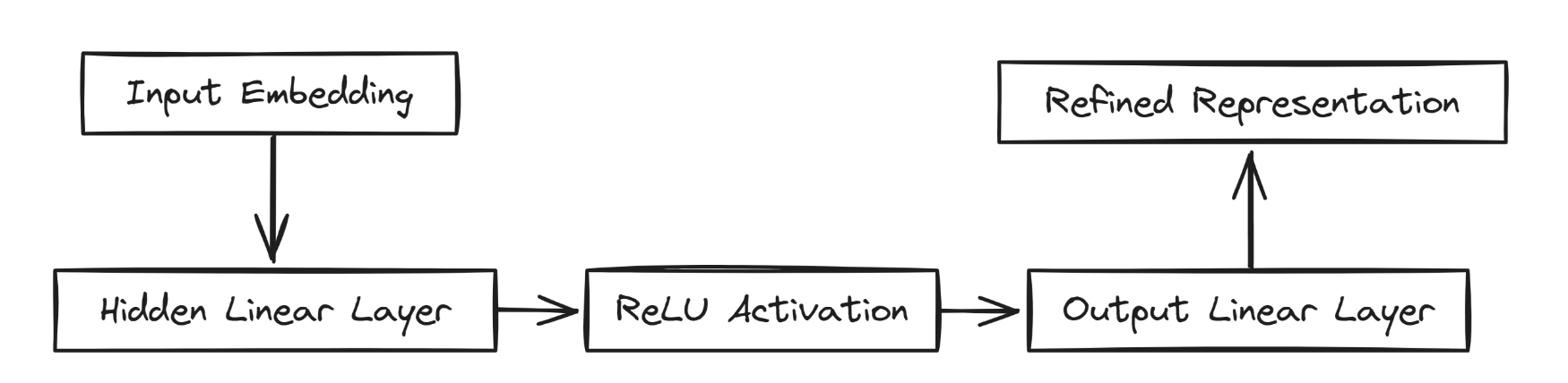
多层感知机(MLP)
MLP 是 Transformer 中前馈网络(Feed Forward Network, FFN)的核心组成部分,主要作用是引入非线性能力,帮助模型学习 embedding 表示中的复杂关系。
在定义 MLP 模块时,重要的参数是 n_embed,它决定了输入 embedding 的维度。
MLP 的典型结构包括三个部分:
扩展层:使用一个线性层将输入 embedding 的维度扩展为原来的 4 倍(例如原始维度为 n_embed,扩展为 4 * n_embed),增加了模型的表达能力。
非线性激活:通常采用 ReLU 激活函数,为模型引入非线性特征。
投影层:使用另一个线性层将扩展后的表示再投影回原始的 embedding 维度。
通过这组扩展 → 激活 → 压缩的结构,MLP 能够在 Attention 机制的基础上进一步精细化、重塑特征表示,从而使模型能够捕捉更加复杂和有意义的上下文信息。MLP对应的部分是图中的
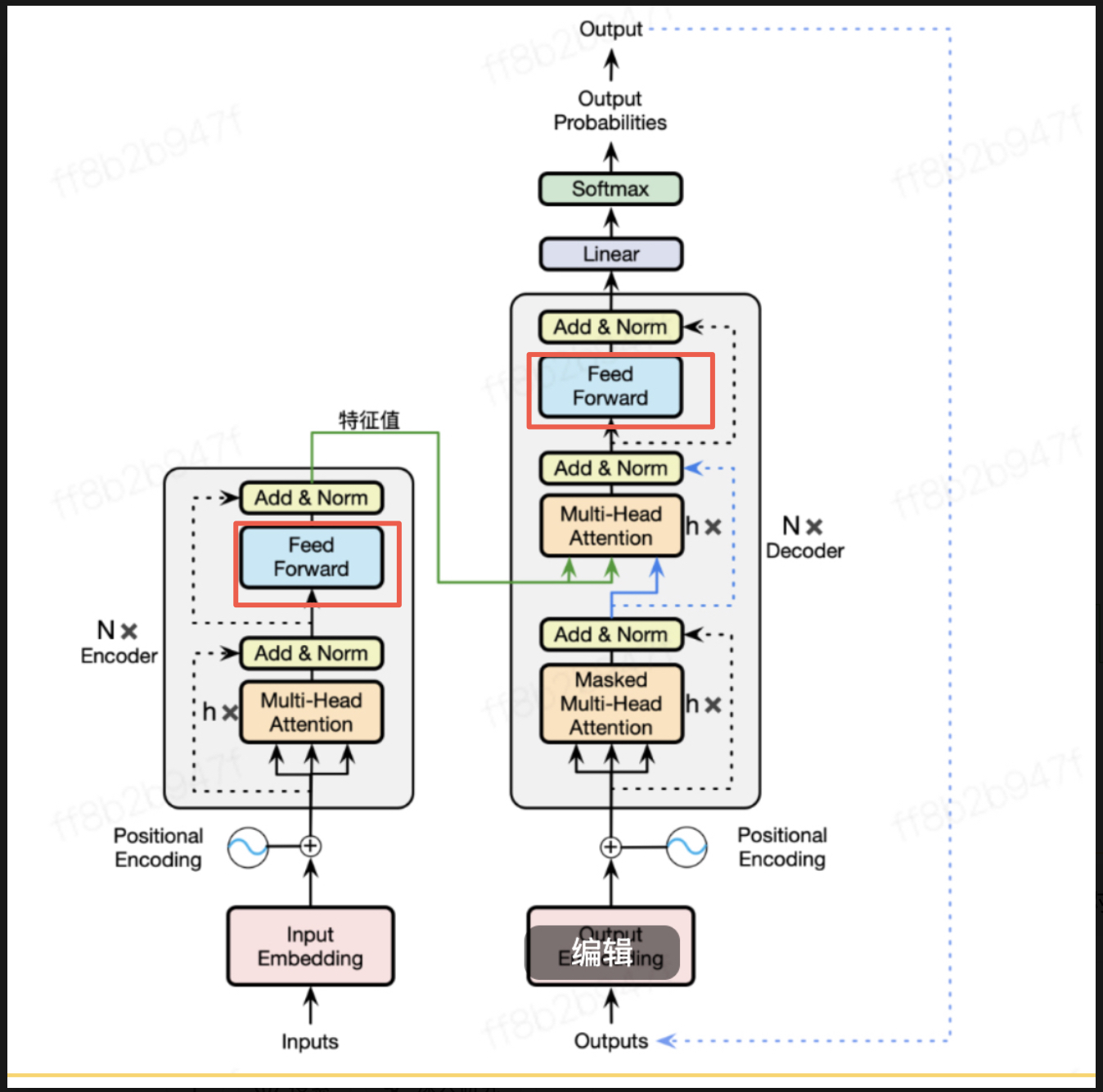
这里补充一下图中的Add&Norm的作用,和位置掩码一样会在transformer中出现
Add(残差连接):
将子模块的输出 和 子模块的输入 相加
公式:x = x + sublayer(x)
作用:解决深层网络中的梯度消失、信息丢失等问题,保留原始的输入信息
Norm(层归一化):
对相加后的结果进行 LayerNorm
作用:稳定训练,加快收敛
与 BatchNorm 不同,LayerNorm 是对 token 的每个 embedding 做归一化,不依赖 batch size
回到MLP
# --- 多层感知机(MLP)模块 ---
class MLP(nn.Module):
"""
多层感知机(Multi-Layer Perceptron)
作用:
- 用于 Transformer Block 中的前馈神经网络(Feed Forward)
- 增强模型的非线性表达能力
- 在 Attention 之后进一步对特征进行转换
结构:
1. 线性层:将 embedding 维度扩展到 4 倍
2. ReLU 激活:引入非线性
3. 线性层:将维度再投影回原始的 embedding 维度
"""
def __init__(self, n_embed):
super().__init__()
# 将输入 embedding 维度扩展 4 倍,输出维度为 4 * n_embed
self.hidden = nn.Linear(n_embed, 4 * n_embed)
# ReLU 激活函数,增加非线性能力
self.relu = nn.ReLU()
# 再投影回原始的 embedding 维度
self.proj = nn.Linear(4 * n_embed, n_embed)
def forward(self, x):
"""
MLP 前向传播
输入:
x (torch.Tensor): 输入张量,形状为 (B, T, C)
B - batch size
T - 序列长度
C - embedding 维度
输出:
torch.Tensor: 输出张量,形状与输入相同
"""
x = self.forward_embedding(x) # hidden + ReLU
x = self.project_embedding(x) # projection
return x
def forward_embedding(self, x):
"""
扩展 embedding 维度,并应用 ReLU 激活
"""
x = self.relu(self.hidden(x))
return x
def project_embedding(self, x):
"""
将维度投影回原始 embedding 尺度
"""
x = self.proj(x)
return x
我们刚刚完成了 MLP 部分的编码,其中
__init__方法初始化了一个 隐藏层(hidden layer)和一个 投影层(projection layer):
隐藏层(hidden layer)负责将输入的 embedding 维度(
n_embed)扩展为 4 倍;投影层(projection layer)则将其重新压缩回原始的 embedding 维度。
在隐藏层之后,接入了 ReLU 激活函数以引入非线性。
forward方法则定义了数据在 MLP 中的前向传播流程:
先通过
forward_embedding方法完成 embedding 扩展和 ReLU 激活;然后通过
project_embedding方法完成投影回原始 embedding 尺度的操作。这样的结构使得 MLP 能够为 Transformer 模型提供更强的特征变换能力。
5)Transformer Block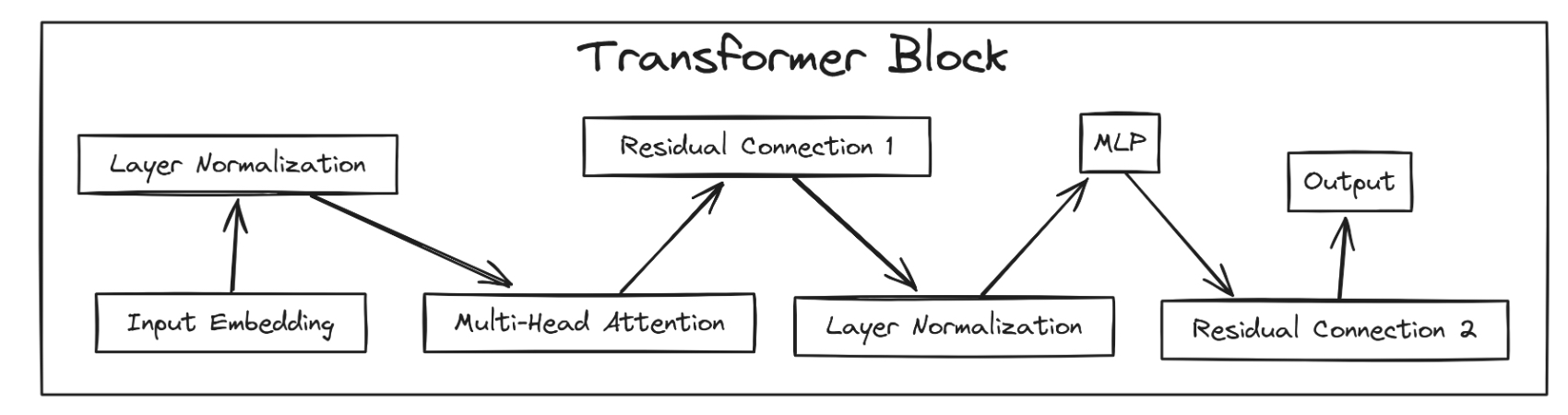
为了构建一个拥有数亿甚至十亿参数的大模型,我们必须设计一个足够深的网络架构,这就需要编写 Transformer Block 并将它们进行堆叠。
Block 的核心参数:
n_head:多头注意力的头数
n_embed:embedding 的维度
context_length:序列的最大长度
Block 的主要结构:
每个 Transformer Block 由以下部分组成:
Multi-Head Attention 多头注意力机制
接收 n_head、n_embed 和 context_length 作为参数
能够建模 token 之间的依赖关系,学习不同类型的关系信息
Feed Forward Network(即 MLP)前馈神经网络
负责对 attention 输出的特征进行非线性变换与信息重塑
使用 n_embed 作为输入和输出的维度
Layer Normalization(层归一化)
作用于 Attention 和 MLP 之前,保证数值稳定性
参数依赖于 embedding 的维度 n_embed
Residual Connection(残差连接)
每个子模块(Attention 和 MLP)都配有残差连接,有效缓解深度模型的梯度消失和退化问题
作用:
通过 Attention + MLP + LayerNorm + Residual 组合,每个 block 能够逐层提取、转化更复杂的特征,捕获序列中的长距离依赖。多个 block 的堆叠,使得 Transformer 能够成为强大的表示学习架构。# --- Transformer Block(变换器块)---
class Block(nn.Module):
"""
单个 Transformer Block
作用:
- 是 Transformer 模型的基本单元,负责特征提取与特征变换
- 内部包含 多头自注意力机制(Multi-Head Attention) 和 前馈神经网络(MLP)
- 每个子结构都配有 LayerNorm(层归一化) 和 Residual Connection(残差连接)
参数:
- n_head:多头注意力中的头数
- n_embed:embedding 维度
- context_length:序列最大长度
"""
def __init__(self, n_head, n_embed, context_length):
super().__init__()
# 第一个 LayerNorm,作用于 Attention 之前
self.ln1 = nn.LayerNorm(n_embed)
# 多头注意力机制
self.attn = MultiHeadAttention(n_head, n_embed, context_length)
# 第二个 LayerNorm,作用于 MLP 之前
self.ln2 = nn.LayerNorm(n_embed)
# 前馈神经网络 MLP
self.mlp = MLP(n_embed)
def forward(self, x):
"""
Block 的标准前向传播
输入:
x (torch.Tensor): 输入特征,形状为 (B, T, C)
流程:
1. 输入 -> LayerNorm -> Multi-Head Attention -> 残差连接
2. 再次 LayerNorm -> MLP -> 残差连接
输出:
torch.Tensor: 经过 Transformer Block 处理的特征
"""
# 第一部分:Attention + Residual
x = x + self.attn(self.ln1(x))
# 第二部分:MLP + Residual
x = x + self.mlp(self.ln2(x))
return x
def forward_embedding(self, x):
"""
仅进行嵌入相关的前向传播,供特定任务(如提取 attention embedding)使用
输入:
x (torch.Tensor): 输入张量
输出:
tuple:
- x: MLP 前向后的输出
- res: Attention 的 residual
"""
# Attention + Residual
res = x + self.attn(self.ln1(x))
# MLP 前向
x = self.mlp.forward_embedding(self.ln2(res))
return x, res
我们的
Block类表示一个标准的 Transformer Block。1. 初始化阶段
在
__init__方法中,完成了以下组件的初始化:
LayerNorm 层:
ln1和ln2,用于在 Attention 和 MLP 前进行层归一化,缓解训练不稳定问题。MultiHeadAttention 模块:负责进行多头自注意力机制的建模,能够提取 token 间的全局依赖关系。
MLP 模块:前馈神经网络,用于对 attention 的输出进行非线性变换与特征增强。
这些模块都依赖于三个超参数:
n_head(头数)、n_embed(embedding 维度)和context_length(上下文长度)。
6)最终transformer 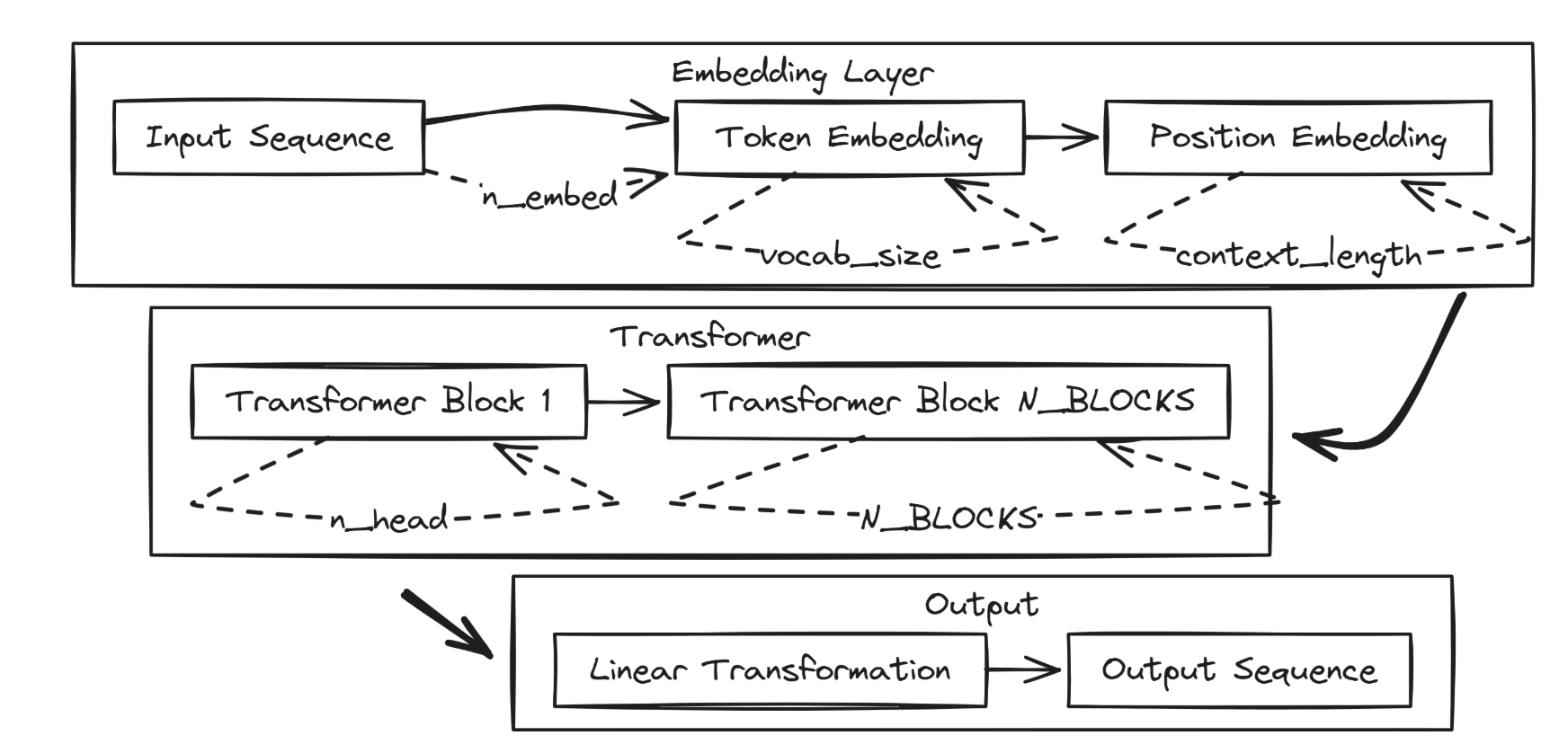
最终模型(The Final Model)
到目前为止,我们已经完成了 Transformer 模型中的各个小组件的实现。接下来,我们将它们整合起来,构建一个完整的 Transformer,用于序列到序列(Sequence-to-Sequence)任务。
主要组成:
为了实现完整的 Transformer,我们需要定义以下关键参数:
vocab_size:词表大小,决定了 token embedding 层的尺寸,用于将每个 token 映射为维度为n_embed的稠密向量。
context_length:上下文长度,决定了 position embedding 层的位置编码范围,确保模型能感知 token 的位置信息。位置编码的输出维度同样是n_embed。
n_embed:embedding 的维度,决定了特征空间的大小,也作为 Transformer 各模块的基础维度。
n_head:注意力头的数量,决定了 self-attention 中并行注意力头的数量,影响模型建模多种关系的能力。
N_BLOCKS:Transformer Block 的堆叠个数,决定了模型的深度和表达能力。模型整体结构
最终模型的构建过程:
输入经过 token embedding 和 position embedding 进行特征表示。
特征表示依次经过
N_BLOCKS个 Transformer Block。输出通过一个 LayerNorm 进行归一化,再经过 Linear Head 投影到 vocab_size,输出 token 分布。
# --- Transformer 主模型 ---
class Transformer(nn.Module):
"""
Transformer主模型
这个类将 Token Embedding、Position Embedding、多个 Transformer Block 和一个输出线性层组合在一起,
用于构建完整的 Transformer 语言模型(Language Model)。
"""
def __init__(self, n_head, n_embed, context_length, vocab_size, N_BLOCKS):
"""
初始化 Transformer 模型
参数:
n_head (int): 注意力头数量
n_embed (int): token embedding 和 hidden 状态的维度
context_length (int): 最大支持的序列长度(最大位置编码)
vocab_size (int): 词表大小
N_BLOCKS (int): Transformer Block 堆叠的数量(即模型的深度)
"""
super().__init__()
self.context_length = context_length
self.N_BLOCKS = N_BLOCKS
# Token Embedding 层:将 token id 映射为 embedding 向量
self.token_embed = nn.Embedding(vocab_size, n_embed)
# Position Embedding 层:给每个位置添加位置信息
self.position_embed = nn.Embedding(context_length, n_embed)
# 多个 Transformer Block 组成的 ModuleList
self.attn_blocks = nn.ModuleList([Block(n_head, n_embed, context_length) for _ in range(N_BLOCKS)])
# 输出前的 LayerNorm
self.layer_norm = nn.LayerNorm(n_embed)
# 输出层,将 hidden state 转换为 vocab size 的 logits
self.lm_head = nn.Linear(n_embed, vocab_size)
# 注册位置索引 buffer(不作为参数参与训练)
self.register_buffer('pos_idxs', torch.arange(context_length))
def _pre_attn_pass(self, idx):
"""
Embedding 阶段:token embedding + position embedding
参数:
idx (Tensor): token 序列的 index
返回:
Tensor: 加和后的 embedding 表示
"""
B, T = idx.shape
tok_embedding = self.token_embed(idx) # (B, T, n_embed)
pos_embedding = self.position_embed(self.pos_idxs[:T]) # (T, n_embed)
return tok_embedding + pos_embedding # 位置编码和 token 编码相加
def forward(self, idx, targets=None):
"""
Transformer 正向传播
参数:
idx (Tensor): 输入 token 序列
targets (Tensor): 标签序列(如果用于计算 loss)
返回:
logits 和 loss(如果 targets 不为 None)
"""
# Step1: Embedding
x = self._pre_attn_pass(idx)
# Step2: 多个 Transformer Block
for block in self.attn_blocks:
x = block(x)
# Step3: LayerNorm + 输出
x = self.layer_norm(x)
logits = self.lm_head(x) # (B, T, vocab_size)
loss = None
if targets is not None:
B, T, C = logits.shape
flat_logits = logits.view(B * T, C)
targets = targets.view(B * T).long()
loss = F.cross_entropy(flat_logits, targets) # 自回归 LM Loss
return logits, loss
def forward_embedding(self, idx):
"""
用于可视化、蒸馏或中间表示输出的 forward(一般不用于训练)
返回:
x: attention + MLP 后的 embedding
residual: attention 前的 residual
"""
x = self._pre_attn_pass(idx)
residual = x
for block in self.attn_blocks:
x, residual = block.forward_embedding(x)
return x, residual
def generate(self, idx, max_new_tokens):
"""
文本生成(基于训练好的模型)
参数:
idx (Tensor): 初始输入的 token 序列
max_new_tokens (int): 生成的 token 数量
返回:
Tensor: 拼接后的新 token 序列
"""
for _ in range(max_new_tokens):
idx_cond = idx[:, -self.context_length:] # 只保留最后 context_length 个 token
logits, _ = self(idx_cond) # Forward
logits = logits[:, -1, :] # 取最后一个 token 的输出
probs = F.softmax(logits, dim=-1) # Softmax 概率
idx_next = torch.multinomial(probs, num_samples=1) # 采样
idx = torch.cat((idx, idx_next), dim=1) # 拼接生成的 token
return idx
我们的
Transformer类的__init__方法负责初始化以下模块:
token_embed:词嵌入层,用于将输入 token ID 映射为向量表示;
position_embed:位置嵌入层,用于提供位置信息;
attn_blocks:一个由多个
Block模块组成的序列(即 Transformer Block 的堆叠);layer_norm:输出前的 Layer Normalization 层;
lm_head:最终的线性层,用于将模型输出映射为词表大小的 logits,进行预测。
🔁 模型中的各个方法
_pre_attn_pass方法将 token 嵌入和位置嵌入进行相加,用于构建输入序列的初始表示。
forward方法是模型的主干流程:
对输入进行嵌入(token + position);
经过若干个 Transformer Block(每个 block 内部含注意力和 MLP);
最后做 LayerNorm 和线性投影;
如果提供了目标序列(
targets),计算交叉熵损失。
forward_embedding方法用于输出经过注意力模块后的中间表示,常用于蒸馏、可视化或调试。
generate方法实现了基于当前输入序列的自回归文本生成逻辑:
每次预测下一个 token;
将其拼接到输入后继续生成;
重复此过程,直到生成
max_new_tokens个 token。
5.定义模型配置
# --- Configuration ---
# Define vocabulary size and transformer configuration
VOCAB_SIZE = 50304 # Number of unique tokens in the vocabulary
CONTEXT_LENGTH = 256 # Maximum sequence length for the model
N_EMBED = 256 # Dimension of the embedding space
N_HEAD = 4 # Number of attention heads in each transformer block
N_BLOCKS =4 # Number of transformer blocks in the model
# Paths to training and development datasets
TRAIN_PATH = "data/train/pile_train.h5" # File path for the training dataset
DEV_PATH = "data/val/pile_dev.h5" # File path for the validation dataset
# Transformer training parameters
T_BATCH_SIZE = 32 # Number of samples per training batch
T_CONTEXT_LENGTH = 16 # Context length for training batches
T_TRAIN_STEPS = 200000 # Total number of training steps
T_EVAL_STEPS = 1000 # Frequency (in steps) to perform evaluation
T_EVAL_ITERS = 250 # Number of iterations to evaluate the model
T_LR_DECAY_STEP = 50000 # Step at which to decay the learning rate
T_LR = 5e-4 # Initial learning rate for training
T_LR_DECAYED = 5e-5 # Learning rate after decay
T_OUT_PATH = "models/transformer_B.pt" # Path to save the trained model
# Device configuration
DEVICE = 'cuda'
# Store all configurations in a dictionary for easy access and modification
config = {
'vocab_size': VOCAB_SIZE,
'context_length': CONTEXT_LENGTH,
'n_embed': N_EMBED,
'n_head': N_HEAD,
'n_blocks': N_BLOCKS,
'train_path': TRAIN_PATH,
'dev_path': DEV_PATH,
't_batch_size': T_BATCH_SIZE,
't_context_length': T_CONTEXT_LENGTH,
't_train_steps': T_TRAIN_STEPS,
't_eval_steps': T_EVAL_STEPS,
't_eval_iters': T_EVAL_ITERS,
't_lr_decay_step': T_LR_DECAY_STEP,
't_lr': T_LR,
't_lr_decayed': T_LR_DECAYED,
't_out_path': T_OUT_PATH,
'device': DEVICE,
}6.计算模型参数值
model = Transformer(
n_head=config['n_head'],
n_embed=config['n_embed'],
context_length=config['context_length'],
vocab_size=config['vocab_size'],
N_BLOCKS=config['n_blocks'],
device=config['device']
).to(config['device'])
print(next(model.parameters()).device)
# Print the total number of parameters
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters in the model: {total_params:,}")
7.配置优化器、追踪损失,并且提供一个训练和验证集的损失评估工具
# ------------------------------
# --- 优化器设置 & 损失追踪模块 ---
# ------------------------------
# 使用 AdamW 作为 Transformer 的优化器
# AdamW 相比 Adam 具有更好的 weight decay 机制,能有效防止 overfitting
optimizer = torch.optim.AdamW(model.parameters(), lr=config['t_lr'])
# 定义用于保存训练过程中的 loss 值的列表
losses = []
# 定义一个滑动窗口大小,用于在训练时对 recent loss 进行平滑显示
AVG_WINDOW = 64
# ------------------------------
# --- 损失评估函数 ---
# ------------------------------
@torch.no_grad() # 禁用梯度计算,加快速度并节省显存
def estimate_loss(steps):
"""
在训练和验证集上评估 loss
Args:
steps (int): 评估时迭代的步数(即采样 steps 个 batch)
Returns:
dict: {"train": 训练集平均loss, "dev": 验证集平均loss}
"""
out = {} # 存储 train 和 dev 的 loss
model.eval() # 切换为 eval 模式,关闭 dropout 和其他训练特有操作
# 遍历 train 和 dev
for split in ['train', 'dev']:
# 根据 split 选择数据路径
data_path = config['train_path'] if split == 'train' else config['dev_path']
# 生成 batch 迭代器
batch_iterator_eval = get_batch_iterator(
data_path, config['t_batch_size'], config['t_context_length'], device=config['device']
)
# 初始化 tensor 用于存放多个 batch 的 loss
losses_eval = torch.zeros(steps)
# 开始 loss 估计
for k in range(steps):
try:
# 取出下一个 batch
xb, yb = next(batch_iterator_eval)
# 前向推理,计算 loss
_, loss = model(xb, yb)
# 记录 loss
losses_eval[k] = loss.item()
except StopIteration:
# 如果数据集提前结束,提示并跳出
print(f"Warning: Iterator for {split} ended early.")
break
# 计算该 split 下的平均 loss
out[split] = losses_eval[:k + 1].mean()
model.train() # 切回训练模式
return out # 返回 {"train": train_loss, "dev": dev_loss}
8.开始训练
# --- Training Loop ---
# Create a batch iterator for the training data.
batch_iterator = get_batch_iterator(
config['train_path'],
config['t_batch_size'],
config['t_context_length'],
device=config['device']
)
# Create a progress bar to monitor training progress.
pbar = tqdm(range(config['t_train_steps']))
for step in pbar:
try:
# Fetch a batch of input and target data.
xb, yb = next(batch_iterator)
# Perform a forward pass and compute the loss.
_, loss = model(xb, yb)
# Record the loss for tracking.
losses.append(loss.item())
pbar.set_description(f"Train loss: {np.mean(losses[-AVG_WINDOW:]):.4f}")
# Backpropagate the loss and update the model parameters.
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# Periodically evaluate the model on training and development data.
if step % config['t_eval_steps'] == 0:
train_loss, dev_loss = estimate_loss(config['t_eval_iters']).values()
print(f"Step: {step}, Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")
# Decay the learning rate at the specified step.
if step == config['t_lr_decay_step']:
print('Decaying learning rate')
for g in optimizer.param_groups:
g['lr'] = config['t_lr_decayed']
except StopIteration:
# Handle the case where the training data iterator ends early.
print("Training data iterator finished early.")
break9.保存模型(15g显存,训练了4h)
# --- Save Model and Final Evaluation ---
# Perform a final evaluation of the model on training and development datasets.
train_loss, dev_loss = estimate_loss(200).values()
# Ensure unique model save path in case the file already exists.
modified_model_out_path = config['t_out_path']
save_tries = 0
while os.path.exists(modified_model_out_path):
save_tries += 1
model_out_name = os.path.splitext(config['t_out_path'])[0]
modified_model_out_path = model_out_name + f"_{save_tries}" + ".pt"
# Save the model's state dictionary, optimizer state, and training metadata.
torch.save(
{
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'losses': losses,
'train_loss': train_loss,
'dev_loss': dev_loss,
'steps': len(losses),
},
modified_model_out_path
)
print(f"Saved model to {modified_model_out_path}")
print(f"Finished training. Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")10.测试大模型
def generate_text(model_path, input_text, max_length=512, device="gpu"):
"""
Generate text using a pre-trained model based on the given input text.
Args:
- model_path (str): Path to the model checkpoint.
- device (torch.device): Device to load the model on (e.g., 'cpu' or 'cuda').
- input_text (str): The input text to seed the generation.
- max_length (int, optional): Maximum length of generated text. Defaults to 512.
Returns:
- str: The generated text.
"""
# Load the model checkpoint
checkpoint = torch.load(model_path)
# Initialize the model (you should ensure that the Transformer class is defined elsewhere)
model = Transformer().to(device)
# Load the model's state dictionary
model.load_state_dict(checkpoint['model_state_dict'])
# Load the tokenizer for the GPT model (we use 'r50k_base' for GPT models)
enc = tiktoken.get_encoding('r50k_base')
# Encode the input text along with the end-of-text token
input_ids = torch.tensor(
enc.encode(input_text, allowed_special={'<|endoftext|>'}),
dtype=torch.long
)[None, :].to(device) # Add batch dimension and move to the specified device
# Generate text with the model using the encoded input
with torch.no_grad():
# Generate up to 'max_length' tokens of text
generated_output = model.generate(input_ids, max_length)
# Decode the generated tokens back into text
generated_text = enc.decode(generated_output[0].tolist())
return generated_text
# Input text
input_text "Subject: "
# Call the Million parameter Mod
m_output = generate_text(Million_model_path, input_text)
print(m_output) # Output from the Million model本博客参考
https://github.com/FareedKhan-dev/train-llm-from-scratch?tab=readme-ov-file#the-final-model



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









