







一、梯度下降法实践
1.特征缩放
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图:
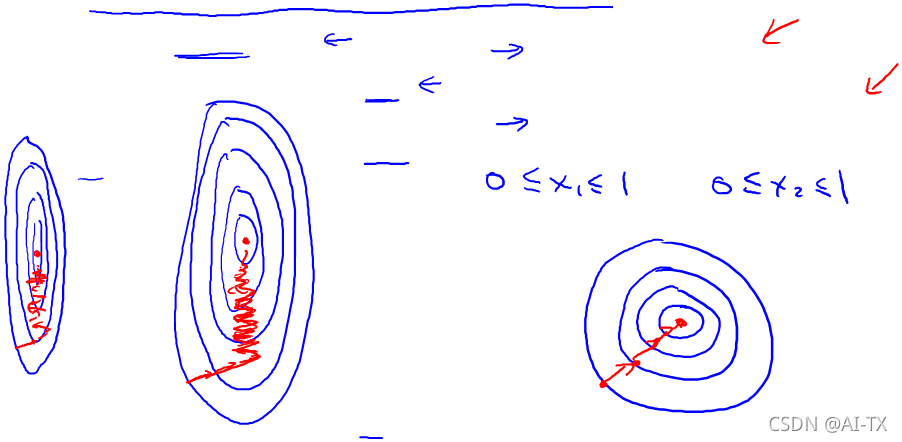
最简单的方法是令:𝑥𝑛=(𝑥𝑛−𝜇𝑛)/𝑠𝑛,其中 𝜇𝑛是平均值,𝑠𝑛是标准差
2.学习率
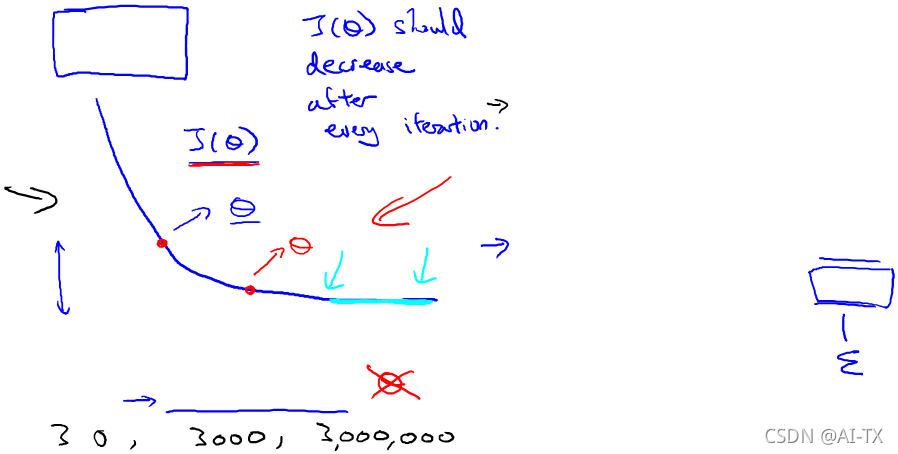
梯度下降算法的每次迭代受到学习率的影响,如果学习率𝑎过小,则达到收敛所需的迭代次数会非常高;如果学习率𝑎过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。 通常可以考虑尝试些学习率: 𝛼=0.01,0.03,0.1,0.3,1,3,10

二、特征和多项式回归
如房价预测问题,

ℎ𝜃(𝑥)=𝜃0+𝜃1×𝑓𝑟𝑜𝑛𝑡𝑎𝑔𝑒+𝜃2×𝑑𝑒𝑝𝑡ℎ 𝑥1=𝑓𝑟𝑜𝑛𝑡𝑎𝑔𝑒(临街宽度),𝑥2=𝑑𝑒𝑝𝑡ℎ(纵向深度),𝑥=𝑓𝑟𝑜𝑛𝑡𝑎𝑔𝑒∗𝑑𝑒𝑝𝑡ℎ=𝑎𝑟𝑒𝑎(面积),则:ℎ𝜃(𝑥)=𝜃0+𝜃1𝑥。 线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型:ℎ𝜃(𝑥)=𝜃0+𝜃1𝑥1+𝜃2𝑥22 或者三次方模型: ℎ𝜃(𝑥)=𝜃0+𝜃1𝑥1+𝜃2𝑥22+𝜃3𝑥33
通常我们需要先观察数据然后再决定准备尝试怎样的模型。 另外,我们可以令: 𝑥2=𝑥22,𝑥3=𝑥33,从而将模型转化为线性回归模型。 根据函数图形特性,我们还可以使: ℎ𝜃(𝑥)=𝜃0+𝜃1(𝑠𝑖𝑧𝑒)+𝜃2(𝑠𝑖𝑧𝑒)2 或者: ℎ𝜃(𝑥)=𝜃0+𝜃1(𝑠𝑖𝑧𝑒)+𝜃2√𝑠𝑖𝑧𝑒
注:如果我们采用多项式回归模型,在运行梯度下降算法前,***特征缩放***非常有必要
三、正规方程
规方程是通过求解下面的方程来找出使得代价函数最小的参数的:𝜕𝜕𝜃𝑗𝐽(𝜃𝑗)=0 。 假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0=1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量 𝜃=(𝑋𝑇𝑋)−1𝑋𝑇𝑦 。 上标T代表矩阵转置,上标-1 代表矩阵的逆。设矩阵𝐴=𝑋𝑇𝑋,则:(𝑋𝑇𝑋)−1=𝐴−1 以下表示数据为例:
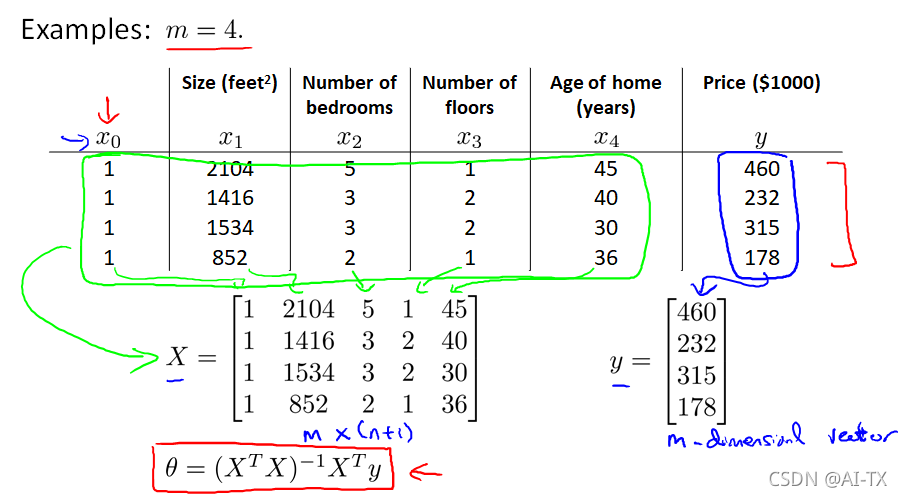
注:对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率𝛼 | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量𝑛大时也能较好适用 | 需要计算(𝑋𝑇𝑋)−1 如果特征数量𝑛较大则运算代价大,因为矩阵逆的计算时间复杂度为𝑂(𝑛3),通常来说当𝑛小于10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数𝜃的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
代码如下(示例):
import numpy as np def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y #X.T@X等价于X.T.dot(X)
return theta
四、作业展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入数据
path = 'G:\网盘资料\机器学习题目代码及数据文件\线性回归\数据文件\ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
data.head()
data.describe()
#数据可视化
data.plot(kind='scatter', x='Population', y='Profit', figsize=(8,5))
plt.show()
#定义代价函数
def computeCost(X, y, theta):
inner = ((X@theta)-y)**2
return np.sum(inner) / (2 * len(X))
#训练集中添加一列1
data.insert(0, 'Ones', 1)
#获取训练集数据
X = data.iloc[:, :-1].as_matrix()
y = data.iloc[:, -1].as_matrix()
theta = np.zeros(X.shape[1])
#检查维度
X.shape, theta.shape, y.shape
#定义梯度下降函数
def gradient(X,y,theta):
m=len(y)
for i in range(1000):
theta=theta-(0.01/97)*X.T@(X@theta-y)
return theta
#计算最终theta值
theta=gradient(X,y,theta)
fig, ax = plt.subplots(figsize=(6,4))
x = np.linspace(data.Population.min(), data.Population.max(), 100) #设置直线x坐标的数据集
y=theta[0]+theta[1]*x #设置直线y坐标的数据集
ax.plot(x, y, 'r', label='Prediction') #画直线
ax.scatter(data.Population, data.Profit, label='Traning Data') #画点,前两个参数是点的x和y坐标的数据集
ax.legend(loc=2) #点和线的图例,2表示在左上角。不写这句的话图例出现不了
ax.set_xlabel('Population') #接下来设置坐标轴名称和图题
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









