






对链表的认识:数据域+指针域。和列表不一样的是,链表的指针不是它本身,而是它下面的一个指针属性的值。
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next第一题:移除链表元素
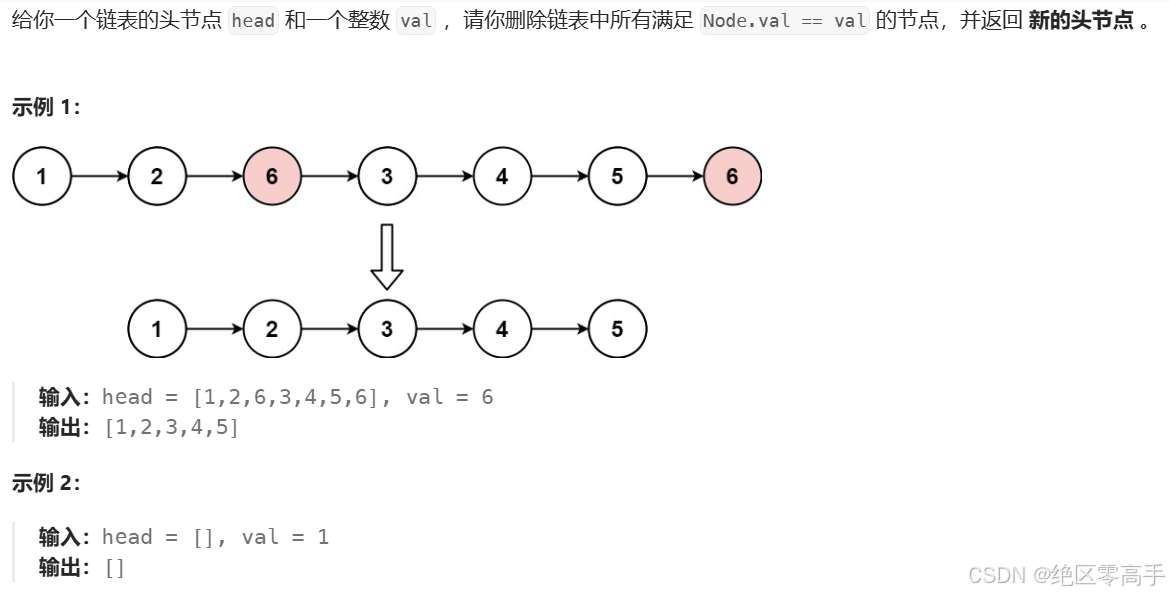
题解方法1:递归,应该也是链表解题常用的一个特性。把删除链表节点的问题归纳为不停地拆去一个点后,对链表剩下的部分求删除链表节点的问题,python代码如下。首先判断head是不是空的对象,防止报错'NoneType' object has no attribute 'next'的问题。然后,先看返回值return,如果head.val==val了,没有这一个节点了,那么head就被head.next取代了,返回看到head.next=self.removeElements(head.next,val)这一步,返回head之后直接给head.next赋值,让当前head的next属性指向下一个head也就是head.next。有点抽象,举个例子。当前链表有[A,toB],[B,toC],[C,toD]三个节点,现在在[A,toB]这个小节,head.next就是指向B这个小节,刚好我的val值是B,那么toC就被赋值为head.next,就是[C,toD]这个小节,(我的下一个的下一个是我),就没有[B,toC]这个小节了。否则,[B,toC]还是[B,toC]返回head(我的下一个是我)。
class Solution(object):
def removeElements(self,head,val):
"""
:type head: Optional[ListNode]
:type val: int
:rtype: Optional[ListNode]
"""
if not head:return
head.next=self.removeElements(head.next,val)
return head.next if head.val==val else head题解方法2:因为在头节点中的val值判断是要通过它本身来判断,而别的节点中的值可以用上一个节点的指针来判断,二者的处理方式不太一样,因此要在头节点左边添加一个虚拟节点dummy,便于将头节点和其他节点统一处理。定义dummy_head为链表类,next是头节点也就是head。定义cur=dummy_head,循环到链表最后:用while(cur.next!=None),判断下一个节点的值是否为val,如果为val则跳过下一个节点,即cur.next=cur.next.next,如果不为val,前进一个节点cur到cur.next的位置进行下一步判断。最后返回头节点的时候,要返回dummy_head.next,因为dummy_head设定为head左边的一个节点。
class Solution(object):
def removeElements(self, head, val):
"""
:type head: Optional[ListNode]
:type val: int
:rtype: Optional[ListNode]
"""
dummy_head=ListNode(next=head)
cur=dummy_head
while(cur.next!=None):
if(cur.next.val==val):
cur.next=cur.next.next
else:
cur=cur.next
return dummy_head.next这个解法依然有一个问题,就是为什么最后返回的是dummy_head.next,dummy和cur都是一个结点对象的两个引用,改变cur的指向就会改变整个链表的结构,但是不会改变链的完整性。为什么不返回cur?因为cur在终点,dummy在起点,但其实他俩内存位置一样的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









