




 本文提出自适应证据驱动推理网络APER,用于不可回答问题的机器阅读理解。它能定位并融合证据片段,自适应选择抽取答案或输出不可回答预测。通过引入逻辑一致性训练目标,保证答案提取和不可回答预测任务的逻辑一致。实验表明,APER在SQuAD2.0和DuReader上表现优越,显著提高不可回答问题召回率。
本文提出自适应证据驱动推理网络APER,用于不可回答问题的机器阅读理解。它能定位并融合证据片段,自适应选择抽取答案或输出不可回答预测。通过引入逻辑一致性训练目标,保证答案提取和不可回答预测任务的逻辑一致。实验表明,APER在SQuAD2.0和DuReader上表现优越,显著提高不可回答问题召回率。
标题:APER: Adaptive Evidence-driven Reasoning Network for machine reading comprehension with unanswerable questions APER:用于不可回答问题机器阅读理解的自适应证据驱动推理网络
时间:2021年
期刊:Knowledge-Based Systems
作者:Wei Peng, Yue Hu, Jing Yu, Luxi Xing, Yuqiang Xie
摘要:
不可回答问题机器阅读理解不仅要求系统在可能的时候要回答问题,还要在给定段落中没有答案时输出不可回答的预测。该任务鼓励系统进行真正的语言理解,而不是传统抽取式阅读理解中只选择看起来与为题最相关的跨度。之前的方法有两个缺点。第一,它们大多利用一个简单的分类器或验证模块来决定问题是否可回答。然而,它们直接预测不可回答问题的可能性,这样的方法缺少明确的解释过程。第二,这些方法将答案抽取任务和不可回答MRC任务看作两个独立的任务,而没有考虑它们结果的逻辑一致性,这导致了这两个任务之间的矛盾性,即在相同问题上具有相对的结果。在本文中,我们提出了自适应证据驱动推理网络(APER),基于证据精炼推理器精炼的证据,自适应选择抽取答案跨度或输出不可回答预测。此外,APER直接关联这两个任务,通过提出的新颖的逻辑一致性训练目标,保证他们结果的逻辑一致性。在SQuAD2.0和DuReader上的实验证明了我们所提APER模型的优越性和有效性。
关键词:机器阅读理解,多步推理网络,逻辑一致性,证据提取
1 引言
机器阅读理解(MRC)在最近的NLP研究中蓬勃发展,各种神经模型[1-5]在一些基准[6-8]上迅速接近人类水平,其目的是鼓励机器理解给定段落的内容并回答问题[9]。抽取式机器阅读理解任务是MRC中的一个分支,它将阅读理解看作从给定段落中提取答案跨度。然而,目前的抽取式MRC任务方法有一个很强的假设:每个问题都能段落中找到答案。这样一来,模型只需要通过模式匹配选择看起来与问题最相关的跨度,而无需检查答案是否真正被文本包含[10]。因此,它们距离真正的语言理解仍然很远,而且不能预测不可回答问题[8,10],这在真实世界设置下更具有挑战性。
之前的方法通过简单的分类器或验证方法已经在不可回答MRC任务上做了一些尝试。[11]使用具有一个密集层的分类器来预测不可回答问题的可能性,而不知道为什么问题是不可回答的,切法明确的推理过程。[12]引入了一个验证模块来决定答案是否存在。然而,该模型趋向于使用可能错误的貌似真实的答案来进行推理。在我们的方法中,使用多部推理过程来精炼一些对预测不可回答问题有帮助的关键证据(在本文中,证据定义为实体或关系)。为了进一步说明基本的想法,在图1中展示了一个例子。
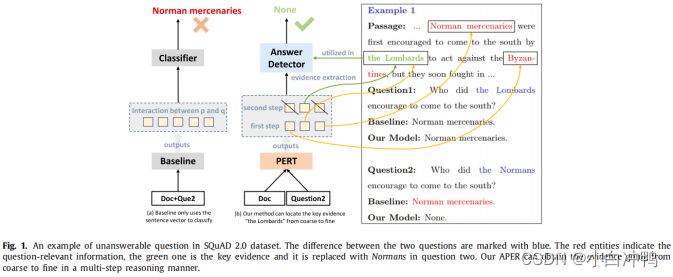
基线模型在问题1中输出了正确答案。然而,用Norman代替实体Lombards时,基线模型在问题2中仍然输出了相同的答案。尽管问题2与段落相关,但它实际上是不可回答的。对于问题2,基线模型并不关系段落中的事件主体Lombards,而是匹配encourage to come to the south,导致输出了错误答案Norman mercenaries。我们的目标是:尽管问题中的实体Lombards被替换了,但APER仍能定位到段落中的关键实体Lombards,与问题2中的实体Normans相矛盾,然后得出结论:是Lombards encouraged norman mercenaries to come to the south,而不是问题2中提到的Normans。在数据集中,大多数不可回答问题是通过改变或替换实体(例如,将问题中的Lombards替换成Normans)来干扰模型的。另外,之前的工作将答案提取任务和不可回答MRC任务看作两个独立的任务,导致在相同问题上有不一致的预测。可能是这样一种矛盾:答案被提取出来了,但是分类器任务问题是不可回答的。
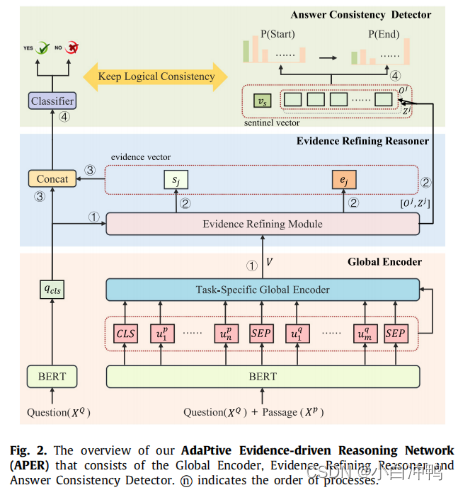
为了解决以上问题,我们提出了自适应证据驱动推理网络(APER),可以以多步推理的方式定位并融合证据片段,从事自适应选择提取答案跨度后者输出不可回答预测。具体来说,预训练语言模型被用作上下文编码器来学习更多通用的语言表示。然后,设计面向特定任务的全局编码器来有效整合全局特征。证据精炼推理器根据与问题的相关性融合所有可能的证据信息,从而得到用于后续模块的关键证据。最后,答案一致性检测器将给出正确答案或输出不可回答预测。为了明确构建答案提取任务和不可回答MRC任务之间的关系,引入了一个逻辑一致性训练目标,来保持这两个任务的逻辑一致性。我们模型的整体框架如图2所示,将在第3部分详细介绍。
本文的贡献可总结如下:
- 提出了APER,自适应地根据提取的证据提取答案跨度或输出不可回答预测,我们通过关键实体或关系解释了为什么问题是不可回答的。
- 设计了证据精炼推理器来全局融合问题相关的信息,从而精炼关键证据——是决定不可回答性的基础。
- 引入了一个新颖的逻辑一致性训练目标,以保持答案提取任务和不可回答MRC任务之间结果的逻辑一致性。
- 在两个数据集上的实验结果和消融研究表明,APER具有较强的竞争力,而且显著提供高了不可回答问题的召回率。
2 相关工作
2.1 MRC数据集
最近,随着发布的数据集,MRC任务吸引了许多兴趣。首先,该数据集是填空类型[6]的,例如CNN/DailyMail[9]和Children Book Test[13],让机器寻找实体填空。多选数据集RACE[14]和MCTest[15],要求系统从多个选项中选择一个答案。然后是抽取式MRC任务[7,16-18]。然而,在抽取式MRC任务中,这些数据集假设所有问题都可以回答,忽略了不可回答问题。在我们的工作中,重点是在SQuAD2.0和Dureader上,它们都提供了更贴近现实、更具挑战性的不可回答问题。
2.2 MRC模型
研究人员提出了大量机器阅读理解神经模型。UMN[19]使用ParaUF和AutoUF机制,从对话角度建模多选MRC。GF-Net[20]利用语言特征来实现答案选择过程中的作用。FNN-MRC[21]考虑使用框架语义知识来促进问答的语义理解。以上工作假设问题可以被给定段落回答,然而,具有不可回答问题的任务是MRC的一项巨大挑战。之前的工作设计了不同的方法,包括二进制分类器,关系网络和验证系统。[22]处理学习答案跨度的分布,还学习学习额外的无答案可能性。[11]关注将一个全连接层作为二进制分类器。尽管以上方法很容易实现,但它们并没有考虑为什么问题是不可回答的,而且准确率相对较低。[23]上传语义对象,生成没有明确建模问题和段落之间的相互交互和关系的不可回答问题的关系得分。[24]从外部知识库中引入了分层知识来增强预测可回答问题的模型表示。SG-Net[25]提出使用语法来指导段落和问题的文本建模,将明确的语法约束用到注意力机制中,从而更好地在语言上激励单词表示。但是,这需要构建给定段落句子和问题的依存解析树。[12]提出了一种用于验证候选答案是否确实被其周围的句子和问题支持的验证机制。然而,阅读后验证系统是一种流水线方法,会导致错误积累,而且会在可能错误的可信答案中进行验证。如何设计一个有效且可解释的模型是本文的重点。我们提出了APER,以端到端的方式由粗到细地精炼关键证据,用于不可回答问题的检测,并通过明确提炼一些实体和关系来对模型进行解释。
2.3 预训练语言模型
另一项有趣的研究是对MRC任务做出巨大贡献的预训练语言模型。之前的方法[26-30]采用传统的语言模型来提高下游任务。最近,一个显著的里程碑是BERT[31],它在11项自然语言任务中获得了最先进的成果。预训练语言模型通过遮掩语言模型和下一句预测两个任务训练大规模语料库,可以学习更多通用的语言表示,这有助于加速我们上层的推理,因此,预训练语言模型[32-34]被视为文本编码器。对于实验中用到的两个数据集,考虑使用两个BERT类型的模型RoBERTa和ALBERT,它们具有比BERT更强大的性能。其中,RoBERTa[35]引入了更多数据和更大的模型以获得更好的性能。ALBERT[36]提出减少内存消耗并加快训练速度,从而在资源有限的设备上可以有效运行。这两个预训练语言模型的性能也验证了我们模型的通用性。
3 方法
根据图2中的概述,提出的框架由三部分组成。第一,全局编码器得到面向特定任务的全局语义信息。第二,证据精炼推理器以多步推理方式精炼关键证据信息。第三,答案一致性检测器根据之前模块得到的关键证据提取正确答案或输出不可回答得分。在答案一致性检测器中引入新颖的逻辑一致性训练目标,保持答案提取任务和不可回答MRC任务之间的逻辑一致性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 到【灌水乐园】发言
到【灌水乐园】发言







