







前提内容
- html网页的简单编写:通过实例学Python爬虫(一)——认识HTML网页与爬虫基础框架
- urllib库的使用:Urllib库的使用(理论+代码演示)
- 正则表达式的构建:正则表达式(理论+代码演示)
- re正则库的使用:re正则库(理论+代码演示)
本节梗概
- 通过urllib库+re库正则匹配完成对当日新闻信息的爬取实例
文章目录
一、整体设计
通过前面的分享,其实已经能够完成简单的爬虫实例。在此就结合框架:urllib+re正则技术 来完成简单爬虫编写。
预计这次尝试爬取新闻网站,目标是抓取新闻标题与对应链接
注:爬虫模板不是通用的,不同的网址对应不同的定位筛选方式,但由于版权原因,此次编写的爬取新闻网站并为直接在代码中写明!。
二、编写思路
2.1 获取网站源代码
首先我们可以利用urllib进行模拟http请求,来获得响应报文从而得到对应的网页源码,在此我们可以直接使用在之前介绍urllib时编写好的模板,只需要传入url即可(想了解如何使用urllib库模拟请求以及各个方法的作用可以看看之前的文章),模板拿来,放入url测试是否能够获取源码:
def get_text(url):
#构造请求头
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#构造请求体
req = urllib.request.Request(url=url, headers=header)
#尝试访问
try:
res = urllib.request.urlopen(req)
# 先测试是否为HTTP错误
except urllib.error.HTTPError as e:
# 如果是,输出错误原因、报错信息、报错报文头
print(e.reason. e.code, e.headers, sep='\n')
# 再测试是否为URL范围错误
except urllib.error.URLError as e:
# 如果是,输出错误原因
print(e.reason)
else:
# ---- 访问成功 -----
byte_text = res.read()
# 检测编码格式,返回置信度和对应编码方式
result = chardet.detect(byte_text)
encode = result['encoding']
return byte_text.decode(encode)
if __name__ == '__main__':
url = input("请输入新闻网址:")
# url = "版权要求,此处url不能直接提供"
txt = get_text(url)
print(txt)
结果测试,已经能够成功获取网页源码:
2.2 正则匹配目的内容
得到网页源码,将其视为一段字符串,在前面内容也对网页源码组成,和正则匹配技术进行了一定了解,因此接下来需要观察目的信息的字符串格式,构建字符串模板。
2.2.1 观察网页源码结构

从浏览器的检查操作中可以发现所有新闻信息都在段落标签<div class=“busBox3”>为开头,标题与网址都在<h3>之下,因此我们可以挑选他们尝试作为匹配所有新闻信息的模板,利用之前介绍的re正则库来创建模板。
为了创建多条信息爬取,我们可以从此页面读取下一页的网址,可以使得对网站的新闻进行更多的获取,通过检查操作可以得到“下一页”的位置:

2.2.2 构建正则表达式
通过观察测试后,将以h3标签开头,其后紧接着<a target="_blank"标签为标志,进行创建正则模板,再进行匹配。
对于“下一页”的定位由于只是查找一个对象,因此选择<a class=“pagestyle”>为标志进行正则模板构建。
一定要分析清楚网页结构,选择合适的标志,否则可能匹配补全或者匹配不必要的信息
# 本页网址新闻信息
# <h3><a target="_blank" shape="rect" href="//cn.chinadaily.com.cn/a/202210/19/WS634f67faa310817f312f2802.html">问道|中国如何实现“双碳”目标?这两个地方值得看看</a>
# 创建re.Pattern对象
pattern = re.compile(r'<h3><a target="_blank" shape="rect" href="(.*?)">(.*?)</a>')
# 搜索所有符合模板的信息
answer_list = pattern.findall(txt)
# 下一页网址
# <a class="pagestyle" href="//cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd54ba2a3101a87ca8ff5ee/5bd54bdea3101a87ca8ff5f0/page_2.html">下一页</a>
pattern2 = re.compile(r'<a class="pagestyle" href="(.*?)">')
next_url = pattern2.findall(txt)
url = "http:" + next_url[0]
2.2.3 结果处理
通过构建的正则表达式与使用的方法可以得知,不考虑匹配失败的情况下,返回的结果应该是一个以长度为2的元祖作为元素的列表,本次实验结果先只进行简单输出。通过观察发现,匹配到的新闻网址都缺少访问协议,因此在这一步中应该对其统一处理,也需要设置好循环,能够使得不断自动获得下一页网址,并重复操作。
★三. 完整实例
3.1 完整代码
import chardet
import urllib
from urllib import request, error
import re
# urllib+re库:爬取新闻信息
def get_text(url):
#构造请求头
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#构造请求体
req = urllib.request.Request(url=url, headers=header)
#尝试访问
try:
res = urllib.request.urlopen(req)
# 先测试是否为HTTP错误
except urllib.error.HTTPError as e:
# 如果是,输出错误原因、报错信息、报错报文头
print(e.reason. e.code, e.headers, sep='\n')
# 再测试是否为URL范围错误
except urllib.error.URLError as e:
# 如果是,输出错误原因
print(e.reason)
else:
# ---- 访问成功 -----
byte_text = res.read()
# 检测编码格式,返回置信度和对应编码方式
result = chardet.detect(byte_text)
encode = result['encoding']
return byte_text.decode(encode)
if __name__ == '__main__':
# url = "版权要求,此处url不能直接提供"
url = input("请输入新闻网址:")
# 定义起始网址
number = eval(input("请输入预计检索的新闻页数(一页五十条左右):"))
for i in range(1, number+1):
print("--"*30+f"开始爬取第 {i} 页数据"+"--"*30)
# 获取网页源代码
txt = get_text(url)
# print(txt)
# 本页网址新闻信息
# <a target="_blank" shape="rect" href="//cn.chinadaily.com.cn/a/202210/19/WS634fd7b2a310817f312f28fd.html">总台海峡时评|祖国完全统一一定要实现,也一定能够实现!</a>
pattern = re.compile(r'<h3><a target="_blank" shape="rect" href="(.*?)">(.*?)</a>')
answer_list = pattern.findall(txt)
# 下一页网址
# <a class="pagestyle" href="//cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd54ba2a3101a87ca8ff5ee/5bd54bdea3101a87ca8ff5f0/page_2.html">下一页</a>
pattern2 = re.compile(r'<a class="pagestyle" href="(.*?)">')
next_url = pattern2.findall(txt)
url = "http:"+next_url[0]
# print(url)
print("--" * 28 + f"第 {i} 页数据爬取成功,数据如下" + "--" * 28)
# 输出本页检索结果
for news_url, news_title in answer_list:
news_url = "http:" + news_url
print("title:{}\t|\turl:{}".format(news_title, news_url))
# 结束报告
print("--" * 30 + f"爬取结束,本次成功爬取{number}页数据" + "--" * 30)
3.2 运行效果
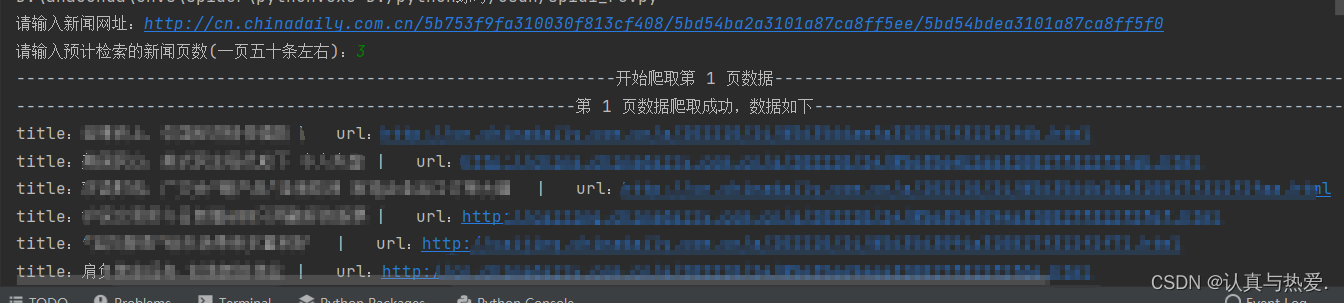
四、结尾
这次主要是基于urllib库与正则匹配的方式进行简单的爬虫项目实现,整体思路很简单,代码量也不多,urllib库获取对应源码能够套用模板,稍微难点的就在于正则部分,其实也不需要掌握太难的方法,有兴趣的看以看之前的正则匹配文章。
基于正则匹配的方法基本已经过时了,但是他确实也能作为完成爬虫的一种手段,在之后会介绍其他定位方式,完成爬虫会更加简单;另外之后也会介绍将爬取的数据用其他形式保存存入文本、图片、Excel表等,在这个记录分享过程中也能不断复习,不断提高。
文章和代码都为原创,在记录分享此篇文章时对文章内容和代码进行很多次修改,作者水平有限,难免出现一些错误或者问题,因此
内容仅供参考,也欢迎大家提出问题共同讨论,共同进步。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









