1.原理分析
- 赫夫曼编码实现压缩的原理是将频繁使用的数据用较短的代码代替,较少使用的数据用较长的代码代替,每个数据的代码各不相同。这些代码都是二进制码,且码的长度是可变的。所以想要实现文本压缩、首先要将文本文件的数据使用IO流读取到程序中、通过使用HashMap来统计读取到的数据中每个字符出现的频率,获得权值数组。其次、就可以根据获取的字符频率来构造相应的赫夫曼树,在赫夫曼树类中添加获取赫夫曼编码和解密赫夫曼编码两个方法。
- 当构造完赫夫曼树实例之后,接下来要做的就是调用获取赫夫曼编码的方法,将获取到的二进制数据写入压缩文件中,由于不同的文件对应不用的赫夫曼编码,故在保存压缩文件的时候,还需要将相应的赫夫曼树序列化写入文件中。在解压文件的时候,先读取序列化的赫夫曼树对象,然后调用解码方法将压缩文件中的二进制数据传入进行解码。
2.设计存储结构
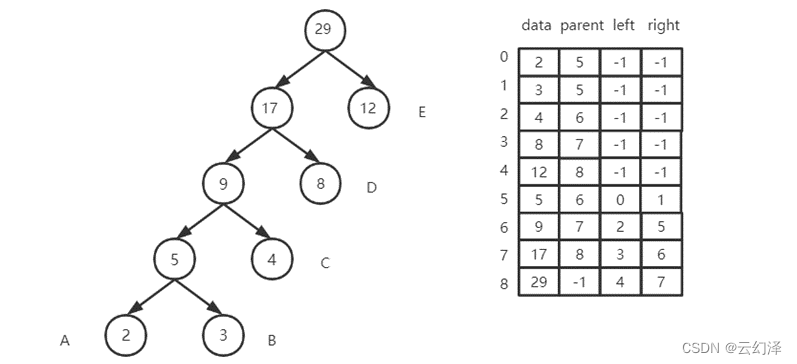
- 采用静态三叉链表存储赫夫曼树
- 存储结构示意图:
3.算法设计
(1)结点类
public class TriElement implements Serializable {
int data;
int parent, left, right;
public TriElement(int data, int parent, int left, int right) {
this.data = data;
this.parent = parent;
this.left = left;
this.right = right;
}
public TriElement(int data) {
this(data, -1, -1, -1);
}
public String toString() {
return "(" + this.data + "," + this.parent + "," + this.left + "," + this.right + ")";
}
public boolean isLeaf() {
return this.left == -1 && this.right == -1;
}
}
(2)构造赫夫曼树
import java.io.Serializable;
import java.util.*;
public class HuffmanTree implements Serializable {
private String charset;
private TriElement[] element;
Map<String, Integer> map;
public HuffmanTree(String str) {
Map<Character, Integer> charCount = getCharCount(str);
int mapLength = charCount.size();
char[] chars = new char[mapLength];
int[] weight = new int[mapLength];
Iterator<Map.Entry<Character, Integer>> iterator = charCount.entrySet().iterator();
int i = 0;
while (iterator.hasNext()) {
Map.Entry<Character, Integer> curr = iterator.next();
chars[i] = curr.getKey();
weight[i] = curr.getValue();
i++;
}
this.charset = new String(chars);
createTriElements(weight);
this.map = new HashMap<>();
for (int j = 0; j < this.charset.length(); j++)
map.put(this.charset.charAt(j) + "", j);
}
private void createTriElements(int[] weights) {
int n = weights.length;
this.element = new TriElement[2 * n - 1];
for (int i = 0; i < n; i++)
this.element[i] = new TriElement(weights[i]);
for (int i = n; i < 2 * n - 1; i++) {
int min1 = Integer.MAX_VALUE, min2 = min1;
int x1 = -1, x2 = -1;
for (int j = 0; j < i; j++)
if (this.element[j].parent == -1) {
if (this.element[j].data < min1) {
min2 = min1;
x2 = x1;
min1 = this.element[j].data;
x1 = j;
} else if (this.element[j].data < min2) {
min2 = element[j].data;
x2 = j;
}
}
this.element[x1].parent = i;
this.element[x2].parent = i;
this.element[i] = new TriElement(min1 + min2, -1, x1, x2);
}
}
private String huffmanCode(int i) {
int n = 8;
char code[] = new char[n];
int child = i, parent = this.element[child].parent;
for (i = n - 1; parent != -1; i--) {
code[i] = (element[parent].left == child) ? '0' : '1';
child = parent;
parent = element[child].parent;
}
return new String(code, i + 1, n - 1 - i);
}
public String encode(String text) {
String compressed = "";
for (int i = 0; i < text.length(); i++) {
int j = this.map.get(text.charAt(i) + "");
compressed += this.huffmanCode(j);
}
return compressed;
}
public String decode(String compressed) {
String text = "";
int node = this.element.length - 1;
for (int i = 0; i < compressed.length(); i++) {
if (compressed.charAt(i) == '0')
node = element[node].left;
else
node = element[node].right;
if (element[node].isLeaf()) {
text += this.charset.charAt(node);
node = this.element.length - 1;
}
}
return text;
}
private Map<Character,Integer> getCharCount(String charset) {
Map<Character, Integer> map = new HashMap<>();
for (int i = 0; i < charset.length(); i++) {
Integer count = map.get(charset.charAt(i));
if (count == null) {
map.put(charset.charAt(i), 1);
} else {
map.put(charset.charAt(i), count + 1);
}
}
return map;
}
public String toString() {
String str = "Huffman树的结点数组:";
for (int i = 0; i < this.element.length; i++)
str += this.element[i].toString() + ",";
str += "\nHuffman编码 ";
for (int i = 0; i < this.charset.length(); i++)
str += this.charset.charAt(i) + ":" + huffmanCode(i) + ",";
return str;
}
}
(3)压缩解压工具类
import java.io.*;
public class CompressedFileUtil {
private static String getAfterName(String beforeName,String suffix) {
String prefix = beforeName.substring(0, beforeName.lastIndexOf('.') + 1);
return prefix + suffix;
}
public static String CompressedFile(File srcFilePath) {
FileInputStream fis = null;
FileOutputStream fos = null;
ObjectOutputStream oos = null;
String str = "";
try {
fis = new FileInputStream(srcFilePath);
int len = 0;
byte[] bytes = new byte[1024 * 1024];
while ((len = fis.read(bytes)) != -1) {
str += new String(bytes, 0, len);
}
System.out.println("文本内容为:" + str);
HuffmanTree huffmanTree = new HuffmanTree(str);
String encode = huffmanTree.encode(str);
oos = new ObjectOutputStream(new FileOutputStream("D://test//huffmanTreeObject.obj"));
oos.writeObject(huffmanTree);
oos.flush();
String afterName = getAfterName(srcFilePath.getAbsolutePath(),"hfm");
fos = new FileOutputStream(afterName);
fos.write(encode.getBytes());
fos.flush();
System.out.println("压缩成功");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return str;
}
public static void unzipFile(File srcFilePath,String desFilePath) {
FileInputStream fis = null;
ObjectInputStream ois = null;
FileWriter writer = null;
try {
fis = new FileInputStream(srcFilePath);
byte[] bytes = new byte[1024 * 1024];
int len = 0;
String str = "";
while ((len = fis.read(bytes)) != -1) {
str += new String(bytes,0,len);
}
ois = new ObjectInputStream(new FileInputStream("D://test//huffmanTreeObject.obj"));
HuffmanTree huffmanTree = (HuffmanTree) ois.readObject();
String decode = huffmanTree.decode(str);
String txt = desFilePath + File.separator + srcFilePath.getName().replace(".hfm",".txt");
writer = new FileWriter(txt);
writer.write(decode);
writer.flush();
System.out.println("解压成功");
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4.调试分析
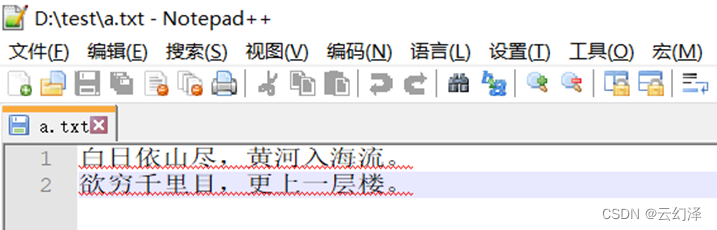
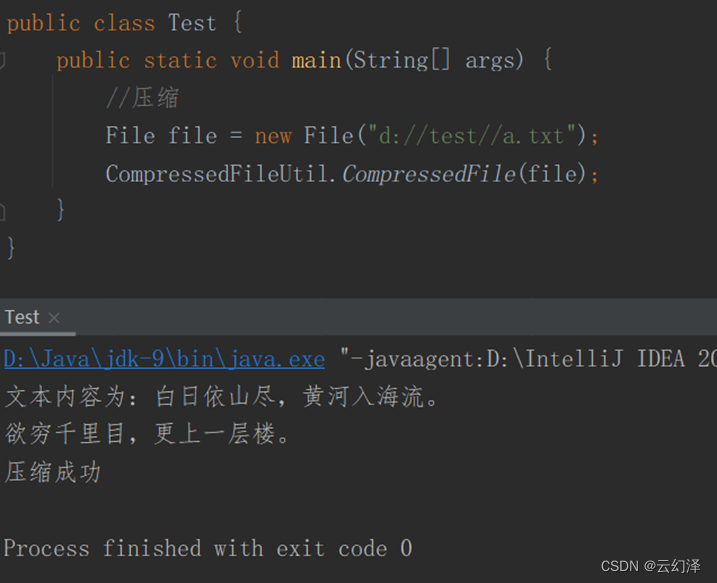
- 读取文档中的古诗,压缩成赫夫曼编码

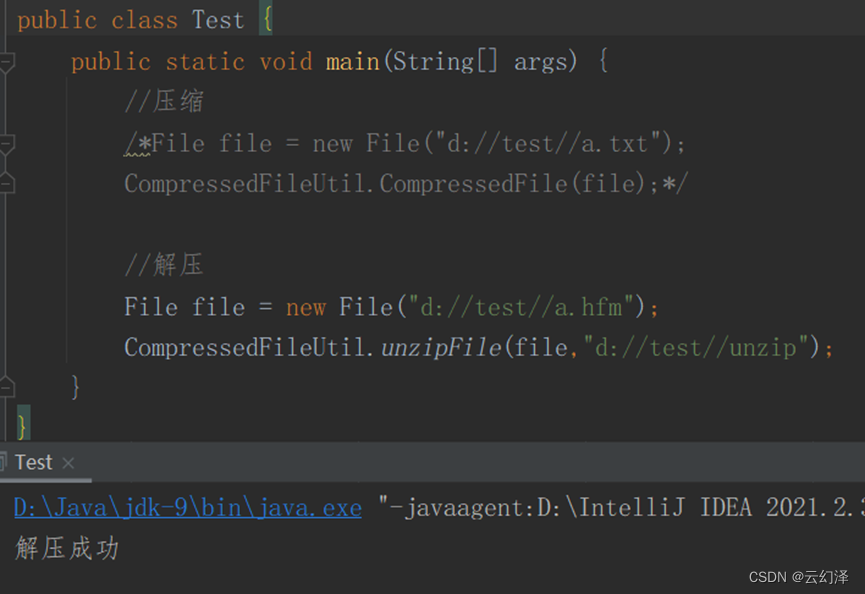
- 实现解压,将赫夫曼编码转成文本
5.总结

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









