






一般源码的测试代码涉及很多文件,因项目需要写一个独立测试的代码。传入的是字典
一、yolov5测试代码
import time
import cv2
import os
import numpy as np
import torch
from modules.detec.models.common import DetectMultiBackend
from modules.detec.utils.dataloaders import LoadImages
from modules.detec.utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from modules.detec.utils.augmentations import letterbox
from modules.detec.utils.plots import Annotator, colors
class DetectionEstimation:
def __init__(self, model_path, conf_threshold=0.9, iou_threshold=0.45, img_size=(640,640)): #(384,640) 适用1280x720 (640,640)适用640x480
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.model = DetectMultiBackend(model_path).to(self.device)
self.conf_threshold = conf_threshold
self.iou_threshold = iou_threshold
self.img_size = img_size
def _preprocess_image(self, img_dict):
img_tensor_list = []
original_sizes = {}
for serial, img in img_dict.items():
original_size = img.shape[:2]
img_resized = letterbox(img, self.img_size, stride=32, auto=True)[0]
img_resized = img_resized.transpose((2, 0, 1))[::-1]
img_resized = np.ascontiguousarray(img_resized)
img_tensor = torch.from_numpy(img_resized).float().to(self.device)
img_normalized = img_tensor / 255
if len(img_normalized.shape) == 3:
img_normalized = img_normalized[None]
img_tensor_list.append(img_normalized)
original_sizes[serial] = original_size
image_input = torch.cat(img_tensor_list)
return image_input, original_sizes
def _postprocess_predictions(self, predictions, im, original_sizes):
results = {}
for i, (det, (serial, img)) in enumerate(zip(predictions, original_sizes.items())):
if det is not None and len(det):
# det[:, :4] = scale_boxes(self.img_size, det[:, :4], img).round()
det[:, :4] = scale_boxes(im[2:], det[:, :4], img).round() #与源码的detect.py的Process predictions第172行保持一致,这里是关键,就是im[2:]这里把原本的图像尺寸取到,就不会再出现尺寸不同的图片测试结果框会不对的情况了
labels = []
coordinates = []
for *xyxy, conf, cls in reversed(det):
label = self.model.names[int(cls)]
labels.append((label, conf.item()))
coordinates.append([xyxy[0].item(), xyxy[1].item(), xyxy[2].item(), xyxy[3].item()])
results[serial] = {
'labels': labels,
'coordinates': coordinates
}
return results
def predict(self, img_dict):
start_total = time.time()
start_preprocess = time.time()
img_tensor, original_sizes = self._preprocess_image(img_dict)
preprocess_time = time.time() - start_preprocess
print(f"Preprocess Time: {preprocess_time * 1000:.2f}ms")
start_inference = time.time()
with torch.no_grad():
predictions = self.model(img_tensor)
inference_time = time.time() - start_inference
print(f"Inference Time:{inference_time * 1000:.2f}ms")
start_non_max_suppression = time.time()
pred = non_max_suppression(predictions, self.conf_threshold, self.iou_threshold)
non_max_suppression_time = time.time() - start_non_max_suppression
print(f"Non-Max Suppression Time: {non_max_suppression_time * 1000:.2f}ms")
start_postprocess = time.time()
results = self._postprocess_predictions(pred,img_tensor.shape, original_sizes)
postprocess_time = time.time() - start_postprocess
print(f"Postprocess Time: {postprocess_time * 1000:.2f}ms")
total_time = time.time() - start_total
print(f"Total Processing Time: {total_time * 1000:.2f}ms")
print("res:",results)
return results
def draw_results(self, img_dict, results):
annotated_images = {}
for serial, img in img_dict.items():
if serial in results:
det = results[serial]['coordinates'] # 从 results 中提取处理后的坐标
labels = results[serial]['labels'] # 提取标签和置信度
annotator = Annotator(img, line_width=3, example=self.model.names)
for i, (xyxy, (label, conf)) in enumerate(zip(det, labels)):
# 生成标签信息
label_str = f'{label} {conf:.2f}'
# 绘制检测框和标签
annotator.box_label(xyxy, label_str, color=colors(i, True))
annotated_images[serial] = annotator.result()
return annotated_images
def _save_labels(self, results, output_folder, batch_size=3):
os.makedirs(output_folder, exist_ok=True)
img_serials = list(results.keys())
for i in range(0, len(img_serials), batch_size):
batch = img_serials[i:i + batch_size]
combined_filename = '_'.join(batch) + '_labels.txt'
labels_path = os.path.join(output_folder, combined_filename)
with open(labels_path, 'w') as file:
for serial in batch:
if serial in results:
result = results[serial]
file.write("{\n")
# file.write(f" 'serial': '{result['serial']}',\n")
file.write(f" 'labels': {result['labels']},\n")
file.write(f" 'coordinates': {result['coordinates']},\n")
file.write("}\n\n")
if __name__ == "__main__":
model_path = 'data/pt/best.pt'
detector = DetectionEstimation(model_path)
img_folder = './data/2/'
img_dict = {}
img_filenames = []
for img_filename in os.listdir(img_folder):
img_path = os.path.join(img_folder, img_filename)
if img_path.lower().endswith(('.png', '.jpg', '.jpeg')):
img_data = cv2.imread(img_path)
serial = os.path.splitext(img_filename)[0]
img_dict[serial] = img_data
img_filenames.append(img_filename)
batch_size = 2
img_keys = list(img_dict.keys())
for i in range(0, len(img_keys), batch_size):
batch_dict = {k: img_dict[k] for k in img_keys[i:i + batch_size]}
results = detector.predict(batch_dict)
annotated_images = detector.draw_results(batch_dict, results)
os.makedirs('results', exist_ok=True)
for serial, img in annotated_images.items():
output_path = f'results/0208/{serial}.jpg'
success = cv2.imwrite(output_path, img)
if not success:
print(f'Error saving image {output_path}')
else:
print(f'Successfully saved image {output_path}')
detector._save_labels(results, 'results/0208/labels', batch_size=batch_size)
在该代码同级目录下放models、results、utils文件夹和export.py
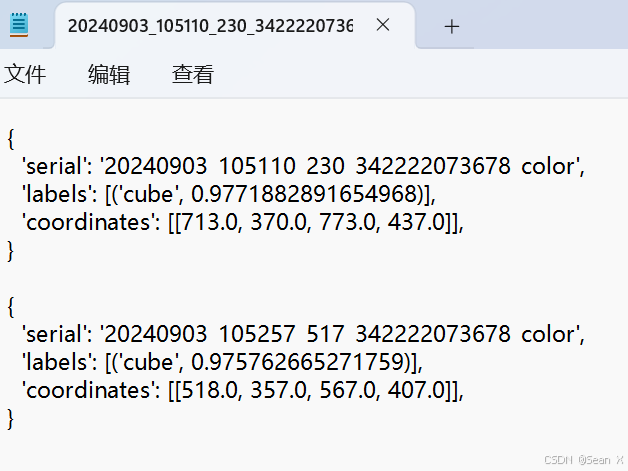
运行该代码得到的txt文件是字典:
二、yolov8测试代码
import os
import cv2
import numpy as np
import torch
import time
from ultralytics import YOLO
from ultralytics.models.yolo.segment import SegmentationPredictor
from ultralytics.utils import DEFAULT_CFG
from datetime import datetime
class YOLOv8SegmentationPredictor(SegmentationPredictor):
def __init__(self, model_path, conf_threshold=0.7):
super().__init__(cfg=DEFAULT_CFG)
self.model = YOLO(model_path)
self.conf_threshold = conf_threshold
def _preprocess_image(self, img_dict):
img_tensor_list = []
original_sizes = {}
for serial, img in img_dict.items():
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
original_sizes[serial] = img_rgb.shape[:2] # 保存原始图像的尺寸
img_resized = cv2.resize(img_rgb, (640, 640)) # 调整为640x640
img_normalized = img_resized / 255.0 # Normalize image
img_tensor = torch.from_numpy(img_normalized).float().permute(2, 0, 1).unsqueeze(0) # Convert to tensor
img_tensor_list.append(img_tensor)
image_input = torch.cat(img_tensor_list)
return image_input, original_sizes
def predict(self, img_dict):
#开始计时整个预测过程的时间
start_total = time.time()
#开始计时 预处理时间 (Preprocess Time)
start_preprocess = time.time()
#执行预处理操作
img_tensor, original_sizes = self._preprocess_image(img_dict)
#计算预处理时间
preprocess_time = time.time() - start_preprocess
print(f"Preprocess Time: {preprocess_time * 1000:.2f}ms") #以毫秒为单位打印时间
#开始计时 推理时间 (Inference Time)
start_inference = time.time()
#执行推理操作
preds = self.model(img_tensor)
#计算推理时间
inference_time = time.time() - start_inference
print(f"--------------Inference Time:{inference_time * 1000:.2f}ms") # 以毫秒为单位打印时间
#开始计时 后处理时间 (Postprocess Time)
start_postprocess = time.time()
#执行后处理操作
results = {}
idx = 0
for serial in img_dict:
pred = preds[idx]
boxes = pred.boxes if hasattr(pred, 'boxes') else None
#masks = pred.masks if hasattr(pred, 'masks') else None
labels = pred.names if hasattr(pred, 'names') else []
orig_height, orig_width = original_sizes[serial] # 使用原始分辨率
resized_height, resized_width = 640, 640 # 模型输入大小是640x640
if boxes:
coordinates = boxes.xyxy.cpu().numpy()
confidences = boxes.conf.cpu().numpy()
classes = boxes.cls.cpu().numpy()
valid_indices = confidences >= self.conf_threshold
coordinates = coordinates[valid_indices]
confidences = confidences[valid_indices]
classes = classes[valid_indices]
labels = [(self.model.names[int(cls)], conf) for cls, conf in zip(classes, confidences)]
# 根据原始分辨率进行调整
for coord in coordinates:
coord[0] *= orig_width / resized_width # x1 scaling
coord[1] *= orig_height / resized_height # y1 scaling
coord[2] *= orig_width / resized_width # x2 scaling
coord[3] *= orig_height / resized_height # y2 scaling
else:
coordinates = []
labels = []
"""
masks_resized = []
if masks is not None:
masks = masks.data.cpu().numpy()
for mask in masks:
resized_mask = cv2.resize(mask, (orig_width, orig_height), interpolation=cv2.INTER_LINEAR)
masks_resized.append(resized_mask)
"""
results[serial] = {
'labels': labels,
'coordinates': coordinates, # Removed .tolist() since it's already a list
#'masks': [mask.tolist() for mask in masks_resized] if masks_resized else []
}
idx += 1
#计算后处理时间
postprocess_time = time.time() - start_postprocess
print(f"--------------Postprocess Time:{postprocess_time * 1000:.2f}ms")
#计算整个处理时间
total_time = time.time() - start_total
print(f"--------------Total Processing Time: {total_time * 1000:.2f}ms")
"""
date_str = datetime.now().strftime("%Y%m%d")
output_folder = f'./data/2second_0826/17_results0902_{date_str}'
labels_folder = os.path.join(output_folder, 'labels')
# 不需要 batch_keys 参数
self._save_results(results, output_folder, img_dict)
self._save_labels(results, labels_folder)
"""
return results
def _save_results(self, results, output_folder, img_dict):
os.makedirs(output_folder, exist_ok=True)
for serial, result in results.items():
original_img = img_dict[serial]
masks = result['masks']
mask_color = np.zeros_like(original_img)
for mask in masks:
mask = np.array(mask)
mask = (mask > 0).astype(np.uint8)
mask_color[mask > 0] = [0, 255, 0]
overlay_img = cv2.addWeighted(original_img, 0.7, mask_color, 0.3, 0)
for (label, conf), coord in zip(result['labels'], result['coordinates']):
label_str = f"{label} ({conf:.2f})"
x1, y1, x2, y2 = coord
cv2.rectangle(overlay_img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(overlay_img, label_str, (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0),
2)
base_filename = os.path.splitext(serial)[0]
mask_path = os.path.join(output_folder, f"{base_filename}_overlay.png")
cv2.imwrite(mask_path, overlay_img)
def _save_labels(self, results, output_folder): #自己测试为了可以看保存的txt文件
os.makedirs(output_folder, exist_ok=True)
# 根据批次中的图像数量生成标签文件名称
img_serials = list(results.keys())
combined_filename = '_'.join(img_serials) + '_labels.txt'
labels_path = os.path.join(output_folder, combined_filename)
with open(labels_path, 'w') as file:
for serial, result in results.items():
# 提取相机序列号
cam_serial = serial.split('_')[-2] # 假设文件名结构为 YYYYMMDD_HHMMSS_<number>_<serial>_color.png
file.write("{\n")
file.write(f" 'SN': [{cam_serial}],\n")
file.write(f" 'serial':[{serial}],\n")
# Write labels and associated bounding boxes and mask coordinates
file.write(f" 'labels': {result['labels']},\n")
file.write(" 'coordinates': [\n")
for coord in result['coordinates']:
coord_str = ', '.join([f'{x:.2f}' for x in coord])
file.write(f" [{coord_str}],\n")
file.write(" ],\n")
if result['masks']:
file.write(" 'mask_coordinates': [\n")
for mask in result['masks']:
mask_coords = [f"({x},{y})" for (y, x) in np.argwhere(np.array(mask) > 0)]
file.write(f" {mask_coords},\n")
file.write(" ]\n")
else:
file.write(" 'mask_coordinates': 'No mask coordinates found'\n")
file.write("}\n\n")
"""def _save_labels(self, results, output_folder): #配合软件框架,不需要保存txt文件
os.makedirs(output_folder, exist_ok=True)
# 创建一个包含所有图片的标签文件
date_str = datetime.now().strftime("%Y%m%d")
combined_filename = f"labels_{date_str}.txt"
labels_path = os.path.join(output_folder, combined_filename)
with open(labels_path, 'w') as file:
for serial, result in results.items():
# 提取相机序列号
cam_serial = serial.split('_')[-2] # 假设文件名结构为 YYYYMMDD_HHMMSS_<number>_<serial>_color.png
file.write("{\n")
file.write(f" 'SN': [{cam_serial}],\n")
file.write(f" 'serial':[{serial}],\n")
# Write labels and associated bounding boxes and mask coordinates
file.write(f" 'labels': {result['labels']},\n")
file.write(" 'coordinates': [\n")
for coord in result['coordinates']:
coord_str = ', '.join([f'{x:.2f}' for x in coord])
file.write(f" [{coord_str}],\n")
file.write(" ],\n")
if result['masks']:
file.write(" 'mask_coordinates': [\n")
for mask in result['masks']:
mask_coords = [f"({x},{y})" for (y, x) in np.argwhere(np.array(mask) > 0)]
file.write(f" {mask_coords},\n")
file.write(" ]\n")
else:
file.write(" 'mask_coordinates': 'No mask coordinates found'\n")
file.write("}\n\n")
"""
if __name__ == '__main__':
model_path = './data/2second_0826/train/weights/best.pt'
conf_threshold = 0.3 # Set your desired confidence threshold here
# date_str = datetime.now().strftime("%Y%m%d")
img_folder = './data/2second_0826/images/'
predictor = YOLOv8SegmentationPredictor(model_path, conf_threshold)
img_dict = {}
img_filenames = []
for img_filename in os.listdir(img_folder):
img_path = os.path.join(img_folder, img_filename)
if img_path.lower().endswith(('.png', '.jpg', '.jpeg')):
img_data = cv2.imread(img_path)
serial = os.path.splitext(img_filename)[0] # Use filename without extension as serial
img_dict[serial] = img_data
img_filenames.append(img_filename)
# Process images in batches of 3
batch_size = 2
img_keys = list(img_dict.keys())
for i in range(0, len(img_keys), batch_size):
batch_dict = {k: img_dict[k] for k in img_keys[i:i + batch_size]}
start_batch = time.time() #开始计时整体批处理时间 (Batch Processing Time)
# results = predictor.predict(batch_dict, output_folder, labels_folder, batch_keys=img_keys[i:i + batch_size])
results = predictor.predict(batch_dict) # 处理图像批次
end_time = time.time()
batch_processing_time = (end_time - start_batch) * 1000 # 计算批处理时间并转换为毫秒
print(f"Processed batch {i // batch_size + 1} in {batch_processing_time:.2f} ms")
# print(f"Processed batch {i // batch_size + 1} in {batch_processing_time:.2f} seconds")
"""E:\software\anaconda3\anaconda3\envs\py39\python.exe E:\project\CODE\9_kuangjia\17_seg_true.py
0: 640x640 1 pocket_cube, 20.2ms
1: 640x640 1 pocket_cube, 20.2ms
Speed: 1.0ms preprocess, 20.2ms inference, 34.4ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 1 in 1.53 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 2.6ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 2 in 0.28 seconds
0: 640x640 1 pocket_cube, 6.0ms
1: 640x640 1 pocket_cube, 6.0ms
Speed: 0.5ms preprocess, 6.0ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 3 in 0.29 seconds
0: 640x640 1 pocket_cube, 5.0ms
1: 640x640 1 pocket_cube, 5.0ms
Speed: 0.5ms preprocess, 5.0ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 4 in 0.27 seconds
0: 640x640 1 pocket_cube, 5.0ms
1: 640x640 1 pocket_cube, 5.0ms
Speed: 0.5ms preprocess, 5.0ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 5 in 0.25 seconds
0: 640x640 1 pocket_cube, 5.0ms
1: 640x640 2 pocket_cubes, 5.0ms
Speed: 0.5ms preprocess, 5.0ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 6 in 0.37 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.8ms preprocess, 4.5ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 7 in 0.27 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 8 in 0.27 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 2.5ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 9 in 0.28 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 2.5ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 10 in 0.27 seconds
0: 640x640 1 pocket_cube, 4.0ms
1: 640x640 1 pocket_cube, 4.0ms
Speed: 0.5ms preprocess, 4.0ms inference, 2.5ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 11 in 0.27 seconds
0: 640x640 1 pocket_cube, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 12 in 0.27 seconds
0: 640x640 1 pocket_cube, 5.5ms
1: 640x640 1 pocket_cube, 5.5ms
Speed: 0.5ms preprocess, 5.5ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 13 in 6.21 seconds
0: 640x640 1 pocket_cube, 42.1ms
1: 640x640 1 pocket_cube, 42.1ms
Speed: 2.0ms preprocess, 42.1ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 14 in 0.36 seconds
0: 640x640 1 pocket_cube, 60.3ms
1: 640x640 1 pocket_cube, 60.3ms
Speed: 2.5ms preprocess, 60.3ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 15 in 0.39 seconds
0: 640x640 1 pocket_cube, 5.5ms
1: 640x640 1 pocket_cube, 5.5ms
Speed: 1.0ms preprocess, 5.5ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 16 in 0.30 seconds
0: 640x640 1 pocket_cube, 5.0ms
1: 640x640 1 pocket_cube, 5.0ms
Speed: 1.0ms preprocess, 5.0ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 17 in 0.26 seconds
0: 640x640 2 pocket_cubes, 5.5ms
1: 640x640 2 pocket_cubes, 5.5ms
Speed: 0.5ms preprocess, 5.5ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 18 in 0.59 seconds
0: 640x640 2 pocket_cubes, 4.5ms
1: 640x640 1 pocket_cube, 4.5ms
Speed: 0.5ms preprocess, 4.5ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 19 in 0.44 seconds
0: 640x640 1 pocket_cube, 10.0ms
1: 640x640 1 pocket_cube, 10.0ms
Speed: 0.5ms preprocess, 10.0ms inference, 3.7ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 20 in 0.33 seconds
0: 640x640 1 pocket_cube, 13.0ms
Speed: 1.0ms preprocess, 13.0ms inference, 6.0ms postprocess per image at shape (1, 3, 640, 640)
Processed batch 21 in 0.15 seconds
Process finished with exit code 0
"""三、yolo11track测试代码
from ultralytics import YOLO
import os, cv2, time
import numpy as np
import torch
print("CUDA Available:", torch.cuda.is_available()) # 检查是否有可用的 GPU
# 检查当前使用的 PyTorch 版本
print(f"PyTorch Version: {torch.__version__}")
# 检查默认的计算设备
print(f"Default device: {torch.cuda.current_device() if torch.cuda.is_available() else 'CPU'}")
class YOLO11TrackPredictor:
def __init__(self, model_path):
"""初始化 YOLO11TrackPredictor实例并加载预训练模型。"""
self.model = YOLO(model_path)
#强制将模型移到GPU
# self.model.to('cuda') #确保模型使用GPU
def predict(self, img_dict):
"""
处理给定字典中的图像,返回每个图像的推断结果字典。
{
"image_name": {
"labels": [(label, confidence)],
"coordinates": [[x_min, y_min, x_max, y_max]]
}
}
"""
results = {} # 使用字典来存储结果
# 记录加载和准备图像时间
track_image_loading_start = time.time()
images = list(img_dict.values()) # 直接使用图像数据,避免保存临时文件 减少临时文件操作
image_loading_end = time.time()
print(f"track图像加载和准备时间: {image_loading_end - track_image_loading_start:.4f}秒")
# # 临时保存图像
# temp_img_paths = []
# for serial, img_data in img_dict.items():
# temp_img_path = f'{serial}.jpg'
# cv2.imwrite(temp_img_path, img_data)
# temp_img_paths.append(temp_img_path)
# 记录开始时间
start_time = time.time()
# # 将所有图像转移到GPU
# images = [cv2.cvtColor(img, cv2.COLOR_BGR2RGB) for img in images]
# images = [img.transpose(2, 0, 1) for img in images] # 将图像转为 (C, H, W) 格式
# images = np.array(images)
# 记录推断时间
track_inference_start = time.time()
# 批处理进行推断
# result = self.model.track(source=temp_img_paths, batch=len(temp_img_paths), save=True, save_txt=True,
# save_crop=True, imgsz=640, conf=0.5)
# result = self.model.track(source=temp_img_paths, batch=len(temp_img_paths), save=True, imgsz=640, conf=0.5)
result = self.model.track(source=images, batch=len(images), imgsz=640, conf=0.5, tracker="bytetrack.yaml") #tracker="botsort.yaml"
inference_end = time.time()
print(f"track推断时间: {inference_end - track_inference_start:.4f}秒")
# 记录结束时间
end_time = time.time()
# 计算每秒处理的帧数 (FPS)
fps = len(img_dict) / (end_time - start_time)
print(f"track每秒处理帧数 (FPS): {fps:.2f}")
# 收集结果
track_collection_start_time = time.time() # 记录收集结果开始时间
for idx, r in enumerate(result):
serial = list(img_dict.keys())[idx] # 获取当前图像的 serial
result_data = {
#'serial': serial,
'labels': [],
'coordinates': [],
# 'mask_coordinates': []
}
# 处理检测框(boxes)
boxes = r.boxes if hasattr(r, 'boxes') else None
# masks = r.masks if hasattr(r, 'masks') else None
if boxes:
coordinates = boxes.xyxy.cpu().numpy() # 转换为 NumPy 数组
confidences = boxes.conf.cpu().numpy()
classes = boxes.cls.cpu().numpy()
# 过滤低置信度目标
valid_indices = confidences >= 0.5
coordinates = coordinates[valid_indices]
confidences = confidences[valid_indices]
classes = classes[valid_indices]
# 处理 labels 和 coordinates
result_data['labels'] = [(self.model.names[int(cls)], float(conf)) for cls, conf in
zip(classes, confidences)] # conf round(float(conf), 3)) confidence 置信度保留 三位
# result_data['coordinates'] = [list(coord) for coord in coordinates]
# result_data["coordinates"] = coordinates.tolist() # 转换为 Python 原生 list
result_data["coordinates"] = [[round(float(x), 1) for x in coord] for coord in coordinates.tolist()] #coordinates 中的数值将只保留 小数点后一位,coordinates.tolist():先将 NumPy 数组转换为 Python 的 list。round(x, 1): 保留一位小数,float(...): 确保是标准 Python float,
# # 处理分割掩码
# if masks:
# for mask in masks.xy:
# mask_coords = [f"({int(x)},{int(y)})" for x, y in mask]
# result_data['mask_coordinates'].append(mask_coords)
# 将当前检测结果添加到结果字典中
results[serial] = result_data
track_collection_end_time = time.time() # 记录收集结果结束时间
print(f"收集结果时间:{track_collection_end_time - track_collection_start_time:.4f}秒")
# # 删除临时文件
# for temp_img_path in temp_img_paths:
# os.remove(temp_img_path)
print("res:", results)
return results
if __name__ == "__main__":
# 创建 YOLO11TrackPredictor 实例并加载模型
trackdetector = YOLO11TrackPredictor("data/pt/best.pt")
# 加载图像到字典中
source = './data/images'
img_dict = {}
for img_filename in os.listdir(source):
img_path = os.path.join(source, img_filename)
if img_path.lower().endswith(('.png', '.jpg', '.jpeg')):
img_data = cv2.imread(img_path)
serial = os.path.splitext(img_filename)[0] # 使用文件名(不带扩展名)作为 serial
img_dict[serial] = img_data
# print("img_dict格式:", type(img_dict))
# 处理图像并获取推断结果
results = trackdetector.predict(img_dict)
# 打印所有推断结果
# print("所有检测结果:")
for result in results:
# for key, value in results.items():
# print(key, ":", value)
print(result)

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









