




1.Series简介
Pandas Series类似表格的列(column),类似于一维数组,可以保存任何数据类型,具有标签(索引),使得数据在处理分析时更具灵活性。Series数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力。
2.Series特点
(1)一维数组:Series是一维的,这意味着它只有一个轴(或维度),类似于 Python 中的列表。
(2)索引: 每个 Series 都有一个索引,它可以是整数、字符串、日期等类型。如果不指定索引,Pandas 将默认创建一个从 0 开始的整数索引。
(3)数据类型: Series可以容纳不同数据类型元素,包括整数、浮点数、字符串、Python 对象等。
(4)大小不变性:Series大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
(5)操作:Series支持各种操作,比如数学运算、统计分析、字符串处理等。
(6)缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
3.创建 Series
可以使用 pd.Series() 构造函数创建 Series 对象,传递数据数组(可以是列表、NumPy 数组等)和可选的索引数组。
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)(1)data:Series 的数据部分,可以是列表、数组、字典、标量值等。如果不提供此参数,则创建一个空的 Series。
(2)index:Series 的索引部分,用于对数据进行标记。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
(3)dtype:指定 Series 的数据类型。可以是 NumPy 数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
(4)name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。
(5)copy:是否复制数据。默认为 False,表示不复制数据。若设置为 True,则复制输入的数据。
(6)fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
4.指定索引值举例
import pandas as pd
a = ["Kalika", "KK", "Kali"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)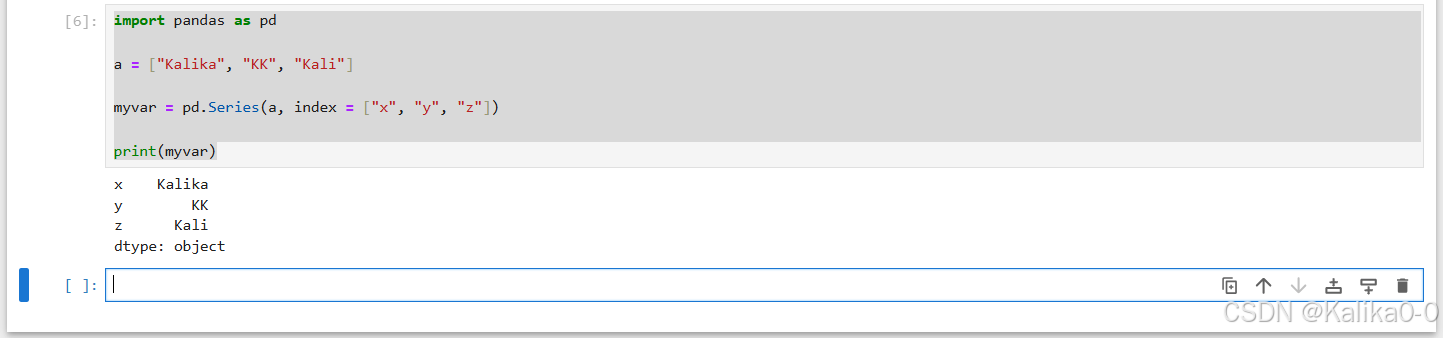
5.使用 key/value 对象类似字典举例
import pandas as pd
sites = {1: "Kalika", 2: "KK", 3: "Kali"}
myvar = pd.Series(sites)
print(myvar)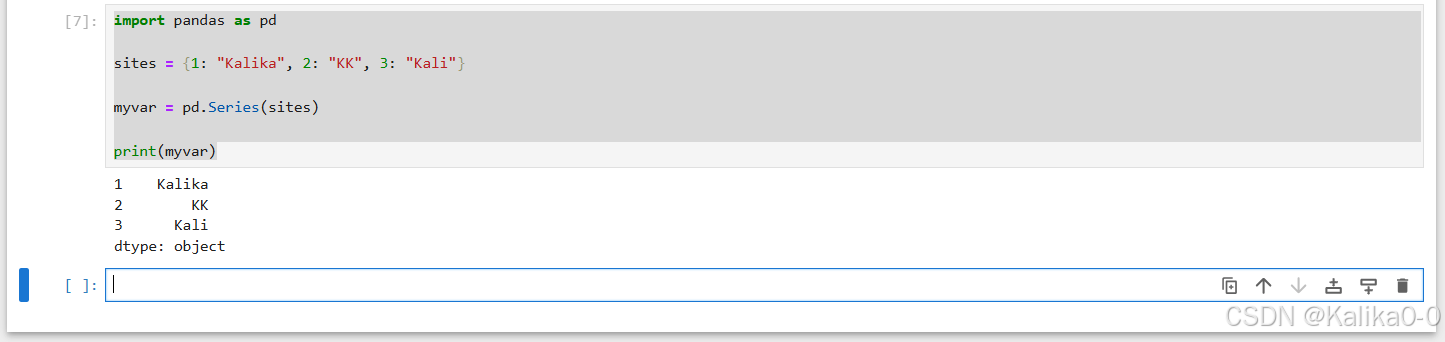
6. 使用列表、字典、数组创建默认索引Series
import pandas as pd # 导入pandas库
import numpy as np # 导入NumPy库
# 使用列表创建 Series
s = pd.Series([1, 2, 3, 4])
# 使用 NumPy 数组创建 Series
s = pd.Series(np.array([1, 2, 3, 4]))
# 使用字典创建 Series
s = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4})
7.Series基本操作
# 指定索引创建 Series
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
# 获取值
value = s[2] # 获取索引为2的值
print(s['a']) # 返回索引标签 'a' 对应的元素
# 获取多个值
subset = s[1:4] # 获取索引为1到3的值
# 使用自定义索引
value = s['b'] # 获取索引为'b'的值
# 索引和值的对应关系
for index, value in s.items():
print(f"Index: {index}, Value: {value}")
# 使用切片语法来访问 Series 的一部分
print(s['a':'c']) # 返回索引标签 'a' 到 'c' 之间的元素
print(s[:3]) # 返回前三个元素
# 为特定的索引标签赋值
s['a'] = 10 # 将索引标签 'a' 对应的元素修改为 10
# 通过赋值给新的索引标签来添加元素
s['e'] = 5 # 在 Series 中添加一个新的元素,索引标签为 'e'
# 使用 del 删除指定索引标签的元素。
del s['a'] # 删除索引标签 'a' 对应的元素
# 使用 drop 方法删除一个或多个索引标签,并返回一个新的 Series。
s_dropped = s.drop(['b']) # 返回一个删除了索引标签 'b' 的新 Series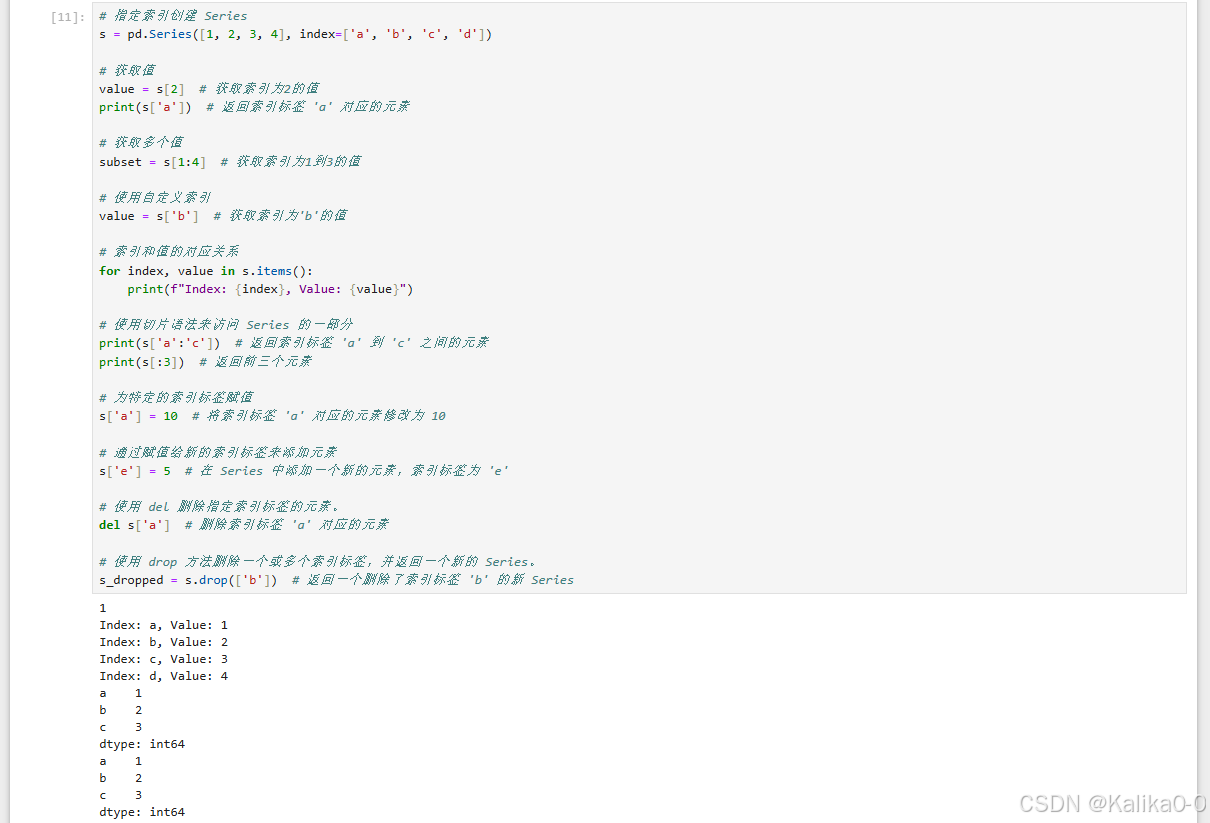
8.Series计算统计数据
print(s.sum()) # 输出 Series 的总和
print(s.mean()) # 输出 Series 的平均值
print(s.max()) # 输出 Series 的最大值
print(s.min()) # 输出 Series 的最小值
print(s.std()) # 输出 Series 的标准差
9.Series属性和方法
# 获取索引
index = s.index
# 获取值数组
values = s.values
# 获取描述统计信息
stats = s.describe()
# 获取最大值和最小值的索引
max_index = s.idxmax()
min_index = s.idxmin()
# 其他属性和方法
print(s.dtype) # 数据类型
print(s.shape) # 形状
print(s.size) # 元素个数
print(s.head()) # 前几个元素,默认是前 5 个
print(s.tail()) # 后几个元素,默认是后 5 个
print(s.sum()) # 求和
print(s.mean()) # 平均值
print(s.std()) # 标准差
print(s.min()) # 最小值
print(s.max()) # 最大值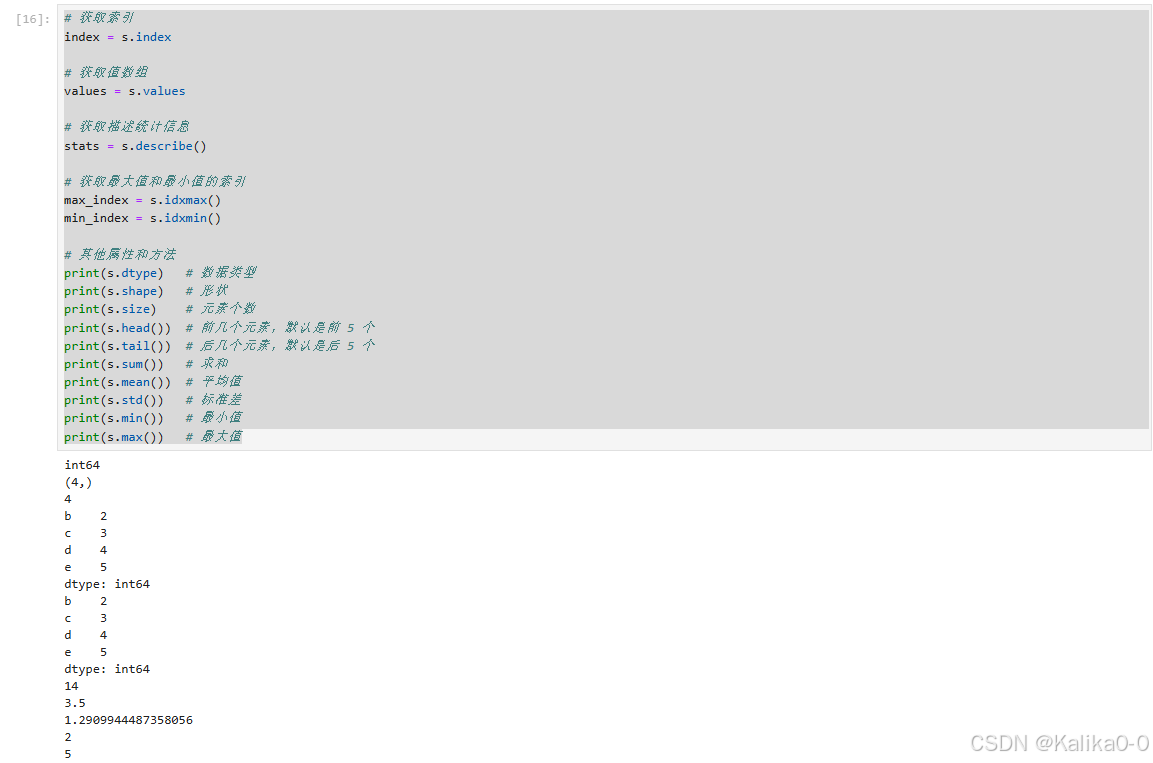
10.布尔表达式根据条件过滤 Series
print(s > 2) # 返回一个布尔 Series,其中的元素值大于 2
11.dtype属性查看 Series数据类型
print(s.dtype) # 输出 Series 的数据类型
12.astype 方法将 Series 转换为其他数据类型
s = s.astype('float64') # 将 Series 中的所有元素转换为 float64 类型
13.注意事项
Series的数据是有序的,可以将 Series 视为带有索引的一维数组。索引可以是唯一的,但不是必须的。数据可以是标量、列表、NumPy 数组等。如果没有指定索引,索引值就从 0 开始。

















 2919
2919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









