






第3章 数据仓库 作业
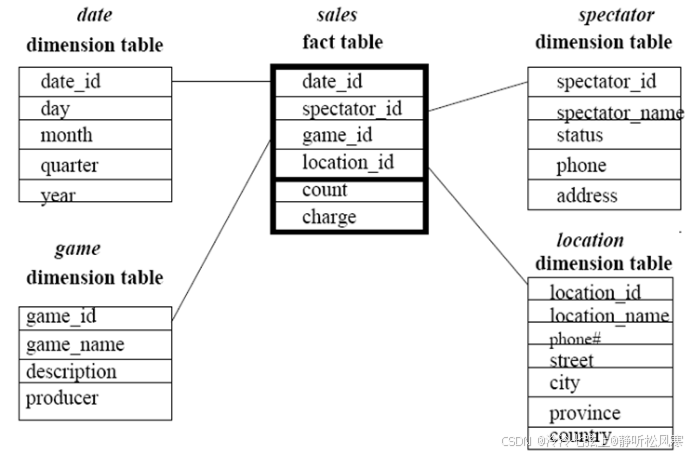
1. (简答题)假定数据仓库包含4个维: date(day, month, quarter, year), spectator(spectator_name, status, phone, address), location(location_name, phone#, street, city, province, country)和game(game_name, description, producer);2个度量: count和charge。其中, charge是观众在给定的日期观看节目的付费。观众可以是学生、成年人或老人(为status属性的取值),每类观众有不同的收费标准。
(a) 画出该数据仓库的星形模式图。
(b) 由基本方体[ date, spectator, location, game]开始,为列出2004 年学生观众在GM-Place (为location_name属性的一个取值)的总代价,应当执行哪些OLAP 操作?
正确答案:
沿date维从date_id “上卷”到year
沿game维从game_id “上卷”到all
沿location维从location_id “上卷”到location name
沿spectator维从spectator_id “上卷”到status
取status=“students”,location name=“GM Place”和year=2004切块
第4章 关联规则挖掘作业课后题
1. (简答题)
| TID | 购买的商品 |
| T100 | {A, C, S, L} |
| T200 | {D, A, C, E, B} |
| T300 | {A, B, C} |
| T400 | {C, A, B, E} |
1. 数据库有4个事务。设min_sup=60%,min_conf=80%。
(1)分别使用Apriori算法和FP增长算法找出所有的频繁项集。(14分)
(2)比较以上两种挖掘过程的有效性。(3分)
(3)列出所有的强关联规则,并与下面的元规则匹配:
buy(X,item1)∧buy(X,item2)⇒buy(X,item3),其中X代表顾客,itemi表示项的量。(3分)
正确答案:
1)Apriori算法:
由于只有4次购买事件,所以绝对支持度是4×min_sup>=3。
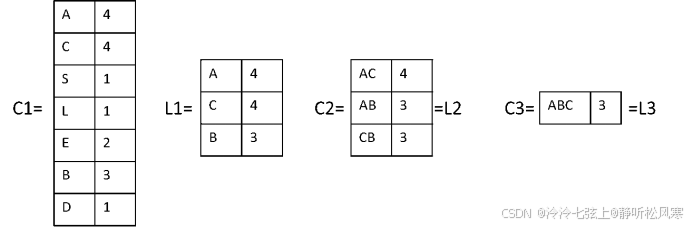
FP-Growth算法:
数据库的第一次扫描与Apriori 算法相同,得到L1。再按支持度计数的递减序排序,得到:L={(A:4), (C:4), (B:3) }。扫描每个事务,按以上L 的排序,从根节点开始,得到FP-树。

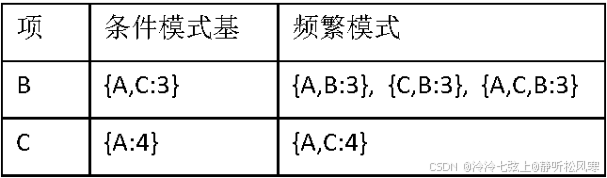
(2)效率比较:Apriori 算法的计算过程必须对数据库作多次扫描,而FP-增长算法在构造过程中只需扫描一次数据库,再加上初始时为确定支持度递减排序的一次扫描,共计只需两次扫描。由于在Apriori 算法中的自身连接过程产生候选项集,候选项集产生的计算代价非常高,而FP-增长算法不需产生任何候选项。
(3)由频繁3项集产生的与元规则匹配的规则有:
A,BàC(conf=3/3=100%)
A,CàB(conf=3/4=75%)
B,CàA(conf=3/3=100%)
所以,与元规则匹配的强关联规则为:
buys(X, “A”)∧buys(X, “B”)⇒buys(X, “C”)
buys(X, “B”)∧buys(X, “C”)⇒buys(X, “A”)


(a) 假定发现关联规则“hot dog-->hamburgers”。给定最小支持度阈值25%,最小置信度阈值50%,该关联规则是强的吗?
(b) 根据给定的数据,买hot dog独立于买hamburgers吗?如果不是,二者之间存在何种相关联系?
正确答案:
support = 2000/5000 = 40%, and confidence = 2000/3000 = 66.7%. 因此,此关联规则是强的。
lift(hotdog, hamburgers)
= P({hot dog, hamburgers})/(P({hot dog})P({hamburgers})
=0.4/(0.5×0.6) =1.33 > 1.
因此,购买hotdogs不独立于购买hamburgers。它们之间是正相关的。
第5章 聚类分析方法 作业
一. 论述题(共2题,100分)
1. (论述题)
假设数据挖掘的任务是将如下6个点(用(x,y)代表位置)聚类为2个簇:

以P1、P2为初始簇中心,距离函数是曼哈顿距离。用k-means算法给出:
(a) 在第一次循环执行后的两个聚类中心
(b) 最后的两个簇
要求写出具体的执行步骤。
正确答案:
第一次迭代:中心为1:P1(4,2.5), 2:P2(1,1)
| P3 | P4 | P5 | P6 | |
| P1 | 2 | 2 | 3 | 4 |
| P2 | 2.5 | 6.5 | 7.5 | 5.5 |
因此:
1:P1、P3、P4、P5、P6 (4,3.3)
2:P2 (1,1) (第一次迭代 4分)
第二次迭代:中心为:1:(4,3.3),2:(1,1)
| P1 | P2 | P3 | P4 | P5 | P6 | |
| (4,3.3) | 0.8 | 5.3 | 2.8 | 1.2 | 2.2 | 3.2 |
| (1,1) | 4.5 | 0 | 2.5 | 6.5 | 7.5 | 5.5 |
因此:
1:P1、P4、P5、P6 (4.25,3.75)
2:P2、P3 (2,1.25) (第二次迭代 4分)
第三次迭代:中心为:1:(4.25,3.75),2:(2,1.25)
| P1 | P2 | P3 | P4 | P5 | P6 | |
| (4.25,3.75) | 1.5 | 6 | 3.5 | 1 | 1.5 | 3 |
| (2,1.25) | 3.25 | 1.25 | 1.25 | 5.25 | 6.25 | 4.25 |
因此:
1:P1、P4、P5、P6 (4.25,3.75)
2:P2、P3 (2,1.25)
簇中心不再发生变化,算法终止。(第三次迭代 4分)
2. (论述题)假设数据挖掘的任务是采用AGNES算法将如下6个点(用(x,y)代表位置)聚类为2个簇(距离函数用曼哈顿距离):

要求写出具体的执行步骤。
正确答案:
点到点之间的距离的如下:

第一步:合并P1、P5,合并后: {P1、P5} {P2} {P3} {P4} {P6}
第二步:合并{P1、P5} {P4},合并后:{P1、P4、P5} {P2} {P3} {P6}
第三步:合并{P1、P4、P5} {P3},合并后:{P1、P3、P4、P5} {P2} {P6}
第四步:合并{P1、P3、P4、P5} {P2},合并后{P1、P2、P3、P4、P5} { P6}算法结束
第六章分类规则作业补充
一. 简答题(共1题,100分)
1. (简答题)
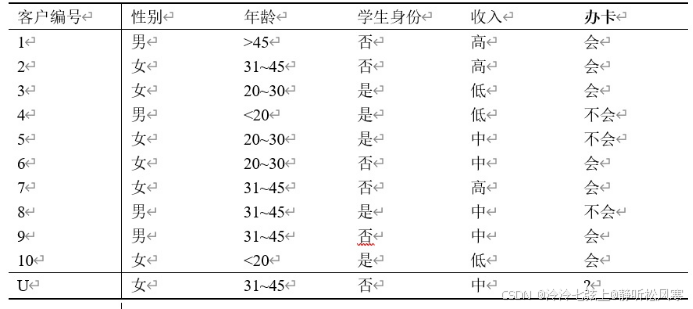
已知编号1~10为客户办信用卡的意愿调查情况,请使用朴素贝叶斯分类算法预测客户U是否会办卡。
正确答案:
A)计算训练样本中每个类别的频率: (2分)
P(办卡=会)=7/10 P(办卡=不会)=3/10
B) 计算P(办卡=不会|U)(5分)
P(性别=女|办卡=不会)=1/3 P(年龄=31~45|办卡=不会)=1/3
P(学生=否|办卡=不会)=0/3 P(收入=中|办卡=不会)=2/3 (2分,每个概率0.5分)
P(U|办卡=不会)=1/3*0/3*1/3*2/3=0 (1分)
在样本U条件下办卡=不会的概率P(办卡=不会|U)= P(U|办卡=不会)* P(办卡=不会)/P(U)=0/ P(U) (2分)
C) 计算P(办卡=会|U)(5分)
P(性别=女|办卡=会)=5/7 P(年龄=31~45|办卡=会)=3/7
P(收入=中|办卡=会)=2/7 P(学生=否|办卡=会)=5/7 (2分,每个概率0.5分)
P(U|办卡=会)=5/7*3/7*2/7*5/7=0.0625 (1分)
在样本U条件下办卡=会的概率P(办卡=会|U)= P(U|办卡=会)* P(办卡=会)/P(U)=0.044/ P(U) (2分)
D)结论:(1分)
P(办卡=会|U)> P(办卡=不会|U),所以:样本U={女 ,31~45,否,中, ?}的办卡类标号值应为:会办卡
1. (论述题)
你被搁浅在一个荒岛上,岛上到处都长满了蘑菇,但是找不到其他食物。有些蘑菇已被确定是有毒的,而其他无毒(通过先前同伴的试验和错误而确定)。你是唯一留在荒岛上的人。你有如下数据,使用你学过的某种算法预测U蘑菇是否有毒。
正确答案:
A)计算训练样本中每个类别的频率:
P(有毒否=1)=5/8 P(有毒否=0)=3/8
B) 有毒否=0:
P(厚实否=1|有毒否=0)=1/3 P(有味否=1|有毒否=0)=1/3
P(有斑点否=0|有毒否=0)=2/3 P(光滑否=0|有毒否=0)=2/3
P(U|有毒否=0)=1/3*1/3*2/3*2/3=0.0494
P(有毒否=0|U)= P(U|有毒否=0)* P(有毒否=0)/P(U)=0.0185/ P(U)
C) 有毒否=1:
P(厚实否=1|有毒否=1)=2/5 P(有味否=1|有毒否=1)=2/5
P(有斑点否=0|有毒否=1)=3/5 P(光滑否=0|有毒否=1)=2/5
P(U|有毒否=1)=2/5*2/5*3/5*2/5=0.0384
P(有毒否=1|U)= P(U|有毒否=1)* P(有毒否=1)/P(U)=0.024/ P(U)
根据计算结果:
P(有毒否=1|U)> P(有毒否=0|U),所以:样本U={1,1, 0, 0, ?}的有毒否类标号值应为1。
题型:
- 选择题(共28分,14小题)
- 判断题(共7分,7小题)
- 简答题(共20分,3小题)(数据仓库、关联规则提升度、KNN分类算法)
- 算法应用题(共45分,3小题,关联规则、聚类、分类三大类算法)
知识点:
| 绪论 |
|
| 数据预处理 |
|
| 数据仓库 |
|
| *关联分析 | 1.关联规则的相关概念:项集、支持度计数、频繁项集、规则的支持度和置信度 P86 2.挖掘规则的步骤:频繁项集的产生、规则的产生 P87 3.先验原理、Apriori算法(候选产生、候选前剪枝、支持度计算、候选后剪枝)、规则的产生P88-95 4.FP-Growth算法:FP树的构建、FP树的挖掘(条件模式基、频繁模式)P95-99 5.关联规则的评估:计算提升度 P104-106 |
| *聚类分析 | 1.聚类的概念 P118 2.相似度的计算(曼哈顿距离、欧几里得距离、简单匹配系数) P122-123 3.基于划分的聚类:概念、基于质心的划分方法(k-means算法)、基于中心的划分方法(PAM算法,了解) P126-128 4.层次聚类:概念、凝聚的层次聚类(AGNES算法)、分裂的层次聚类(DIANA算法 了解)P135-136 5.基于密度的聚类(DBSCAN算法)(核心点、直接密度可达、密度可达、密度相连、噪声)P143-144 |
| *分类 | 1. 分类的过程 P160-162 2. KNN算法 P164-165 (看课件例题) 3. 决策树的概念 P167-170 4. ID3分类算法:信息熵、信息增益、建立决策树、ID3算法的特点、C4.5算法的改进P171-174、176(此部分注意概念即可) 5. 贝叶斯定理相关概念 P181-182(看课件) 6. 朴素贝叶斯分类算法 P183-185 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









