



 本文介绍了Python的基础知识,包括关键字、运算符、数据类型、输入输出、格式化输出、文件操作、字符串、列表、元组、集合、字典、函数、面向对象、异常处理等。还探讨了Python的输入输出方法,如使用`input`和`open`,以及格式化输出的多种方式,如百分比、字符串、数字等。此外,还讲解了Python的文件写入和CSV处理,以及各种数据结构的操作,如列表的添加、删除、切片等。最后,介绍了正则表达式和常用模块如`random`和`re`的使用。
本文介绍了Python的基础知识,包括关键字、运算符、数据类型、输入输出、格式化输出、文件操作、字符串、列表、元组、集合、字典、函数、面向对象、异常处理等。还探讨了Python的输入输出方法,如使用`input`和`open`,以及格式化输出的多种方式,如百分比、字符串、数字等。此外,还讲解了Python的文件写入和CSV处理,以及各种数据结构的操作,如列表的添加、删除、切片等。最后,介绍了正则表达式和常用模块如`random`和`re`的使用。
想看python的关键字,可以用
import keyword print(keyword.kwlist)
>>> print(keyword.kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
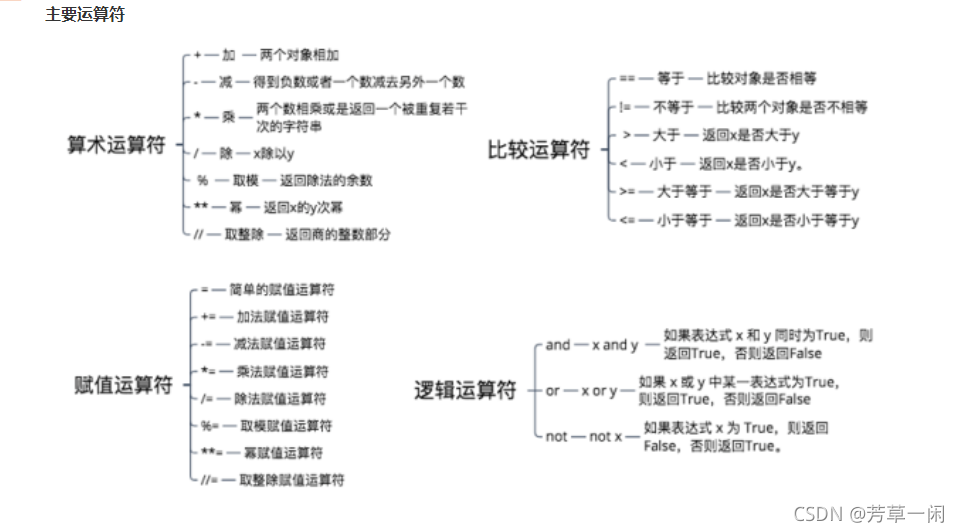
主要运算符
python基本数据类型
数据类型:
Numbers(数字):int, float, complex
Boolean(布尔类型): True False
python的输入
从键盘获取输入:input
从文件获取输入: open close
if __name__ == '__main__':
str = input("请输入:")
print(str)
f = open("D:\\python-data\\0910-1.ipynb", "r", encoding='utf-8')
while 1:
str = f.readline()
if not str:
break
print("readline=", str)
f.close()
python的输出
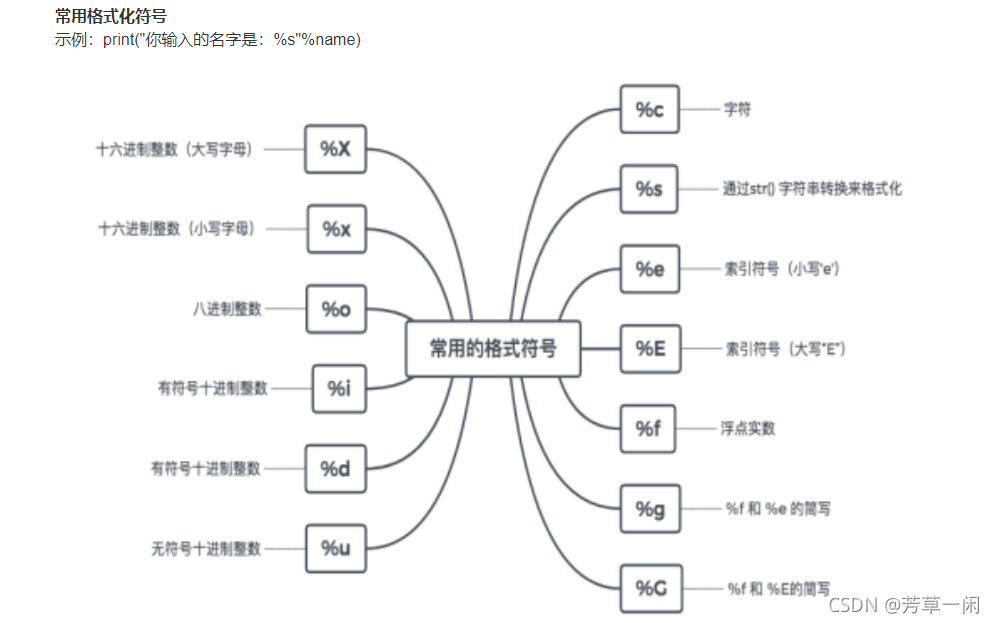
格式化符号:
格式 描述
%% 百分号标记 #就是输出一个%
%c 字符及其ASCII码
%s 字符串
%d 有符号整数(十进制)
%u 无符号整数(十进制)
%o 无符号整数(八进制)
%x 无符号整数(十六进制)
%X 无符号整数(十六进制大写字符)
%e 浮点数字(科学计数法)
%E 浮点数字(科学计数法,用E代替e)
%f 浮点数字(用小数点符号)
%g 浮点数字(根据值的大小采用%e或%f)
%G 浮点数字(类似于%g)
%p 指针(用十六进制打印值的内存地址)
%n 存储输出字符的数量放进参数列表的下一个变量中
% 格式化符也可用于字典,可用%(name)引用字典中的元素进行格式化输出
负号指时数字应该是左对齐的,“0”告诉python用前导0填充数字,正号指时数字总是显示它的正负(+,-)符号,即使数字是正数也不例外。
可指定最小的字段宽度,如:"%5d" % 2。也可用句点符指定附加的精度,如:"%.3d" % 3。
格式化操作符辅助指令
符号 作用
* 定义宽度或者小数点精度
- 用做左对齐
+ 在正数前面显示加号( + )
在正数前面显示空格
# 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X')
0 显示的数字前面填充 ‘0’ 而不是默认的空格
% '%%'输出一个单一的 '%'
(var) 映射变量(字典参数)
m.n m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话)
写入文件:
if __name__ == '__main__':
"""格式化字符:"""
year = 2021
month = 5
day = 1
print("%04d-%02d-%02d" % (year, month, day))
# 保留宽度为6的2位小数浮点型
fValue = 8.123
print("%06.2f")
# 以科学计数法输出浮点型保留2位小数
fValue = 1.2888
print("%.2e" % 1.2888)
'''写文件:'''
f = open("D:\\python-data\\test-data\\testwritefile.txt", "w", encoding='utf-8')
num = f.write("这是我写的第一行.\n 这是我写的第二行\n")
print(num)
f.close
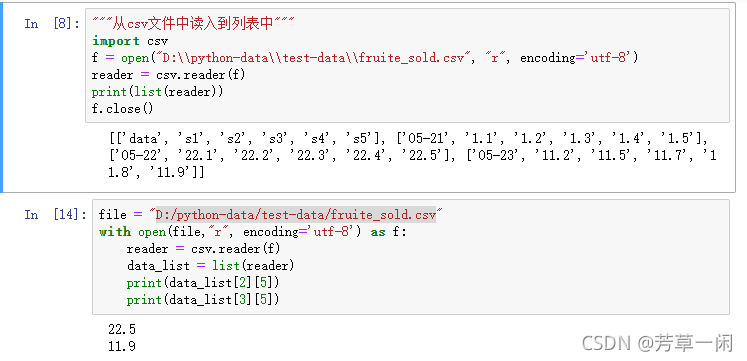
CSV处理:
列表方式读入
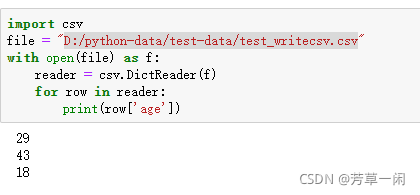
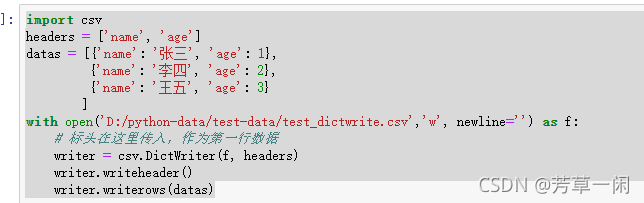
字典方式读入:
'''向CSV中写数据'''
列表方式写数据
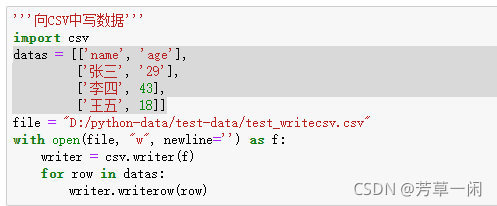
字典方式写数据:
列表添加元素
append()/insert(),append()将元素添加到列表的末端,insert()将新的元素添加到指定的位置
+ 组合两个列表生成新的列表
extend向调用它的列表中添加另外一个列表的元素
append和extend的区别是:如果append添加的是一个列表,则会把列表整体作为一个元素添加到列表末尾,
extend添加一个列表,是向调用它的列表中添加另一个列表的元素。

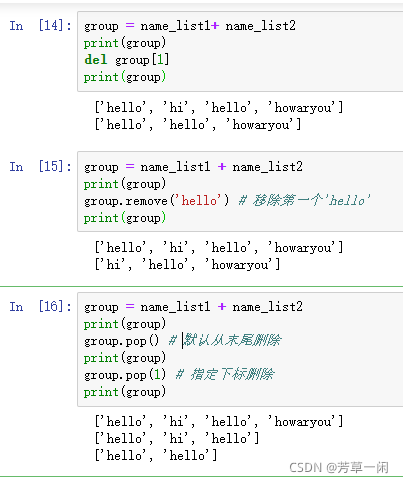
列表删除元素del/remove/pop
列表切片
格式:[start:end:step]
结果中包含start而不包含end
-1表示列表的最后一个元素
-2表示列表的倒数第二个位置
在step为默认的正数时,start必须在end的前面,否则就是空列表
使用in/not in判断元素在列表中是否存在
列表内元素重排序:sort

列表内倒置:reverse

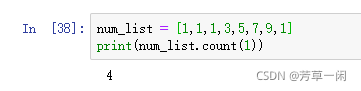
统计列表内指定元素个数:count()
从列表中找出某个值第一个匹配项的索引位置:index()
list.index(x[,start[, end]])
for循环:
for 临时变量 in 序列:
序列中存在等待处理元素则进入循环体执行代码
range:根据指定的开始位置,结束位置,以及步长,生成数字序列:
range(start, stop[,step])
for 临时变量 in range(...):
列表中存在待处理元素则进入循环体执行代码
pypthon的print函数之end:
print函数默认换行,是end='\n'在起作用,
print(value,...,sep=' ', end='\n', file=sys.stdout, flush=False)
如果不想换行,可以用print(xxx, end='')
列表推导式:
推导式的一种,推导式是可以从一个数据序列构建另一个新的数据序列的结构体。
列表推导式是用于列表类型的推导式。
基本格式:
variable = [out_exp_res for out_exp in input_list i f out_cond]
out_exp_res:列表生成元素表达式,可以是有返回值的函数。
for out_exp in input_list:迭代input_list将out_exp传入out_exp_res表达式中。
if out_cond:根据条件过滤哪些值可以(没有else)。
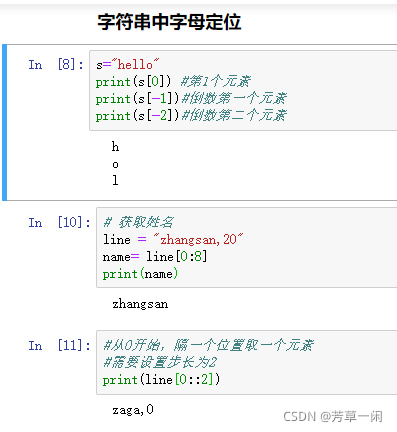
字符串:
字符串定义:
s = "hello" 或者'hello'
字符串串接:
方法一:使用+
方法二:使用字符串格式化符号将多个变量组成一个新的字符串

通过下标获取指定位置的字符:string_name[index]
切片:
切片的语法:string_name[起始:结束:步长]
字符串的方法
str.format()方法:字符串格式化方法:
可以接受不限个数参数,位置可以不按顺序
也可以通过字典或者列表索引设置参数
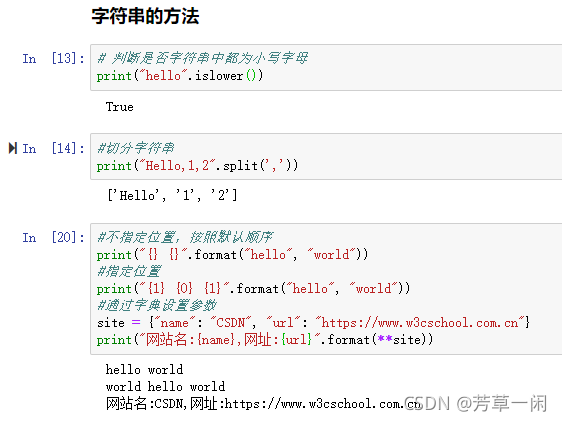

注: format字符串格式化用{}和:来实现%的功能,{0:.3}0表示第一个位置参数,.3表示小数点后保留3位
使用dir(字符串对象)可以获得这个对象的所有方法

元组
定义
顺序存储相同/不同类型的元素
元素之间用“,”隔开,使用()将元素括起来
特性
不可变,不支持添加、修改、删除元素操作
查询
通过下标查询元组指定位置的元素
空元组定义
none_tuple = ()
只包含一个元素的元组
one_tuple = ("one",)
定义可省略小括号
tuple_a = 1, 2
循环遍历元组
for item in tuple:
print(item)


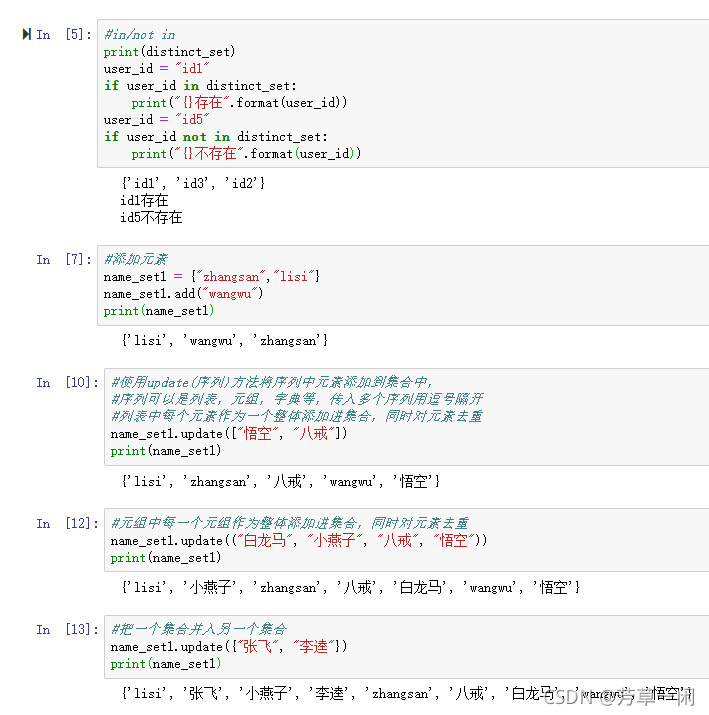
集合
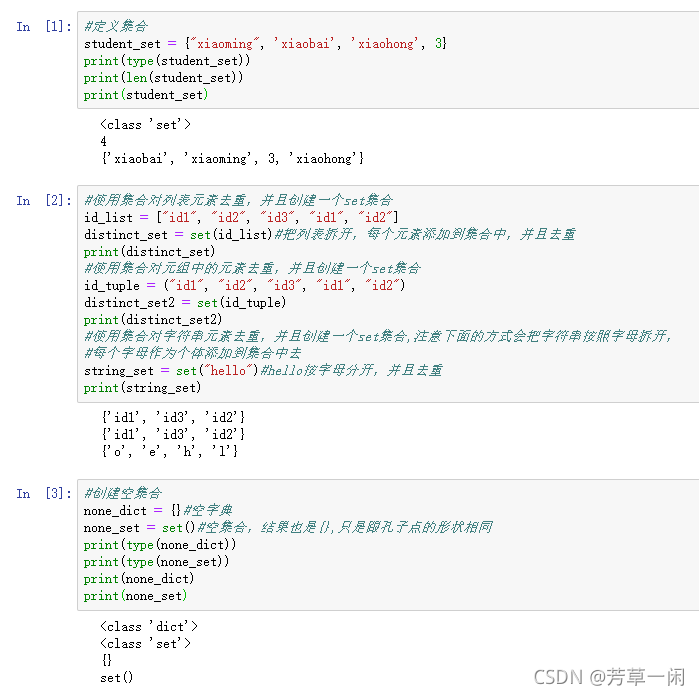
定义
无序存储不同数据类型不重复元素的序列
name_set={"xiaoming","xiaoqiang","xiaobai","lisi"}
创建空集合
none_set = set()
使用in和not in
判断一个元素在集合中是否存
add(元素)
添加一个元素到集合中
使用set(序列)来对一个序列去重,并且创建一个新的集合
update(序列)
将一个序列中的元素添加到集合中,同时对元素去重。
remove(元素)
根据元素值删除集合中指定元素,如果元素不存在,则报错。
discard(元素)
根据元素值删除集合中指定元素,如果元素不存在,不会引发错误。
pop()
随机删除集合中的某个元素,并且返回被删除的元素。
clear()
清空集合
集合操作
1. 交集intersection(&)
2. 并集union(|)
3. 差集difference(-)
4. 对称差集(^)
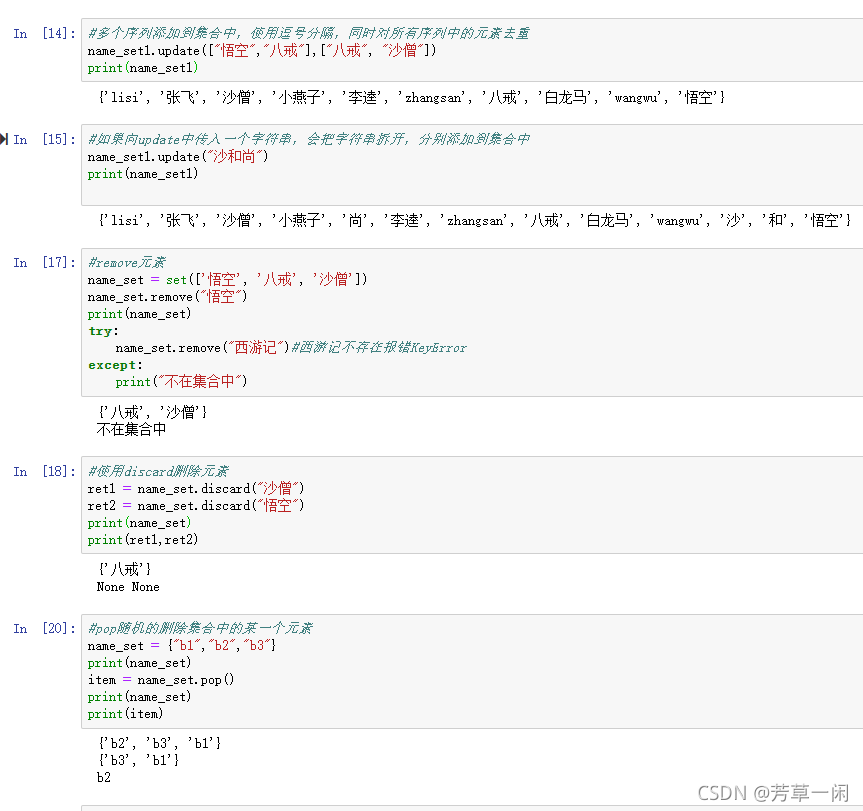

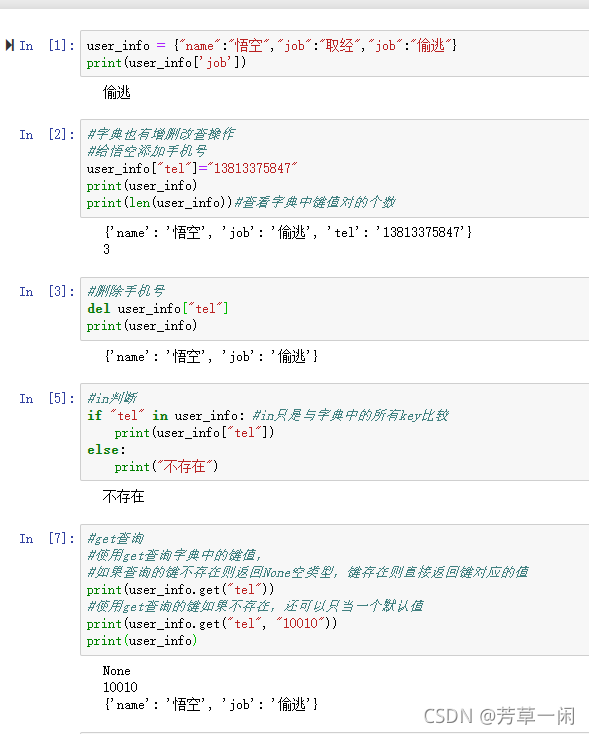
字典
存储Key-Value键值对类型的数据
{key1:value1,key2:value2,…}
查询
根据Key查找Value
主要内置方法
get、keys、values、items、clear
遍历字典
for key in user_info.keys():
print("{}:{}".format(key,user_info[key]))
for value in user_info.values():
print(value)
for item in user_info.items():
print(item)
print(item[0])#元组的第1个元素是key
print(item[1])#元组的第2个元素是value
for key,value in user_info.items():
print("{}:{}".format(key,value))
注意:即在字典中,有至少两个成员的键相同,但是键对应的值是不同的,
格式如下:
dict = {key1:value1,key1:value2,...}
这种情况下,后来赋值给键的值将作为键的真实值
python中字典的key必须是不可变数据类型
python中可变数据类型有list,set, dict,不可变数据类型有tuple,string,int ,float
列表转成字符串后可以作为字典的key值,但是要注意,列表转成字符串后,每个元素后面的逗号
后会默认放一个空格,即str([1,2,3])转成字符串后会编程'[1, 2, 3]'


函数
函数定义
def 函数名称 (参数) :
函数体代码
return 返回值
调用方法
函数名(参数)
缺省参数
1. 函数定义带有初始值的形参
2. 函数调用时,缺省参数可传,也可不传
3. 缺省参数一定要位于参数列表的最后
4. 缺省参数数量没有限制
命名参数
1. 调用带有参数的函数时,通过指定参数名称传入参数的值
2. 可以不按函数定义的参数顺序传入
局部变量
1. 函数内部定义的变量
2. 不同函数内的局部变量可以定义相同的名字,互不影响
3.作用范围:函数体内有效,其他函数不能直接使用
全局变量
1. 函数外部定义的变量
2. 作用范围:可以在不同函数中使用
3. 在函数内使用global关键字实现修改全局变量的值
如果在函数中想要修改全局变量,则需要先用global关键字来声明
但是列表,字典作为全局变量,在函数内修改他们的元素,则不使用global关键字;
注意:这点与简单变量不同
带返回值的函数
def x_y_sum_return(x,y):
res = x + y
return res
多返回值函数
可以返回列表,字典,元组
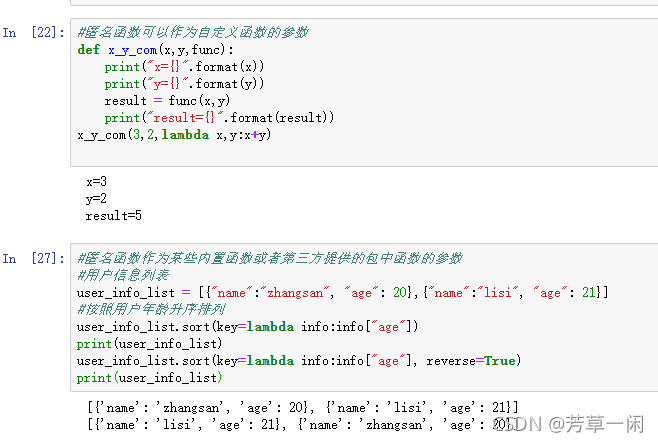
匿名函数定义方法
lambda [参数列表]:表达式
匿名函数可以作为参数被传入其他函数
面向对象基础-__init__构造方法
__init__构造方法
1. 调用时间:在对象被实例化时被程序自动调用
2. 作用:用于对象创建时初始化
3. 程序不显示定义init方法,则程序默认调用一个无参init方法
实例属性
所属于具体的实例对象,不同实例对象之间的实例属性互不影响
类属性
1. 所属于类对象,多个实例对象之间共享同一个类属性
2. 获取类属性方法:类名.类属性
3. 通过实例对象不能够修改类属性
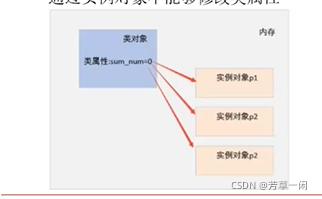
属性的访问权限
私有属性
1. 定义:__私有变量名
2. 只能在类内部使用,类外部不能访问,否则报错
私有方法
1. 只能在类内部调用,在类的外部无法调用
2. 定义私有方法在方法名前添加两个下划线
3. 类内部调用私有方法要使用self.私有方法的方式调用
异常的发生
捕获异常
try:
逻辑代码块
except ExceptionType as err:
异常处理方法
捕获多个异常
try:
逻辑代码块
except (ExceptionType1, ExceptionType2,…) as err:
异常处理方法
捕获所有可能发生的异常
try:
逻辑代码块
except (ExceptionType1, ExceptionType2,…) as err:
异常处理方法
except Exception as err:
异常处理方法
finally处理
try:
逻辑代码块
except (ExceptionType1, ExceptionType2,…) as err:
异常处理方法
except Exception as err:
异常处理方法
f
finally:
无论是否有异常产生,都会执行这里的代码块!
函数嵌套异常传递
函数嵌套调用时,如果执行过程中放生异常,若内层函数没有捕捉,异常会被逐层抛给外层调用者。
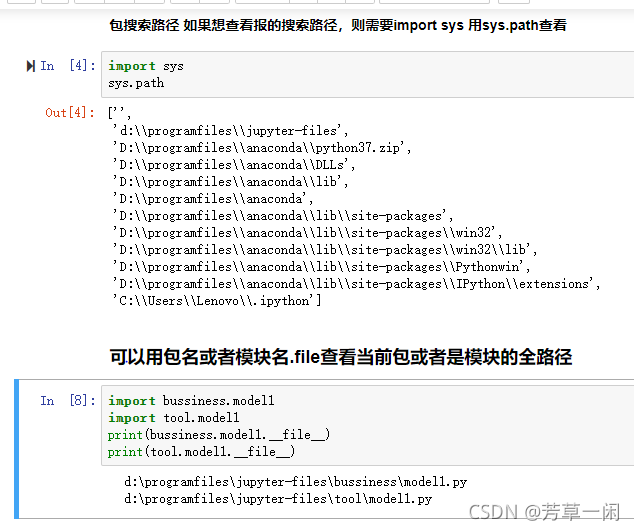
包和模块
模块的名字
.py文件的名字
引入模块的方式
引入单个模块
import model_name
引入多个模块
import model_name1,model_name2,…
引入模块中的指定函数
from model_name import func1,func2,…
定义别名
import model_name as xx
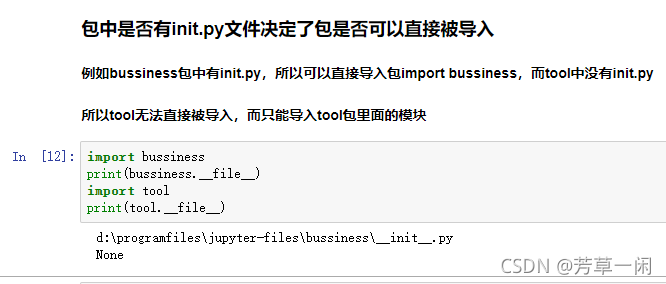
包中的__init__文件
1. 会在包或者该包下的模块被引入时自动调用
2. 常用于设置包和模块的一些初始化操作
代码结构样例
main
语法
if __name__ == '__main__'
作用
定义一个代码块,只在py文件以python命令方式被调用的时候被执行,而以模块方式被导入的时候不被执行。
zip函数
作用
将可迭代对象,打包成由对象中的对应元素组成的元组列表(Python2)或者Zip对象(Python3)
语法
zip([iterable, ...])
注意
1. 当各个迭代器的元素个数不一致时,则返回列表长度与最短的对象相同。
2. 使用”*”做解压操作。

enumerate
作用
将一个可遍历的数据对象(列表、元组等)组合为一个索引序列,同时列出数据和数据下标。
语法
enumerate(sequence, [start=0])
random
random()
0.0到1.0随机数
uniform(n, m)
n到m随机浮点数
randint(n, m)
n到m随机整数
randrange(n, m, x)
n到m之间步长为x的随机数
choice()
随机选择一个元素
shuffle()
混洗
sample()
取样若干元素
正则表达式
在Python中提供了re(regular expression简写)正则表达式模块,能够非常方便的使用正则表达式进行一些常用的规则验证。
常用方法:
match(正则表达式,待匹配字符串)方法
match方法用来进行正则匹配检查,如果待匹配字符串能够匹配正则表达式,则match方法返回匹配对象Match Object,否则返回None。match方法采用从左往右逐项比较。
group()方法
匹配对象Macth Object具有group方法,用来返回字符串的匹配部分。
示例:匹配以chinahadoop开头的字符串
import re
#
#匹配以chinahadoop开头的字符串
r
result = re.match("chinahadoop","chinahadoop.cn")
#
#打印匹配出来的内容
p
print(result.group())
运行结果:
chinahadoop
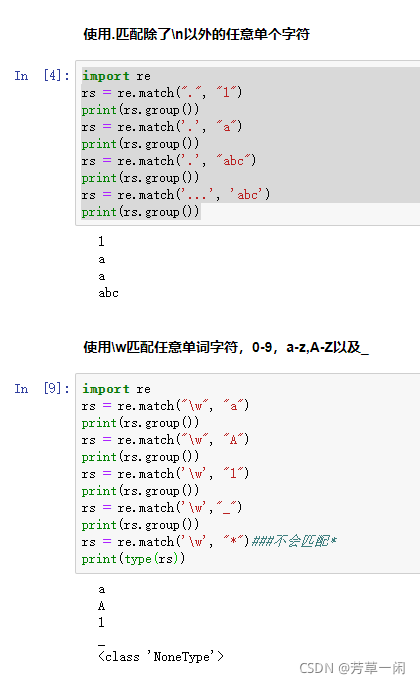
正则表达式-单字符匹配
.匹配除“\n”之外的任意单个字符
\
\d匹配0到9之间的一个数字,等价于[0-9]
\
\D匹配一个非数字字符,等价于[^0-9]
\
\s匹配任意空白字符,如空格、制表符“\t”、换行“\n”等
\
\S匹配任意非空白字符
\
\w匹配任意单词字符(包含下划线),如a-z,A-Z,0-9,_等
\
\W匹配任意非单词字符,等价于[^ a-zA-Z0-9_]
[
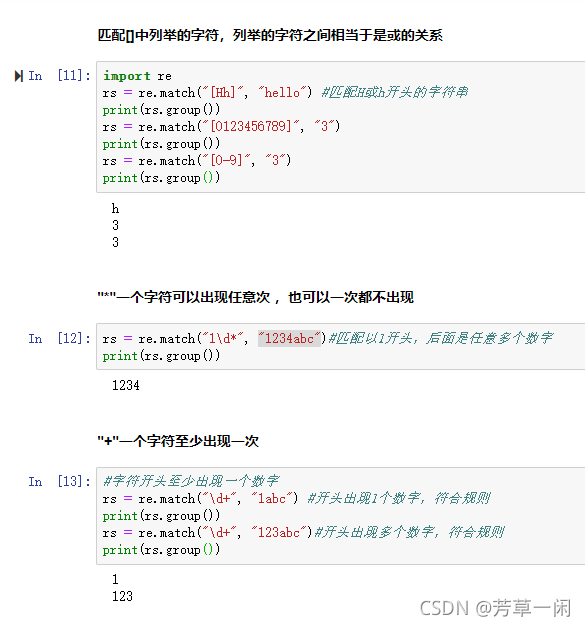
[ ]匹配[ ]中列举的字符
^
^取反
正则表达式-数量表示(匹配多个字符)
*一个字符可以出现任意次,也可以一次都不出现
+一个字符至少出现一次
?一个字符至多出现一次
{m}一个字符出现m次
{m,}一个字符至少出现m次
{m,n}一个字符出现m到n次
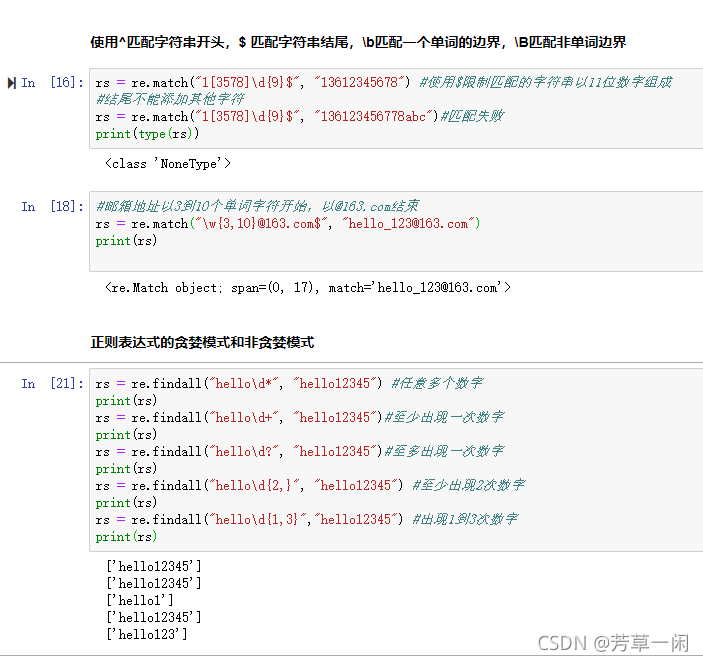
正则表达式-边界表示(在写正则表达式的时候,限制匹配的字符串的开始和结束边界)
^匹配字符串开头
$匹配字符串结尾
\b匹配一个单词的边界
\B匹配非单词边界
注意:边界字符只用于描述边界信息,不能用于字符的匹配
正则表达式-贪婪与非贪婪模式
贪婪模式:
正则引擎默认是贪婪模式,尽可能多的匹配字符。
非贪婪模式
与贪婪模式相反,尽可能少的匹配字符
在表示数量的“*”,“?”,“+”,“{m,n}”符号后面加上?,使贪婪变成非贪婪。
re.findall函数
语法:findall(pattern, string, flags=0)
说明:返回string中所有与pattern相匹配的全部字串,返回形式为数组)
正则表达式的() [] {}有不同的意思。
() 是为了提取匹配的字符串。表达式中有几个()就有几个相应的匹配字符串。
(\s*)表示连续空格的字符串。
[]是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s*]表示空格或者*号。
{}一般用来表示匹配的长度,比如 \s{3} 表示匹配三个空格,\s[1,3]表示匹配一到三个空格。
(0-9) 匹配 '0-9′ 本身。 [0-9]* 匹配数字(注意后面有 *,可以为空)[0-9]+ 匹配数字(注意后面有 +,不可以为空){1-9} 写法错误。
[0-9]{0,9} 表示长度为 0 到 9 的数字字符串。


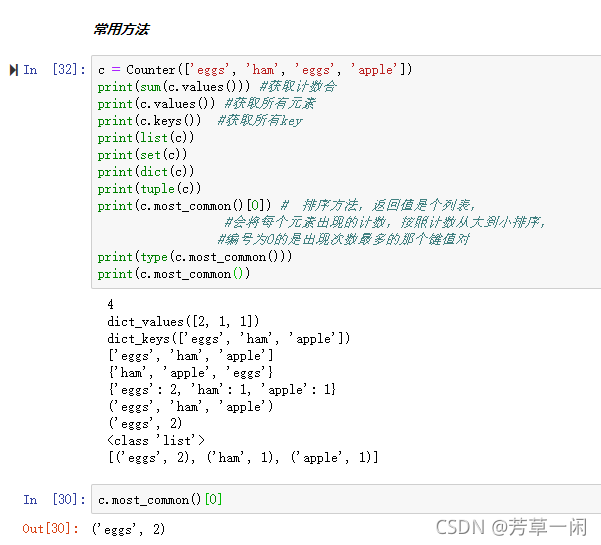
Collections Counter
1. 跟踪dict、set、list、tuple等结构中值出现的次数
2. 无序的容器类型,以字典的键值对形式存储
3. 元素作为key,其计数作为value
4. 计数值可以是任意的Interger(包括0和负数)




















 4436
4436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









