







11 Requests+PyQuery+PyMongo基本案例实践
4月一直在找工作和忙毕业论文,好久没更新笔记了,自我督促下!努力养成写博客的习惯!
准备工作
- 安装好Python3(版本>=3.6),能成功运行Python3程序
- 了解Python多进程的基本原理
- 了解Python HTTP请求库requests的基本用法
- 了解正则表达式的用法和Python中正则表达式库re的基本用法
- 了解PythonHTML解析库pyquery的基本用法
- 了解MongoDB并安装和启动MongoDB服务
- 了解Python的MongoDB操作库PyMongo的基本用法
以上内容在之前的笔记中有过整理,不熟悉的伙伴可以去看看
爬取目标
我们以一个基本的静态网站作为案例进行爬取,爬取链接为https://static1.scrape.center/,这个网站里面包含了一些电影信息
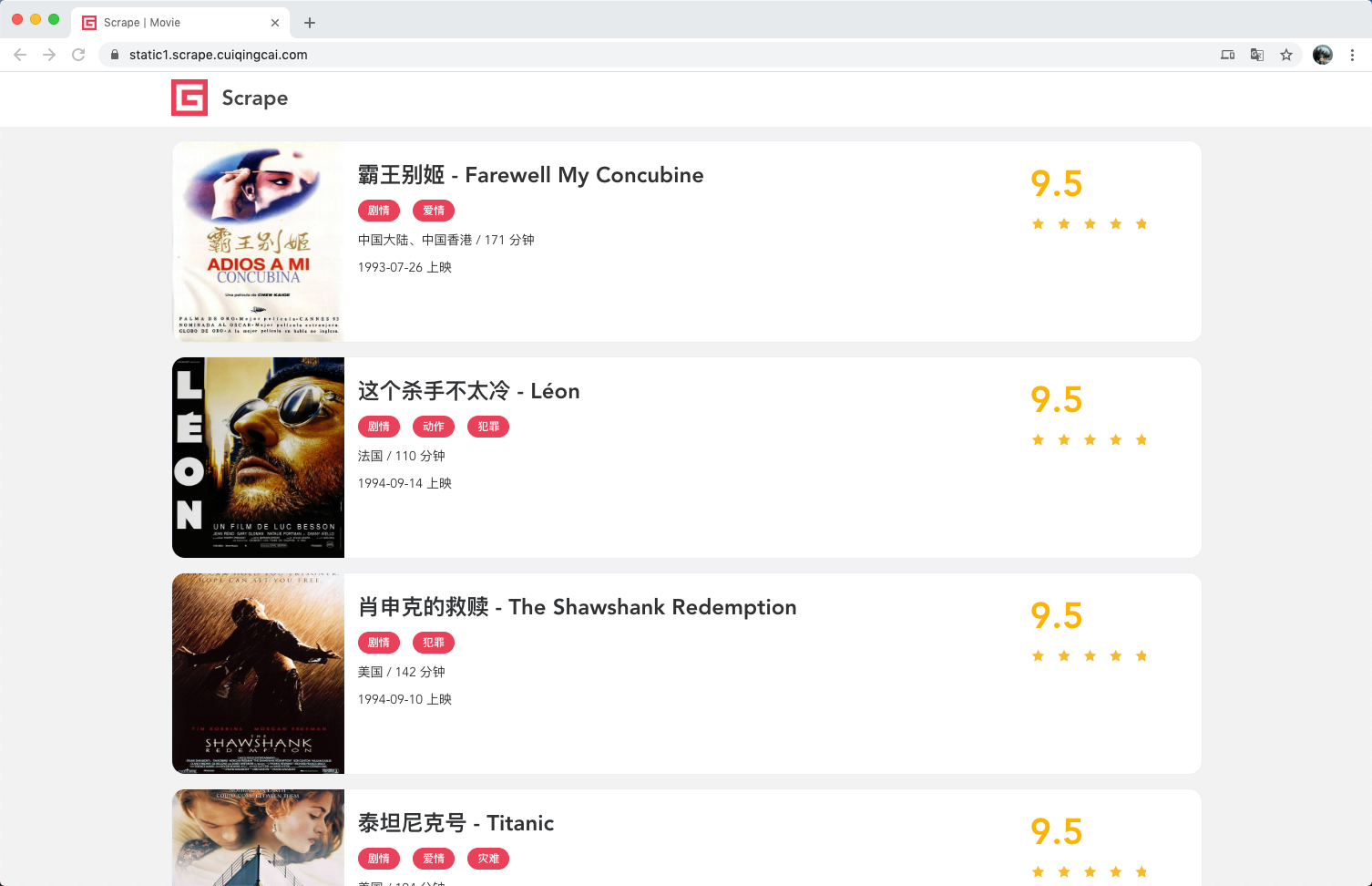
首页是一个影片列表,每栏里都包含了这部电影的封面、名称、分类、上映时间、评分等内容
同时列表页还支持翻页,点击相应的页码我们就能进入到对应的新列表页
如果我们点开其中一部电影,会进入电影的详情页面
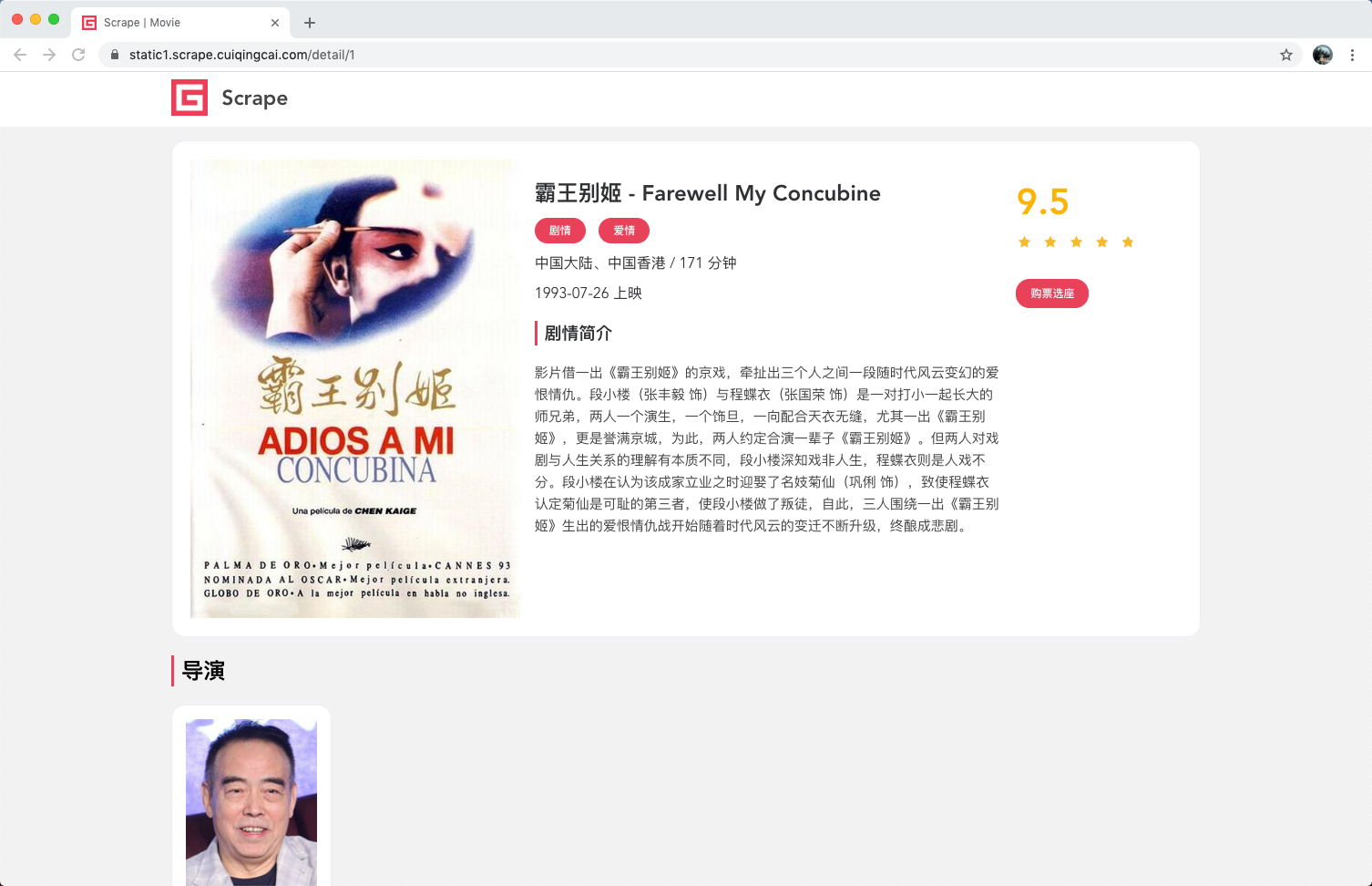
这里显示的内容更加丰富,包括剧情简介、导演、演员等信息
我们要完成的目标是
- 用requests爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页
- 用pyquery和正则表达式提取每部电影的名称、封面、类别、上映时间、评分、剧情简介等内容
- 将爬取的内容存入MongoDB数据库
- 使用多进程实现爬取的加速
爬取列表页
爬取的第一步肯定要从列表页入手,我们首先观察一下列表页的结构和翻页规则,打开浏览器开发者工具,观察每一个电影信息区对应的HTML,以及进入到详情页的URL是怎样的
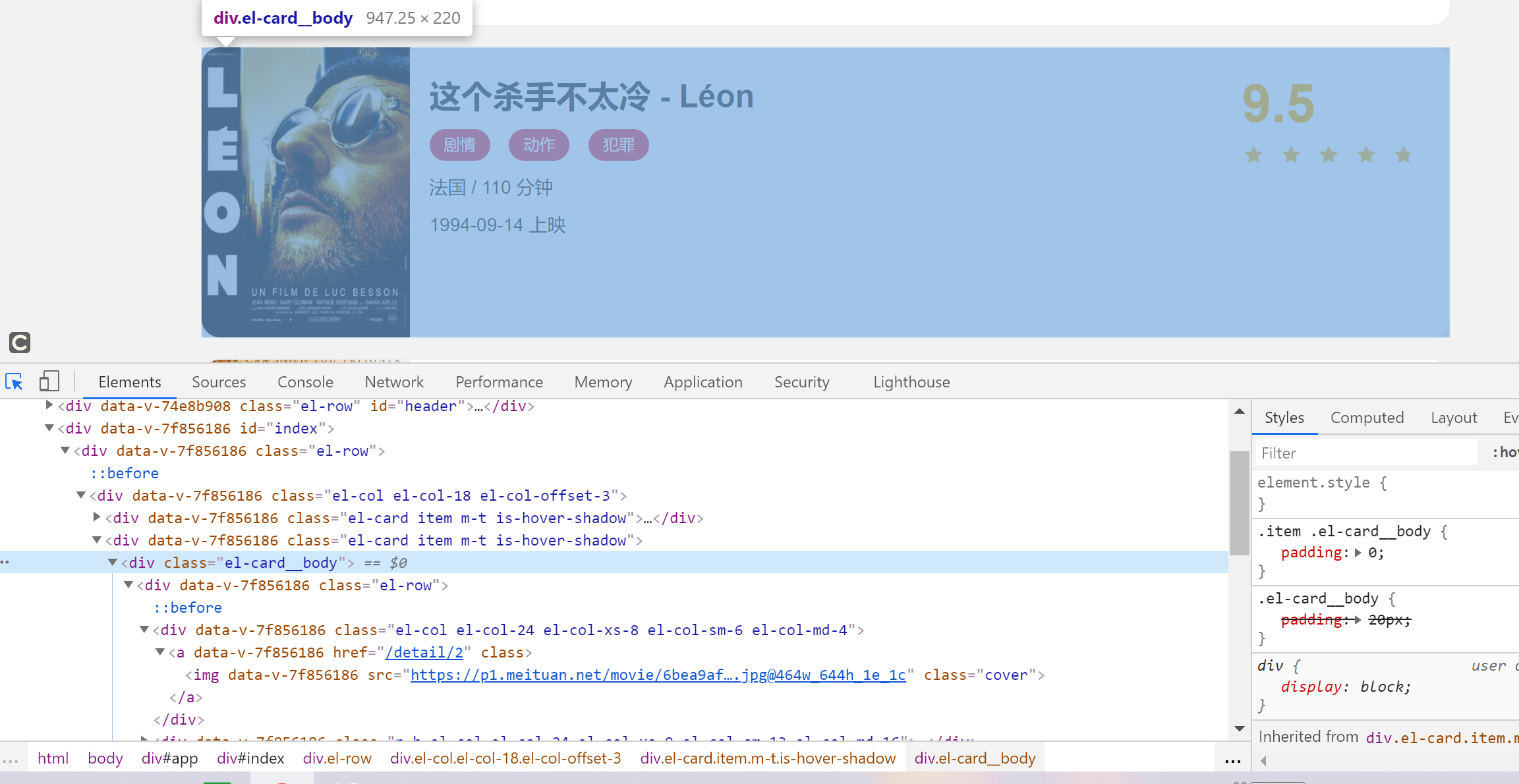
每部电影对应的区块都是一个div节点,它的class属性都有el-card这个值
每个列表页有10个这样的div节点,也就对应着10部电影的信息
我们再来看从列表页是怎么进入到详情页的,选中电影的名称
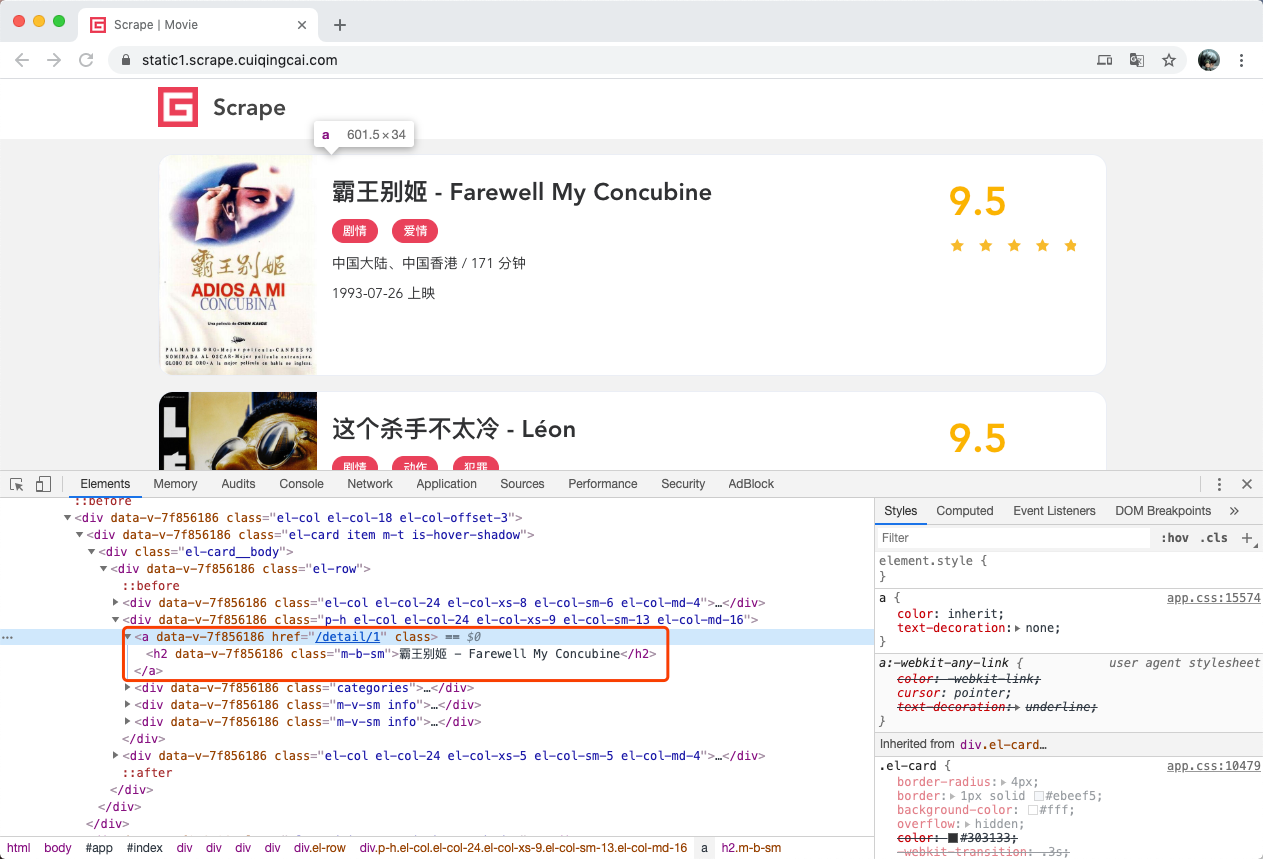
这个名称实际上是一个h2节点,其内部的文字就是电影的标题
h2节点的外面包含了一个a节点,这个a节点带有href属性,这就是一个超链接
其中href的值为/detail/2 ,这是一个相对网站的根URL路径
加上网站的根URL就能构成https://static1.scrape.center/detail/2,也就是电影详情页的URL。
这样我们只需要提取这个href属性就能构造出详情页的URL并接着爬取了
接下来分析下翻页的逻辑,页面最下方,可以看到分页页码
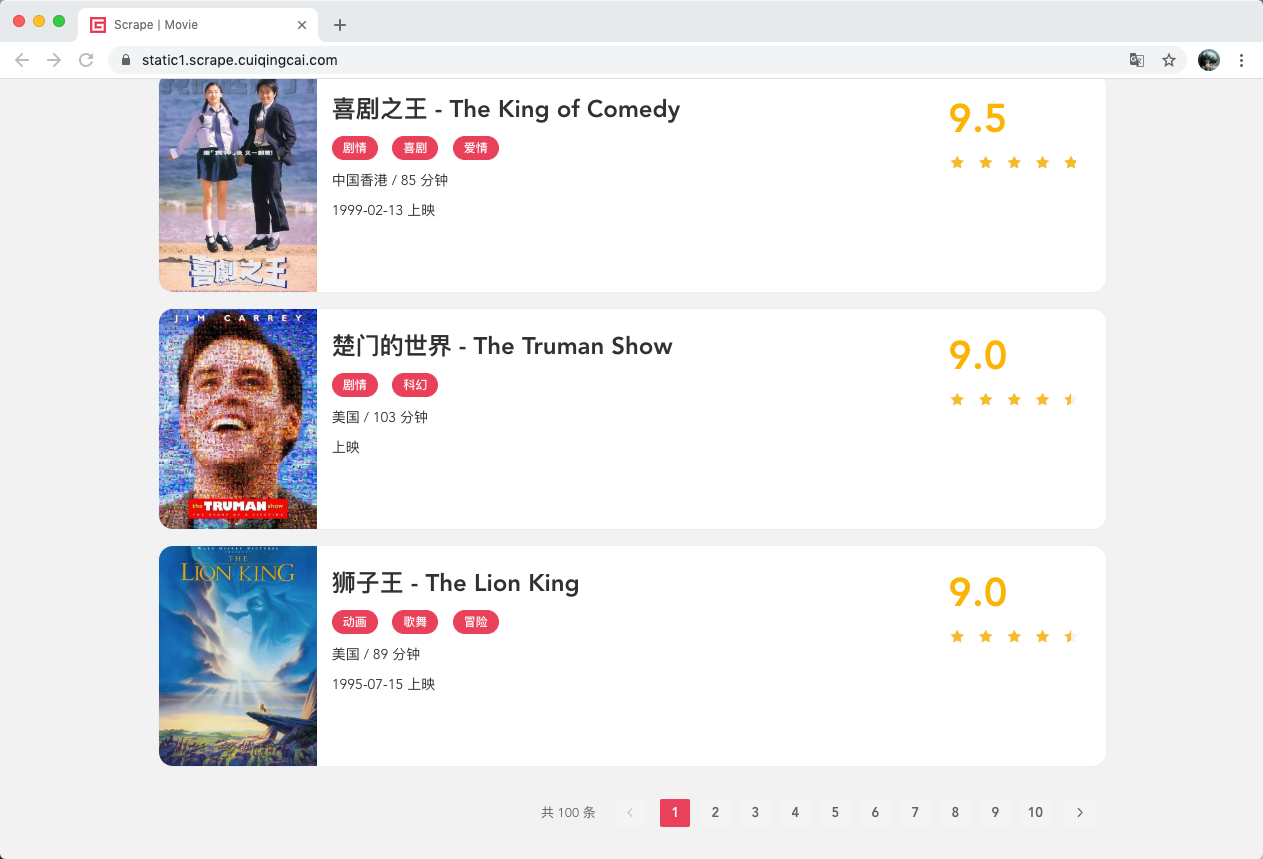
页面显示一共有100条数据,10页的内容,因此页码最多也是10
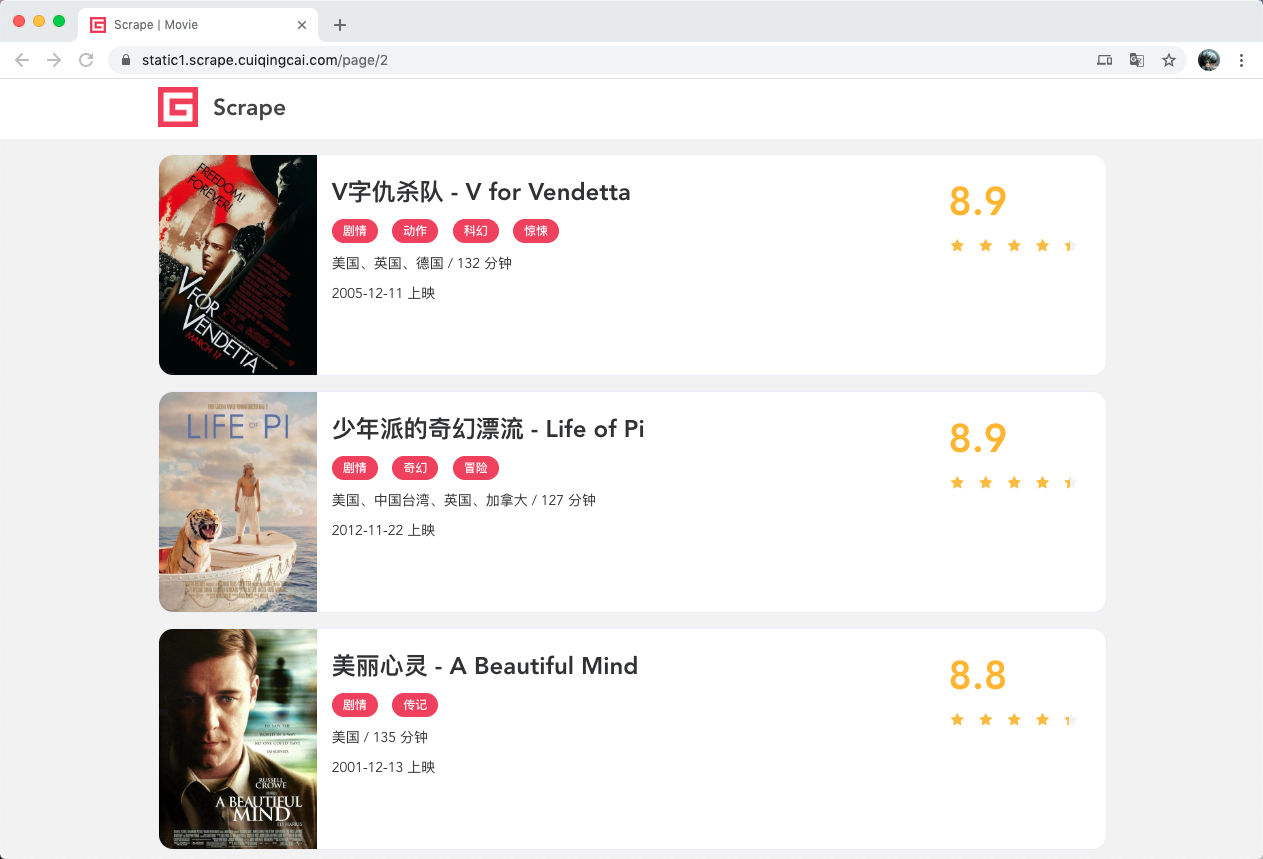
点击第二页,可以看到网页的URL变成了https://static1.scrape.center/page/2,相比根URL多了/page/2这部分内容
网页的结构还是和原来一模一样,所以我们可以和第一页一样处理
查看第三页、第四页等内容,可以发现有一个规律,每一页的URL最后分别变成了/page/3、/page/4
所以, /page后面跟的就是列表页的页面,第一页也是一样,只不过网站做了处理,默认的页面是1,所以https://static1.scrape.center显示第一页的内容
我们要完成列表页的爬取
- 遍历页码构造10页的索引页
- 从每个索引页分析提取出每个电影的详情页URL
首先我们定义一些基础的变量,并引入一些必要的库
import requests # 用来爬取页面
import logging # 用来输出信息
import re # 用来实现正则表达式解析
import pymongo # 用来实现MongoDB存储
from pyquery import PyQuery as pq # 用来直接解析网页
from urllib.parse import urljoin # 用来做URL的拼接
# 定义日志输出级别和输出格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levename)s: %(message)s')
# 定义当前站的根URL
BASE_URL = 'https://static1.scrape.center/'
# 需要爬取的总页码数量
TOTAL_PAGE = 10
定义好之后,我们来实现一个页面爬取的方法
def scrape_page(url):
logging.info('scraping %s...',url)
try:
response = requests.get(url,verify=False)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s',response.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
考虑到我们不仅要爬取列表页,还要爬取详情页
所以我们定义一个较通用的爬取页面的方法——scrape_page,它接受一个url参数,返回页面的html代码
-
我们首先判断状态码是不是200,如果是,则直接返回页面的HTML代码,如果不是,则会输出错误日志信息
-
同时这里实现了requests的异常处理,如果出现了爬取异常,则会输出对应的错误日志信息
-
我们将logging的error方法的exc_info参数设置为True则可以打印出Traceback错误堆栈信息
有了scrape_page方法后,我们给这个方法传入一个url,正常情况下它就可以返回页面的HTML代码了
在这个基础上,我们来定义列表页的爬取方法
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}'
return scrape_page(index_url)
这个方法会接受一个page参数,即列表页的页码
在这个方法里面实现列表页的URL拼接,然后调用scrape_page方法爬取即可得到列表页的HTML代码了
获取了HTML代码后,下一步就是解析列表页,并得到每部电影的详情页的URL
def parse_index(html):
doc = pq(html)
links = doc('.el-card .name')
for link in links.items():
href = link.attr('href')
detail_url = urljoin(BASE_URL,href)
logging.info('get detail url %s',detail_url)
yield detail_url
-
parse_index方法,它接收一个html参数,即列表页的HTML代码
-
接着用pyquery新建一个PyQuery对象
-
再用 .el-card .name选择器选出来每个电影名称对应的超链接节点
-
遍历这些节点(每页有10个),通过调用attr方法并传入href获得详情页的URL路径,得到的href就是类似 /detail/1这样的结果
-
由于这并不是一个完整的URL,所以我们需要借助urljoin方法把BASE_URL 和 href 拼接起来,获得详情页的完整URL,
-
得到的结果就是类似https://static1.scrape.center/detail/1 这样完整的URL 最后yield返回
这样通过调用parse_index方法传入列表页的HTML代码就可以获得该列表页所有电影的详情页URL了
我们把上面的方法串联调用一下
def main():
for page in range(1,TOTAL_PAGE +1): //从1开始到11,不包括11
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
logging.info('detail urls %s',list(detail_urls))
if __name__ == '__main__':
main()
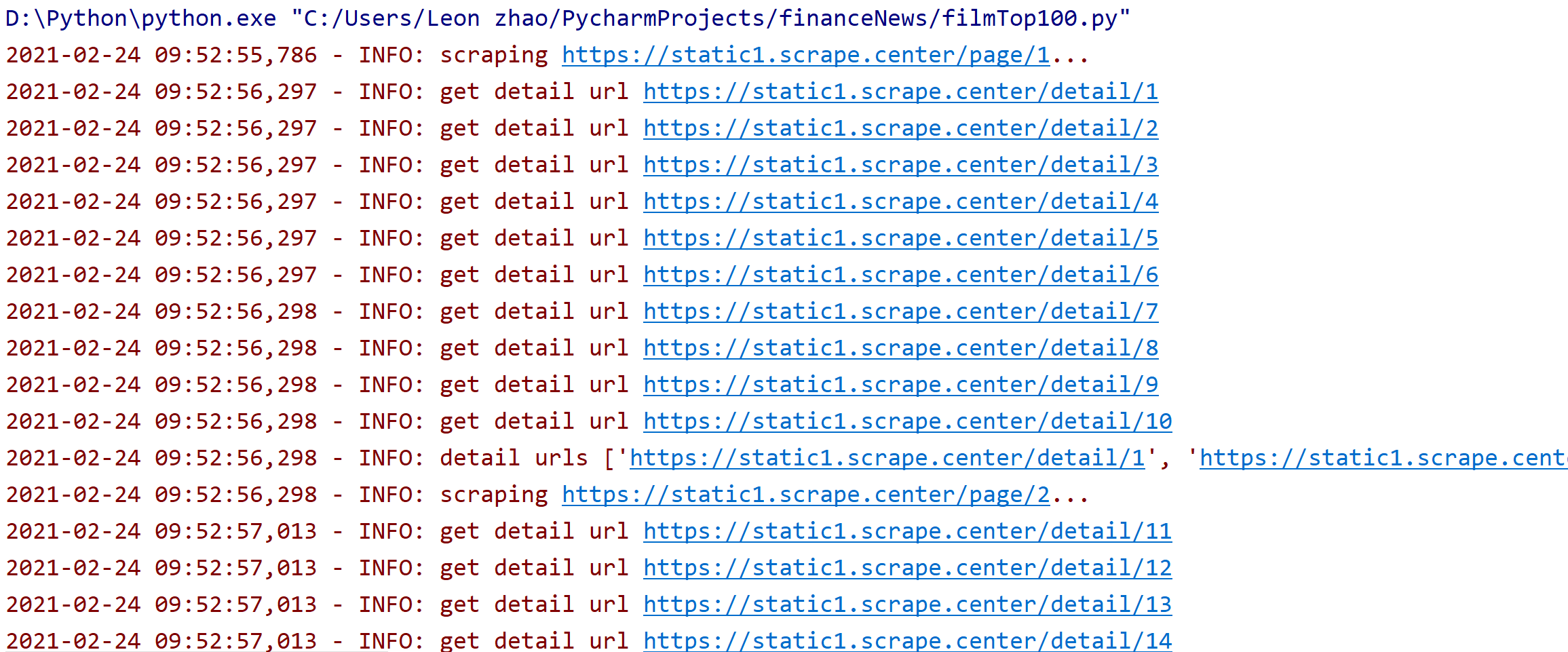
在这个过程中程序首先爬取了第1页列表页,然后得到了对应详情页的每个URL
接着爬取第2页、第3页,一直到第10页,依次输出了每一页的详情页URL
这样我们就成功获取到所有电影详情页URL了
爬取详情页
下一步就是解析详情页并提取出我们想要的信息了
首先看一下详情页的HTML代码
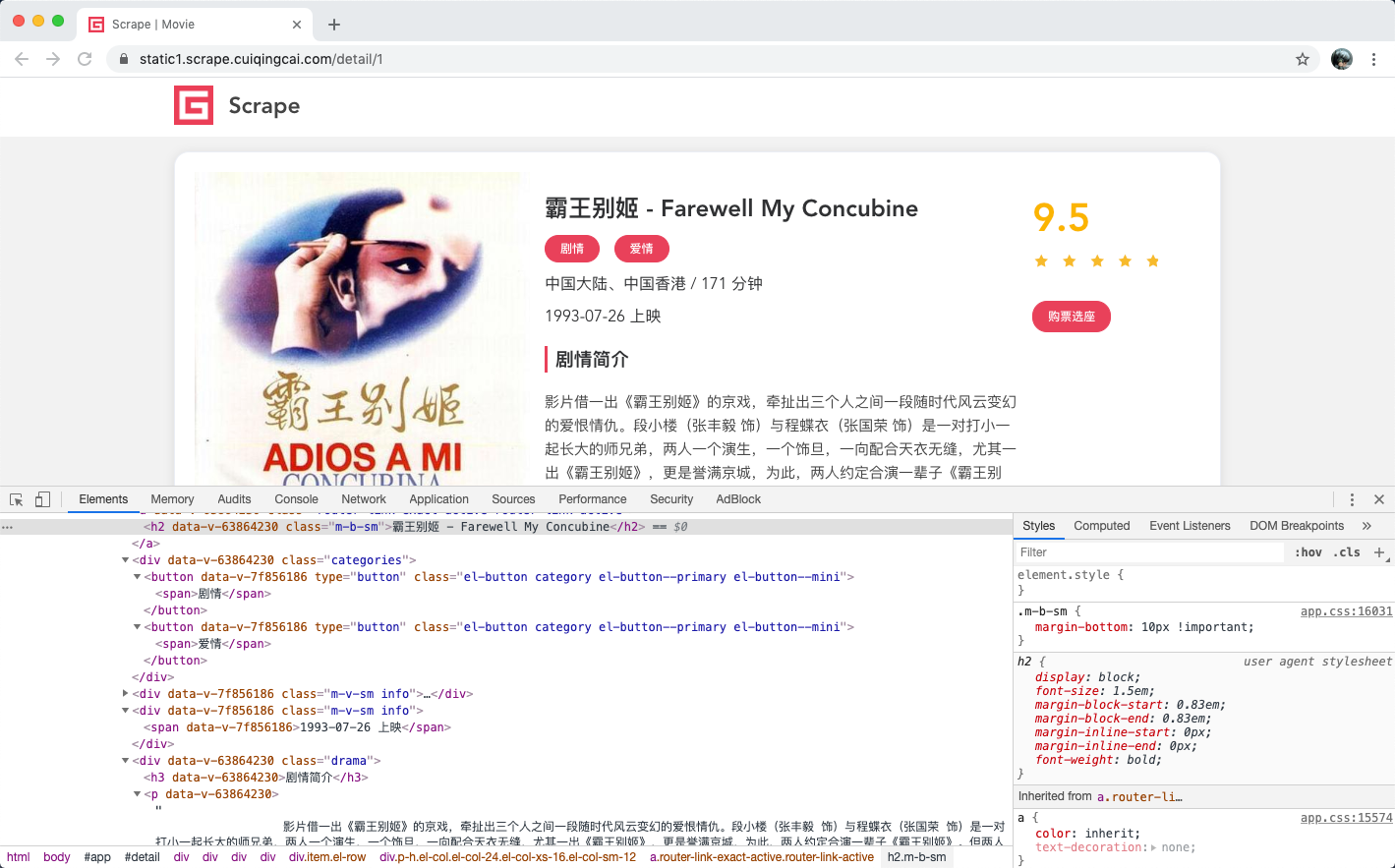
经过分析,我们想要提取的内容和对应的节点信息如下
-
封面: 是一个img节点,其class属性为cover
-
名称: 是一个h2节点,其内容便是名称
-
类别:是span节点,其内容便是类别内容,其外侧是button节点,再外侧是class为categories的div节点
-
上映时间:是span节点,其内容包含了上映时间,其外侧是包含了class为info的div节点
但注意,这个div前面还有一个class为info的div节点
我们可以使用其内容来区分,也可以使用nth-child 或 nth-of-type这样的选择器来区分
另外提取结果中还多了[上映]二字,可以用正则表达式把日期提取出来
-
评分:是一个p节点,其内容便是评分,p节点的class属性为score
-
剧情简介:是一个p节点,其内容便是剧情简介,其外侧是class为drama的div节点
看上去有些复杂,但是有pyquery和正则表达式,我们可以轻松搞定
刚才我们成功获取了详情页的URL,接下来我们要定义一个详情页的爬取方法
def scrape_detail(url):
return scrape_page(url)
scrape_detail方法,它接收一个url参数,并通过调用scrape_page方法获得网页源代码
由于我们刚才已经实现了scrape_page方法,所以在这里我们不再写一遍页面爬取的逻辑了,直接调用即可,这就做到了代码复用
你可能会问,这个scrape_detail方法里面只调用了scrape_page方法,没有别的功能,那爬取详情页直接用scrape_page方法不就好了?还有必要再单独定义scrape_detail方法吗?
- 有必要,单独定义个scrape_detail方法在逻辑上会显得更清晰,而且以后如果我们想要对scrape_detail方法进行改动
- 比如添加日志输出或是增加预处理,都可以在scrape_detail里面实现,而不用改动scrape_page方法,灵活性会更好
详情页的爬取方法已经实现,接着就是详情页的解析
parse_detail方法用于解析详情页,它接收一个html参数,解析其中的内容,并以字典的形式返回结果。每个字段的解析情况如下
def parse_detail(html):
doc = pq(html)
cover = doc('img.cover').attr('src')
# cover:封面,直接选取class为cover的img节点,并调用attr方法获取src属性的内容即可
name = doc('a >h2').text()
# name:名称,直接选取a节点的直接子节点h2节点,并调用text方法提取其文本内容即可得到名称
categories = [item.text() for item in doc('.categories button span').items()]
# categories:类别,由于类别是多个,所以首先用.categories button span选取了class为 categories的节点内部的span节点,其结果是多个,所以这里进行了遍历
published_at = doc('.info:contains(上映)').text()
published_at = re.search('(\d{4}-\d{2}\-\d{2})',p ublished_at).group(1) \
if published_at and re.search('(\d{4}-\d{2}\-\d{2})',published_at) else None
# published_at,上映时间,由于pyquery支持使用:contains直接指定包含的文本内容并进行提取,且每个上映时间信息都包含了[上映]二字,所以我们这里直接使用:contains(上映)提取了class为info的div节点
# 提取之后,得到的结果类似[1993-07-26 上映],但我们并不想要[上映]这两个字,所以我们又调用了正则表达式把日期单独提取出来了。
# 这里也可以直接使用strip或replace方法把多余的文字去掉,但我们为了联系正则表达式的用法,使用了正则表达式来提取
drama = doc('.drama p').text()
# drama 直接提取class为drama的节点内部的p节点的文本
score = doc('p.score').text()
score = float(score) if score else None
# score 直接提取class为score的p节点的文本,但由于提取结果是字符串,我们需要把它转成浮点数,即float类型
return {
'cover':cover,
'name':name,
'categories':categories,
'published_at': published_at,
'drama':drama,
'score':score
}
# 字段提取完毕之后,构造一个字段返回即可
最后,我们将main方法稍微改写一下,增加这两个方法的调用
def main():
for page in range(1,TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s',data)
遍历了detail_urls ,获取了每个详情页的URL
然后依次调用了scrape_detail和parse_detail方法,最后得到了每个详情页的提取结果,赋值为data并输出
2021-02-24 16:25:04,665 - INFO: scraping https://static1.scrape.center/page/1...
2021-02-24 16:25:05,011 - INFO: get detail url https://static1.scrape.center/detail/1
2021-02-24 16:25:05,011 - INFO: scraping https://static1.scrape.center/detail/1...
2021-02-24 16:25:05,687 - INFO: get detail data {'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'name': '霸王别姬 - Farewell My Concubine', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'drama': '影片借一出《霸王别姬》的京戏,牵扯出三个人之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅 饰)与程蝶衣(张国荣 饰)是一对打小一起长大的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐 饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。', 'score': 9.5}
2021-02-24 16:25:05,687 - INFO: get detail url https://static1.scrape.center/detail/2
2021-02-24 16:25:05,687 - INFO: scraping https://static1.scrape.center/detail/2...
2021-02-24 16:25:06,213 - INFO: get detail data {'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c', 'name': '这个杀手不太冷 - Léon', 'categories': ['剧情', '动作', '犯罪'], 'published_at': '1994-09-14', 'drama': '里昂(让·雷诺 饰)是名孤独的职业杀手,受人雇佣。一天,邻居家小姑娘马蒂尔德(纳塔丽·波特曼 饰)敲开他的房门,要求在他那里暂避杀身之祸。原来邻居家的主人是警方缉毒组的眼线,只因贪污了一小包毒品而遭恶警(加里·奥德曼 饰)杀害全家的惩罚。马蒂尔德 得到里昂的留救,幸免于难,并留在里昂那里。里昂教小女孩使枪,她教里昂法文,两人关系日趋亲密,相处融洽。 女孩想着去报仇,反倒被抓,里昂及时赶到,将女孩救回。混杂着哀怨情仇的正邪之战渐次升级,更大的冲突在所难免……', 'score': 9.5}
2021-02-24 16:25:06,213 - INFO: get detail url https://static1.scrape.center/detail/3
2021-02-24 16:25:06,213 - INFO: scraping https://static1.scrape.center/detail/3...
2021-02-24 16:25:06,666 - INFO: get detail data {'cover': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c', 'name': '肖申克的救赎 - The Shawshank Redemption', 'categories': ['剧情', '犯罪'], 'published_at': '1994-09-10', 'drama': '20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……', 'score': 9.5}
可以看到,我们已经成功提取出每部电影的基本信息(封面、名称、类别…)
保存到MongoDB
成功提取到详情页信息之后,下一步我们就要把数据保存起来了
请确保现在有一个可以正常连接和使用的MongoDB数据库
定义MongoDB的连接配置
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'movies'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movies']
collection = db['movies']
我们声明了几个变量
- MONGO_CONNECTION_STRING : MongDB的连接字符串,里面定义了MongoDB的基本连接信息,如host、port,还可以定义用户名密码等内容
- MONGO_DB_NAME:MongoDB数据库的名称
- MONGO_COLLECTION_NAME:MongoDB的集合名称
我们用MongoClient声明了一个连接对象,然后依次声明了存储的数据库和集合
接下来实现将数据保存到MongoDB的方法
def save_data(data):
collection.update_one({
'name':data.get('name')
},
{
'$set':data
},upsert=True)
sava_data方法,它接受一个data参数,也就是我们提取的电影详情信息
我们调用updata_one方法
-
第1个参数是查询条件,即根据name进行查询;
-
第2个参数是data对象本身,也就是所有的数据
我们用$set操作符表示更新操作
-
第3个参数很关键,upsert参数,如果设置为True,则可以做到存在即更新,不存在即插入的功能
更新会根据第一个参数设置的name字段,所以这样可以防止数据库中出现同名的电影数据
实际上电影可能有同名,但该场景下的爬取数据没有同名情况,当然这里更重要的是实现MongoDB的去重操作
我们将main方法稍微改写下,增加了save_data方法的调用,并加了一些日志信息
def main():
for page in range(1,TOTAL_PAGE +1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s',data)
logging.info('saving data to mongodb')
save_data(data)
logging.info('data saved successfully')
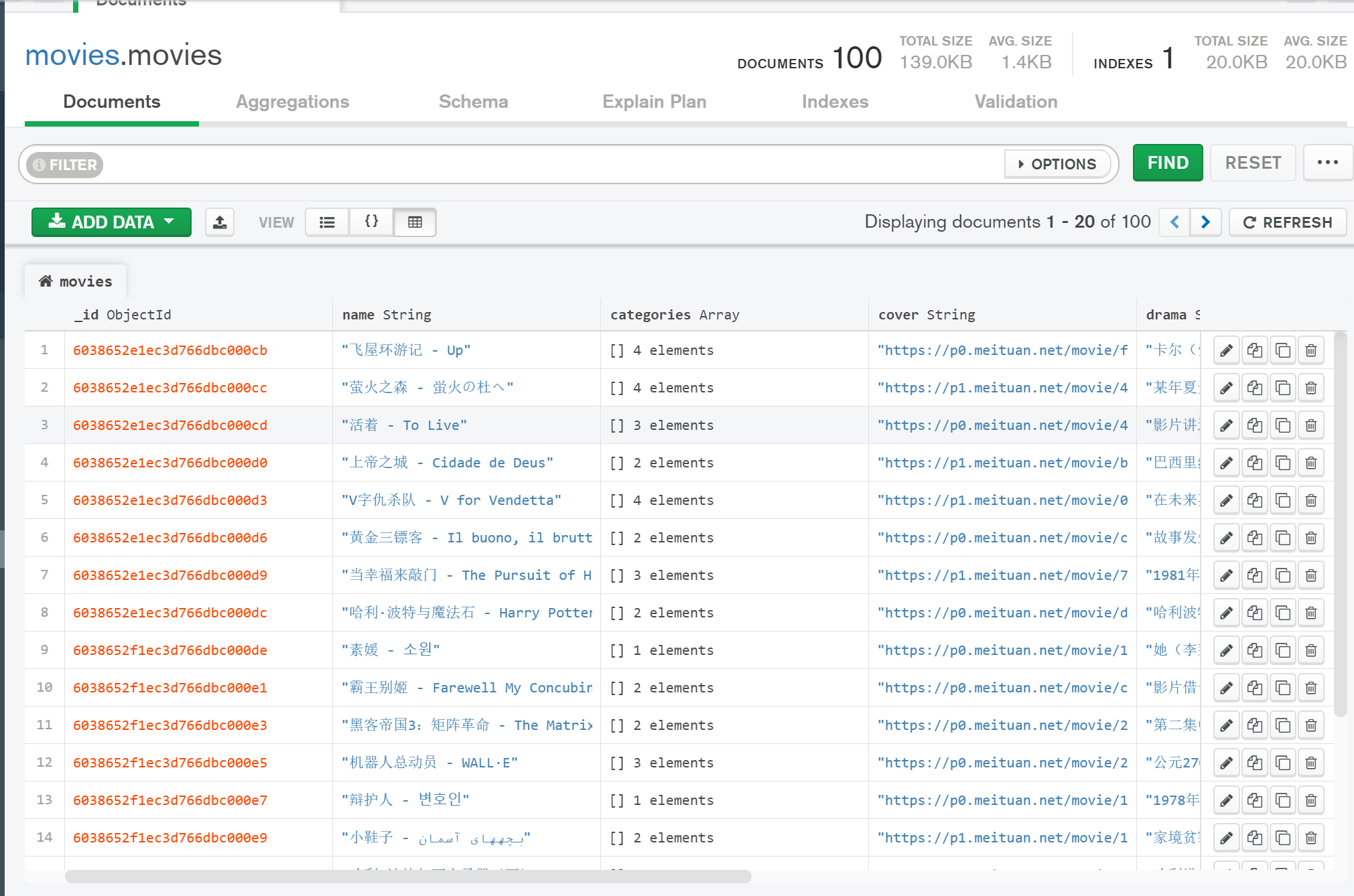
运行完毕之后我们可以使用MongoDB客户端工具(MongoDBCompass)可视化地查看已经爬取到的数据
多进程加速
-
由于整个的爬取是单进程的,而且只能逐条爬取,速度稍微有些慢,我们来实践下多进程的爬取
-
由于一共有10页详情页,并且这10页内容是互不干扰的
所以我们可以一页一个进程来爬取
-
由于这10个列表页页码正好可以提前构成一个列表
所以我们可以选用多进程里面的进程池Pool来实现这个过程
我们改写下main方法的调用
import multiprocessing
def main(page):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
logging.info('saving data to mongodb')
save_data(data)
logging.info('data saved successfully')
if __name__ == '__main__':
pool = multiprocessing.Pool()
pages = range(1,TOTAL_PAGE + 1)
pool.map(main,pages)
pool.close()
pool.join()
-
我们首先给main方法添加一个参数page,用以表示列表页的页码
-
接着声明了一个进程池,并声明pages为所有需要遍历的页码,即1~10
-
最后调用map方法
第1个参数就是需要被调用的方法
第2个参数就是pages,即需要遍历的页码
这样pages就会被依次遍历。把1~10这10个页码分别传递给main方法
并把每次的调用变成一个进程,加入到进程池中执行,进程池会根据当前运行环境来决定运行多少进程
- 比如我的机器的CPU有8个核,那么进程池的大小就会默认设定8,同时有8个进程并行执行
我们清空一下之前的MongoDB数据,输出结果和之前类似,但是爬取速度快了很多
总结
我们完成了全站电影数据的爬取并实现了存储和优化
我们用到的库有requests、pyquery、PyMongo、multiprocessing、re、logging…

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









