






迭代法
LDU分解
概念:假定我们能把矩阵A写成下列两个矩阵相乘的形式:A=LU,其中L为下三角矩阵,U为上三角矩阵。这样我们可以把线性方程组Ax= b写成
Ax= (LU)x = L(Ux) = b。令Ux = y,则原线性方程组Ax = b可首先求解向量y 使Ly = b,然后求解 Ux = y,从而达到求解线性方程组Ax= b的目的。
LU分解的基本思想
将系数矩阵A转变成等价的两个矩阵L和U的乘积,其中L和U分别是下三角和上三角矩阵,而且要求L的对角元素都是1;
由LU = A及对L和U的要求可以得到分解的计算公式。根据下式(独立特尔Doolittle分解):

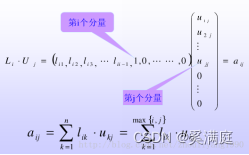


在计算机程序中常常用到这种方法解线性代数方程组。它的优点是存储量很省。L和U中的三角零元素都不必存储,这样只用一个n阶仿真就可以把L和U存储起来。
即:下三角存储L各元素而上三角存储U的元素。
再考察公式S会发现A中任一元素aij只在计算lij(j<=i)和uij(u>=j)中用到一次,以后就不再出现了,因为完全可以利用原始数据A的单元,一个个逐次存储L或U中
的相应元素,即:
当系数矩阵A完成了LU分解后,方程组Ax = b就可以化为L(Ux) = b,等价于求解两个方程组Ly = b和Ux = y;
具体计算公式为
采用LU分解有如下特点:
(1)LU分解与右端向量无关。先分解,后回代,分解的运算次数正比于n^3,回代求解正比于n^2。遇到多次回代时,分解的工作不必重新做,这样节省计算时间。
(2)分解按步进行,前边分解得到的信息为后边所用。
(3)【A】矩阵的存储空间可利用,节省存储
Jacobi迭代法

代码
import numpy as np
def Astringency(mx):
L, D, U = [], [], []
for i in range(len(mx)):
L.append([]), D.append([]), U.append([])
for j in range(len(mx)):
if i > j:
L[i].append(mx[i][j]), D[i].append(0), U[i].append(0)
if i == j:
L[i].append(0), D[i].append(mx[i][j]), U[i].append(0)
if i < j:
L[i].append(0), D[i].append(0), U[i].append(mx[i][j])
print(L)
print(D)
print(U)
ld = L
for i in range(len(mx)):
for k in range(len(mx)):
ld[i][k] = L[i][k] + D[i][k]
print(ld)
print(-np.linalg.inv(ld))
print(D)
G = np.dot(-np.linalg.inv(ld), U)
print(G)
e, v = np.linalg.eig(G)
print(e)
for i in range(len(e)):
count = 0
if abs(e[i]) < 1:
continue
else:
count = count + 1
print(abs(e[i]))
if count == 0:
return True
else:
print("迭代法不收敛")
return False
def Gauss_seidel(mx, mr, n=10, e=0.0001):
if len(mx) == len(mr):
if Astringency(mx) == 1:
x = []
for i in range(len(mr)):
x.append([0])
count = 0
while count < n:
tempx = np.copy(x)
for i in range(len(x)):
ri = mr[i]
for k in range(len(mx[i])):
if k != i:
ri = ri - mx[i][k] * x[k][0]
ri = ri / mx[i][i]
x[i][0] = ri
print("第{}次迭代的值为:{}".format(count + 1, x))
ee = []
for i in range(len(x)):
ee.append(abs(x[i][0] - tempx[i][0]))
em = max(ee)
print("第{}、{}次迭代间误差值为:{}".format(count, count + 1, em))
if em < e:
return x
count += 1
return False
else:
print("使用迭代法不收敛")
else:
print("此方程无解")
mx= np.loadtxt('D:/1.txt',delimiter=',')
mr= np.loadtxt('D:/2.txt',delimiter=',')
print(Gauss_seidel(mx, mr, 10, 0.0001))




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











