







如何爬取豆瓣评分前250部的电影,我们可以使用Python来快速的实现,爬取其实就是发起网络请求,而利用程序发起可以更加方便快捷,不用频繁地进行点击,只需要我们把要爬取的数据之间相同的规律总结处理,利用这个规律解析出数据即可。
爬取的网站地址:
https://movie.douban.com/top250?start=0&filter=
进入网页后右键选择检查页面
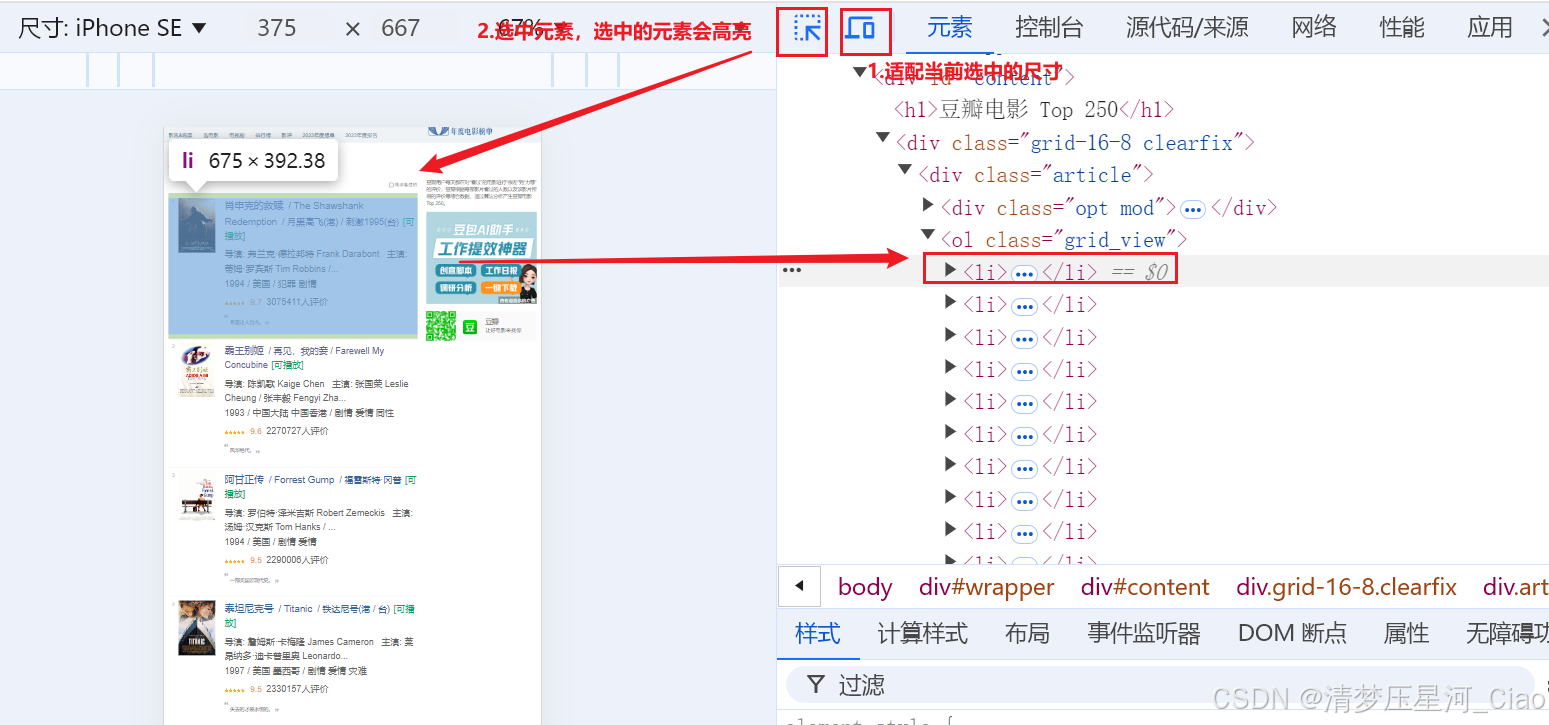
通过上面的方法定位电影,能看出每部电影都在一个<li>标签中,而这些<li>标签都在一个class_='grid_view'的标签中,所以只需要遍历出250个<li>标签并且将的<li>标签中我们想要的元素提取出来即可。
下面通过代码来进行详细讲解:
若导入包失败,请先通过pip install xxx安装
import requests
from bs4 import BeautifulSoup
import xlwt
def request_douban(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.146 Safari/537.36',
}
try:
# 使用get请求获取数据,加上请求头伪装成浏览器发起的请求尽量避免被网站反爬机制识别
response = requests.get(url=url, headers=headers)
# 当请求响应码为200表示请求成功,返回请求页面文本
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
# 创建excel工作本
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
# 创建工作表及标题行</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









