






1、 引例
如何正确地写出我们所期望的东西?编程已然是一种尽最大努力满足我们需求的方法,像编写算法来正确求解我们的问题,Specification也是一样的思想。只不过Specification不专注于如何做,而在于表达我们的需求到底是什么,为了证明我们的代码实现了我们所需要的功能,我们必须要能准确描述我们所需要的性质、状态等等。
例如,我们有一个max函数,他是返回两个数中的较大值,同样给出了后置条件。
/*@
ensures \result >= a && \result >= b;
*/
int max(int a, int b){
return (a > b) ? a : b;
}
void foo(){
int a = 42;
int b = 37;
int c = max(a,b);
// assert c == 42;
}单独对max进行WP证明,发现没有问题,但一旦对foo中的assert进行验证,发现证明失败,事实上这是因为这个后置条件太过宽松,如果将max的return值改为INT_MAX,同样可以通过WP证明,所以,我们不仅期望结果大于或等于两个参数,而且期望结果是它们中的一个,增加后置条件后,就可以证明foo中的assert了。可以体会一下well specified function的这种感觉。
2、不一致的前提条件
有以下的一个例子:
/*@
requires a < 0 && a > 0;
ensures \false;
*/
void foo(int a ){}如果对这个函数进行WP证明,结果显然是proved,因为前提条件为假。为检查这种问题,WP插件中有一个烟雾测试,用来检查前提条件是否不满足,命令行如下:
frama-c-gui -wp -wp-smoke-test 1.c
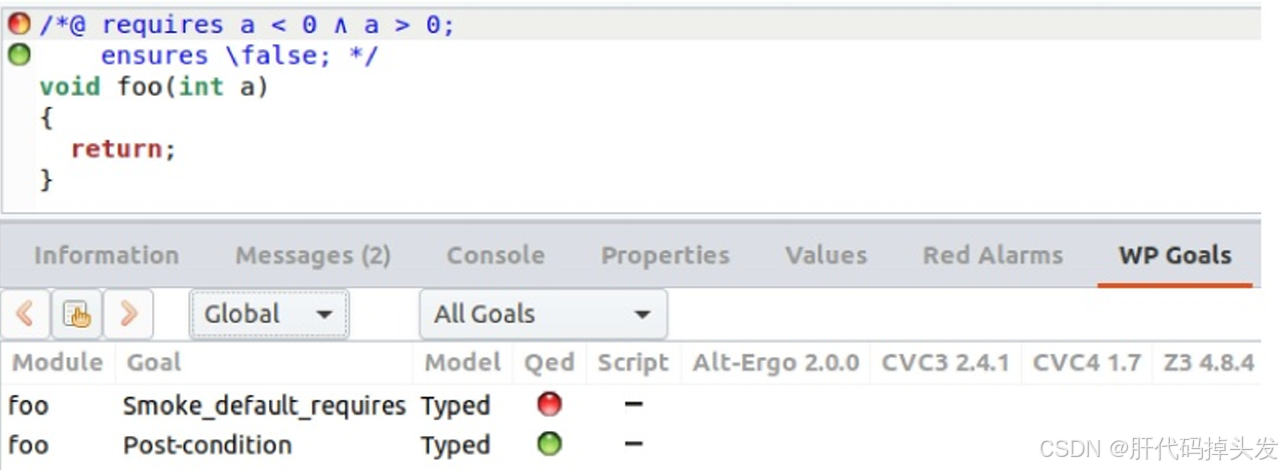
我们会发现一个红橙参半的圆圈,表示如果有这个函数被调用,那么他的前提条件必被违反,在WP Goals里Qed也证明其为假。
3、指针
C语言的Bug大户,故需要慎重对待,用swap函数来举例。
/*@
ensures *a == \old(*b) && *b == \old(*a);
*/
void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}\old:ACSL的内置函数(谓词?),只在ensures里使用,它允许我们获得给定元素的旧值(在执行函数前)。如果我们在其他地方需要这种特定点的值,使用\at。
\at:往往与Label一起使用,可见下例。它允许我们表达我们想要一个变量在特定程序点的值。这个函数接收两个参数。第一个是我们想要获取其值的变量(或内存位置),第二个是我们想要考虑的程序点(作为C标签)。
void foo(){
int a = 42;
Label_a:
a = 45;
//@ assert a == 45 && \at(Label_a, a) == 42;
}请注意,这个Label是往上的范围,这个冒号很容易误导认为接下来的内容是程序点,实则看assert内容可以发现,Label_a:指的是上面一条语句a = 42的程序点。
还有一些内置标签(区分于前面的\old内置函数等):
Pre/Old:函数调用前的值,old仅在后置中用,pre随处可用
Post:函数调用后的值
LoopEntry:在循环入口的值
LoopCurrent:当前循环的值
Here:当前程序点的值
示例:
/*@ requires x + 2 != p; */
void foo(int *x, int *p){
*p = 2;
//@assert x[2] == \at(x[2],Pre);
//@assert x[*p] == \at(x[*p],Pre);
}尽管这两条assert想表达的语义似乎相同,但他们大相径庭并且第二条是肯定错误的。原因在于只是简单的将\at(x[*p],Pre)理解成了x在Pre点的值,而没有考虑*p在Pre点的值,真正理解应该是\at(x[\at(*p),Pre](相当于\at是一个全称量词,作用域必须是整个表达式),而在Pre点,*p的值未被定义,故肯定证明失败。
指针还有一个老生常谈的bug,空指针或使用前未定义。相应的,ACSL提供了\valid谓词,一般会在前置条件中使用,确保函数接收到的指针是有效的。
/*@ requires \valid(a) && \valid(b)*/
void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
} 同样地,valid可接受多个指针来解决数组的问题,\valid(p + (s .. e)),这意味着对于,p+i是一个有效的指针。
ACSL中有个更加宽松的\valide_read,这代表指针是可以被引用的,但引用它只能用于读操作,而不能写,例如。
/*@ requires \valid(p); */
int unref(int *p){
return *p;
}
int const value = 42;
int main(){
int i = unref(&value);
}这个unref通不过WP的证明,因为unref只对读操作是合法的,所以需要改成\valid_read(p)。
通过以上的举措,我们是否得到了一个well specified的function呢?并非如此,可以看下面这个例子(懒得敲了直接截了...出处来自于frama-c-wp-tutorial-en这本教材):

这是由于函数的副作用引起的,默认情况下,WP认为函数可以修改内存中的所有内容,所以我们应该要有一个指令来指定函数可以修改什么,assigns指令,后接要修改的变量名,如果没有需要修改的,就接\nothing。
/*@ assigns *a, *b; */ /*@ assigns \nothing; */
那指针还有问题吗?当然,还有一堆...再考虑下面这个问题:

看源代码似乎没有什么问题,但WP证明失败,这是因为我们没有考虑*a, *b是否为指向的是同一块内存区域(这两指针可能是相同的),若相同,第一条ensures只在*a=0时成立,第二条甚至都违反了\valid_read。所以需要引入\separated(p1,...,pn),来确保指针指向内存是不同的。
/*@ requires \separated(a, b); */ 注意拼写,我以为是seperated...找了半天bug...
以上,我们就先介绍到这里,显然我们可能还要考虑数据范围,数据溢出等问题,本节先不做关注。
4、小总结
检查规范是否足够精确的一个好方法就是测试,事实上,这基本上就是我们对例子max和swap所做的。我们已经写了规范的第一个版本,通过这些代码,调用相应的函数来验证是否可以证明一些期望从函数合约中的容易证明的属性。最重要的思想是在不考虑函数内容的情况下确定契约(至少在第一步中是这样),如果我们写的合约太直接地考虑了它的代码,我们就有引入同样bug的风险(Overfitting的感觉),比如考虑了一个错误的条件结构。
5、练习题
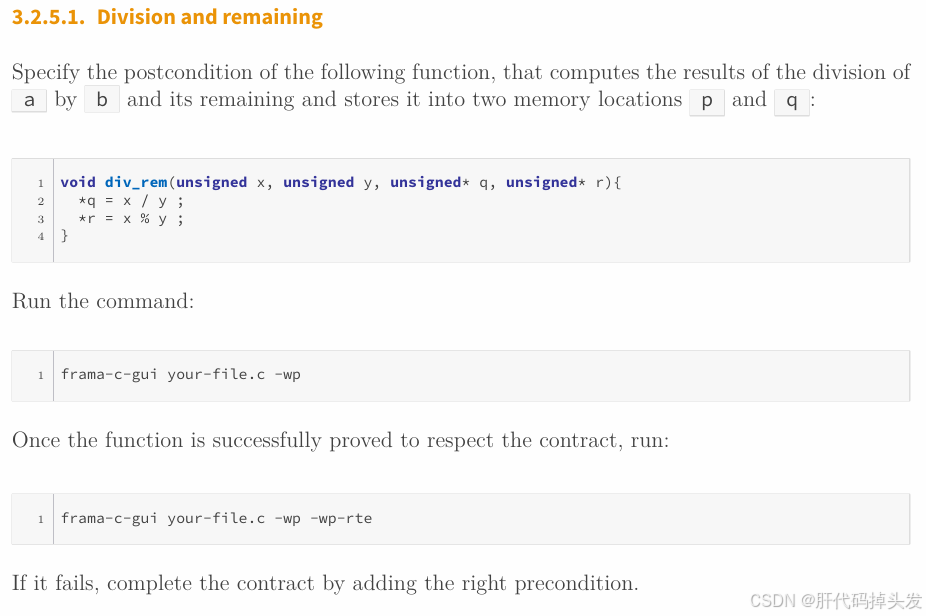
/*@
requires y != 0;
requires \valid(q) && \valid(r);
requires \separated(q, r);
assigns *q, *r;
*/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









