






问题一、java程序读/写到oracle数据库,都是中文乱码。
step1:引入依赖
<!-- 说明:该依赖要和Oracle数据库的版本相对应,例如我对应的oracleDB版本是11g(通过语句查询:select * from v$version),所以用ojdbc6--> <dependency> <groupId>com.oracle.database.jdbc</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.4</version> </dependency> <!-- 说明:该依赖是为了能引入druid的连接属性,从而配置转字符-> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.6</version> </dependency> <dependency>
step2:yaml中修改url和增加源数据类型和链接属性:
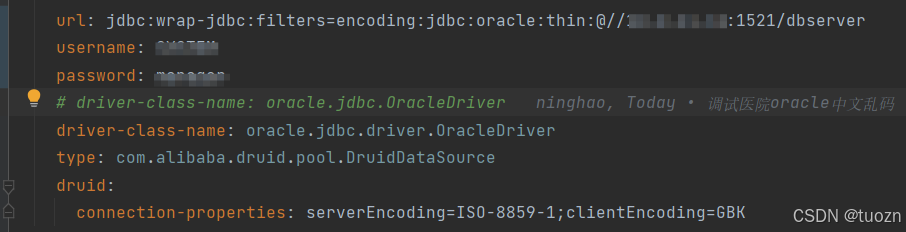
url: jdbc:wrap-jdbc:filters=encoding:jdbc:oracle:thin:@//[ip]/[数据库名] username: 用户名 password: 密码 driver-class-name: oracle.jdbc.driver.OracleDriver type: com.alibaba.druid.pool.DruidDataSource druid: connection-properties: serverEncoding=ISO-8859-1;clientEncoding=GBK
!!!注意:红色字体部分为主要链接部分。
这两步处理完,再重启java程序就能读/写到正确格式的oracle数据了。
问题二、Datagrip查oracle数据,是中文乱码。

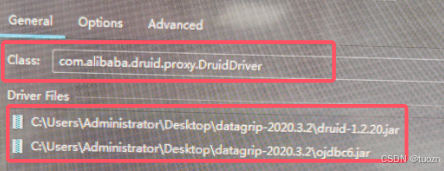
Step1.从General的Driver进去到dataGrip驱动库,引入ojdbc驱动:和前面pom引入的版本原因一致,所以下载ojdbc6引入。
Step2.引入druid数据源。
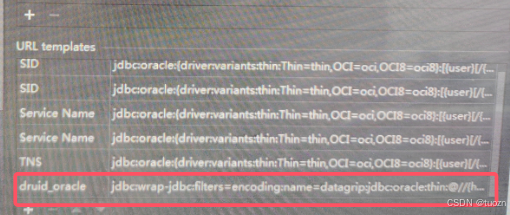
Step3.增加URL templates:
key:druid_oracle
value:jdbc:wrap-jdbc:filters=encoding:name=datagrip:jdbc:oracle:thin:@//{host}[:{port}]/{database}
完成上面3个步骤后,dataGrip查询oracle就不会乱码了。


















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











