







摘要
解决无标签样本和有标签样本之间类别分布不平衡的问题
While long-tailed semi-supervised learning (LTSSL) has received tremendous attention in many real-world classification problems, existing LTSSL algorithms typically assume that the class distributions of labeled and unlabeled data are almost identical. Those LTSSL algorithms built upon the assumption can severely suffer when the class distributions of labeled and unlabeled data are mismatched since they utilize biased pseudo-labels from the model. To alleviate this issue, we propose a new simple method that can effectively utilize unlabeled data of unknown class distributions by introducing the adaptive consistency regularizer (ACR). ACR realizes the dynamic refinery of pseudo-labels for various distributions in a unified formula by estimating the true class distribution of unlabeled data. Despite its simplicity, we show that ACR achieves state-of-the-art performance on a variety of standard LTSSL benchmarks, e.g., an averaged 10% absolute increase of test accuracy against existing algorithms when the class distributions of labeled and unlabeled data are mismatched. Even when the class distributions are identical, ACR consistently outperforms many sophisticated LTSSL algorithms. We carry out extensive ablation studies to tease apart the factors that are most important to ACR’s success. Source code is available at https://github.com/Gank0078/ACR.
不平衡的情况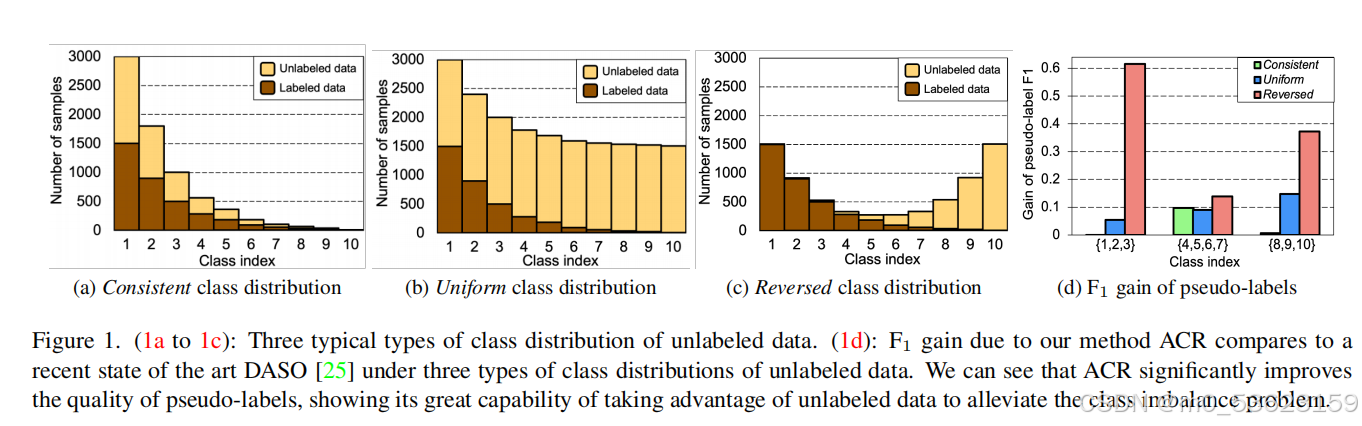
整体的框图
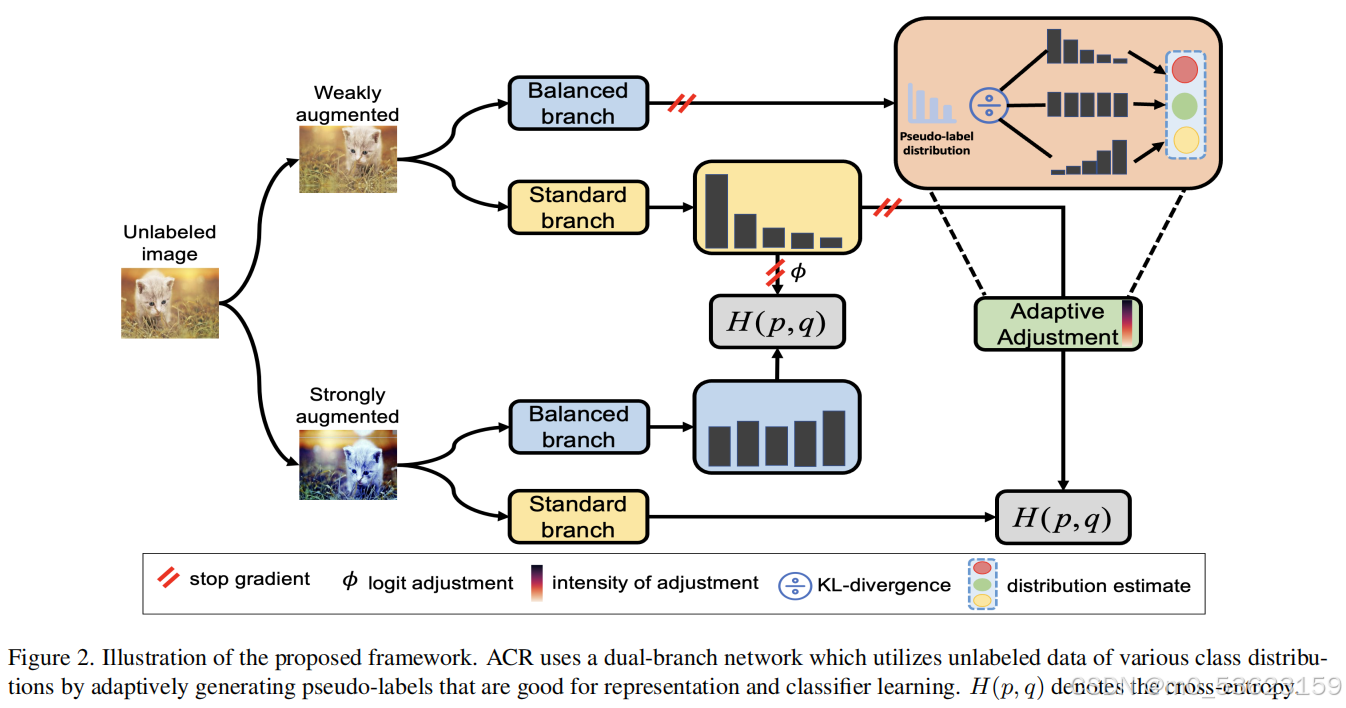
针对本文的公式3,下面进行了详细的分析
深入解析:τ在平衡Softmax损失函数中的关键作用
在深度学习的领域中,分类任务常常面临着类别不平衡的问题。为了应对这一挑战,研究者们提出了诸多方法,其中平衡Softmax损失函数便是一种有效的方式。今天,我将通过自己的学习和思考,详细解析τ(tau)参数在这一损失函数中的重要作用,以及它如何影响整个模型的训练过程。
一、问题背景
我们考虑一个双分支网络结构,包括一个标准分支和一个平衡分支。标准分支采用FixMatch方法,通过优化标准交叉熵损失来学习良好的特征表示 f f f。而平衡分支 f ~ \tilde{f} f~则通过优化一个改进的交叉熵损失——平衡Softmax,来实现更平衡的分类器训练。
平衡Softmax的损失函数定义如下:
L
b
−
l
a
b
e
l
=
−
∑
i
=
1
N
log
exp
(
f
~
y
i
(
l
)
(
x
i
(
l
)
)
+
τ
⋅
log
π
y
i
(
l
)
)
∑
c
=
1
C
exp
(
f
~
c
(
x
i
(
l
)
)
+
τ
⋅
log
π
c
)
\mathcal{L}_{b-\mathrm{label}} = -\sum_{i=1}^N \log \frac{\exp\left(\tilde{f}_{y_i^{(l)}}(x_i^{(l)}) + \tau \cdot \log \pi_{y_i^{(l)}}\right)}{\sum_{c=1}^C \exp\left(\tilde{f}_c(x_i^{(l)}) + \tau \cdot \log \pi_c\right)}
Lb−label=−i=1∑Nlog∑c=1Cexp(f~c(xi(l))+τ⋅logπc)exp(f~yi(l)(xi(l))+τ⋅logπyi(l))
其中, π c \pi_c πc 表示类别先验概率 P ( y = c ) P(y = c) P(y=c) ,通过训练数据的频率来估计,而 τ \tau τ 是一个影响 logit 调整强度的缩放参数。
二、τ参数的作用解析
初看之下,平衡Softmax损失与标准交叉熵损失颇为相似,但其核心区别在于引入了 τ ⋅ log π c \tau \cdot \log \pi_c τ⋅logπc项。这一项的引入,使得每个类别的logit值在计算过程中被调整,从而影响最终的概率分布。
具体而言:
-
分子部分:对于每个样本 x i ( l ) x_i^{(l)} xi(l)的真实类别 y i ( l ) y_i^{(l)} yi(l),我们不仅考虑模型的输出 f ~ y i ( l ) ( x i ( l ) ) \tilde{f}_{y_i^{(l)}}(x_i^{(l)}) f~yi(l)(xi(l)),还加上了 τ ⋅ log π y i ( l ) \tau \cdot \log \pi_{y_i^{(l)}} τ⋅logπyi(l)。这实际上是对真实类别的logit值进行了调整。
-
分母部分:类似地,对所有类别 c c c 的logit值进行了相同的调整,确保调整后的概率分布仍然归一化。
-
对数与负号:通过取对数和加上负号,我们得到了每个样本的损失值,负号确保了损失的最小化方向。
三、τ参数的影响分析
接下来,我深入思考τ的大小如何影响整个损失函数,从而影响模型的训练过程。
-
τ较大时:当τ值较大时, τ ⋅ log π c \tau \cdot \log \pi_c τ⋅logπc 项的权重显著增加。由于 π c \pi_c πc 是类别先验概率,通常情况下,少数类的 π c \pi_c πc 较小,而多数类的 π c \pi_c πc 较大。因此,较大的τ会增强多数类的logit值,抑制少数类的logit值。这可能导致模型更倾向于预测多数类,从而可能加剧类别不平衡的问题。
-
τ较小时:当τ值较小时, τ ⋅ log π c \tau \cdot \log \pi_c τ⋅logπc 项的影响减弱,损失函数更多地依赖于原始的logit值 f ~ c ( x i ( l ) ) \tilde{f}_c(x_i^{(l)}) f~c(xi(l))。这使得模型的预测更加公平,不会因为类别先验而偏向于多数类或少数类,有助于实现更平衡的分类器。
然而,这种直觉似乎与我们的初衷有所出入。我们引入τ的目的是为了缓解类别不平衡,而不是加剧。这提示我,可能需要重新审视τ的符号或其在公式中的具体作用。
四、重新审视τ的作用
经过进一步的思考,我意识到在平衡Softmax损失中,τ的引入是为了调整类别先验的影响,而非单纯地增强或抑制某一类别的logit值。具体来说:
-
平衡分类器的目标:我们希望模型不仅关注多数类,也能公平地对待少数类。因此,τ的调整应当补偿类别不平衡,而不是加剧它。
-
τ的符号问题:或许τ应当取负值,这样 τ ⋅ log π c \tau \cdot \log \pi_c τ⋅logπc 项会增加少数类的logit值,减少多数类的logit值,从而达到平衡的效果。
然而,公式中τ是正值,这意味着我的初步理解可能有误。这需要我进一步深入研究。
五、结合τ的动态调整公式
随后,我看到了τ的计算公式:
τ
(
t
)
=
2
e
d
i
s
t
c
o
n
(
t
−
1
)
e
d
i
s
t
c
o
n
(
t
−
1
)
+
e
d
i
s
t
u
n
i
(
t
−
1
)
+
e
d
i
s
t
r
e
v
(
t
−
1
)
\tau(t) = \frac{2e^{dist^{(t-1)}_{con}}}{e^{dist^{(t-1)}_{con}} + e^{dist^{(t-1)}_{uni}} + e^{dist^{(t-1)}_{rev}}}
τ(t)=edistcon(t−1)+edistuni(t−1)+edistrev(t−1)2edistcon(t−1)
其中:
- t t t 是训练迭代次数。
- d i s t c o n ( t − 1 ) dist^{(t-1)}_{con} distcon(t−1)、 d i s t u n i ( t − 1 ) dist^{(t-1)}_{uni} distuni(t−1)、 d i s t r e v ( t − 1 ) dist^{(t-1)}_{rev} distrev(t−1)分别表示在第 t − 1 t-1 t−1 次迭代时,预测分布与一致性锚定分布、均匀分布、相反分布之间的平均距离。
通过这个公式,τ(t) 是根据模型在不同迭代中的表现动态调整的。进一步分析:
-
当类别分布一致时:若标记和未标记数据的类别分布一致, e d i s t r e v e^{dist_{rev}} edistrev 会远大于 e d i s t c o n e^{dist_{con}} edistcon,使得 τ(t) 接近 0。这意味着调整项几乎不起作用,模型主要依赖于原始的logit值 f ~ c ( x i ( l ) ) \tilde{f}_c(x_i^{(l)}) f~c(xi(l))。
-
在均匀设置中:产生一个适中的 τ(t) 值,小于 1。这表明调整项适当地影响logit值,使模型在类别平衡和原始预测之间取得平衡。
-
相反的情况:当类别分布不均匀时, e d i s t c o n e^{dist_{con}} edistcon 会远大于 e d i s t r e v e^{dist_{rev}} edistrev,因此 τ(t) 会大于其他两种情况,但小于 2。这意味着调整项显著影响logit值,使模型更加关注少数类,从而达到平衡分类的目的。
六、τ(t) 的范围和作用
进一步分析公式 (7),τ(t) 的取值范围大致在 ( 0 , 2 ) (0, 2) (0,2) 之间:
-
τ(t) 接近 0:调整项几乎不起作用,模型主要依赖原始logit值。
-
τ(t) 适中(例如 2 3 \frac{2}{3} 32):调整项适当地影响logit值,实现类别平衡。
-
τ(t) 较大(接近 2):调整项显著影响logit值,使模型偏向于少数类,以达到平衡。
这种动态调整机制确保了 τ(t) 能够根据模型当前的训练状态和数据分布特性,自适应地调节损失函数中的类别先验影响。
七、总结τ(t) 的关键作用
通过上述分析,我清晰地认识到 τ(t) 在平衡Softmax损失函数中的关键作用:
-
动态调节:τ(t) 根据模型在不同迭代中的表现动态变化,适应不同的训练阶段和数据分布特性。
-
平衡损失:通过 τ(t) 调整损失函数中类别先验的影响,使模型在面对类别不平衡数据时,能够做出更公平、更平衡的分类预测。
-
自适应机制:τ(t) 的自适应调整确保了模型训练过程的灵活性和鲁棒性,能够在多变的数据环境中保持良好的性能。
最终,τ(t) 的引入不仅增强了模型对类别不平衡问题的应对能力,还提供了一种自适应的调节机制,使模型训练过程更加智能和高效。
希望这篇文章能够帮助你深入理解 τ(t) 在平衡Softmax损失函数中的重要作用,以及它如何精细地调节模型的训练过程,从而提升分类器的性能。
τ(t) 在平衡Softmax损失函数中作为动态调节参数,通过自适应调整控制类别先验的影响,从而在模型训练过程中实现对类别不平衡问题的有效平衡。 \boxed{\text{τ(t) 在平衡Softmax损失函数中作为动态调节参数,通过自适应调整控制类别先验的影响,从而在模型训练过程中实现对类别不平衡问题的有效平衡。}} τ(t) 在平衡Softmax损失函数中作为动态调节参数,通过自适应调整控制类别先验的影响,从而在模型训练过程中实现对类别不平衡问题的有效平衡。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









