







目录
一、C++概述
1.1 c++简介
“c++”中的++来自于c语言中的递增运算符++,该运算符将变量加1。c++起初也叫”c with clsss”.通过名称表明,c++是对C的扩展,因此c++是c语言的超集,这意味着任何有效的c程序都是有效的c++程序。c++程序可以使用已有的c程序库。
库是编程模块的集合,可以在程序中调用它们。库对很多常见的编程问题提供了可靠的解决方法,
因此可以节省程序员大量的时间和工作量。
c++语言在c语言的基础上添加了面向对象编程和泛型编程的支持。c++继承了c语言高效,简洁,快速和可移植的传统。
c++融合了3种不同的编程方式:
c语言代表的过程性语言.
c++在c语言基础上添加的类代表的面向对象语言.
c++模板支持的泛型编程。
c语言和c++语言的关系:
c++语言是在C语言的基础上,添加了面向对象、模板等现代程序设计语言的特性而发展起来的。两者无论是从语法规则上,还是从运算符的数量和使用上,都非常相似,所以我们常常将这两门语言统称为“C/C++”。
C语言和C++并不是对立的竞争关系:
1)C++是C语言的加强,是一种更好的C语言。
2)C++是以C语言为基础的,并且完全兼容C语言的特性。
c语言和C++语言的学习是可以相互促进。学好C语言,可以为我们将来进一步地学习C++语言打好基础,而C++语言的学习,也会促进我们对于C语言的理解,从而更好地运用C语言。
1.2 c++起源
与c语言一样,c++也是在贝尔实验室诞生的,Bjarne Stroustrup(本贾尼·斯特劳斯特卢普)在20世纪80年代在这里开发了这种语言。
Stroustrup关心的是让c++更有用,而不是实施特定的编程原理或风格。在确定语言特性方面,真正的编程比纯粹的原理更重要。Stroustrup之所以在c的基础上创建c++,是因为c语言简洁、适合系统编程、使用广泛且与UNIX操作系统联系紧密。
用他自己的话来说,“C++主要是为了我的朋友和我不必再使用汇编语言、C语言或者其他现代高级语言来编程而设计的。它的主要功能是可以更方便得编写出好程序,让每个程序员更加快乐”。
二、C++初识
2.1 简单的c++程序
2.1.1 c++ hello world
#include<iostream>
using namespace std; //命名空间
int main(){
//<< 重载运算符;cout和endl前加上std::可以避免省去定义命名空间
std::cout << "hello world" << std::endl;
return EXIT_SUCCESS;
}
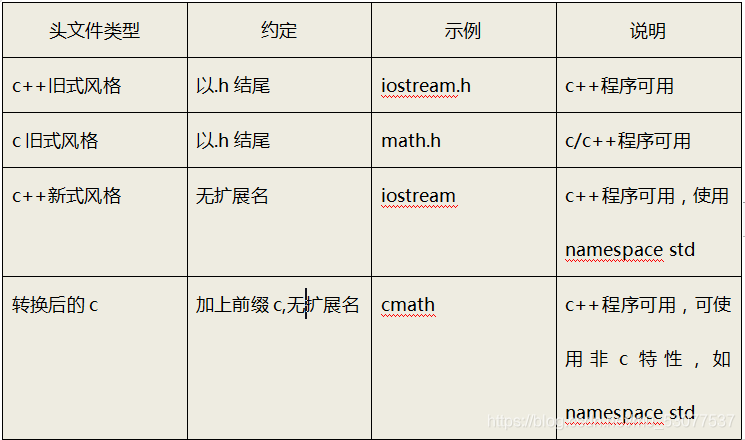
问题1:c++头文件为什么没有.h?
- 在c语言中头文件使用扩展名.h,将其作为一种通过名称标识文件类型的简单方式。但是c++得用法改变了,c++头文件没有扩展名。但是有些c语言的头文件被转换为c++的头文件,这些文件被重新命名,丢掉了扩展名.h(使之成为c++风格头文件),并在文件名称前面加上前缀c(表明来自c语言)。例如c++版本的math.h为cmath.
- 由于C使用不同的扩展名来表示不同文件类型,因此用一些特殊的扩展名(如hpp或hxx)表示c++的头文件也是可以的,ANSI/IOS标准委员会也认为是可以的,但是关键问题是用哪个比较好,最后一致同意不适用任何扩展名。
问题2:using namespace std 是什么?
namespace是指标识符的各种可见范围。命名空间用关键字namespace 来定义。命名空间是C++的一种机制,用来把单个标识符下的大量有逻辑联系的程序实体组合到一起。此标识符作为此组群的名字。
问题3:cout 、endl 是什么?
cout是c++中的标准输出流,endl是输出换行并刷新缓冲区。
2.2 面向过程
面向过程是一种以过程为中心的编程思想。
通过分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向过程编程思想的核心:功能分解,自顶向下,逐层细化==(程序=数据结构+算法)。==
面向过程编程语言存在的主要缺点是不符合人的思维习惯,而是要用计算机的思维方式去处理问题,而且面向过程编程语言重用性低,维护困难。
2.3 面向对象
面向对象编程(Object-Oriented Programming)简称 OOP 技术,是开发计算机应用程序的一种新方法、新思想。过去的面向过程编程常常会导致所有的代码都包含在几个模块中,使程序难以阅读和维护。在做一些修改时常常牵一动百,使以后的开发和维护难以为继。而使用 OOP 技术,常常要使用许多代码模块,每个模块都只提供特定的功能,它们是彼此独立的,这样就增大了代码重用的几率,更加有利于软件的开发、维护和升级。
在面向对象中,算法与数据结构被看做是一个整体,称作对象,现实世界中任何类的对象都具有一定的属性和操作,也总能用数据结构与算法两者合一地来描述,所以可以用下面的等式来定义对象和程序:
对象 = 算法 + 数据结构
程序 = 对象 + 对象 + ……
从上面的等式可以看出,程序就是许多对象在计算机中相继表现自己,而对象则是一个个程序实体。
面向对象编程思想的核心:应对变化,提高复用。
面向对象三大特性
- 封装
把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
类将成员变量和成员函数封装在类的内部,根据需要设置访问权限,通过成员函数管理内部状态。 - 继承
继承所表达的是类之间相关的关系,这种关系使得对象可以继承另外一类对象的特征和能力。
继承的作用:避免公用代码的重复开发,减少代码和数据冗余。 - 多态
多态性可以简单地概括为==“一个接口,多种方法”==,字面意思为多种形态。程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。
三、C++对C的扩展
3.1 ::作用域运算符
- 通常情况下,如果有两个同名变量,一个是全局变量,另一个是局部变量,那么局部变量在其作用域内具有较高的优先权,它将屏蔽全局变量。
//全局变量
int a = 10;
void test(){
//局部变量
int a = 20;
//全局a被隐藏
cout << "a:" << a << endl;
}
程序的输出结果是a:20。在test函数的输出语句中,使用的变量a是test函数内定义的局部变量,因此输出的结果为局部变量a的值。
- ==作用域运算符可以用来解决局部变量与全局变量的重名问题 ==
//全局变量
int a = 10;
//1. 局部变量和全局变量同名
void test(){
int a = 20;
//打印局部变量a
cout << "局部变量a:" << a << endl;
//打印全局变量a
cout << "全局变量a:" << ::a << endl;
3.2 名字控制与C++命名空间(namespace)语法
-
名字控制
名字是程序设计过程中一项最基本的活动,当一个项目很大时,它会不可避免地包含大量名字。c++允许我们对名字的产生和名字的可见性进行控制。
我们之前在学习c语言可以通过static关键字来使得名字只得在本编译单元内可见,在c++中我们将通过一种通过==定义命名空间(控制标识符的作用域)==来控制对名字的访问。 -
命名空间(namespace)
在c++中,名称(name)可以是符号常量、变量、函数、结构、枚举、类和对象等等。工程越大,名称互相冲突性的可能性越大。另外使用多个厂商的类库时,也可能导致名称冲突。为了避免在大规模程序的设计中,以及在程序员使用各种各样的C++库时,这些标识符的命名发生冲突,标准C++引入关键字namespace(命名空间/名字空间/名称空间),可以更好地控制标识符的作用域。
3.2.1 创建一个命名空间
- 1.命名空间里面可以防止:常量、变量、函数、结构、枚举、类和对象
namespace A{
int a = 10;
}
namespace B{
int a = 20;
}
void test(){
cout << "A::a : " << A::a << endl;
cout << "B::a : " << B::a << endl;
}
- 2.命名空间只能全局范围内定义(以下错误写法)
void test(){
namespace A{
int a = 10;
}
namespace B{
int a = 20;
}
cout << "A::a : " << A::a << endl;
cout << "B::a : " << B::a << endl;
}
- 3.命名空间可嵌套命名空间
namespace A{
int a = 10;
namespace B{
int a = 20;
}
}
void test(){
cout << "A::a : " << A::a << endl;
cout << "A::B::a : " << A::B::a << endl;
}
- 4.命名空间重名会发生合并
或者说命名空间是开放的,可以随时把新的成员加入已有的命名空间中
namespace A{
int a = 10;
}
namespace A{
void func(){
cout << "hello namespace!" << endl;
}
}
void test(){
cout << "A::a : " << A::a << endl;
A::func();
}
- 5.匿名命名空间,相当于c语言static的用法,使得其可以作为内部连接
namespace {
int a = 10;
}
- 6.命名空间可以起别名
#include<iostream>
using namespace std;
namespace A{
int a = 10;
}
void test(){
namespace B = A;
cout<<"a="<<B::a<<endl; //a = 10
cout<<"a="<<A::a<<endl; //a = 10
}
3.2.2 声明和实现可分离
//声明
#pragma once
namespace MySpace{
void func1();
void func2(int param);
}
//实现
void MySpace::func1(){
cout << "MySpace::func1" << endl;
}
void MySpace::func2(int param){
cout << "MySpace::func2 : " << param << endl;
}
3.2.3 using声明与using编译
- == 注意避免二义性==,区分以下两种情况
namespace A{
int a = 10;
}
void test(){
int a = 10;
using A::a; //using声明:打开命名空间并使用里面的变量,当该变量与局部变量重名时会导致二义性
using namespace A; //using编译:只是打开命名空间,不会导致二义性;注意若是打开多个命名空间还是可能导致二义性
cout<<a<<endl; //二义性?
}
- 可使得指定的标识符可用
namespace A{
int paramA = 20;
int paramB = 30;
void funcA(){ cout << "hello funcA" << endl; }
void funcB(){ cout << "hello funcA" << endl; }
}
void test(){
//1. 通过命名空间域运算符
cout << A::paramA << endl;
A::funcA();
//2. using声明
using A::paramA;
using A::funcA;
cout << paramA << endl;
//cout << paramB << endl; //不可直接访问
funcA();
//3. 同名冲突
//int paramA = 20; //相同作用域注意同名冲突
}
- using声明碰到函数重载:如果命名空间包含一组用相同名字重载的函数,using声明就声明了这个重载函数的所有集合。
namespace A{
void func(){}
void func(int x){}
int func(int x,int y){}
}
void test(){
using A::func;
func();
func(10);
func(10, 20);
}
-
注意:使用using声明或using编译指令会增加命名冲突的可能性。也就是说,如果有名称空间,并在代码中使用作用域解析运算符,则不会出现二义性。
-
需要记住的关键问题是当引入一个全局的using编译指令时,就为该文件打开了该命名空间,它不会影响任何其他的文件,所以可以在每一个实现文件中调整对命名空间的控制。比如,如果发现某一个实现文件中有太多的using指令而产生的命名冲突,就要对该文件做个简单的改变,通过明确的限定或者using声明来消除名字冲突,这样不需要修改其他的实现文件。
3.3 c++对c的增强
3.3.1 全局变量检测增强(重定义)
c语言代码:
int a = 10; //赋值,当做定义
int a; //没有赋值,当做声明
int main(){
printf("a:%d\n",a);
return EXIT_SUCCESS;
}
此代码在c++下编译失败,在c下编译通过.
3.3.2 C++函数检测
- 参数和返回值必须有类型
- 函数有参时,形参和实参数目和位置保持一致;无参时,不得传入实参;
c语言代码:
//i没有写类型,可以是任意类型
int fun1(i){
printf("%d\n", i);
return 0;
}
//i没有写类型,可以是任意类型
int fun2(i){
printf("%s\n", i);
return 0;
}
//没有写参数,代表可以传任何类型的实参
int fun3(){
printf("fun33333333333333333\n");
return 0;
}
//C语言,如果函数没有参数,建议写void,代表没有参数
int fun4(void){
printf("fun4444444444444\n");
return 0;
}
g(){
return 10;
}
int main(){
fun1(10);
fun2("abc");
fun3(1, 2, "abc");
printf("g = %d\n", g());
return 0;
}
以上c代码c编译器编译可通过,c++编译器无法编译通过。
- 在C语言中,int fun() 表示返回值为int,接受任意参数的函数,int fun(void) 表示返回值为int的无参函数。
- 在C++ 中,int fun() 和int fun(void) 具有相同的意义,都表示返回值为int的无参函数。
3.3.3 更严格的类型转换
在C++,不同类型的变量一般是不能直接赋值的,需要相应的强转。
c语言代码:
typedef enum COLOR{ GREEN, RED, YELLOW } color;
int main(){
color mycolor = GREEN;
mycolor = 10;
printf("mycolor:%d\n", mycolor);
char* p = malloc(10); //需要强转
return EXIT_SUCCESS;
}
以上c代码c编译器编译可通过,c++编译器无法编译通过。
3.3.4 struct类型加强
- c中定义结构体变量需要加上struct关键字,c++不需要。
- c中的结构体只能定义成员变量,不能定义成员函数。c++即可以定义成员变量,也可以定义成员函数。
//1. 结构体中即可以定义成员变量,也可以定义成员函数
struct Student{
string mName;
int mAge;
void setName(string name){ mName = name; }
void setAge(int age){ mAge = age; }
void showStudent(){
cout << "Name:" << mName << " Age:" << mAge << endl;
}
};
//2. c++中定义结构体变量不需要加struct关键字
void test01(){
Student student;
student.setName("John");
student.setAge(20);
student.showStudent();
}
3.3.5 新增bool类型关键字
标准c++的bool类型有两种内建的常量true(转换为整数1)和false(转换为整数0)表示状态。这三个名字都是关键字。
- bool类型只有两个值,true(1值),false(0值)
- bool类型占1个字节大小
- 给bool类型赋值时,非0值会自动转换为true(1),0值会自动转换false(0)
void test()
{ cout << sizeof(false) << endl; //为1,//bool类型占一个字节大小
bool flag = true; // c语言中没有这种类型
flag = 100; //给bool类型赋值时,非0值会自动转换为true(1),0值会自动转换false(0)
}
- [c语言中的bool类型]
c语言中也有bool类型,在c99标准之前是没有bool关键字,c99标准已经有bool类型,包含头文件stdbool.h,就可以使用和c++一样的bool类型。
3.3.6 三目运算符功能增强
- c语言三目运算表达式返回值为数据值,为右值,不能赋值。
int a = 10;
int b = 20;
printf("ret:%d\n", a > b ? a : b);
//思考一个问题,(a > b ? a : b) 三目运算表达式返回的是什么?
//(a > b ? a : b) = 100;
//返回的是右值
- c++语言三目运算表达式返回值为变量本身(引用),为左值,可以赋值。
int a = 10;
int b = 20;
printf("ret:%d\n", a > b ? a : b);
//思考一个问题,(a > b ? a : b) 三目运算表达式返回的是什么?
cout << "b:" << b << endl;
//返回的是左值,变量的引用
(a > b ? a : b) = 100;//返回的是左值,变量的引用
cout << "b:" << b << endl;
3.3.7 [左值和右值概念]
在c++中可以放在赋值操作符左边的是左值,可以放到赋值操作符右面的是右值。
有些变量即可以当左值,也可以当右值。
左值为Lvalue,L代表Location,表示内存可以寻址,可以赋值。
右值为Rvalue,R代表Read,就是可以知道它的值。
比如:int temp = 10; temp在内存中有地址,10没有,但是可以Read到它的值。
3.4 C++中的const
- 在c++中,一个const不必创建内存空间,而在c中,一个const总是需要一块内存空间。在c++中,是否为const常量分配内存空间依赖于如何使用。
- 一般说来,如果一个const仅仅用来把一个名字用一个值代替(就像使用#define一样),那么该存储局空间就不必创建。如果存储空间没有分配内存的话,在进行完数据类型检查后,为了代码更加有效,值也许会折叠到代码中。 不过,取一个const地址, 或者把它定义为extern,则会为该const创建内存空间。
- 在c++中,出现在所有函数之外的const作用于整个文件(也就是说它在该文件外不可见),默认为内部连接(extern可提升作用域),c++中其他的标识符一般默认为外部连接。
3.4.1 C/C++中const异同总结
- c语言全局const会被存储到只读数据段。c++中全局const当声明extern或者对变量取地址时,编译器会分配存储地址,变量存储在只读数据段。两个都受到了只读数据段的保护,不可修改。
const int constA = 10;
int main(){
int* p = (int*)&constA;
*p = 200;
}
以上代码在c/c++中编译通过,在运行期,修改constA的值时,发生写入错误。原因是修改只读数据段的数据。
- c语言中局部const存储在堆栈区,只是不能通过变量直接修改const只读变量的值,但是可以跳过编译器的检查,通过指针间接修改const值。
const int constA = 10;
int* p = (int*)&constA;
*p = 300;
printf("constA:%d\n",constA);
printf("*p:%d\n", *p);
c++中对于局部的const变量要区别对待:
- 1.对于基础数据类型,也就是(extern)const int a = 10这种,编译器会把它放到符号表中,不分配内存,当对其取地址时,会分配内存。
const int constA = 10; //前面加extern也会分配内存
int* p = (int*)&constA; //取地址时会分配临时内存
*p = 300;
cout << "constA:" << constA << endl; //10
cout << "*p:" << *p << endl; //300
constA在符号表中,当我们对constA取地址,这个时候为constA分配了新的空间,*p操作的是分配的空间,而constA是从符号表获得的值。
- 2.对于基础数据类型,如果用一个变量初始化const变量,如果const int a = b,那么也是会给a分配内存。
int b = 10;
const int constA = b;
int* p = (int*)&constA;
*p = 300;
cout << "constA:" << constA << endl; //300
cout << "*p:" << *p << endl; //300
constA 分配了内存,所以我们可以修改constA内存中的值。
- 3.对于自定数据类型,比如类对象,那么也会分配内存。
const Person person; //未初始化age
//person.age = 50; //不可修改
Person* pPerson = (Person*)&person;
//指针间接修改
pPerson->age = 100;
cout << "pPerson->age:" << pPerson->age << endl;
pPerson->age = 200;
cout << "pPerson->age:" << pPerson->age << endl;
为person分配了内存,所以我们可以通过指针的间接赋值修改person对象。
-
c中const默认为外部连接,c++中const默认为内部连接.当c语言两个文件中都有const int a的时候,编译器会报重定义的错误。而在c++中,则不会,因为c++中的const默认是内部连接的。如果想让c++中的const具有外部连接,必须显示声明为: extern const int a = 10;
-
const由c++采用,并加进标准c中,尽管他们很不一样。在c中,编译器对待const如同对待变量一样,只不过带有一个特殊的标记,意思是”你不能改变我”。在c++中定义const时,编译器为它创建空间,所以如果在两个不同文件定义多个同名的const,链接器将发生链接错误。简而言之,const在c++中用的更好。
-
了解: 能否用变量定义数组:
在支持c99标准的编译器中,可以使用变量定义数组。
- 微软官方描述vs2013编译器不支持c99.:
Microsoft C conforms to the standard for the C language as set forth in the 9899:1990 edition of the ANSI C standard. - 以下代码在Linux GCC支持c99编译器编译通过
int a = 10;
int arr[a];
int i = 0;
for(;i<10;i++)
arr[i] = i;
i = 0;
for(;i<10;i++)
printf("%d\n",arr[i]);
3.4.2 尽量以const替换#define
- 在旧版本C中,如果想建立一个常量,必须使用预处理器#define MAX 1024;
- 我们定义的宏MAX从未被编译器看到过,因为在预处理阶段,所有的MAX已经被替换为了1024,于是MAX并没有将其加入到符号表中。但我们使用这个常量获得一个编译错误信息时,可能会带来一些困惑,因为这个信息可能会提到1024,但是并没有提到MAX.如果MAX被定义在一个不是你写的头文件中,你可能并不知道1024代表什么,也许解决这个问题要花费很长时间。
- 解决办法就是用一个常量替换上面的宏。
const int max= 1024;
const和#define区别总结:
1.const有类型,可进行编译器类型安全检查。#define无类型,不可进行类型检查.
2.const有作用域,而#define不重视作用域,默认定义处到文件结尾.如果定义在指定作用域下有效的常量,那么#define就不能用。
- 宏常量没有类型,所以调用了int类型重载的函数。const有类型,所以调用希望的short类型函数?
#define PARAM 128
const short param = 128;
void func(short a){
cout << "short!" << endl;
}
void func(int a){
cout << "int" << endl;
}
- 宏常量不重视作用域.
void func1(){
const int a = 10;
#define A 20
//#undef A //卸载宏常量A
}
void func2(){
//cout << "a:" << a << endl; //不可访问,超出了const int a作用域
cout << "A:" << A << endl; //#define作用域从定义到文件结束或者到#undef,可访问
}
int main(){
func2();
return EXIT_SUCCESS;
}
问题: 宏常量可以有命名空间吗?
namespace MySpace{
#define num 1024
}
void test(){
//cout << MySpace::NUM << endl; //错误
//int num = 100; //命名冲突
cout << num << endl;
}
3.5 引用(reference)
3.5.1 引用基本用法
引用是c++对c的重要扩充。在c/c++中指针的作用基本都是一样的,但是c++增加了另外一种给函数传递地址的途径,这就是按引用传递(pass-by-reference),它也存在于其他一些编程语言中,并不是c++的发明。
- 变量名实质上是一段连续内存空间的别名,是一个标号(门牌号)
- 程序中通过变量来申请并命名内存空间
- 通过变量的名字可以使用存储空间
对一段连续的内存空间只能取一个别名吗?
c++中新增了引用的概念,引用可以作为一个已定义变量的别名。
引用初始化基本语法: Type& ref = val;
注意事项:
1.&在此不是求地址运算,而是起标识作用。 类型标识符是指目标变量的类型
2.必须在声明引用变量时进行初始化。
3.引用初始化之后不能改变。不能有NULL引用。必须确保引用是和一块合法的存储单元关联。
4.可以建立对数组的引用。
- 认识引用
void test01(){
int a = 10;
//给变量a取一个别名b
int& b = a;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "------------" << endl;
//操作b就相当于操作a本身
b = 100;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "------------" << endl;
//一个变量可以有n个别名
int& c = a;
c = 200;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
cout << "------------" << endl;
//a,b,c的地址都是相同的
cout << "a:" << &a << endl;
cout << "b:" << &b << endl;
cout << "c:" << &c << endl;
}
- 使用引用注意事项
void test02(){
//1) 引用必须初始化
//int& ref; //报错:必须初始化引用
//2) 引用一旦初始化,不能改变引用
int a = 10;
int b = 20;
int& ref = a;
ref = b; //不能改变引用
//3) 不能对数组建立引用
int arr[10];
//int& ref3[10] = arr;
}
//1. 建立数组引用方法一
typedef int ArrRef[10];
int arr[10];
ArrRef& aRef = arr;
for (int i = 0; i < 10;i ++){
aRef[i] = i+1;
}
for (int i = 0; i < 10;i++){
cout << arr[i] << " ";
}
cout << endl;
//2. 建立数组引用方法二
int(&f)[10] = arr;
for (int i = 0; i < 10; i++){
f[i] = i+10;
}
for (int i = 0; i < 10; i++){
cout << arr[i] << " ";
}
cout << endl;
3.5.2 函数中的引用
- 最常看见引用的地方是在函数参数和返回值中。当引用被用作函数参数时,在函数内对任何引用的修改,将对还函数外的参数产生改变。当然,可以通过传递一个指针来做相同的事情,但引用具有更清晰的语法。
- 如果从函数中返回一个引用,必须像从函数中返回一个指针一样对待。当函数返回值时,引用关联的内存一定要存在。
- 引用作为其它变量的别名而存在,因此在一些场合可以代替指针。C++主张用引用传递取代地址传递的方式,因为引用语法容易且不易出错。
//值传递
void ValueSwap(int m,int n){
int temp = m;
m = n;
n = temp;
}
//地址传递
void PointerSwap(int* m,int* n){
int temp = *m;
*m = *n;
*n = temp;
}
//引用传递
void ReferenceSwap(int& m,int& n){
int temp = m;
m = n;
n = temp;
}
void test(){
int a = 10;
int b = 20;
//值传递
ValueSwap(a, b);
cout << "a:" << a << " b:" << b << endl;
//地址传递
PointerSwap(&a, &b);
cout << "a:" << a << " b:" << b << endl;
//引用传递
ReferenceSwap(a, b);
cout << "a:" << a << " b:" << b << endl;
}
通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单:
1) 函数调用时传递的实参不必加“&”符
2) 在被调函数中不必在参数前加“*”符
- 不能返回局部变量的引用。
- 函数当左值,必须返回引用。
//返回局部变量引用
int& TestFun01(){
int a = 10; //局部变量
return a;
}
//返回静态变量引用
int& TestFunc02(){
static int a = 20;
cout << "static int a : " << a << endl;
return a;
}
int main(){
//不能返回局部变量的引用
int& ret01 = TestFun01();
//如果函数做左值,那么必须返回引用
TestFunc02();
TestFunc02() = 100;
TestFunc02();
return EXIT_SUCCESS;
}
3.5.3 引用的本质
引用的本质在c++内部实现是一个指针常量.
Type& ref = val; // Type* const ref = &val;
c++编译器在编译过程中使用常指针作为引用的内部实现,因此引用所占用的空间大小与指针相同,只是这个过程是编译器内部实现,用户不可见。
//发现是引用,转换为 int* const ref = &a;
void testFunc(int& ref){
ref = 100; // ref是引用,转换为*ref = 100
}
int main(){
int a = 10;
int& aRef = a; //自动转换为 int* const aRef = &a;这也能说明引用为什么必须初始化
aRef = 20; //内部发现aRef是引用,自动帮我们转换为: *aRef = 20;
cout << "a:" << a << endl;
cout << "aRef:" << aRef << endl;
testFunc(a);
return EXIT_SUCCESS;
}
3.5.4 指针引用
- 在c语言中如果想改变一个指针的指向而不是它所指向的内容,函数声明可能这样:
void fun(int**); - 给指针变量取一个别名。
Type* pointer = NULL;
Type*& = pointer;
Type* pointer = NULL; Type*& = pointer;
struct Teacher{
int mAge;
};
//指针间接修改teacher的年龄
void AllocateAndInitByPointer(Teacher** teacher){
*teacher = (Teacher*)malloc(sizeof(Teacher));
(*teacher)->mAge = 200;
}
//引用修改teacher年龄
void AllocateAndInitByReference(Teacher*& teacher){
teacher->mAge = 300;
}
void test(){
//创建Teacher
Teacher* teacher = NULL;
//指针间接赋值
AllocateAndInitByPointer(&teacher);
cout << "AllocateAndInitByPointer:" << teacher->mAge << endl;
//引用赋值,将teacher本身传到ChangeAgeByReference函数中
AllocateAndInitByReference(teacher);
cout << "AllocateAndInitByReference:" << teacher->mAge << endl;
free(teacher);
}
- 对于c++中的定义那个,语法清晰多了。函数参数变成指针的引用,用不着取得指针的地址。
3.5.5 常量引用
-
常量引用的定义格式:
const Type& ref = val; -
常量引用注意:
字面量不能赋给引用int& ref = 100;,但是可以赋给const引用const int& ref = 100
const修饰的引用,不能修改。
void test01(){
int a = 100;
const int& aRef = a; //此时aRef就是a
//aRef = 200; 不能通过aRef的值
a = 100; //OK
cout << "a:" << a << endl;
cout << "aRef:" << aRef << endl;
}
void test02(){
//不能把一个字面量赋给引用
//int& ref = 100;
//但是可以把一个字面量赋给常引用
const int& ref = 100; //int temp = 200; const int& ret = temp;
}
- [const引用使用场景]
常量引用主要用在函数的形参,尤其是类的拷贝/复制构造函数。 - 将函数的形参定义为常量引用的好处:
引用不产生新的变量,减少形参与实参传递时的开销。
由于引用可能导致实参随形参改变而改变,将其定义为常量引用可以消除这种副作用。 - 如果希望实参随着形参的改变而改变,那么使用一般的引用,如果不希望实参随着形参改变,那么使用常引用。
//const int& param防止函数中意外修改数据
void ShowVal(const int& param){
cout << "param:" << param << endl;
}
3.11 练习作业
1.设计一个类,求圆的周长。
2.设计一个学生类,属性有姓名和学号,可以给姓名和学号赋值,可以显示学生的姓 名和学号

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









