







diffusion model
讲解:
【较真系列】讲人话-Diffusion Model全解(原理+代码+公式)_哔哩哔哩_bilibili
stable diffusion【CVPR2022】
原始论文: https://arxiv.org/pdf/2112.10752
代码:
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
Imagen【NeurIPS 2022】
论文:https://arxiv.org/pdf/2205.11487
讲解:https://zhuanlan.zhihu.com/p/640941181
其实挺简单的,就是在后面加入了一个超分的部分。
1. 文本编码:T5模型
2. classifier-free guidance:

3. 对unet进行改进,减小训练过程的计算开销。
4. text-image(base model:64*64);image-image(超分model:64*64->256*256);image-image(超分model:256*256->1024*1024) 三个模块。
在两个超分模块中,除了text embeddings作为条件外,作者还将低分辨率的输出图像作为控制生成过程的条件之一。而对于文本编码的使用,则是先concat到图像后面,然后再作cross attention处理

Dreambooth【CVPR 2023】
论文:https://arxiv.org/pdf/2208.12242v1
讲解:【文生图】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation-优快云博客
感觉就是sd换了一个损失函数,然后又加上了sr模块。
语言模型也是使用的T5
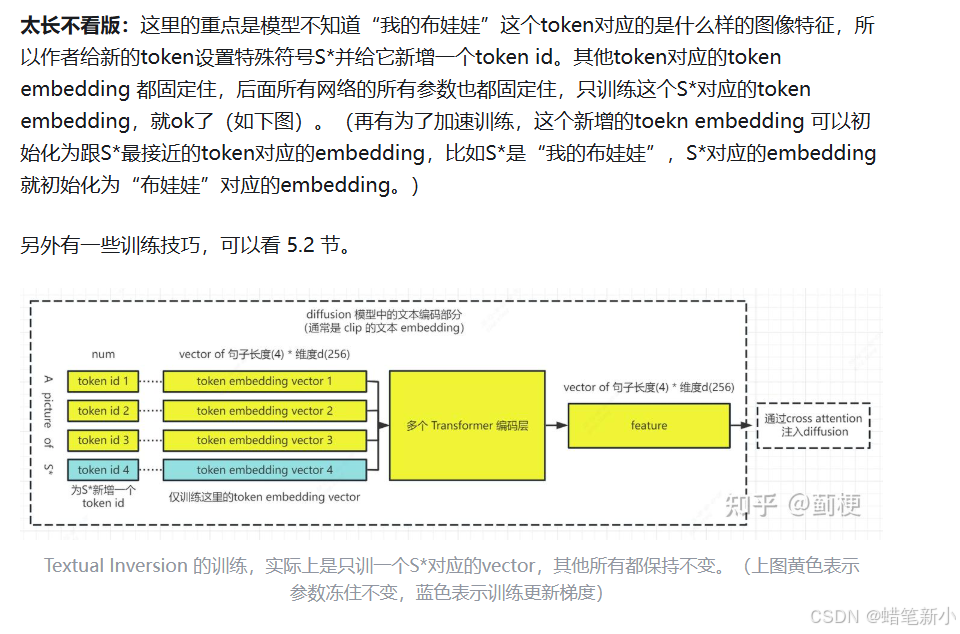
Textual Inversion
讲解:https://zhuanlan.zhihu.com/p/621437374
类似于dreambooth,这个是输入几张图片,训练文本表示的embedding
IP-Adapter【未发表】
其实还挺简单的,它是有两个prompt,分别是image和text(可以不要)
两个prompt分别经过cross-attn,并把结果相加后输入到unet中。

SnapFusion【NeurIPs 2023】
讲解:https://zhuanlan.zhihu.com/p/650739412
论文:https://arxiv.org/pdf/2306.00980
创新点:
1. 改进unet,将里面的结构去掉,分析效果,然后找到去掉结构后对网络影响最小的那几块使用;
2. 蒸馏,对DDPM的步数进行蒸馏
3. VAE Decoder 优化,使用蒸馏
感觉改进不是很多。
对于文本编码器,好像是用的clip,和sd一样,没有重点在文章中找。
DeepCache【CVPR2024】
论文:https://arxiv.org/pdf/2312.00858
讲解:https://zhuanlan.zhihu.com/p/673114336
代码:GitHub - horseee/DeepCache: [CVPR 2024] DeepCache: Accelerating Diffusion Models for Free
创新点:
找的角度很好,改进并不大,效果很好,就是将上一时刻的特征缓存下来,然后后续直接使用。
对于文本编码器,使用的是clip。

DiT【ICCV 2023】
论文:https://arxiv.org/pdf/2212.09748
DiT只能按照类别进行图片生成,可以生成imagenet中的1000类。主要的创新点感觉就是改进了一个transformer,其余的没有什么太大的变化.应证了实习的时候和同事们聊的,多模态现在几乎使用一个mlp进行编码了。这边也是将文本数据进行mlp编码。

DiT还沿用了OpenAI的Improved DDPM扩散思想,与原始DDPM相比不再采用固定的方差,而是采用网络来预测方差。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









