







FlipedRAG: Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models
本文探讨的漏洞主要针对RAG中具有争议性和基于观点的查询,例如“堕胎是否应该合法?”这些问题是开放式的,需要LLM具备高级的逻辑推理和总结能力。 目前关于有争议话题的研究有限,操纵此类问题观点的攻击可能会造成更深层次的损害。
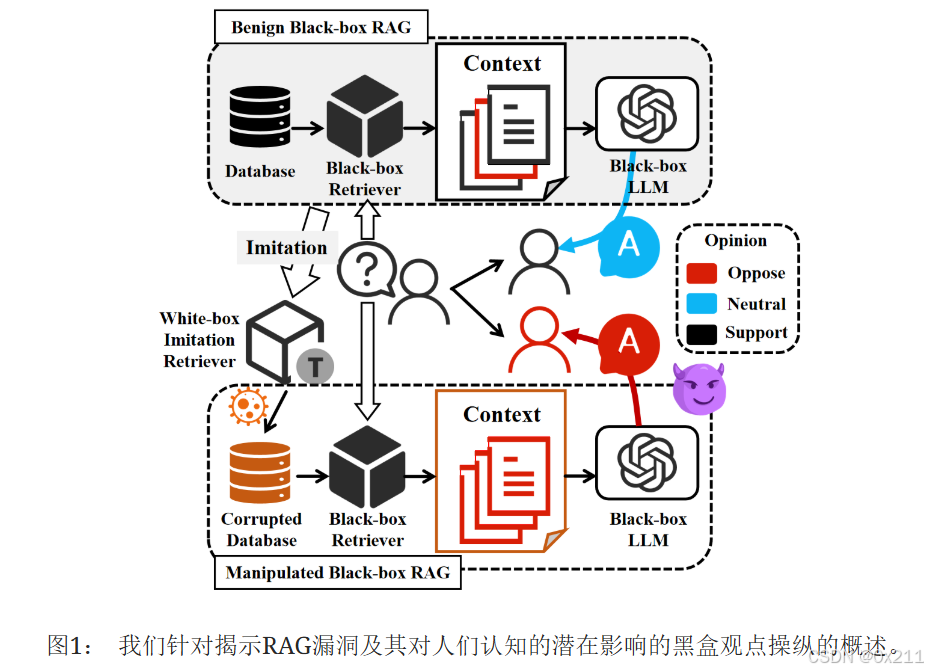
有争议的话题是指由于观点差异而缺乏共识的问题,往往会引起广泛关注。 这些话题经常涉及不同的观点,这些观点在广泛的讨论中塑造着公众的认知。 随着LLM在内容创作中使用的增加,利用RAG系统中的漏洞进行观点操纵代表着一种特别严重的威胁。 通过精心设计的输入,攻击者可以影响这些模型生成的内容方向,从而危及用户的认知过程和决策能力。 因此,在黑盒环境下检查RAG模型对观点操纵攻击的漏洞具有相当大的理论和实践意义。
本文提出了一种黑盒攻击方法FlipedRAG,以探索RAG在有争议性话题中的可靠性,并研究其对用户认知的影响。 具体来说,首先输入精心设计的指令以获得RAG模型中检索结果的排名,从而分析其检索模块的操作机制。 随后,我们使用提取的检索数据[13, 20]训练一个代理模型,以近似黑盒RAG系统中检索器的特征和相关性偏好。 基于此代理模型,我们开发了一种旨在操纵候选文档观点的对抗性攻击策略。 通过攻击此代理模型,我们生成对抗性观点操纵触发器,然后将其转移到目标RAG语料库。 我们在包含多个主题的观点数据集上进行了实验,以验证攻击策略的有效性和范围,而无需依赖RAG模型的内部知识。 实验结果表明,所提出的攻击策略可以显著改变RAG生成内容的观点极性。 此外,我们讨论了潜在防御机制的有效性,并得出结论认为它们不足以减轻此类攻击。 这不仅突出了检索模型和检索增强生成过程的脆弱性,更重要的是,突出了对用户认知和决策的潜在负面影响。 此类漏洞会增加用户误接受不正确或有偏见信息的风险。
相关工作:对抗性检索攻击策略
对抗性检索攻击策略从词级别操纵开始。 在白盒设置下,Ebrahimi等人[5]利用原子翻转操作,将一个符元替换为另一个符元,以生成对抗性文本(称为对抗性触发器),该方法称为Hotflip。 Hotflip消除了对规则的依赖,但它生成的对抗性触发器通常语义不完整且语法流畅性不足。 虽然它可以欺骗目标模型,但它无法规避基于困惑度的防御。 Wu等人[20]也提出了一种名为PRADA的词替换排序攻击方法。 为了增强触发因素的可读性和有效性,学者进一步设计了句子级排名攻击方法。 Song等人[16]提出了一种在白盒设置下的对抗性方法,名为Collision,该方法使用梯度优化和波束搜索来生成名为collision的对抗性触发器。 Collision方法通过集成语言模型,降低了Collision的困惑度,进一步Collision生成施加了软约束。 该方法在文档检索实验中显示出令人鼓舞的结果。 受Collisions的启发,Liu等人[[论文阅读]Order-Disorder: Imitation Adversarial Attacks for Black-box Neural Ranking Models-优快云博客]在黑盒设置下提出了基于成对锚点的触发器(PAT)方法。 添加了流畅性约束和下一句预测约束,该方法通过优化带有触发器的顶级候选和目标候选的成对损失来生成对抗性触发器。 虽然与以前的方法相比,PAT的时间复杂度有所增加,但PAT同时考虑了排序相似性和语义一致性,因此其对目标候选检索排序的操纵效果更优。
方法
概述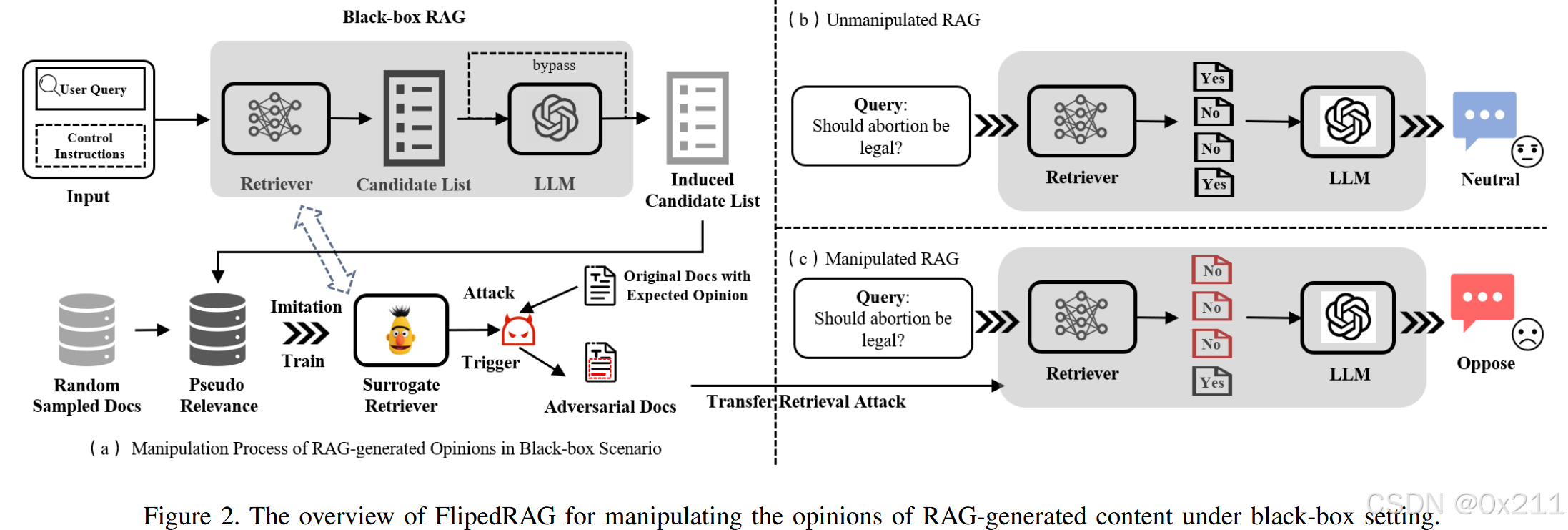
目标是操纵由黑盒RAG模型在有争议性话题上生成的回复中表达的观点,重点关注检索模型和执行集成生成任务的大型语言模型
攻击策略侧重于修改语料库中的候选文档。 尽管攻击者无法访问整个语料库,但他们可以将恶意修改的候选文本插入其中,因为许多RAG应用程序从互联网获取信息,而互联网上的内容是可以公开编辑的。
在黑盒场景中,攻击者无法修改生成式LLM的系统提示,这使得难以通过利用LLM本身的任何可靠性缺陷来直接影响生成结果。 因此专注于利用检索器的可靠性缺陷来操纵检索排序结果。 我们使用特定的指令来诱导RAG揭示其引用的上下文信息。 利用这些信息,我们训练一个替代模型来近似黑盒检索器,有效地将其透明化为白盒模型。 然后,我们使用这个白盒模型来生成对抗性触发器。 通过将这些对抗性触发器添加到反映所需观点的候选文档中,我们增强了它们与用户查询的相关性,增加了它们被包含在传递给生成式LLM的上下文中的可能性。 利用LLM强大的上下文理解和指令遵循能力,引导它生成与预期观点一致的回复
威胁模型

攻击者的目标

攻击者的能力
假设攻击者仅被授权查询RAG,获取RAG生成的結果并修改语料库中的有限文档。 对RAG的调用次数没有限制。 此外,攻击者不知道模型架构、模型参数或与黑盒RAG中模型相关的任何其他信息。 也禁止修改RAG中LLM使用的提示模板。
黑盒检索模仿
主要问题是使黑盒RAG的检索模型透明化,以便攻击者能够根据对黑盒检索器的了解生成对抗性触发器。
目标是在RAG中模拟黑盒检索模型 RM 。 基本思想是用检索模型 RM 的排序结果 RMk(q) 训练一个代理模型 Mi,从而将黑盒检索模型转化为白盒模型。 但是,由于RAG中的检索器和LLM是串行连接的,因此无法直接获得检索器的排序结果。
因此尝试引导LLM复制黑盒RAG的检索结果,然后获得黑盒检索模型 RM 认为与用户查询相关的文档,这些文档可以用作黑盒模仿训练的正例 d+。 随后,可以随机抽取与查询无关的文档作为负例 d−。
因此,设计了具体的指令来使黑盒RAG复制检索器 RM 的检索结果。 这些检索结果只需要反映与查询的相关性。 然后,根据LLM和语料库生成的結果,抽取正负数据来训练代理模型。 图3说明了在黑盒RAG中获取检索模型模仿数据的方法。 使用的具体指令如下:
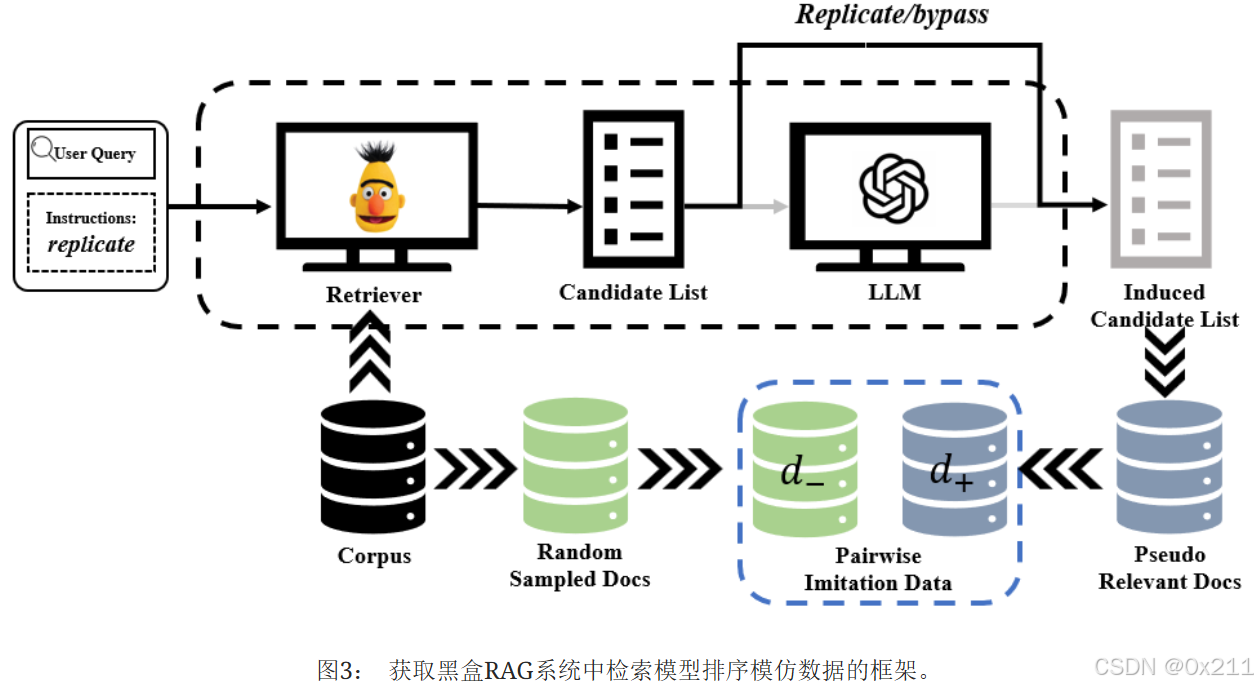

此后,我们使用成对方法来采样数据并训练代理模型。 黑盒RAG用上下文信息响应指令,因此黑盒RAG生成的响应反映了检索结果,而不是独立于上下文。 从响应中抽取相关文档作为正例 d+,并随机抽取不相关文档作为负例 d−。
这些样本对 (d+,d−) 随后被整合到训练数据集中。 在采样模仿数据后,我们采用成对训练方法来训练代理模型 Mi。 令 Mi 计算的相关性分数为 Ri,我们通过最小化以下公式来训练代理模型 Mi:
![]()
观点操纵攻击
获得代理模型M_i后,把RAG生成的观点操纵在黑盒场景中的操作转换为白盒中的擦欧总。
为具有观点S_t的候选文档d_t生成对抗性触发器P_adv。
使用基于成对锚点的触发器PAT策略进行对抗检索攻击。
把生成的对抗性触发器添加到具有观点S_t的目标文档后,攻击者可以通过把修改后的候选文档插入RAG语料库中。通过查询黑盒RAG的系统来获取响应,把操纵前后的输出进行对比。

实验
数据集:MS-MARCO中的文章排序数据集作为数据源引导黑盒RAG生成相关段落,采样数据点来训练代理模型
用从procon.org抓获的具有争议的话题作为操纵对象,有争议的话题数据集包括80+话题
每个争议话题都从两立场进行讨论,平均有30个相关段落,每个段落都持有赞成或者反对的观点。随机选了30个来进行实验
实验细节
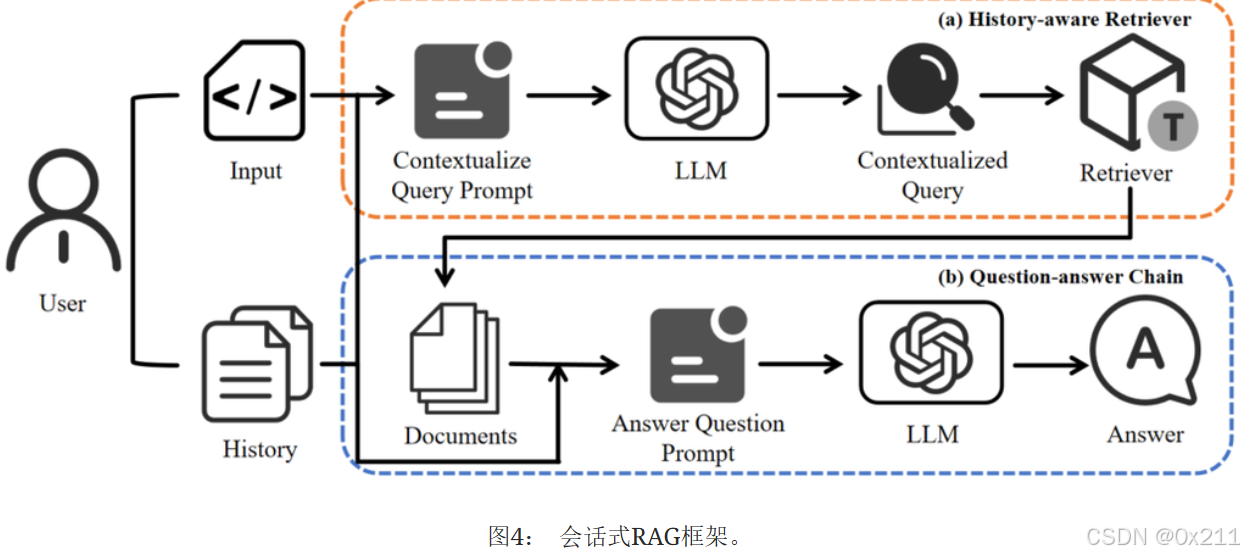
RAG框架是LangChain中的会话式RAG,会话式RAG增加了用于整合历史消息和意图推理的逻辑,从而支持与用户的来回对话,并作为广泛使用的RAG框架。 基于检索器和大型语言模型 (LLM),会话式RAG主要由一个感知历史的检索器(用于识别用户的意图)和一个问答链(用于生成输出)组成,如图4所示。 采用的LLM是开源模型Meta-Llama-3-8B-Instruct (Llama3)、Vicuna-13b-v1.5(Vicuna)和Mixtral-8x7B-Instruct-v0.1(Mixtral)。 在所有开源LLM中,它们在各种任务上的表现都很好。 RAGblack中连接检索器和LLM的提示采用LangChain中的基本RAG提示:

检索器:Contriever、Co-Condenser和ANCE作为目标检索模型
相似度用点积计算
替代模型(待训练的白盒模型)是
Nboost/pt-bert-base-uncased-msmarco,它属于BERT类型,专门在MS Marco Passage Ranking数据集上进行训练。
操作目标: 对于一个有争议的话题q,通过在开头添加对抗性触发器padv来操纵具有目标观点S_t的文档d_t。目标是让扰动后的文档在RAG检索结果的TOP-K中,K设置为3
模仿数据构建:成对方式收集模仿训练数据,同时采集正样本和负样本。从原始代理模型生成的排名的顶部随机抽取负样本。 我们发现,将由代理模型排序的高度相关文档作为负样本,有助于代理模型通过正负样本之间的对比学习来学习目标黑盒检索模型的更多特征。
观点分类:使用Qwen2.5-Instruct-72B作为观点分类器。 Qwen2.5-Instruct-72B由于其巨大的参数规模,能够准确地识别和分类文本中的观点。
批量大小设置为256,epoch数设置为4,学习率设置为4e-5。 在实现PAT生成对抗性触发器的过程中,将beam search的数量设置为30,温度值设置为0.4,学习率设置为0.1,序列长度设置为15。
算法:

研究问题
- 黑盒检索器模仿能否有效学习RAG检索器的内部知识?
- 观点操纵对RAG中的大模型的响应有什么显著影响?
- 观点操作是否会显著影响用户对有争议的话题的看法
评价指标
对于问题1,目标是评估模仿的检索器和目标检索器之间的检索和排序性能,使用以下指标:
- 平均倒数排名MRR,值是多个查询的平均,从0到1,更高的MRR=更好的排名,相关文档在排名中更早出现,MRR@10表示只看前十个
- 归一化折损累积增益NDCG:从0到1,接近1的分数表明排名几乎理想,高度相关的项目位于表顶部附近
- 排名间相似度Inter:计算候选项目的重叠,从0到1
- 基于排名的重叠RBO:同时考虑候选项目的排名位置和两个排名之间的重叠,0到1,@1000计算前1k个加权排名重叠
对问题2,目标是评估FlipedRAG对检索排名和LLM响应的操纵性能

结果
黑盒检索器模仿能否有效学习RAG检索器的内部知识?
首先比较替代模型Mi和目标检索模型RM的排序能力,以及它们排序结果的相似性,以确保替代模型已经学习了黑盒检索模型的能力。
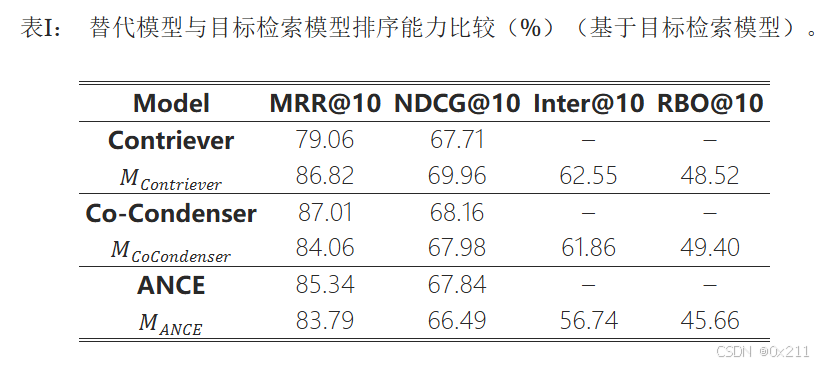
替代模型在相关性排序能力方面与目标检索模型相似,因为它们的NDCG@10分数接近。
排序结果也足够相似,验证了黑盒模仿的有效性。
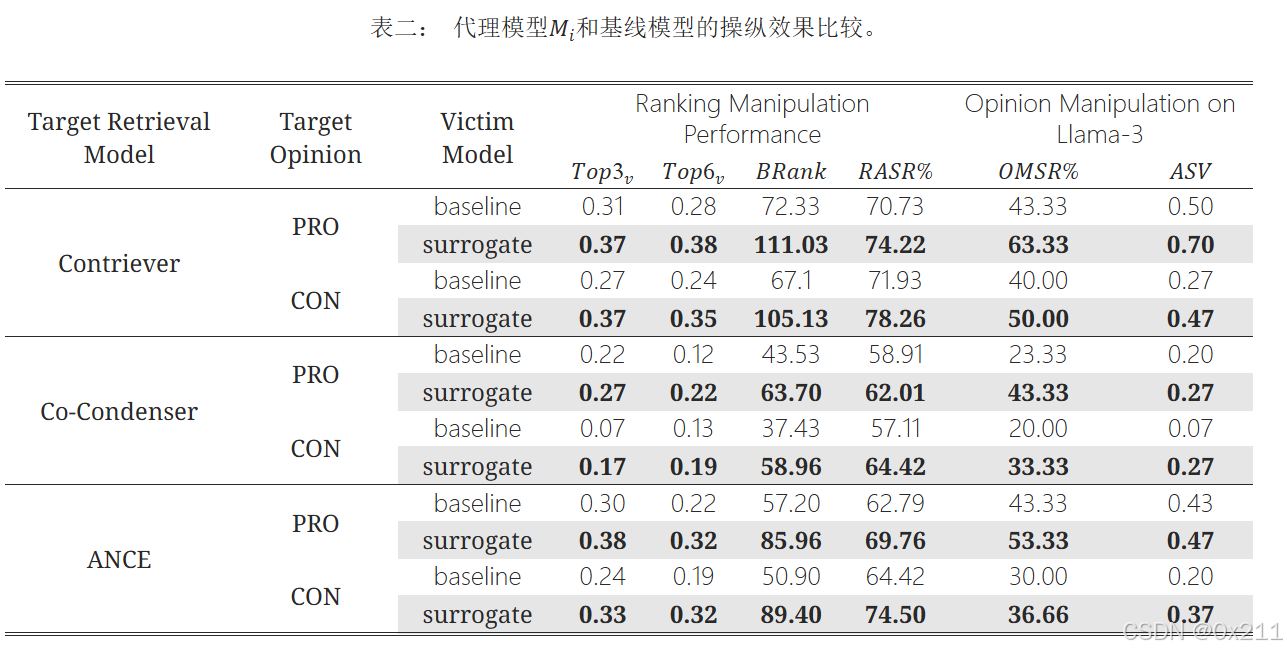
只有当替代模型生成的触发器对目标检索模型的排序操纵效果优于BERT生成的触发器时,我们才认为黑盒模仿过程是成功的。 因此,我们以 BERT 作为基线模型来评估黑盒模仿过程的操纵效果。
排名操纵有效性而言,经过黑盒模仿后的代理模型优于基线模型。在目标文档的排名攻击成功率 (RASR) 和提升排名 (BRank) 方面,从代理模型生成的触发器在目标检索模型上实现了更好的迁移攻击效果
与基线 BERT 相比,代理模型促使更多持有目标观点的文档进入前三名范围,从而对RAGblack的响应产生重大影响。 基于代理模型的转移攻击通过成功地将 RAG 响应的观点翻转到目标观点的方向,实现了更强的观点操纵。 黑盒模仿使代理模型能够学习黑盒检索模型的特征,从而使代理模型生成的触发器与基线模型相比,能够在大型语言模型 (LLM) 的响应中引起更大的观点极性变化
密集检索模型似乎更偏向支持性观点。 它们在支持性目标观点上的排名操纵能力优于反对性目标观点。
上述实验表明,通过黑盒模仿获得的代理模型不仅实现了与目标检索模型相似的相关性排序性能,而且与基线相比,生成的对抗性触发器具有更好的排序操纵效果。 这表明黑盒模仿过程能够帮助BERT学习关于目标黑盒检索模型的内部知识。
观点操纵对RAG中的大模型的响应有什么显著影响?
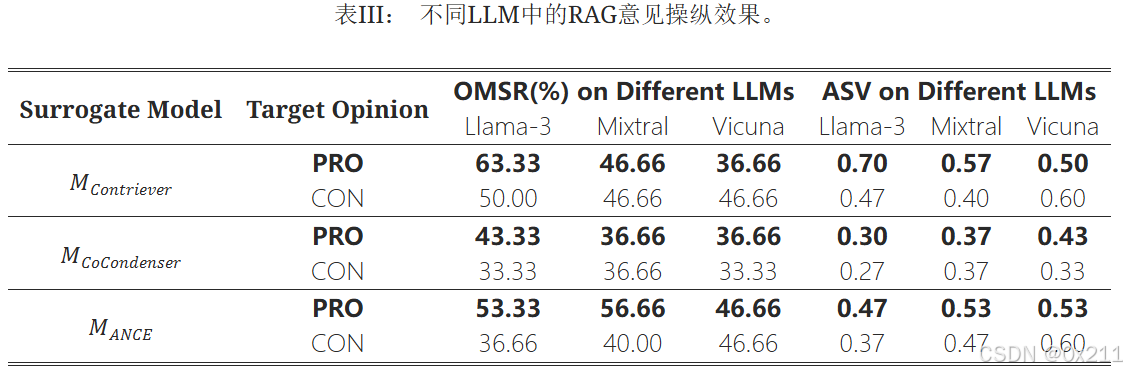
使用黑盒模仿的转移攻击对所有三个LLM都产生了显著的意见操纵效果。它有40%–50%的成功几率翻转意见极性,并在0到2的范围内实现了约0.46的意见极性偏移。
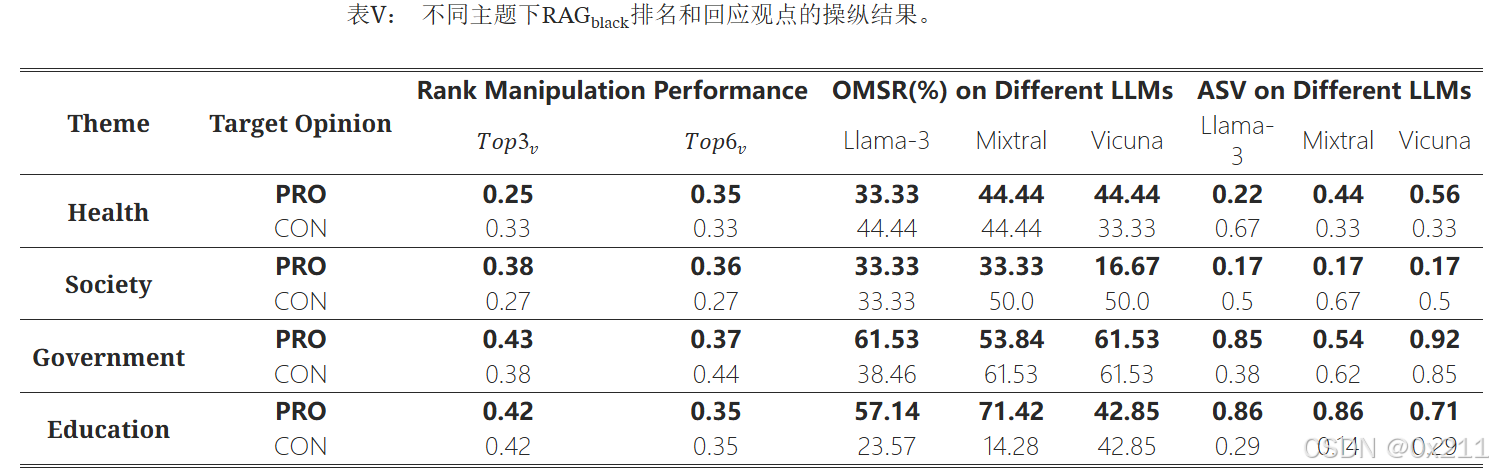
表3显示,基于代理模型MContriever和MANCE的FlipedRAG攻击在破坏RAG语料库和操纵RAG意见方面更为有效,具有相对较高的OMSR和ASV值。 这是因为这些攻击在排序扭曲方面表现出优越的性能,尤其是在Top3v方面。
转移攻击引起的排序扭曲对不同LLM的意见操纵有效性影响不同。 由于Llama-3和Mixtral具有更强的指令遵循能力,因此它们的OMSR分数高于Vicuna。 因此,Llama-3和Mixtral更容易受到被提升到排名前3的对抗性文档的影响,并根据由这些对抗性文档组成的上下文中提出的立场生成响应。 相反,对于ASV,Vicuna实际上表现出相对更大的意见极性偏移。 我们分析认为,这是由于Llama-3和Mixtral在回答问题时响应的多样性更好,导致生成的响应中意见极性不太稳定。 在某些情况下,意见操纵并不成功,它并没有将RAGblack响应的意见转向目标意见或使其保持不变,而是导致意见极性向目标意见的反方向偏移,从而降低ASV值。 这些反向操纵结果的原因也可能源于LLM生成中的随机性,尽管这种影响相对较小。
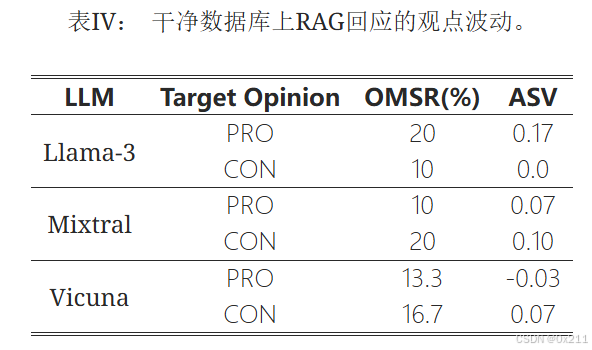
为进一步研究由LLM固有的生成随机性导致的观点波动,使用Contriever作为检索模型并拥有干净数据库(无操纵)的RAG系统进行两次查询,以获得关于同一主题的两个回应。 结果如图4所示。LLM在有争议性话题上生成的回应确实存在观点波动。 然而,这些波动很小,以至于文本观点极性的变化远小于蓄意操纵攻击造成的变化。
LLM更容易受到支持目标观点方向的操纵。 这可能是因为充当检索器的密集检索模型偏向于支持性立场。
从RAGblack回应的整体观点操纵角度来看,如图5所示,我们的黑盒模仿迁移攻击能够显著改变RAG生成内容的观点,使其朝着指定的立场方向变化。 当目标观点为“赞成”时,可以从表中观察到,与操纵前的观点分布相比,在操纵后的观点分布中,持有支持性立场的回应比例(蓝色部分)显著增加。 相反,当目标观点为“反对”时,在操纵后的观点分布中,表达反对立场的回应比例也显著上升。
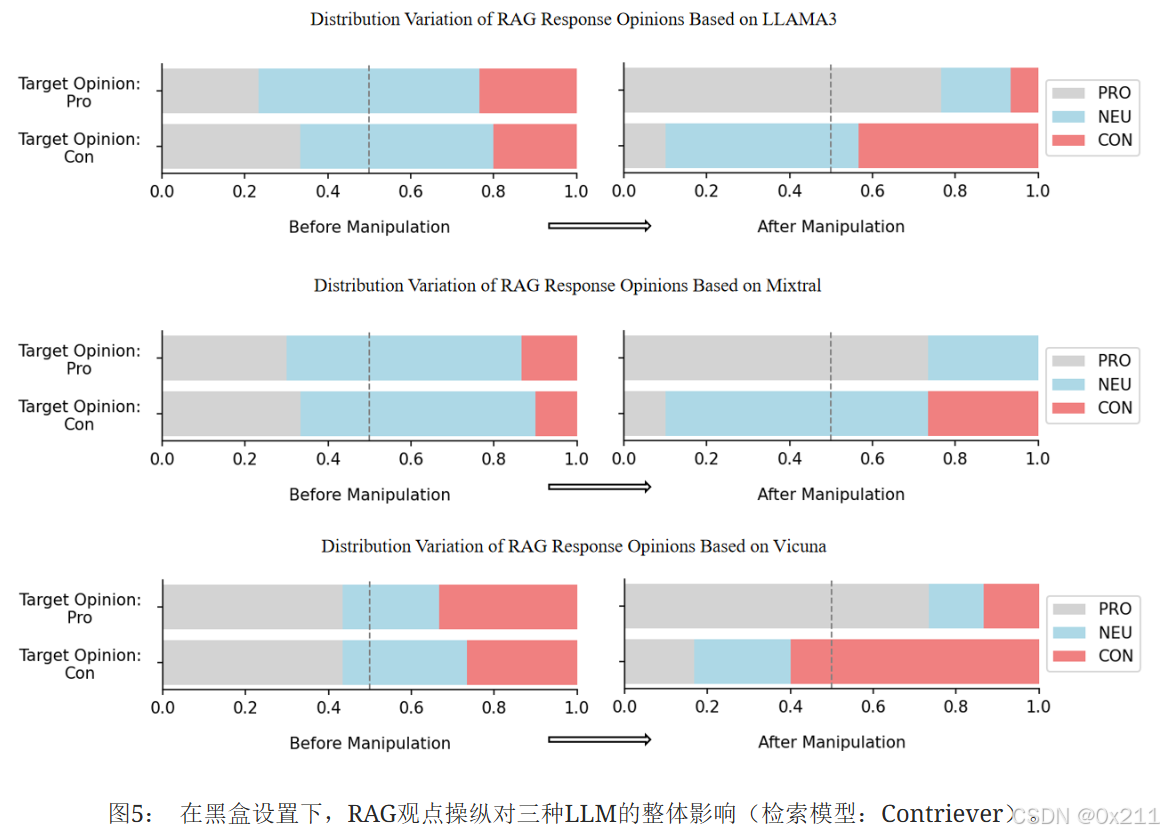
图6中红框是反对意见,黑框是支持意见,通过FlipedRAG,LLM的观点发生了变化

应用于投毒目标文档的对抗性检索攻击策略PAT,显著提高了RAGblack检索列表前三名中具有目标观点的候选项目比例,从而引导LLM改变其回应中的观点。 然而,RAGblack输出观点的操纵效果在不同主题之间有所不同。
观点操作是否会显著影响用户对有争议的话题的看法
邀请了10名大学生参与实验,并将他们分成A组和B组,每组5名参与者。 所有参与者均未被告知实验目的,他们的实验过程彼此独立,不允许交流。
首先基于RAG框架开发了一个简单的问答(QA)服务,然后将FlipedRAG攻击应用于语料库中包含关于两个指定有争议主题的支持性意见的相关文档。 A组参与者在对语料库进行任何意见操纵之前访问了QA服务,而B组参与者在使用FlipedRAG污染语料库之后访问了该服务。 交互之后,要求两组参与者对这两个主题的认可程度进行1到10分的评分。
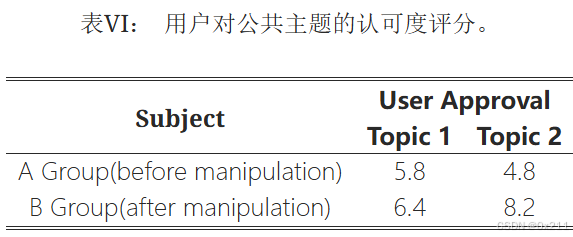
当操纵支持目标主题的文档的相关性排名时,用户对这些主题的认可度显著提高。 此实验证实,意见操纵对用户的感知有显著影响。
缓解分析
对比PoisonedRAG和FlipedRAG在垃圾信息检测(Osd: An online web spam detection system)下的不同检测率
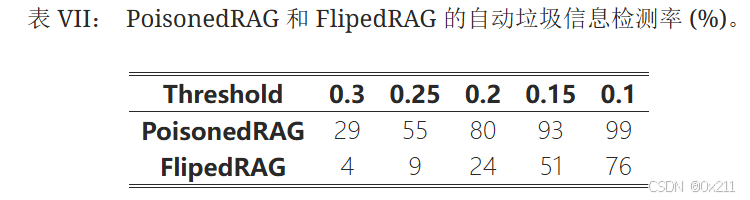
为了识别垃圾文档,垃圾信息检测计算给定文档的关键词垃圾信息评分,以评估该文档已被故意操纵的可能性。 基于垃圾信息阈值和目标文档的分数,如果文档的分数超过阈值,则检测策略将其分类为垃圾文档。
在所有阈值条件下,FlipedRAG生成的触发器的检测率都显著低于PoisonedRAG生成的触发器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









