







ARL2: Aligning Retrievers with Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
ACL 2024
RAG中的检索器的训练过程是单独的,并且LLM通常是黑盒的,导致检索器和LLM不匹配。因此提出了ARL2,一种利用LLM作为标签器的检索器学习技术,ARL2利用LLM来注释和评分相关性证据,从而能够从强大的LLM监督中学习检索器。
当前检索器存在的问题:检索出来的结果可能相关,但是对回答问题没有一点用。
一些研究的解决方案:检索器和LLM的联合训练,但是需要从新开始训练LLM,成本太高,不切实际。RePlug利用答案的语言建模分数作为代理信号来训练密集检索器。然而,这种对检索器训练的监督是间接的,并且可能不够有辨别力,特别是当问题可以通过LLM的参数知识直接回答时。
本文提出ARL2,该方法通过利用大语言模型的指导自引导自适应相关性标注。与现有依赖通过注意力或基于答案的语言建模分数进行间接监督的方法不同,ARL2 利用大语言模型直接评估文档相关性的能力,生成高质量的相关性标签,以训练更优的检索器。
使用大语言模型标注的相关性标签来训练检索器具有三个优点。首先,ARL2 能够有效地从相似但不相关的文档中区分出真正有用的文档,为训练提供有价值的正样本和难负样本。其次,它能够创建超越单一目标数据集的多样化训练数据,克服了像 RePlug 等方法的局限性。第三,ARL2 可以从未标记文档中反向生成多样化的问题,增强数据多样性,并有助于在具有挑战性的少样本或零样本场景下实现有效的泛化。
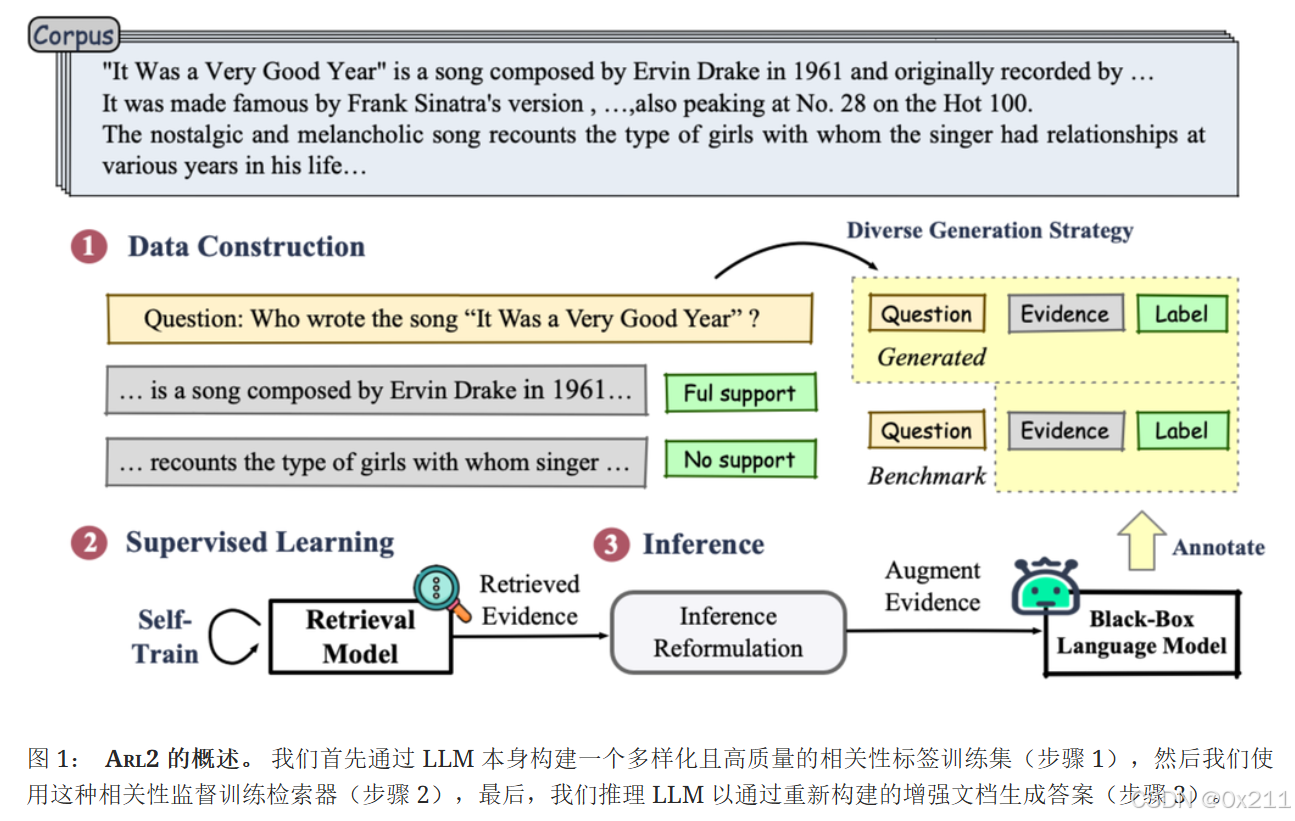
为了降低因频繁调用大语言模型进行相关性标注而产生的数据整理成本,我们提出了一种自适应自训练策略。该策略使检索器能够识别并标记置信度高且训练良好的数据点,减少对昂贵的大语言模型交互的依赖。此外,我们引入了一种基于聚类驱动的提示示例度量方法,以确保构建的数据具有多样性和高质量。这使得我们能够从少量高质量且多样化的标注数据中学习到强大的检索器。
相关工作
RAG 已广泛应用于语言建模(Borgeaud 等人,2022; Ram 等人,2023)、问答(Lewis 等人,2020; Izacard 等人,2022b; Shi 等人,2023b)和领域适应(Xu 等人,2023a,b; Shi 等人,2023c)。
为了使检索器与大语言模型对齐,大多数 RAG 方法将预训练的检索器与生成器集成,然后进行端到端的微调过程以有效地捕获知识(Lewis 等人,2020)。其中,Atlas(Izacard 等人,2022b)将检索到的文档作为潜在变量,并使用四种设计的损失对检索模型进行微调。AAR(Yu 等人,2023c)通过 FiD 交叉注意力分数(Izacard 和 Grave, 2021)识别大语言模型偏好的文档,并使用难负样本采样对检索器进行微调。然而,这些方法不适用于黑盒大语言模型,因为它们需要访问大语言模型的参数。
唯一的例外是 RePlug(Shi 等人,2023b),它通过评估检索到的文档和大语言模型可能性的概率分布之间的 KL 散度来进行有监督的训练。
方法
需要解决的两个关键:如何有效地利用大语言模型构建一个多样化且高质量的相关性标签训练集?如何使用提供的相关性监督来训练检索器,并进一步利用检索器为自适应的大语言模型标注提供信息?
数据构建
利用大语言模型为每个问题的证据有用性提供直接的监督信号。

通过编译各种语料库,如 WikiPedia和 MS MARCO,来构建语料库 𝒟。 对于 𝒟 中的每个文档 d,我们通过一个三步过程生成一个训练元组:问题生成、证据识别 和 证据评分。 此过程产生一个包含 100,000 个带注释实例的数据集,表示为 𝒯g。 此外,我们从 QA 基准中整理了 140,000 个数据实例 𝒯b。 这两个数据集的组合形成了完整的数据集 𝒯。
1.问题生成
使用 ChatGPT(gpt - 3.5 - turbo - 0613)进行问题生成,从语料库d∈D中的文档生成格式为(q,e)的对。这个过程涉及向大语言模型阅读器提供一个特定的提示,即 “仅根据以下信息,按照示例,提出一个我们可以根据给定段落回答的事实性问题”,并提供示例以引导上下文学习。
多样化的生成策略: 生成问题的质量在很大程度上依赖于所选文档和提供的问题示例。通常,生成的问题会遵循与给定示例相似的模式。这里的问题模式指的是问题的句子结构,如特殊疑问句、是非疑问句和陈述句。为了提高构建数据的质量,我们采用了多样化选择策略。
首先,我们从Tb(数据)中选择与目标文档具有相同或相似领域的相关问题qr。其次,我们根据问题模式对Tb中的问题进行聚类,并从不同的簇中选择多个问题模式来生成多样化的问题。为了促进多样化和高质量的问题生成,我们屏蔽问题中的实体提及,以专注于其核心结构。然后,每个屏蔽后的问题被映射到一个句子嵌入中,并使用 ISODATA(Ball 等人,1965)(K - 均值的一种变体)进行聚类。这使得生成的问题不仅多样化,而且质量高。
2.支持证据标注
证据识别:对于 𝒯b 中的每个数据点 (qi, di, ei),我们分配一个支持级别标签 s 来指示证据 ei 与问题 qi 的相关性。 如果 (qi, di, ei) 是直接从人工标注者那里获得的,我们设置 s 为 “完全支持”。 否则,我们使用 ChatGPT 作为标注者来获取支持级别标签。 具体来说,我们向 ChatGPT 提供问题 qi,文档 di,以及从文档中提取支持证据的指令。 然后,ChatGPT 返回提取的证据及其与问题相关性得分。
证据评分:除了具有 “完全支持” 标签的正样本外,我们还创建负样本用于训练检索模型。 对于每个正样本 (qi, di, ei),我们通过从相同文档 di 或从内容或领域与 di 相似其他文档中选择证据片段,构建一个具有挑战性的负样本集 𝒩i。 我们使用 SimCSE Gao et al. (2021),一个句子嵌入模型,将 𝒩i 中的每个证据片段嵌入。 然后,我们根据它们余弦相似性得分,识别出与 ei 语义上最相似的 top-k 个证据片段。 最后,我们要求 ChatGPT 对这些 top-k 个证据片段与问题 qi 的相关性进行标注。 我们丢弃标记为 “完全支持” 的证据片段,并保留标记为 “部分支持” 或 “不支持” 的证据片段作为负样本。

检索模型学习
在 ARL2 中,我们从上述 <问题,证据,相关性分数> 实例中训练一个密集检索器。为了增强检索器的学习,设计了结合难负样本采样的成对损失和列表损失。此外,为了降低 ChatGPT 标注的成本,我们提出了一种自训练策略来提高效率。
1.密集检索器
用检索器中的encoder分别把问题和文本数据映射到向量嵌入空间中,为了提高效率,提前把文本数据的全部向量获取了,构建了一个FAISS索引
2.密集检索器的学习目标
训练使用排名损失。

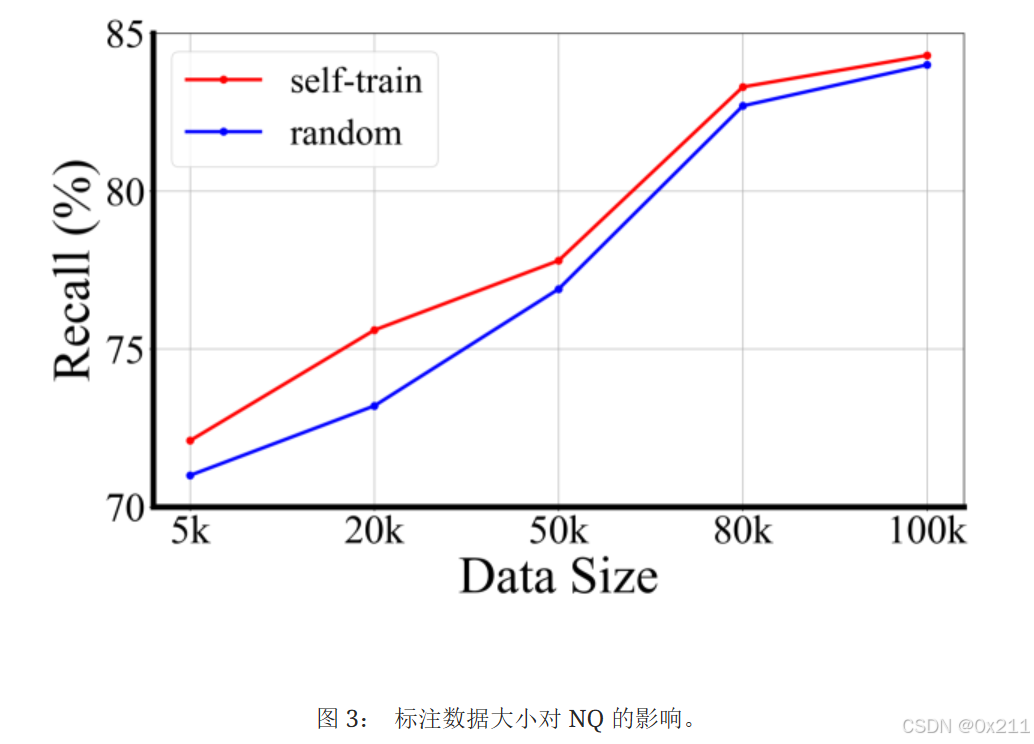
负采样:上述学习目标的另一个重要方面是如何为每个查询q挖掘负样本N。文章提出一种多步自训练策略,逐步提供“更难”的负样本来有效训练检索器。最初,使用批量内的负样本作为热身来启动检索器训练。然后选择 “部分支持” 的文档作为两种损失的难负样本,进一步进行模型训练。与使用随机选择或 BM25 选择的负样本相比,这种先进的负采样策略显著提高了检索器的性能
3.自适应相关性标注

推理
 方法的人话版本
方法的人话版本
1. 让大模型教检索器 "什么有用"
目标:让检索器学会像大模型一样判断哪些文档对回答问题有帮助
方法:
用 ChatGPT 生成训练数据:
给 ChatGPT 一个文档段落,让它生成相关问题(比如文档讲 "某首歌的创作背景",GPT 生成问题 "这首歌是谁写的?")。
同时,GPT 会给每个问题的答案片段打分:
- 1 分:完全支持(直接包含答案)
- 0.5 分:部分支持(相关但不完整)
- 0 分:不支持(无关内容)
多样化问题生成:
避免生成重复问题,通过聚类技术(类似给问题按句式分类),确保生成的问题覆盖不同类型(如 "谁 / 什么 / 何时 / 哪里")。2. 训练检索器:像学生一样学习老师的判断
目标:让检索器学会根据问题找到最可能被 GPT 打高分的文档
方法:
双编码器结构:
用两个 BERT 模型分别编码问题和文档,计算它们的向量相似度(类似比较两个句子的 "语义距离")。损失函数设计:
- 列表损失:让检索器把完全支持的文档排在前面,部分支持的次之,无关的最后。
- 成对损失:确保完全支持的文档得分高于部分支持,部分支持高于无关文档。
自训练策略:
- 先用少量 GPT 标注的数据训练检索器
- 让检索器自己从海量文档中 "挑出" 它认为最可能有用的片段(置信度高的),作为新训练数据
- 只有当检索器对某类问题不确定时,才再次调用 GPT 标注,降低成本
3. 优化推理:让大模型更容易找到答案
目标:解决 LLM 在长文本中 "中间信息丢失" 的问题
方法:
重新排列检索结果:
把最相关的文档放在开头或结尾,中间放次相关的(因为 LLM 对首尾更敏感)。
例如:最相关 → 次相关 → 中间相关 → 次相关 → 最相关集成多个排列结果:
生成多个不同顺序的文档组合,让 LLM 分别处理后取平均结果,提高鲁棒性。关键创新点总结
用大模型直接标注数据:
让 LLM 扮演 "老师" 角色,明确告诉检索器哪些文档有用,解决传统检索器与 LLM 需求不匹配的问题。自训练降低成本:
检索器通过 "自学" 减少对昂贵 GPT 标注的依赖,仅在不确定时才求助 GPT。动态数据增强:
不仅用现有数据,还反向生成新问题,确保训练数据覆盖更多场景,提升模型泛化能力。类比理解
假设你要训练一个搜索引擎(检索器),但不知道用户的真实需求。于是:
- 让专家(GPT)帮忙标注哪些网页对特定问题有用。
- 先用专家标注的数据训练搜索引擎。
- 让搜索引擎自己尝试搜索,遇到不确定的结果时再请专家确认。
- 最终,搜索引擎能像专家一样理解用户需求,甚至帮专家减少工作量。
这样,搜索引擎既学到了专家的判断标准,又通过自我迭代变得更高效。
实验
实验设置
数据集:NQ,TQA和MMLU
文档语料库:包含300k个问答对的语料库,包括来自MS的880万个段落和来自危机百科的2100万个段落。
基准:传统的联合训练方法(RETRO,UnifiedQA和Atlas)基于LLM的方法(提示LLM生成问题的答案)。代表性LLM:Chinchilla、Palm。ChatGPT、codex、GenRead。RAG方法:contriever、Replug、DPR
评估指标:召回率 Recall@Top-k(k=10、20)衡量答案是否与Top-k检索到的段落中的文本跨度匹配。整体精度使用Acc
实验结果
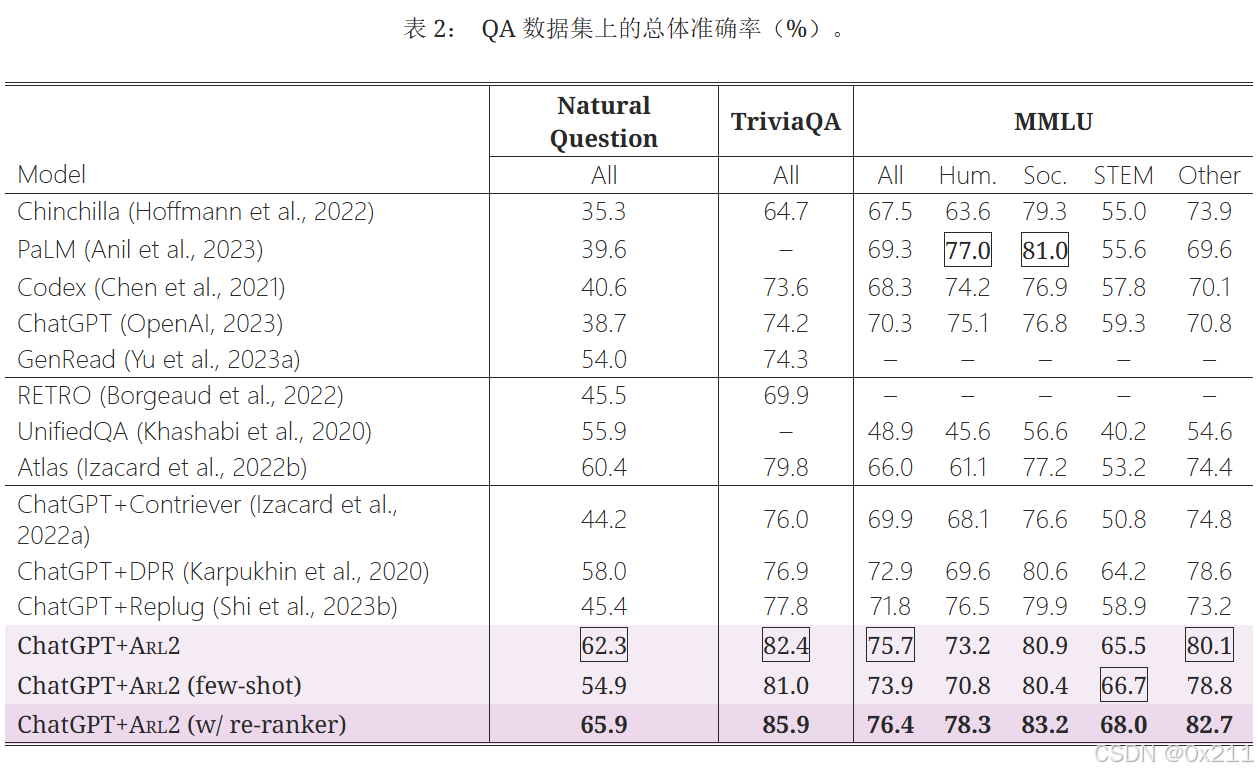
粗体表示最佳性能,下划线表示第二好性能。
结论:ARL2训练的检索器可以增强LLM;ARL2优于其他的检索方案
迁移和泛化能力
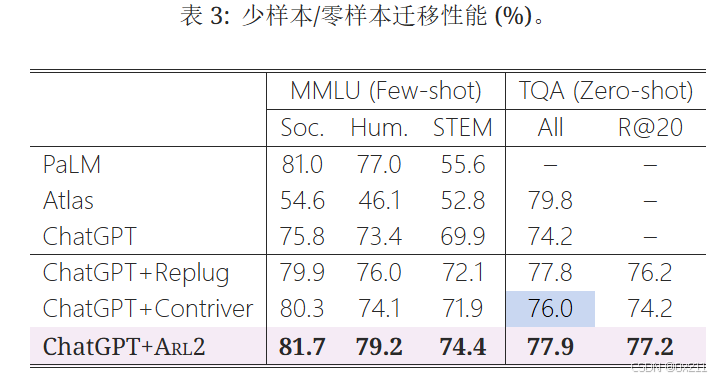
消融
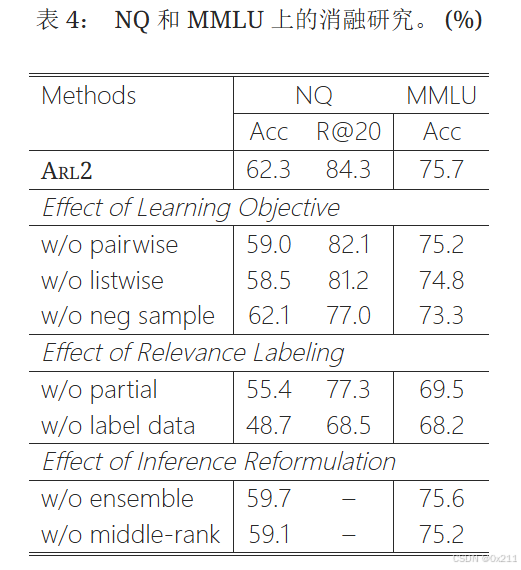
结论
介绍了 Arl2,这是一种检索增强框架,利用 LLM 作为标注器来进行检索器学习。 与由于单独的训练过程和 LLM 的固有复杂性而面临错位的传统方法不同,框架动态地利用 LLM 来注释和评估相关证据。 这使得检索器能够从强大的 LLM 监督中获益。 此外,还整合了一种自训练策略来减轻与 API 调用相关的成本。 通过大量的实验证明了 Arl2 的有效性,它提高了开放域问答任务的准确性,展现出强大的迁移学习能力,并具有强大的零样本泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









