







Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
http://arxiv.org/abs/2410.07176
总结:没有什么实质性的开发,只是在提示词上下了功夫,让RAG在最终决策生成答案之前过一轮设定好的prompt
摘要
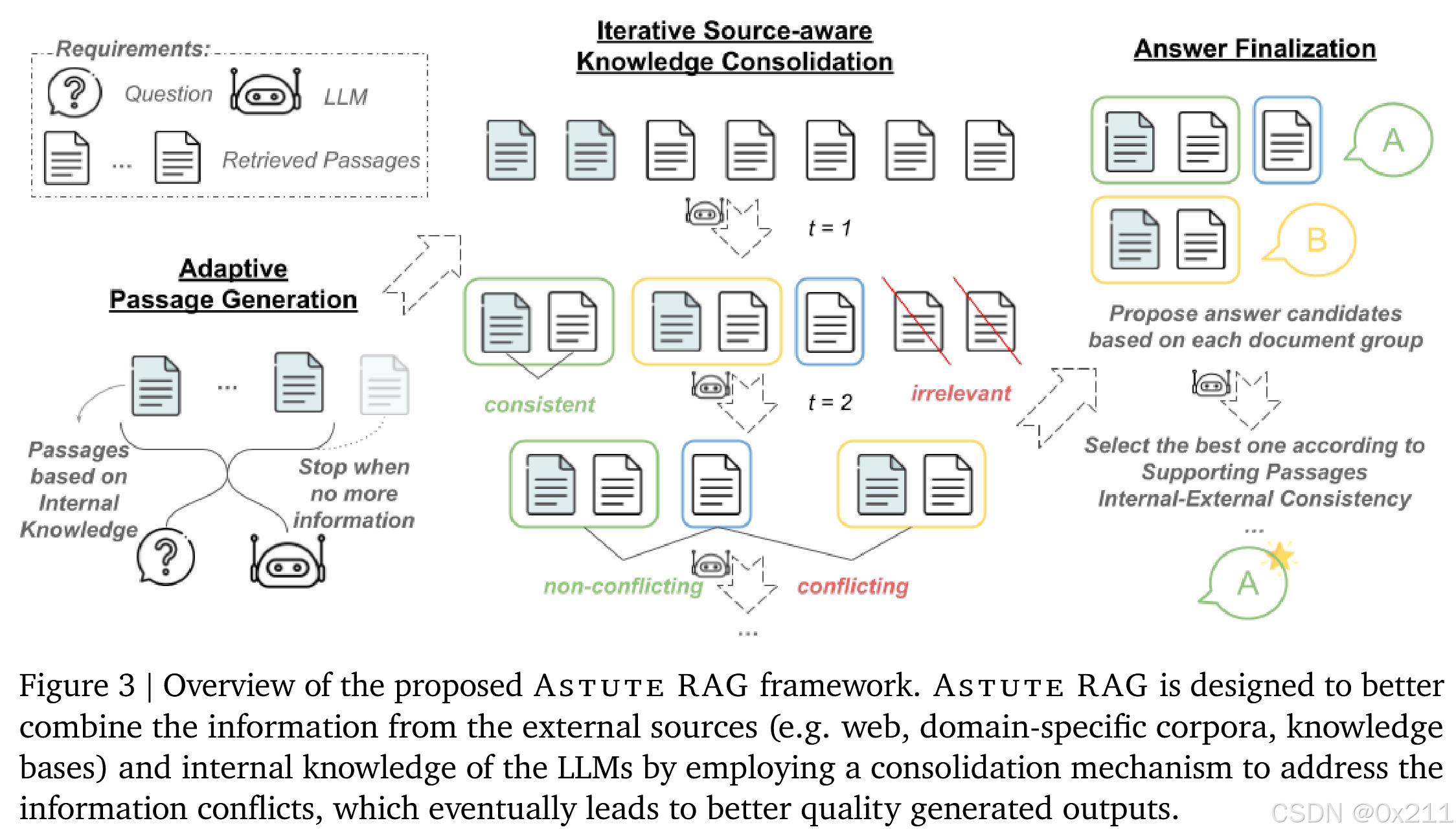
检索增强生成(RAG)虽然能有效地整合外部知识以解决大型语言模型(LLMs)的局限性,但可能会被不完善的检索所破坏,因为不完善的检索可能会引入无关、误导甚至恶意的信息。尽管 RAG 非常重要,但以往的研究很少通过联合分析来探讨 RAG 的行为,即不完善检索造成的错误是如何归因和传播的,以及 LLMs 的内部知识和外部资源之间是如何产生潜在冲突的。通过在现实条件下进行对照分析,我们发现不完善的检索增强可能是不可避免的,而且相当有害。我们将 LLM 内部知识与来自检索的外部知识之间的知识冲突确定为 RAG 后检索阶段需要克服的瓶颈。为了使 LLM 能够抵御不完善的检索,我们提出了 Astute RAG,这是一种新颖的 RAG 方法,它能自适应地从 LLM 的内部知识中获取基本信息,通过源感知迭代整合内部和外部知识,并根据信息可靠性最终确定答案。我们使用 Gemini 和 Claude 进行的实验表明,Astute RAG 明显优于之前的鲁棒性增强 RAG 方法。值得注意的是,在最坏情况下,Astute RAG 是唯一能达到或超过无 RAG 的 LLM 性能的方法。进一步的分析表明,Astute RAG 能有效地解决知识冲突,从而改善了 LLM 的性能。
也就是说,Astute RAG在检索到的结果中不包含有用信息甚至包含了错误信息时,能够达到LLM本身的性能(利用内部信息),这还是很厉害的,因为RAG系统很容易被检索到的结果误导。
不完美检索:RAG的陷阱
为了更好地展示常见的现实挑战并更好地激励改进方法设计,我们在一组受控数据上评估检索质量、端到端 RAG 性能和知识冲突。选定的数据包括来自 NQ、TriviaQA 、BioASQ 和 PopQA 的各种一般、特定领域和长尾问题。我们的分析基于真实的检索结果,其中 Google Search(https://developers.google.com/custom-search/v1/overview) 作为检索器,Web 作为语料库。此设置允许我们分析真实世界 RAG 中不完美检索的严重性。总体而言,我们从这些数据集中抽取了 1K 个简短的 QA 实例,并将每个实例与 10 个检索到的段落配对。
不完美的检索很常见
我们研究了正确答案在检索段落中的出现率,以此作为检索质量的近似值。由于我们主要关注的是短式问答,它为每个问题提供了正确答案的大多数变体,因此通过字符串匹配的近似值可以让我们对检索结果的精确度有一个粗略的直观认识。具体来说,我们将检索精度定义为每个实例中包含正确答案的段落比例:
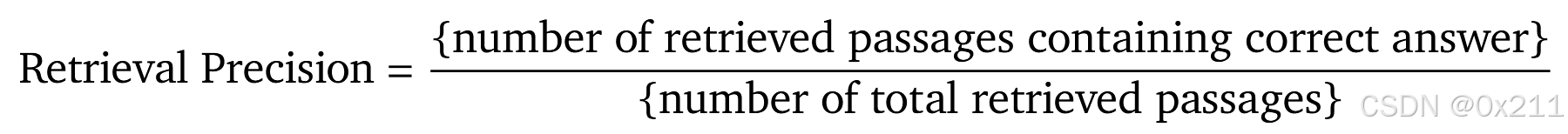
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









