



 本文详细介绍了MySQL的事务处理,包括事务的四大特性ACID、并发事务可能导致的问题(脏读、不可重复读、幻读)及其解决的隔离级别。此外,还深入探讨了存储引擎,如InnoDB、MyISAM和Memory的特点与区别。同时,讲解了索引的原理,如B+Tree、Hash索引,以及如何创建、使用和优化索引,以提高查询性能。
本文详细介绍了MySQL的事务处理,包括事务的四大特性ACID、并发事务可能导致的问题(脏读、不可重复读、幻读)及其解决的隔离级别。此外,还深入探讨了存储引擎,如InnoDB、MyISAM和Memory的特点与区别。同时,讲解了索引的原理,如B+Tree、Hash索引,以及如何创建、使用和优化索引,以提高查询性能。
目录
如果一个事务还没提交,那么它中间产生的数据变化会不会在未提交之前写入磁盘
一、事务
1.事务简介
2.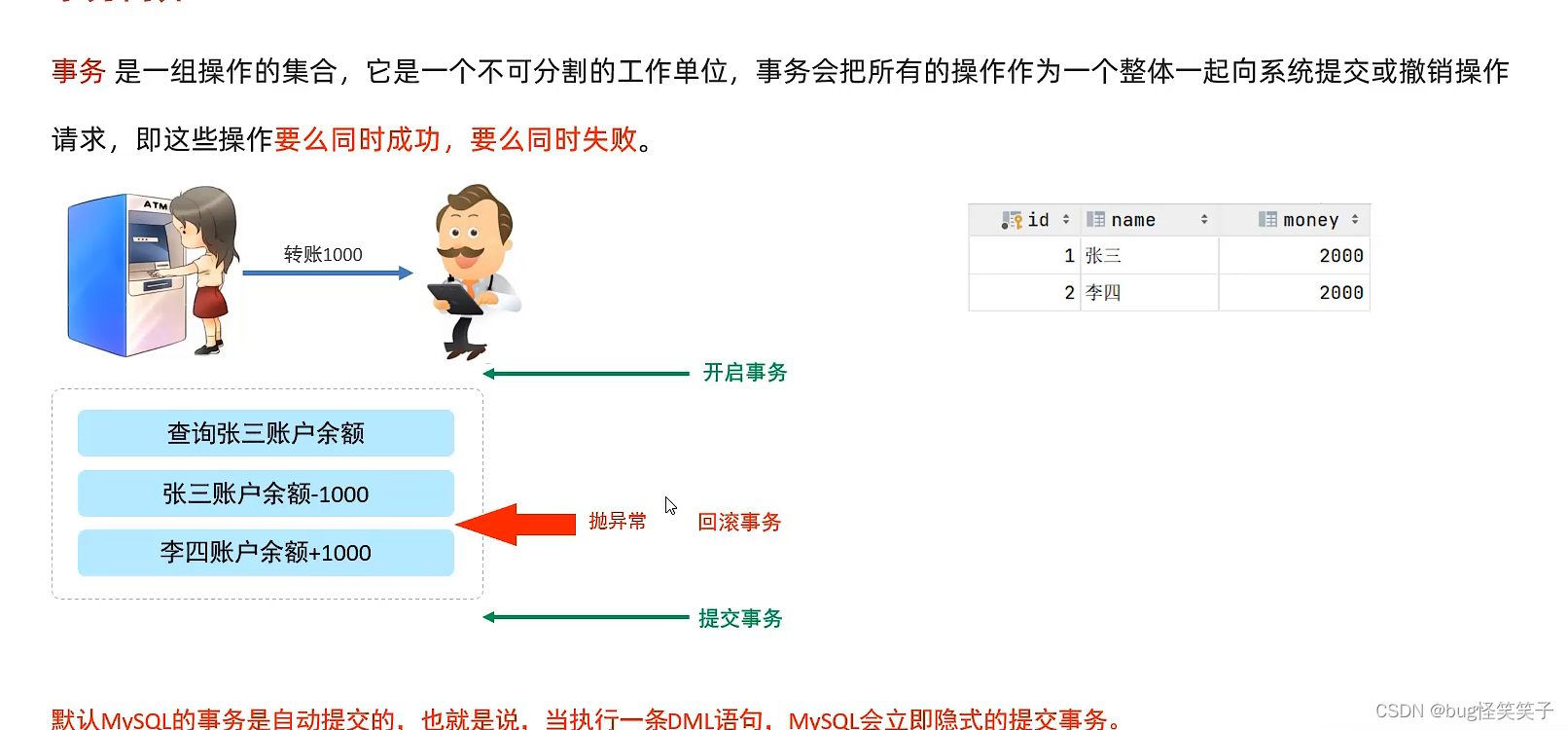
2、实务操作
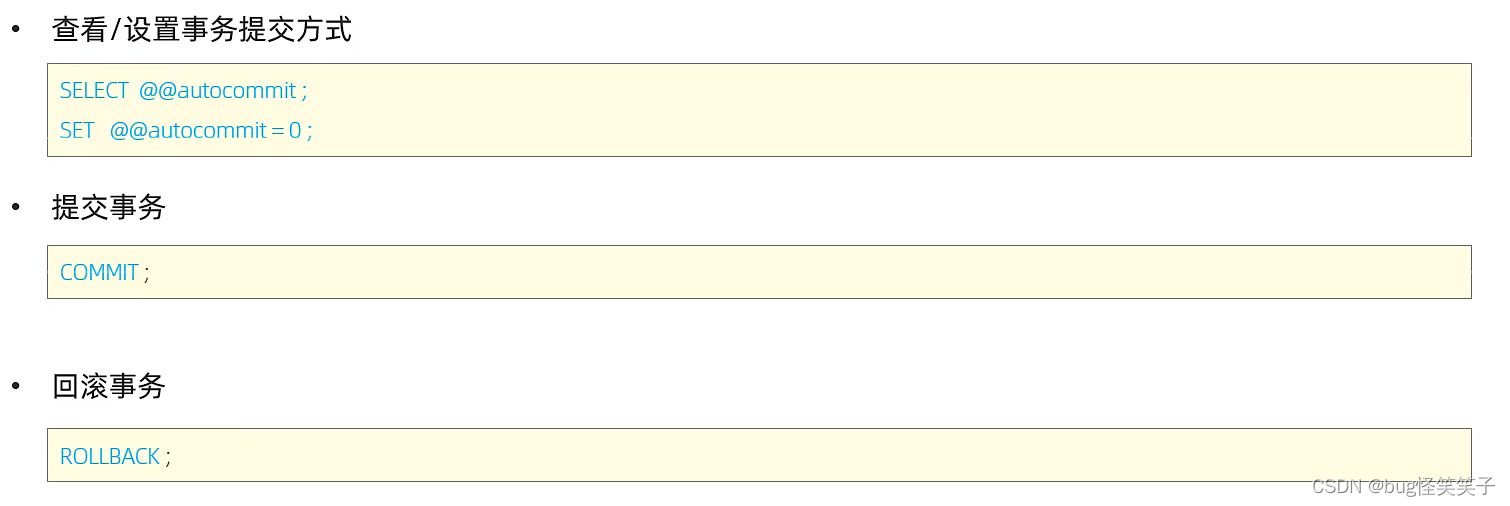
<1>select @@autocommit查看事务提交方式
<2>set @@autocommit设置事务提交方式
set @@autocommit = 0;显示事务提交
<3>commit 提交事务
<4>rollback 回滚事务
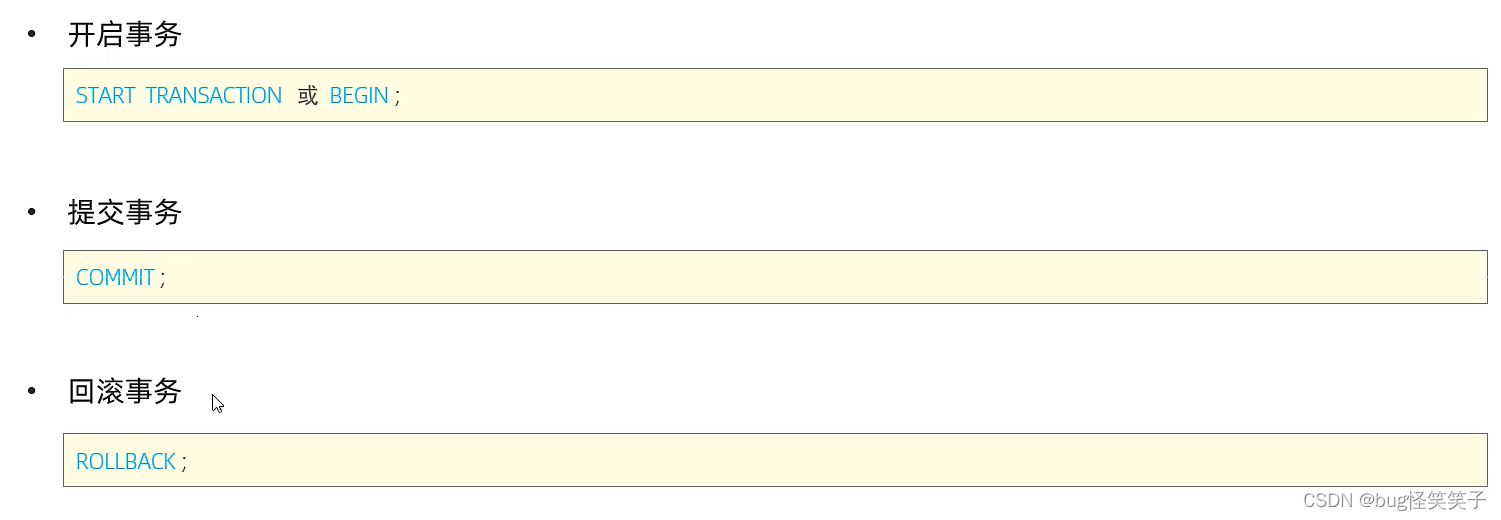
方式一
<5> start transaction 开启事务
方式二
 3、四大特性ACID
3、四大特性ACID

4、并发事务问题

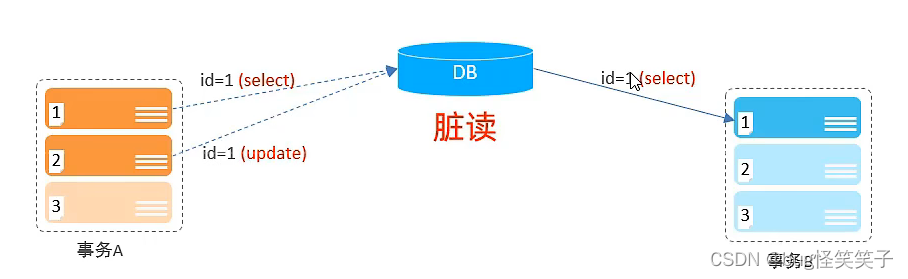
<1>脏读
如果一个事务还没提交,那么它中间产生的数据变化会不会在未提交之前写入磁盘
1、如果一个事务还没提交,那么它中间产生的数据变化会不会在未提交之前写入磁盘呢?
回答:
会,写入不写入磁盘和提交没提交没有关系
commit 不一定会写磁盘哦,要等到dwr进程的时候才会写入磁盘吧,但commit一定会写人redo
一个事务 commit 并不是把数据写到数据文件中,而是写到联机 重做日志文件中
脏读:事务A有很多操作,有一个操作为,修改id=2的数据,此时数据库的表结构已经发生变化,但是事务A还没结束,此时事务B就查询所有,此时就查到了已经变化的id=2的数据。这就是脏读。
-----------------------------------------------------------------------------------------------------------------------------
引用其他作者< 脏读指事务A读取到了事务B更新了但是未提交的数据,然后事务B由于某种错误发生回滚,那么事务A读取到的就是脏数据。
具体的说,一个数据原本是干净的,但是事务B将它进行修改使得其不再干净,此时事务A读取到事务B修改后的数据,也就是脏数据,称为脏读,后来事务B由于良心发现又将数据回滚为最初的样子,而事务A不知道事务B进行了回滚操作,最终事务A读取到的是脏数据,称为脏读。

————————————————
版权声明:本文为优快云博主「好运的云」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/HeyYun/article/details/108412027 >
<2>不可重复读
事务A刚执行完查询id=1的数据,然后事务B修改了id=1de数据并且提交了,然后紧接着事务A在后续操作时又执行了查询id=1的操作,结果发现和第一次查询到的不同。这就是不可重复读。

<3>幻读
前提:DB里确实没有id=1的数据。
事务A查询id=1的数据,发现没有,与此同时事务B执行插入id=1的数据的sql,此时数据库里有了id=1的数据,事务A继续进行并且执行插入,发现数据库里id=1的地方有数据,然后事务A继续执行查询,发现id=1没有数据(原因是解决了不可重复读的并发问题,前后查询的数据在事务没有进行增删改操作的情况下,查处的数据必须相同)这种情况就是幻读。
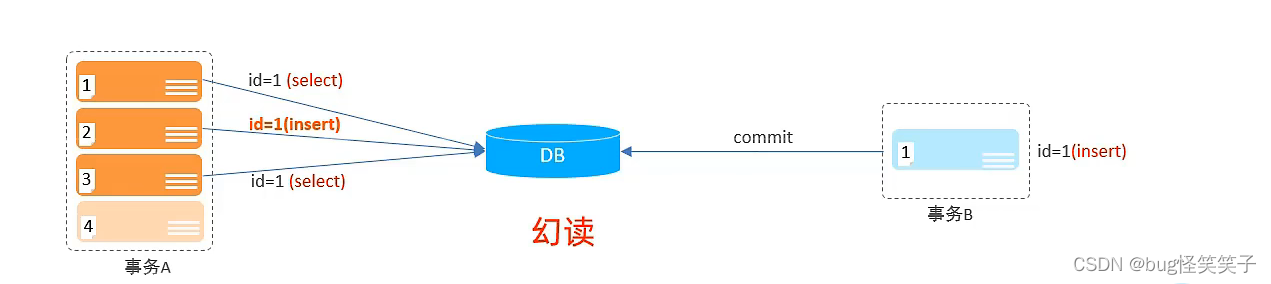
5、事物的隔离级别(解决并发情况下发生的并发事务问题)
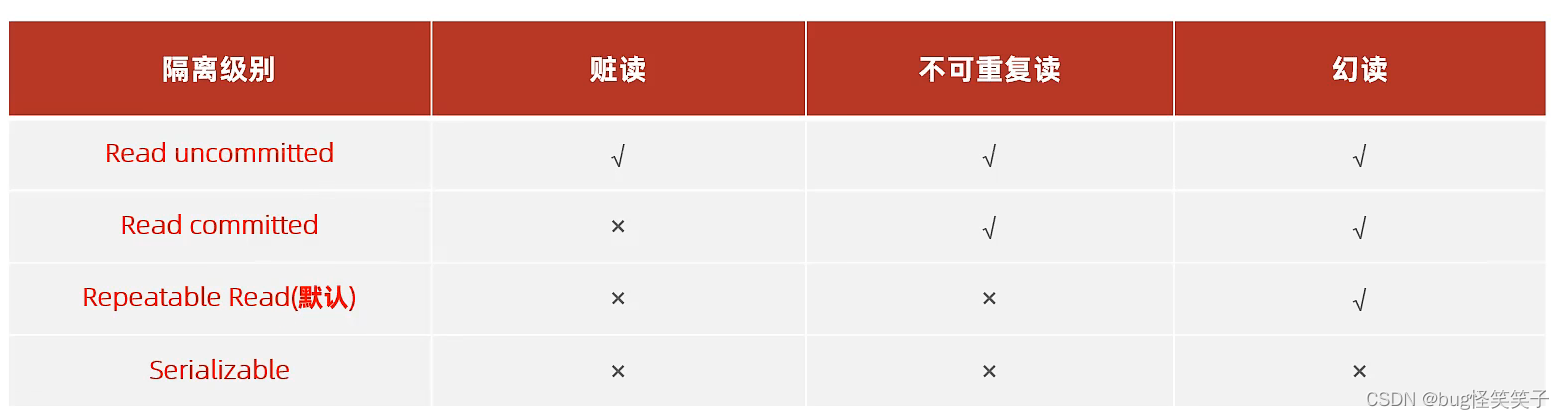
------ 查看事务隔离级别 select @@transaction_isolation
------ 设置事物的隔离级别
set [ session | global ] transaction isolation level { 隔离级别 } ;
实际写的时候不用添加{ }和[ ]。
session表示当前用户窗口可用,global表示

二、存储引擎
1、简介
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。
存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
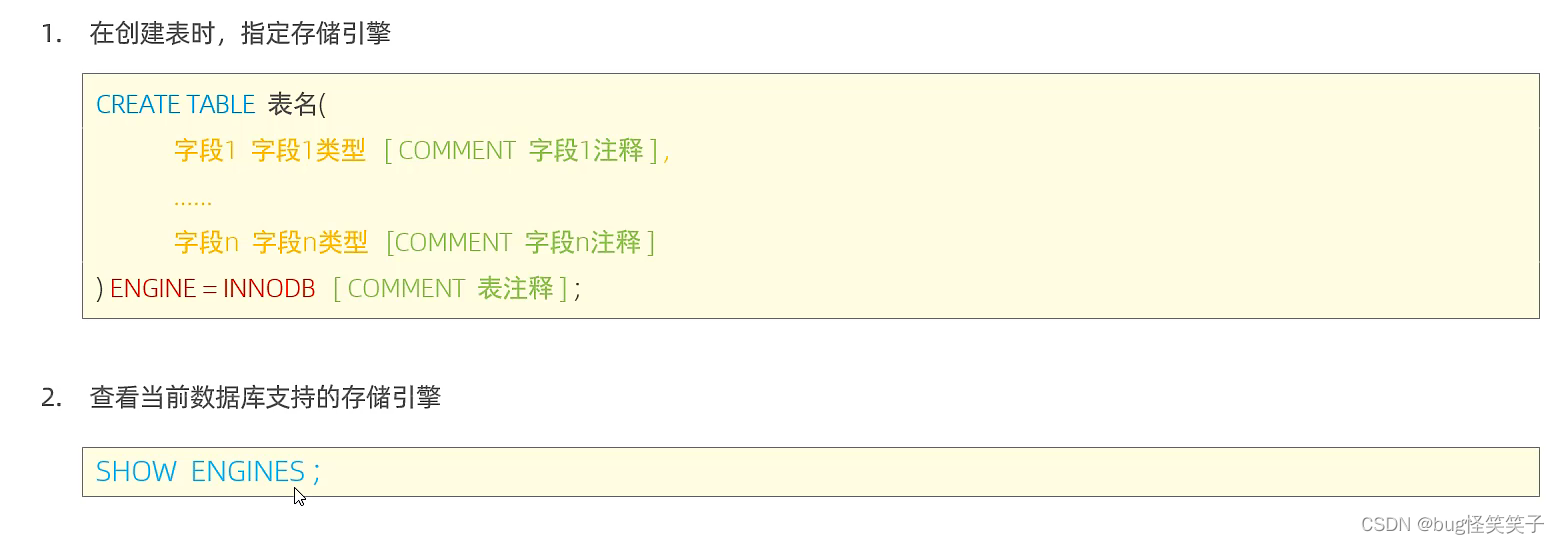
<1>查询当前数据库支持的存储引擎
show engines;
<2>创建表时,指定存储引擎
create table 表名 (
字段1 类型1 [comment 字段一注释],
字段2 类型2 [comment 字段二注释],
......
字段n 类型n [comment 字段n注释]
)engine=inndb ;[comment 表注释]
2、InnoDB
<1>InnoDB的特点

对于xxx.ibd文件可以采用cmd的命令行打开:ibd2sdi xxx.ibd
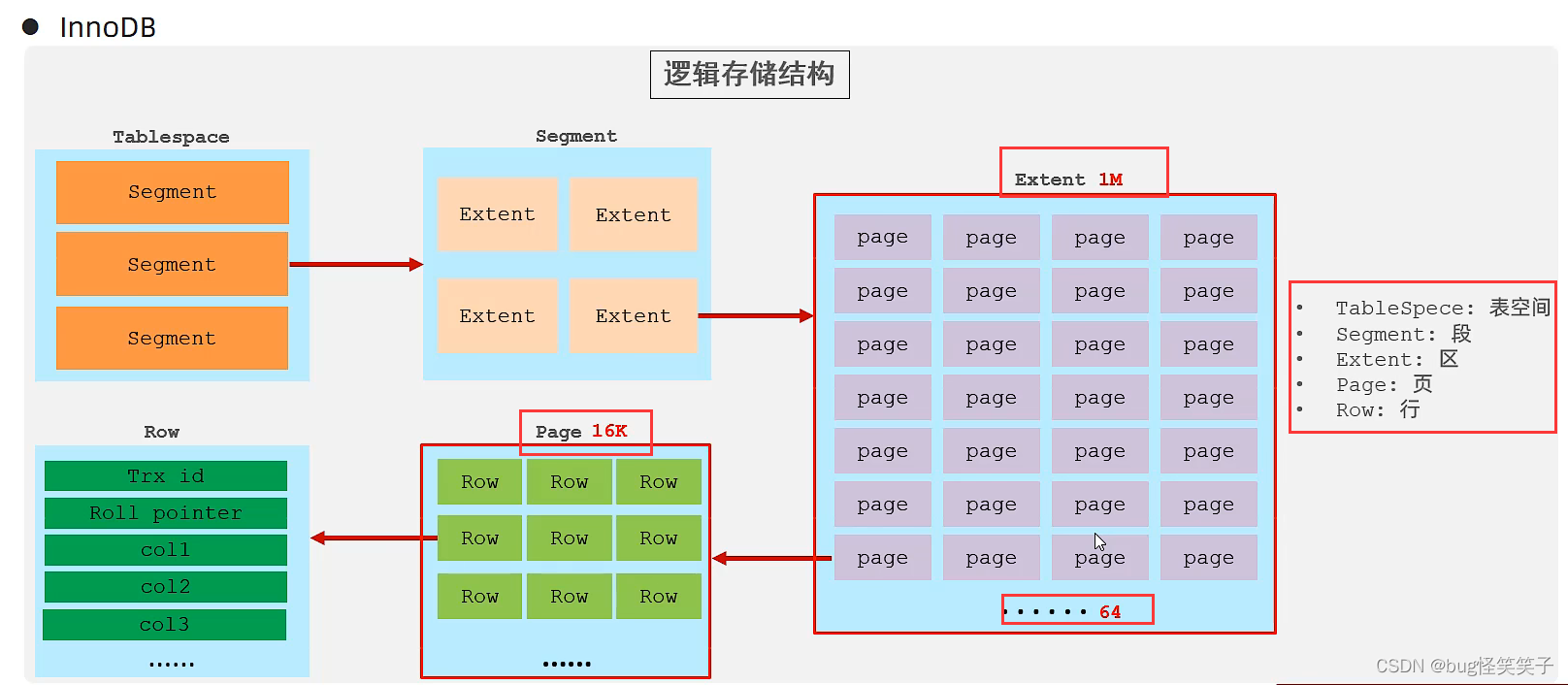
<2>InnoDB的逻辑存储结构
~表空间:里面有若干个段
~段:里面有若干个区
~区:里面有若干个页(每个区大小1M)
~页:一个页里有若干行(每页大小16k)
~行: 行里面有若干字段
3、MyISAM
无事务、表级锁、访问速度快

4、Memory
内存存放、hash索引,只有sdi文件没有数据文件和索引文件

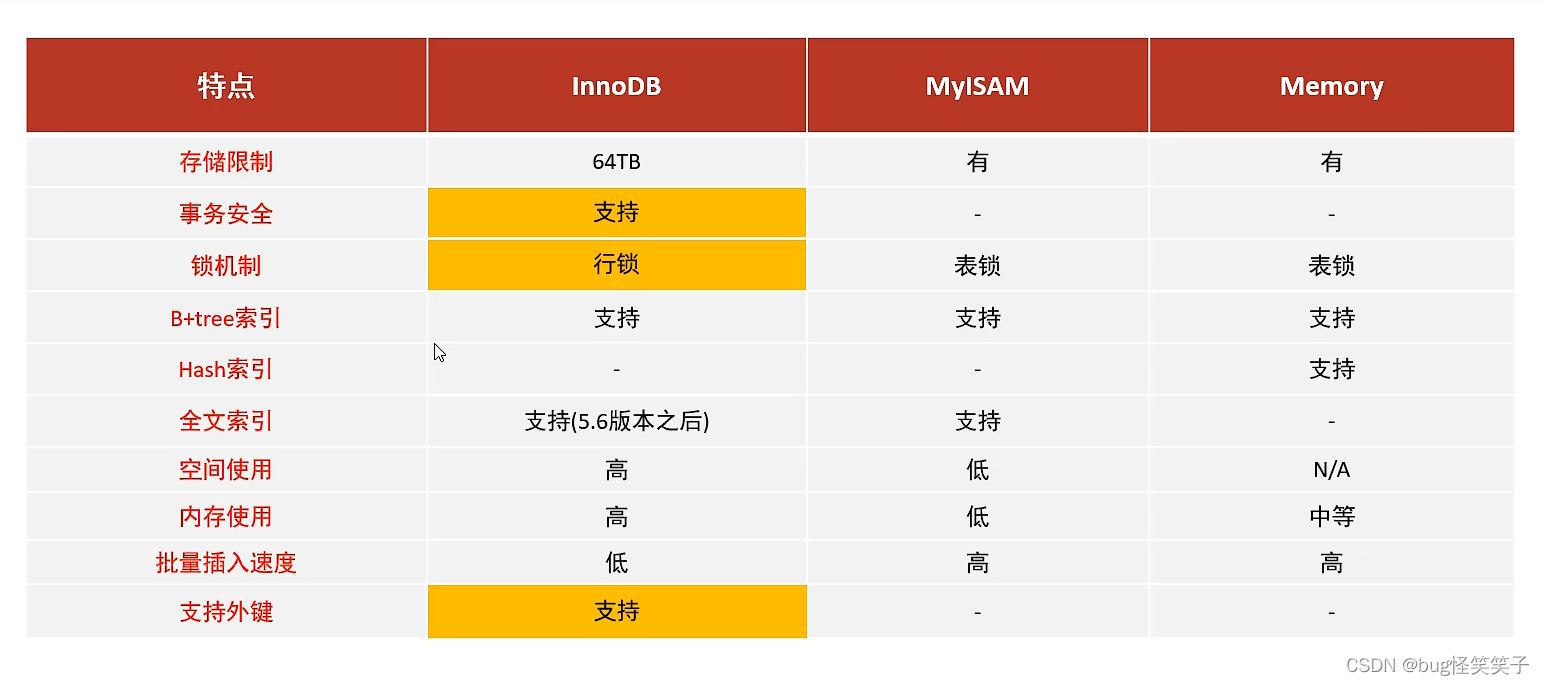
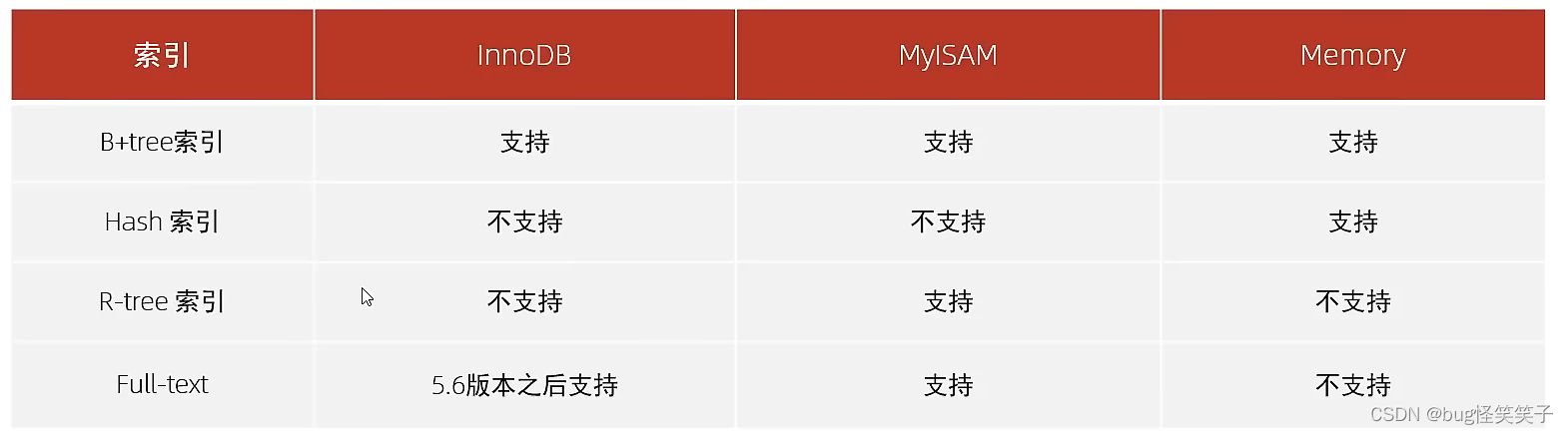
5、三个存储引擎的区别
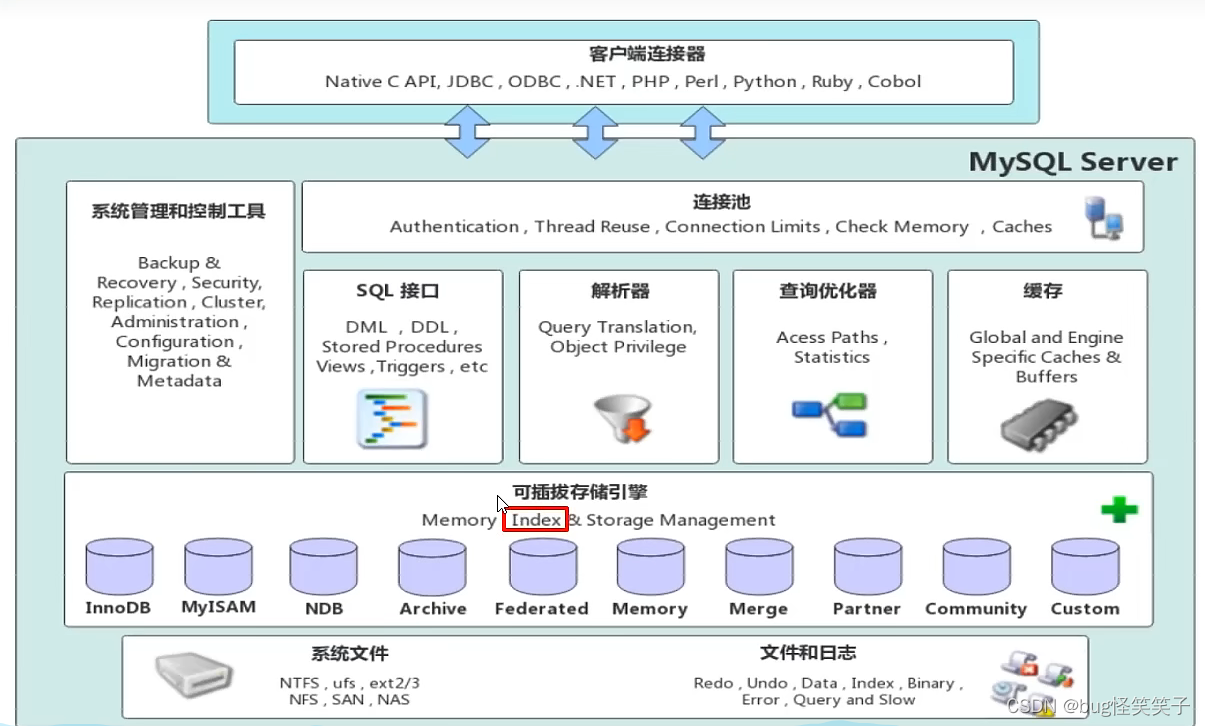
连接层:客户端的连接,认证,授权 服务层:SQL的接口、优化 引擎层:引擎的不同索引结构不同

三、索引(1)
1、索引概述
<1>索引概述


<2>索引结构

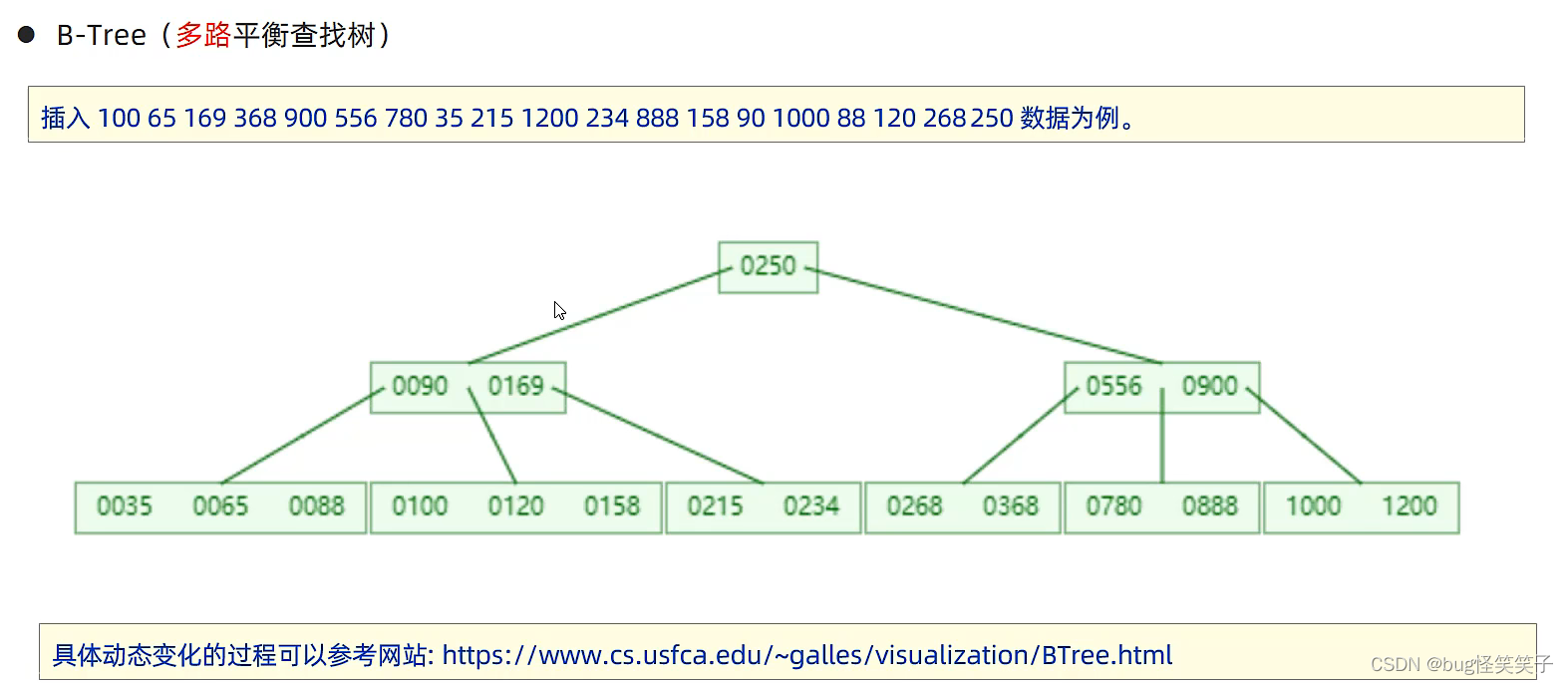
<1>B-Tree
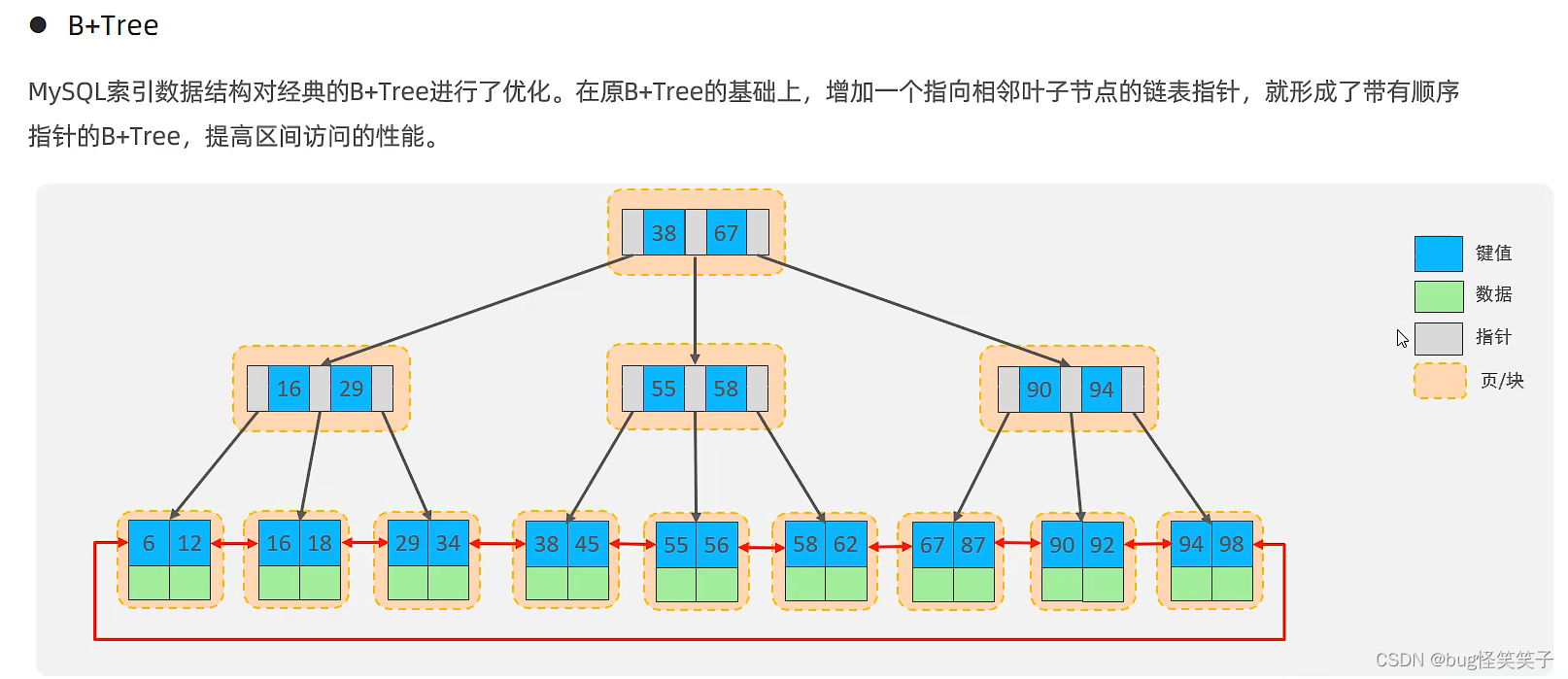
<2>B+Tree
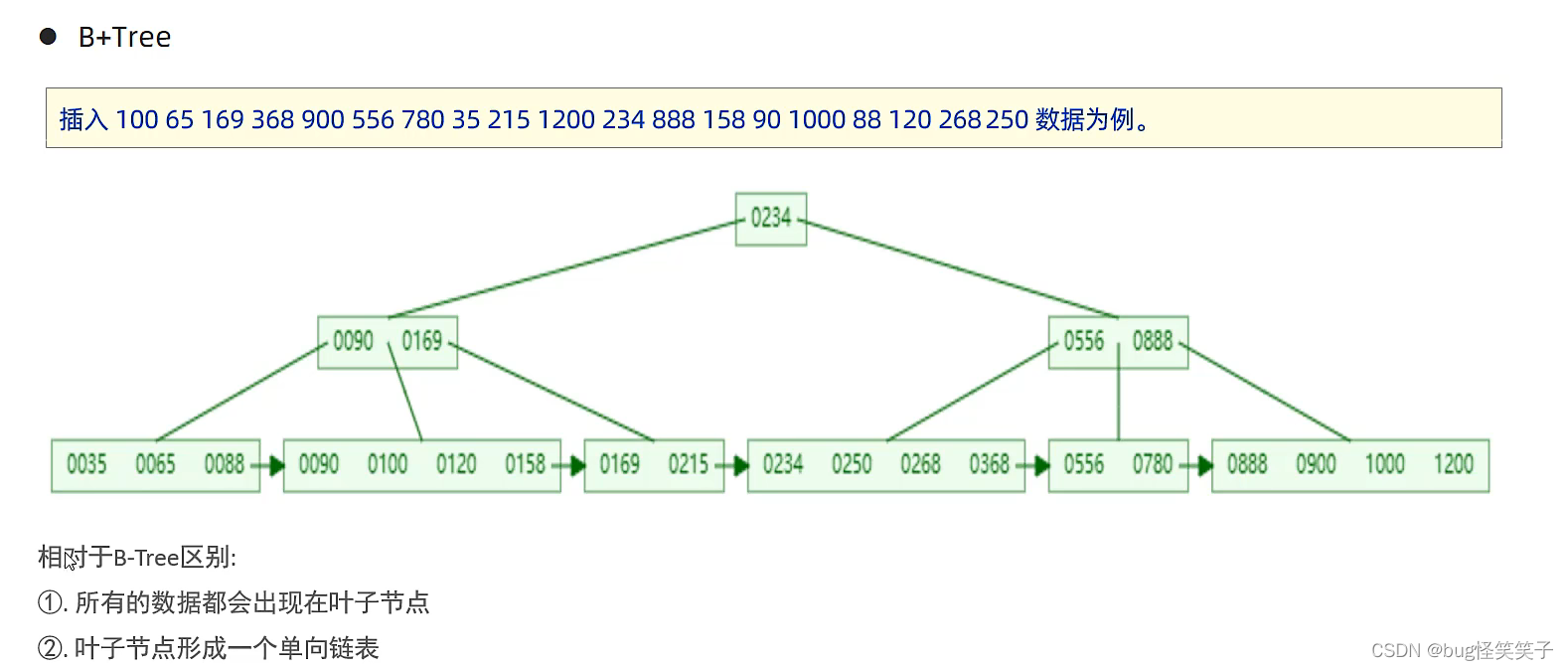
在Mysql中的B+Tree数据结构:相邻的子节点新增链表指针
<3>Hash索引
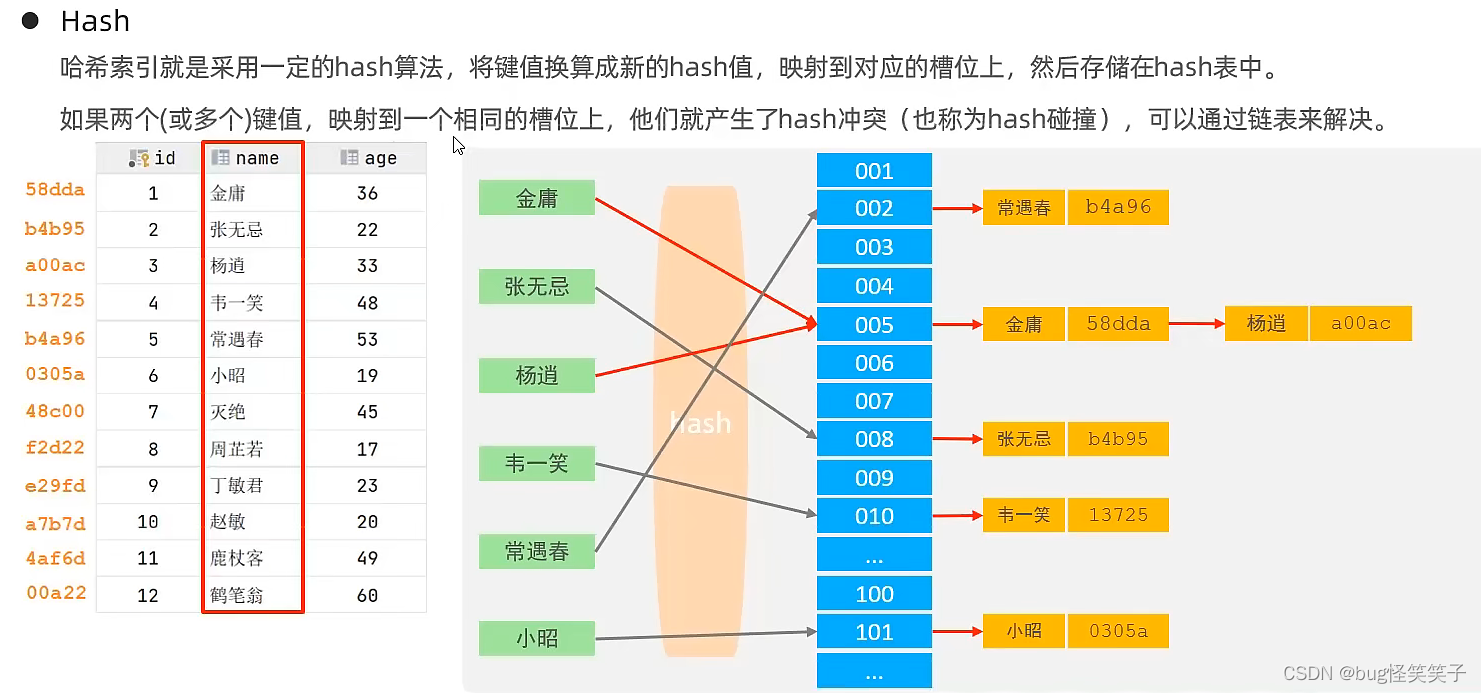
hash的使用情况:

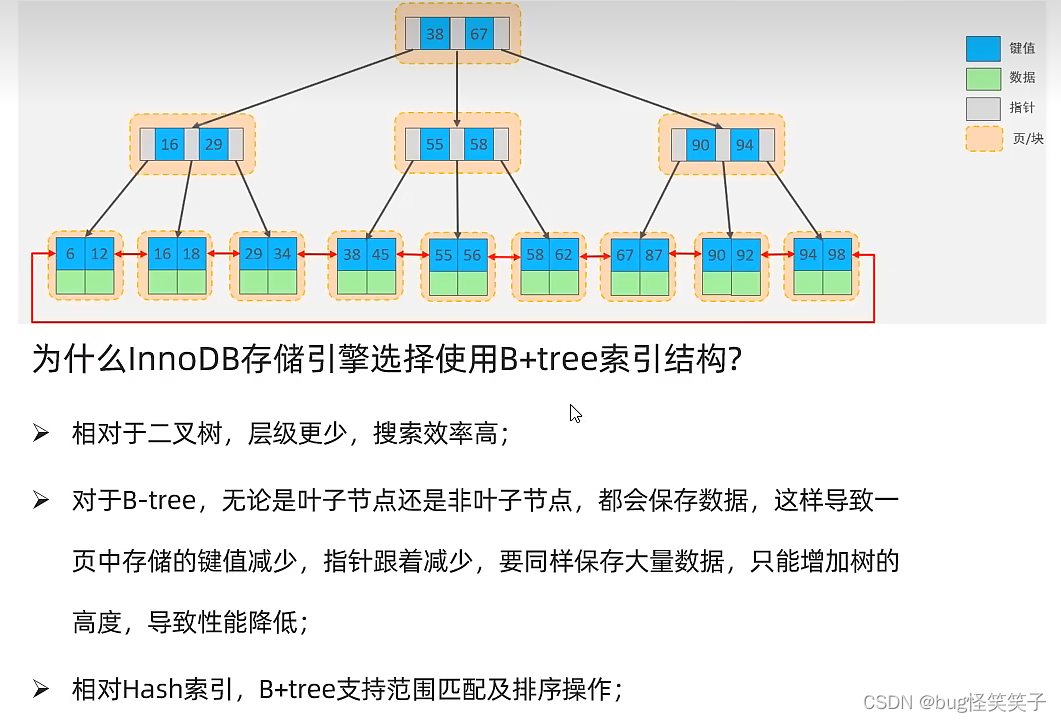
<4>为什么使用B+Tree(面试题)
三、索引(2)
1、索引的分类


<1>聚集索引:就是将B+树的同一个叶子节点分为两部分,一半放索引,一半放索引所在行的数据。
<2>二级索引:就是将B+树的同一个叶子节点分为两部分,一部分存放索引,一部分存放对应的主键。
查询案例 :select * from user where name = 'Arm';
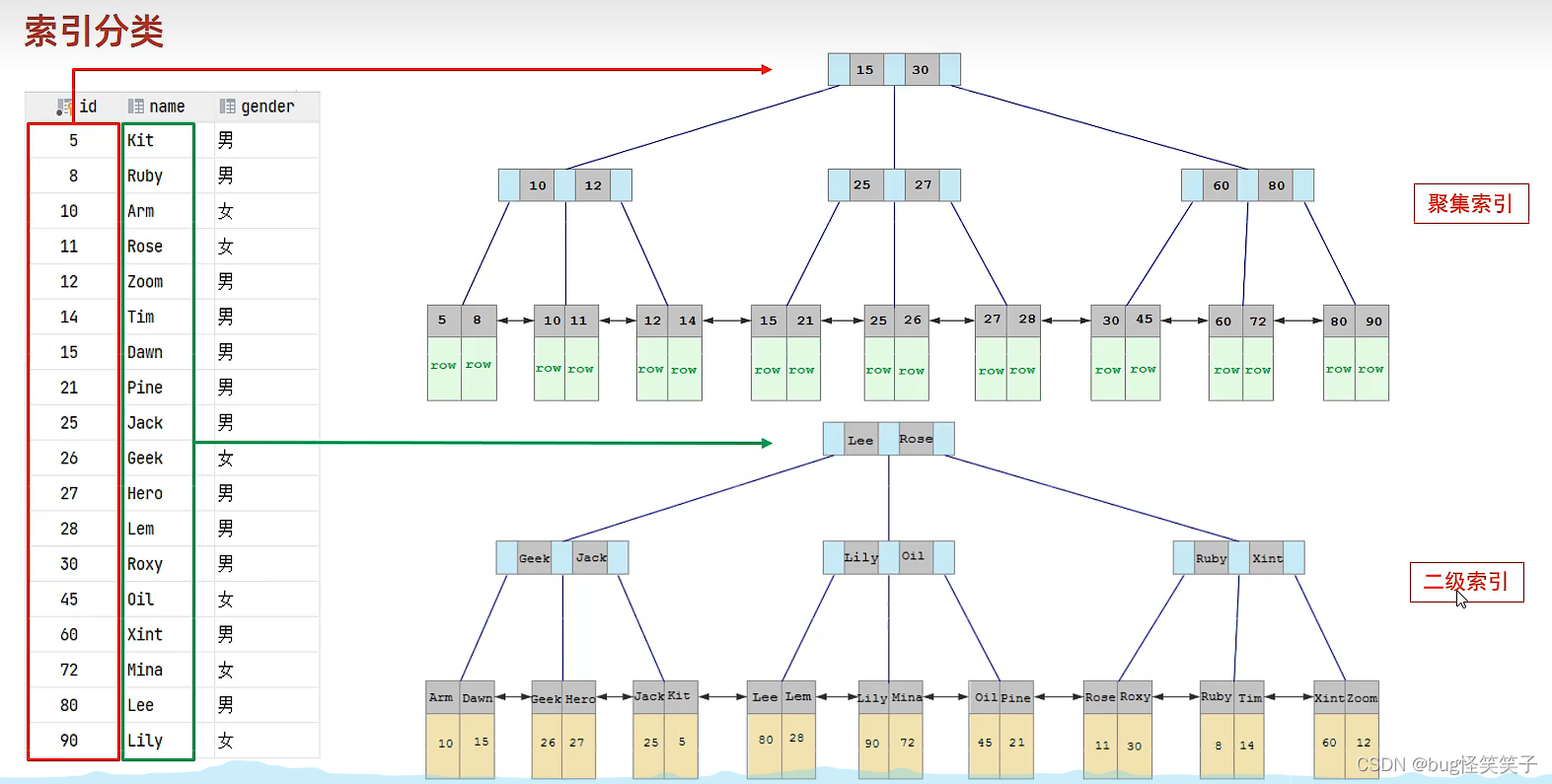
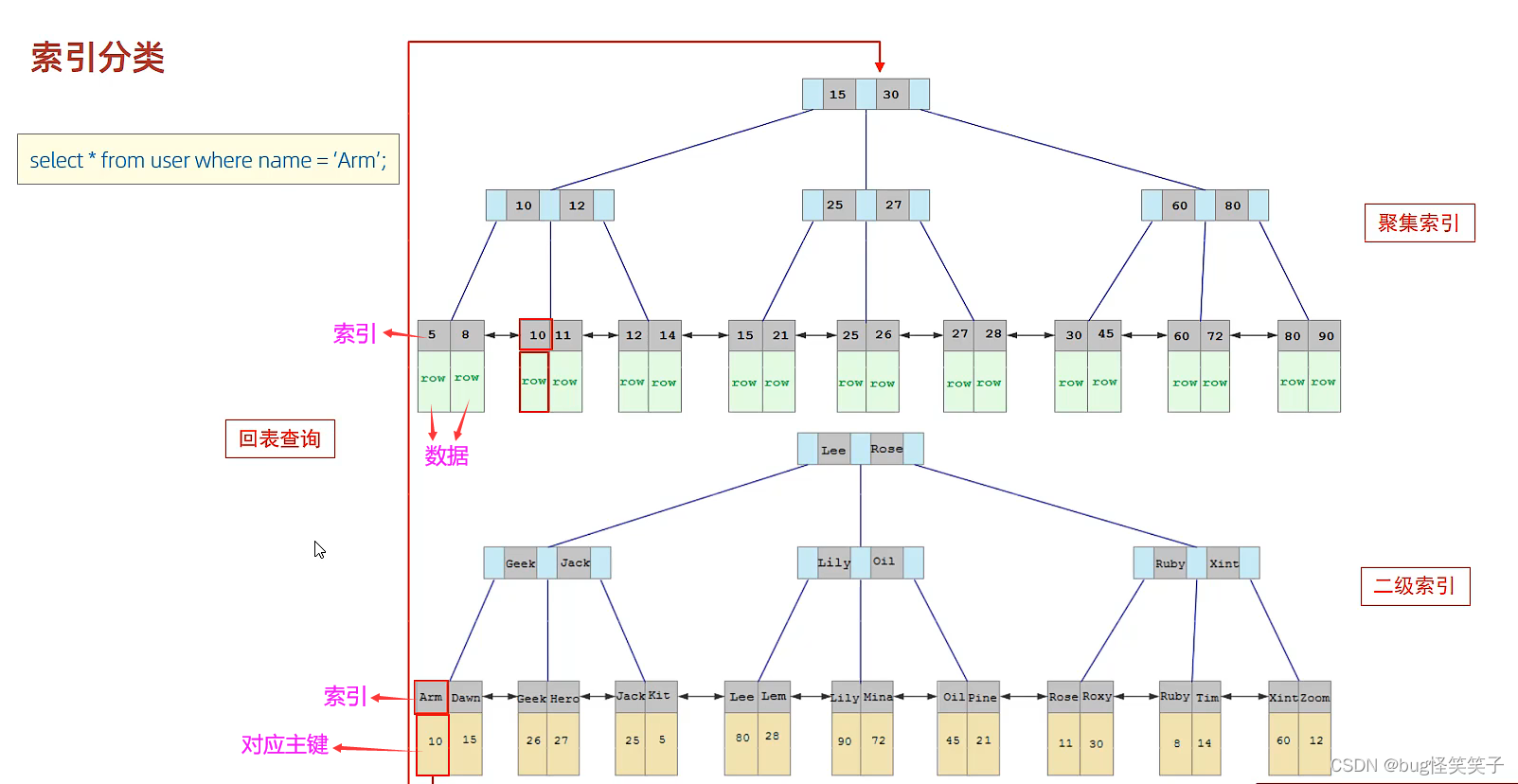
对于非主键的数据的查询,通常通过二级索引,找到对应的主键,再通过回表查询来获取对应的数据。
2、索引的语法
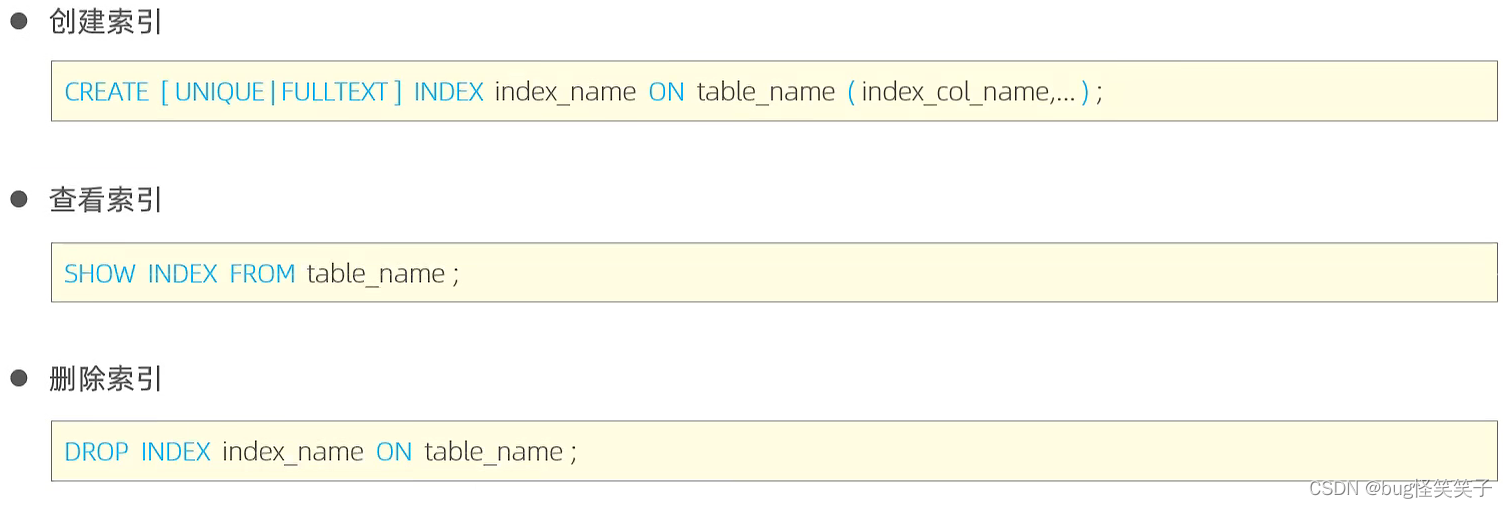
 create
create
如何创建create_time和update_time的联合索引。(表名:category)
create index idx_crtime_updtime on category(create_time,update_time);
删除刚刚创建的索引:
drop index idx_crtime_updtime on category;
3、性能分析
<1>查看SQL的执行频率
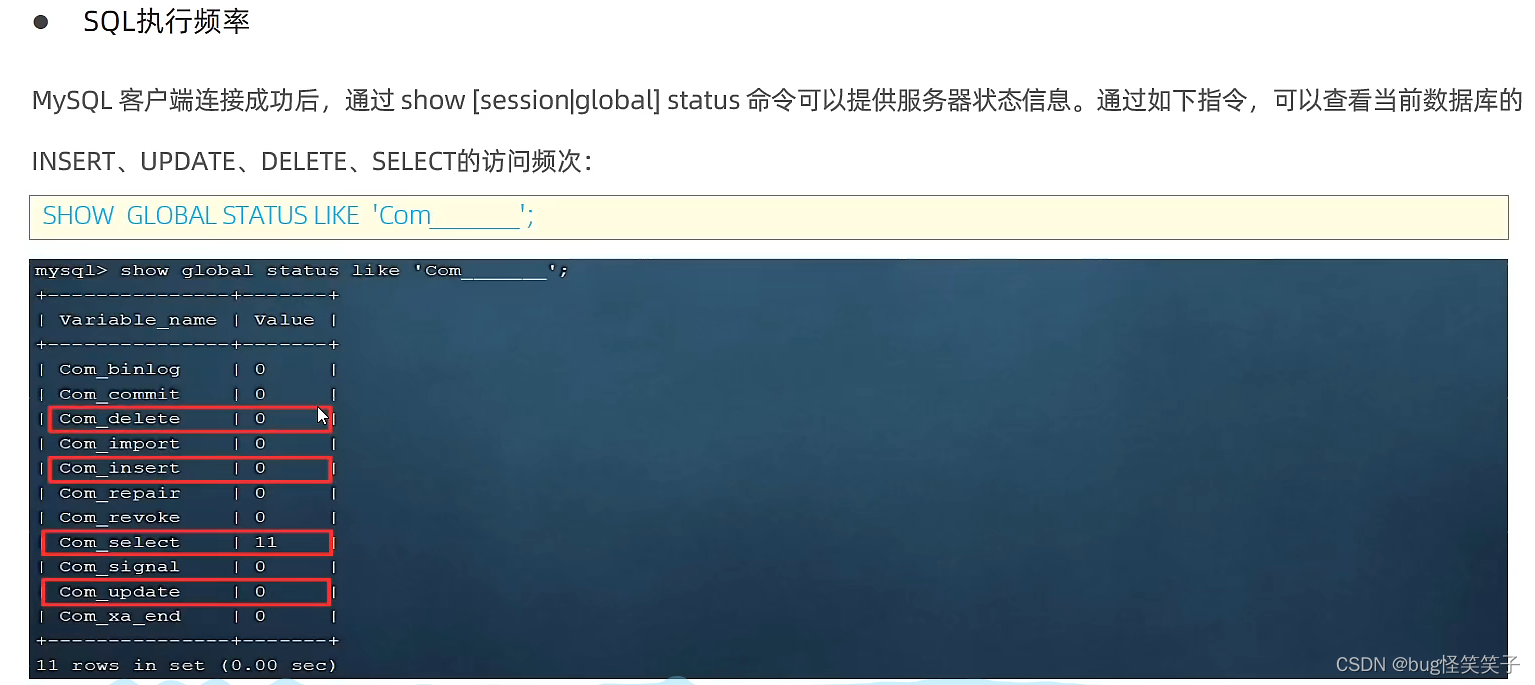
show global status like 'Com_______'; (7个下划线)
显然我这张表是查询为主。
<2>慢查询日志------定位慢查询SQl语句
需要在mysql里查看慢查询sql:

也可以打开慢查询日志:
cat /var/lib/mysql/localhost-slow.log
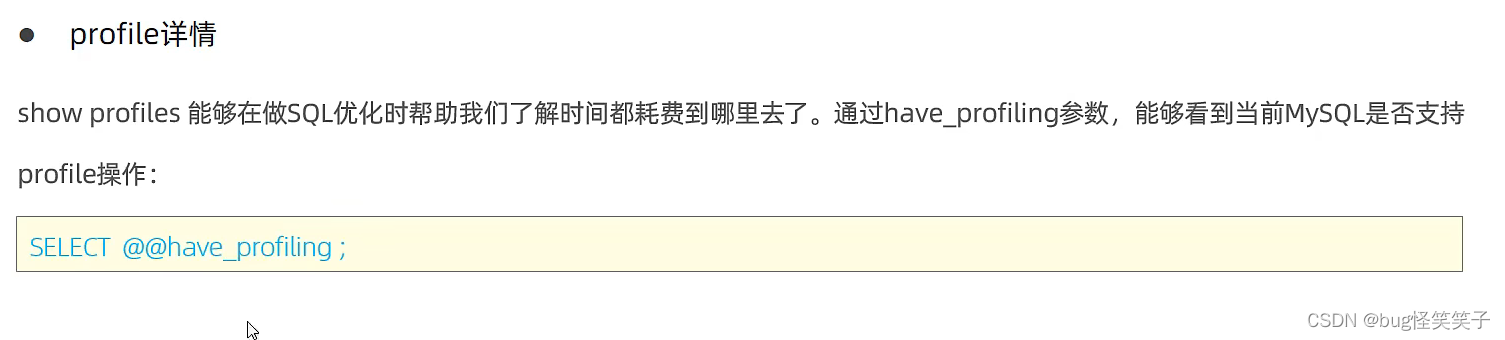
<3>show profiles查看耗时情况
select @@have_profiling查看是否支持profile操作
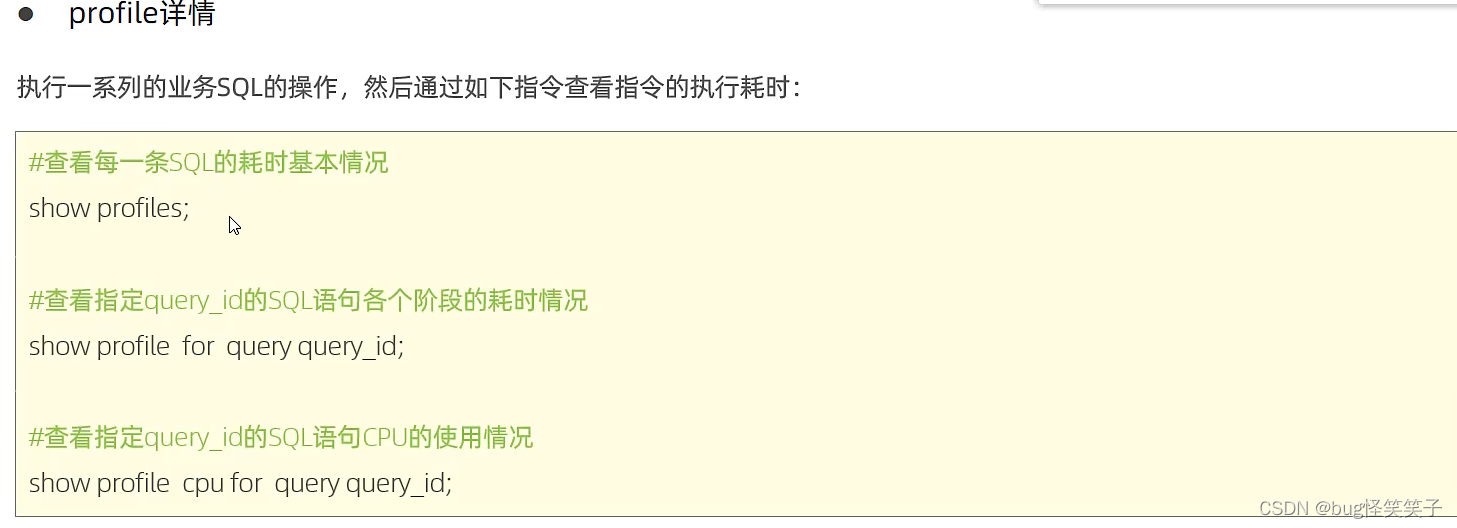
show profiles;查看每条SQL的耗时
show profile for query query_id; 查看指定query_id的SQL语句在各阶段的耗时情况;
show profile cpu for query query_id;查看指定query_id的SQL语句在cpu的使用情况;
<4>查看SQL的执行计划
在查询语句前加上 explain 或者 desc

<5>验证索引效率

4.索引使用
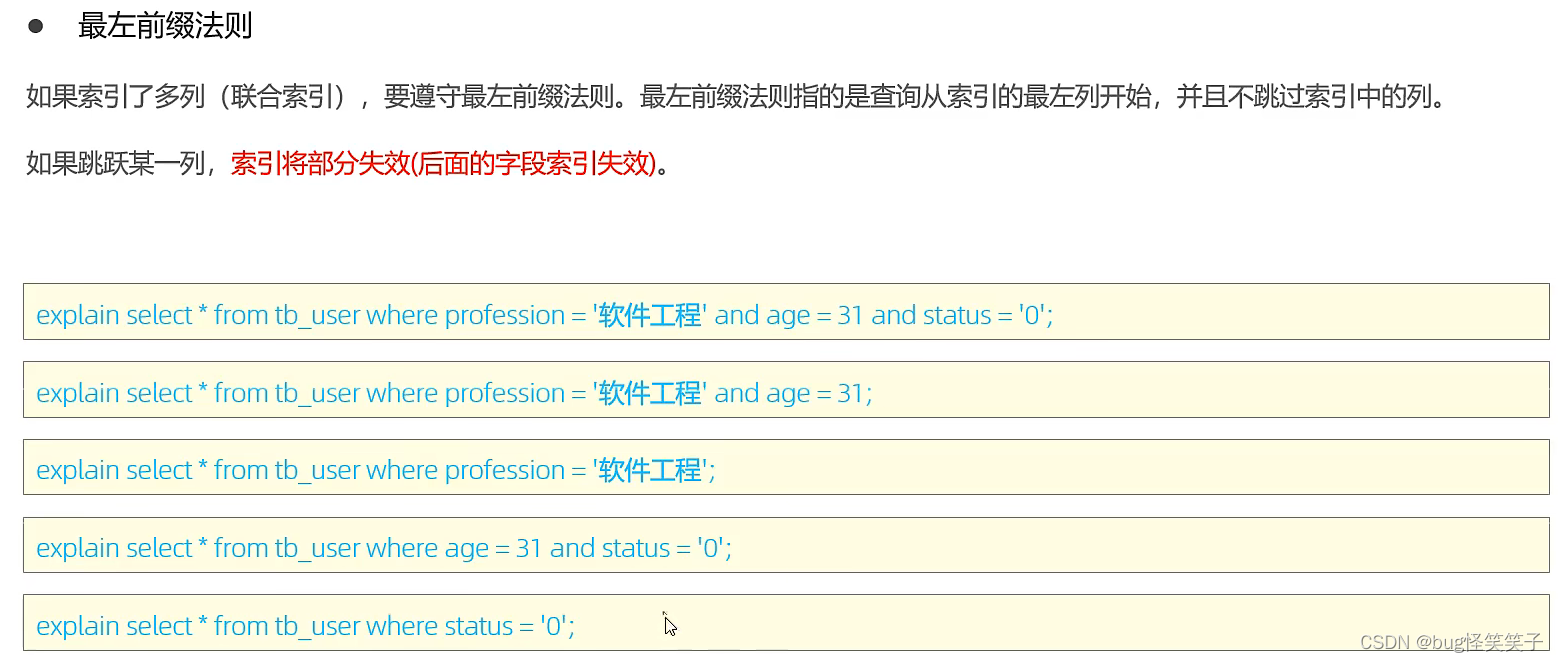
<1>最左前缀法则
在一个表里有:profession ,age , status等字段。
并且创建三个字段的联合索引:
create index idx_prof_age_stat on tb_user (profession ,age , status) ;
索引里字段数序为 profession ,age , status。
我们在查询时,最左边的字段一定要出现也就是profession字段一定在。
后面的字段如果想让索引生效,只能前面的字段都存在。
例如:
(1)profession 此时走索引,满足最左前缀 有效
(2)age 失效,因为没有最左前缀profession 失效
(3)age , status 失效,因为没有最左前缀profession 失效
(4)profession ,status 此时只有profession索引生效,因为跳过了age,age后面的索引失效
(5)profession,age 此时两者都走索引满足最左前缀 有效
<2>范围查询
在一个表里有:profession ,age , status等字段。
并且创建三个字段的联合索引:
create index idx_prof_age_stat on tb_user (profession ,age , status) ;
索引里字段数序为 profession ,age , status。
查看如图下面的第一句SQL,age>30 右侧的列失效。
如果age>30 换为 age >=30 索引让然有效。
例如:(前提是满足最左前缀原则)
(1)profession = 'ssssxxx' and age > 30 and status =0; age > 30右侧 status =0索引失效)
(2)profession = 'ssssxxx' and age >= 30 and status =0; 索引有效

<3>索引失效情况一
(1) 索引列运算
如果在索引列进行运算操作,索引就会失效,函数运算也会失效。

(2)字符串不加引号

例如:phone 类型为 varchar 类型的,如果字符串类型没单引号会失效
(1)我们执行查询操作时候,phone = 1231312313 此时 索引失效
(2)我们执行查询操作时候,phone = '1231312313' 此时 索引有效
(3)模糊匹配-----开头模糊
对于模糊匹配来说,开头模糊会导致索引失效。
例如:
(1)select * from user where name like '%科技'; 此时开头模糊匹配 索引失效
(2)select * from user where name like '科技%'; 此时结尾模糊匹配 索引生效

(4)or连接的条件
只有or连接的两个条件都有索引,索引才生效,只有一个有索引,索引不生效。
(1)假设id有索引 name没有
select * from user where id =1 or name ='wrx'; name没有索引 此时索引不生效
(2)假设id和name都有索引
select * from user where id =1 or name ='wrx'; 两者的索引都生效

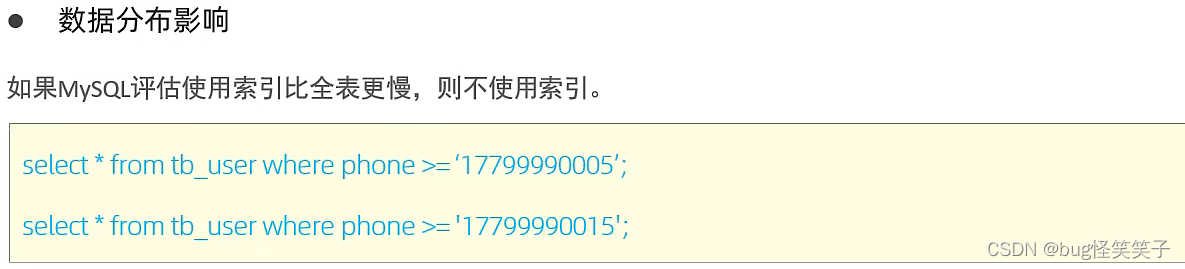
(5)数据分布影响
mysql评估使用索引比全表扫描慢,就不用索引
<4>SQL提示-----多索引情况下选择使用哪个?
use index 使用某个索引
ignore index 忽略某个索引
force index 强制使用某个索引
例如 :
age 这一列有两个索引 一个 主键索引 primary,一个单列索引 idx_usr_age,一个联合索引
idx_usr_prof_age.
(1)使用单列索引
select * from user use index (idx_usr_age) where age =18;
注意sql提示的位置!!!!
(2)忽略索引
select * from user ignore index (idx_usr_age) where age =18;
(3)强制使用某个索引
select * from user ignore index (idx_usr_prof_age) where age =18;

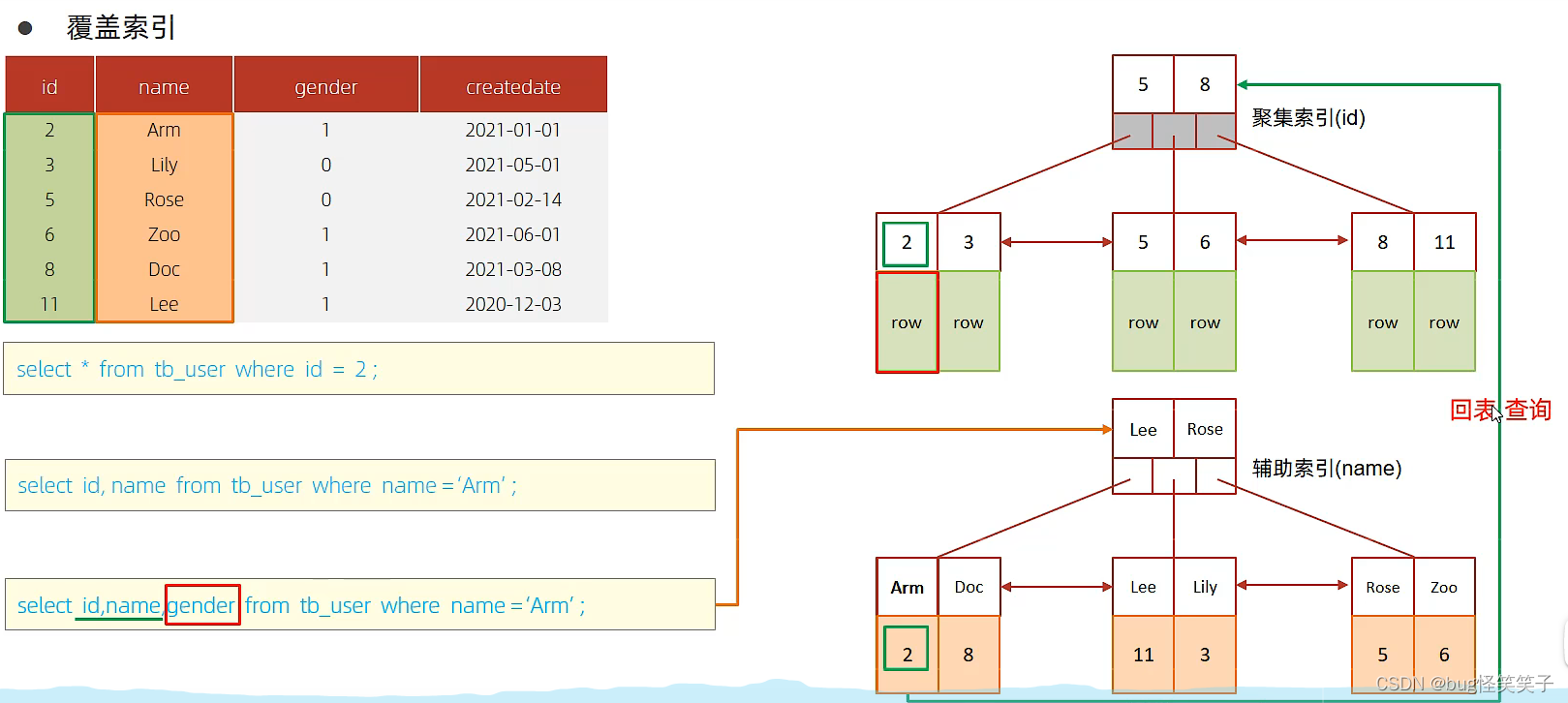
<5>覆盖索引
覆盖索索引一定程度上提高了检索的效率,因为他避免了回表查询。
查询使用了索引,并且返回的列在索引中都能找到,可避回表查询提高效率。
l例如下图:
给name和gender创建了联合索引,只有createdate没有索引。
(1)select id,name,gender from tb_user where name = 'Arm';
此时不需要回表查询,name和gander有联合索引,所以name和gander都能在索引中找到,id在联合索引下面所以不用回到聚集索引中查询。 不回表
(2)select id,name from tb_user where name = 'Arm'; 同理 不回表
(3)select id,name,gender ,createdate from tb_user where name = 'Arm';
我们发现createdate不在我们的联合索引里,而且creatdate也没有创建单列索引,所以在查到id之后还需要回表来进行聚集索引的查询来获取createdate的数据 。 回表

<6>前缀索引
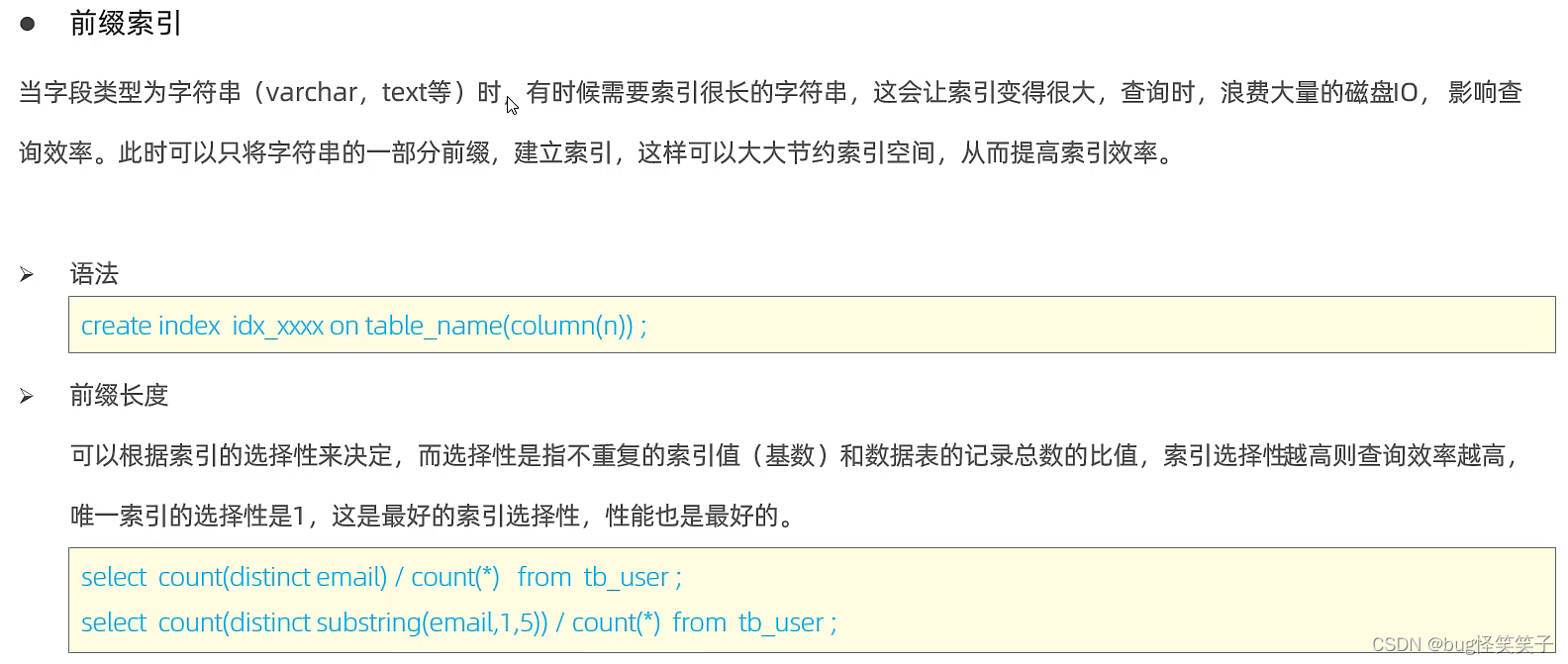
如图数据:
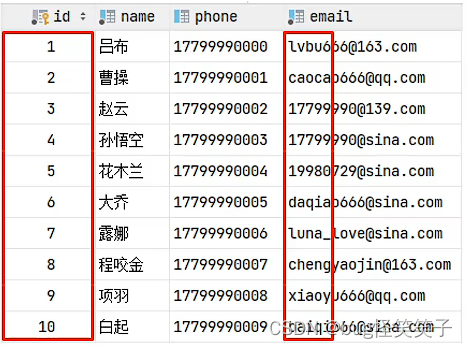
我们发现,例如email的数据为varchar类型的,但是字符很长,如果这样就创建索引的话,其实很占用磁盘IO的,为了减小占用,我们可以截取前面的几个字符创建索引。
语法:只需要在建立索引的列后面添加前缀的字符数
create index idx_user_email_5 on tb_user(email(5));
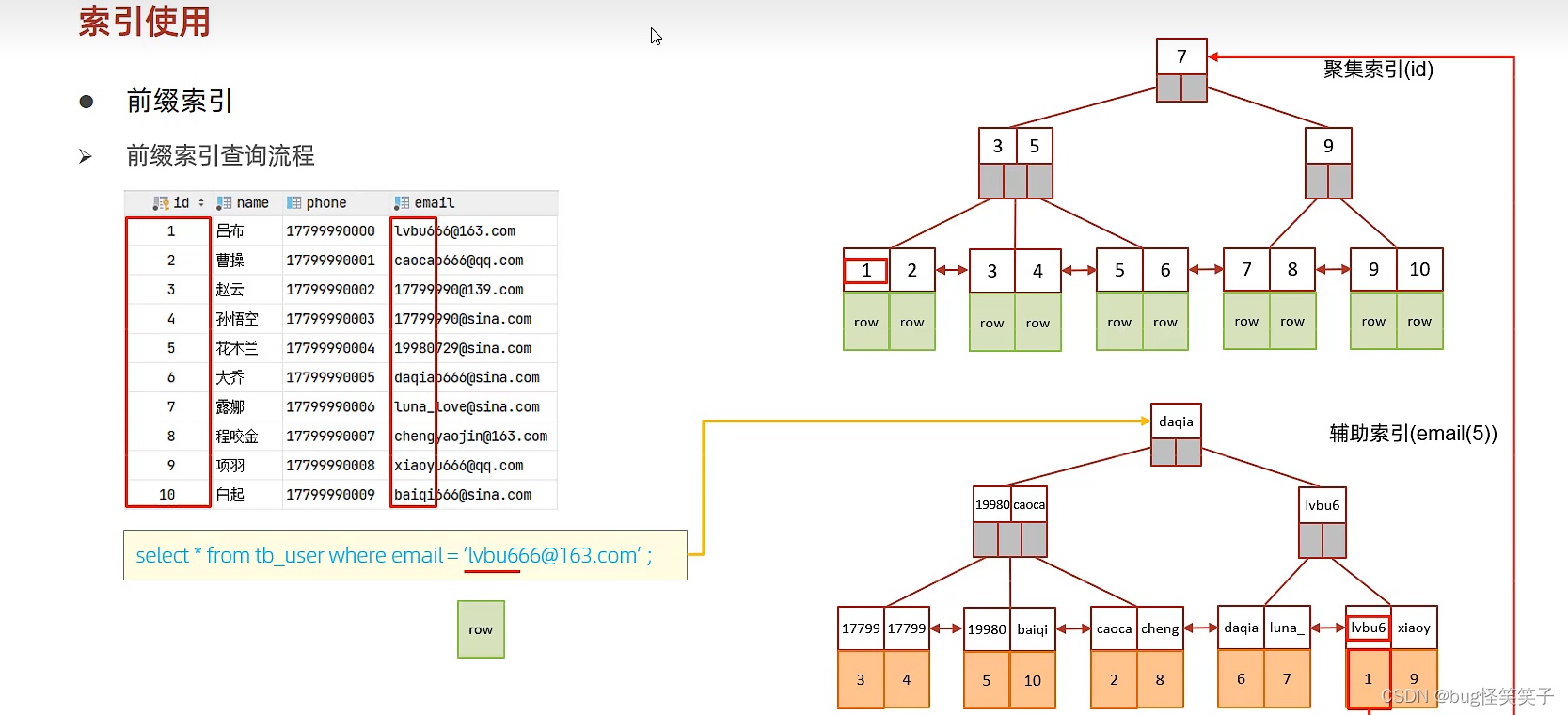
查询流程:
select * from tb_user where email = '17799990@sina.com';
第一:匹配前缀索引,找到索引对应的id。
第二:根据id回表查询,获取整行数据。
第三:取出这行数据的email来和17799990@sina.com进行比较是否相同。相同就返回数据
<7>单列索引和联合索引的选择
mysql在使用索引时候,会先查看,查询条件包含几个索引。
例如:name,phone,age三个数据列
分别创建name,phone,age的单列索引,然后创建idx_name_phon_age的联合索引
我们查询:
select id , name ,phone from tb_user where nane = 'wrx';
此时name字段在两个索引里都存在,name的单列索引和idx_name_phon_age的联合索引,此时mysql只会选择效率最高的一个索引进行查询,而不是都用。
我们也可以使用SQL提示可进行干预。
注意:此处我们发现name虽然包含在idx_name_phon_age的联合索引里,但是我们要看看是否符合最左前缀法则,满足才能使用。
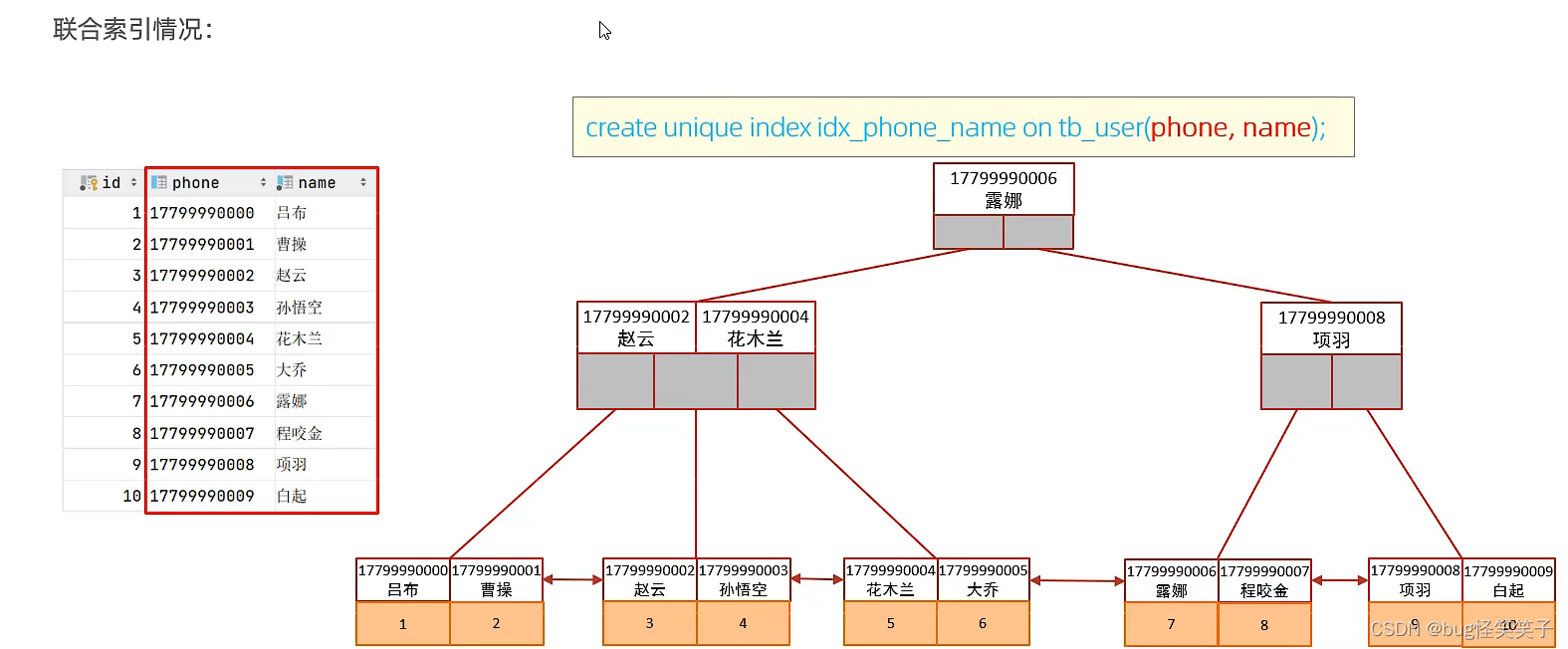
此图的phone和name组成的联合索引,phone在前面,所以排序的时候,先按照手机号phone进行排序,如果顺序相同再使用name进行排序。
<8>索引的设计原则

四、SQL优化
1、插入优化
<1>批量插入
对于批量插入来说插入的数据最好是在500-1000条之间,如果数据很多,可以分成多个1000条。

<2>手动开启和提交事务
我们知道,mysql默认是自动提交事务,而且每条sql都是一个事物,这样的话,mysql每次执行一个sql都必须执行事物的开启与提交操作,所以不如手动开启和提交事务,这样就不用频繁的开启和提交事务了。

<3>主键顺序插入
顺序插入比乱序插入效率更高,这个详见下面的主键优化。

<4>mysql的load指令批量插入
'/root/sql1.log' : 指的是文件名
' ,' : 指的是两个数据的分隔符为 ' ,'
' \n ' : 指的是每行数据为数据库的一条数据

2、主键优化
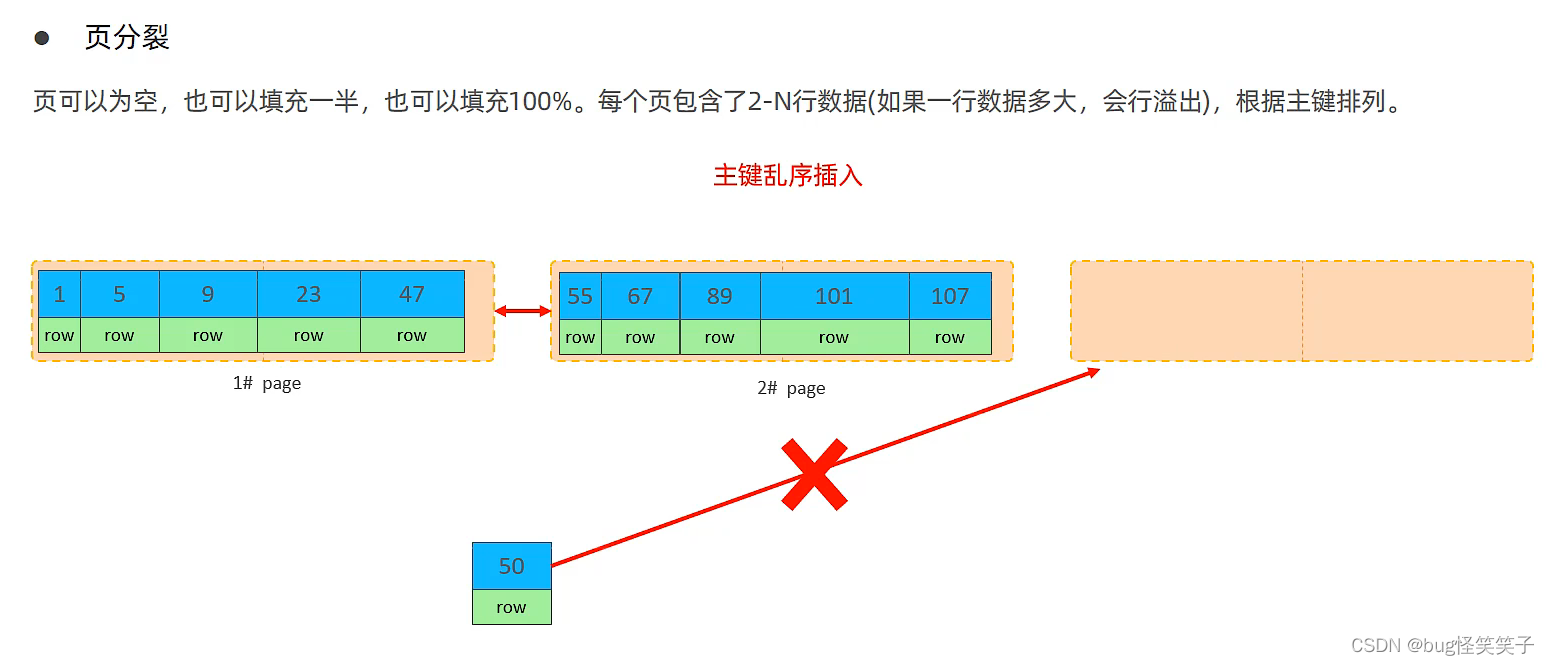
<1>页分裂
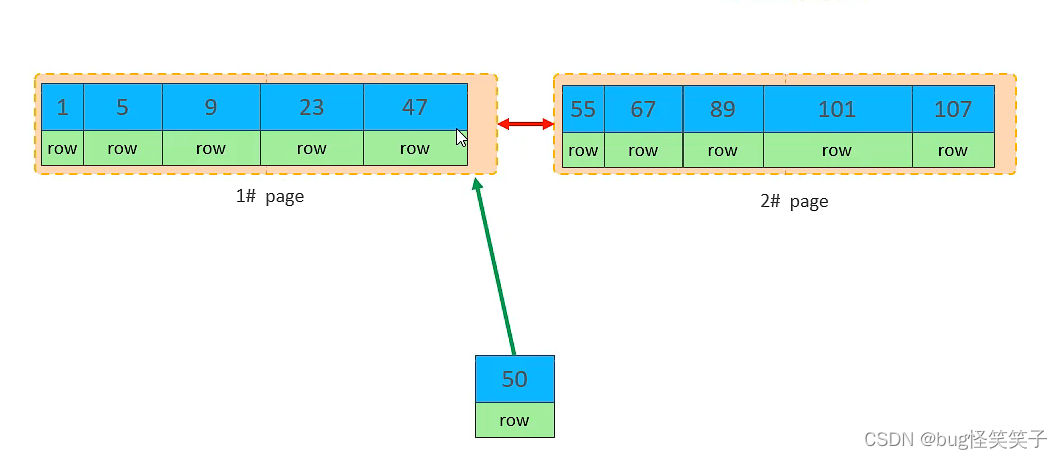
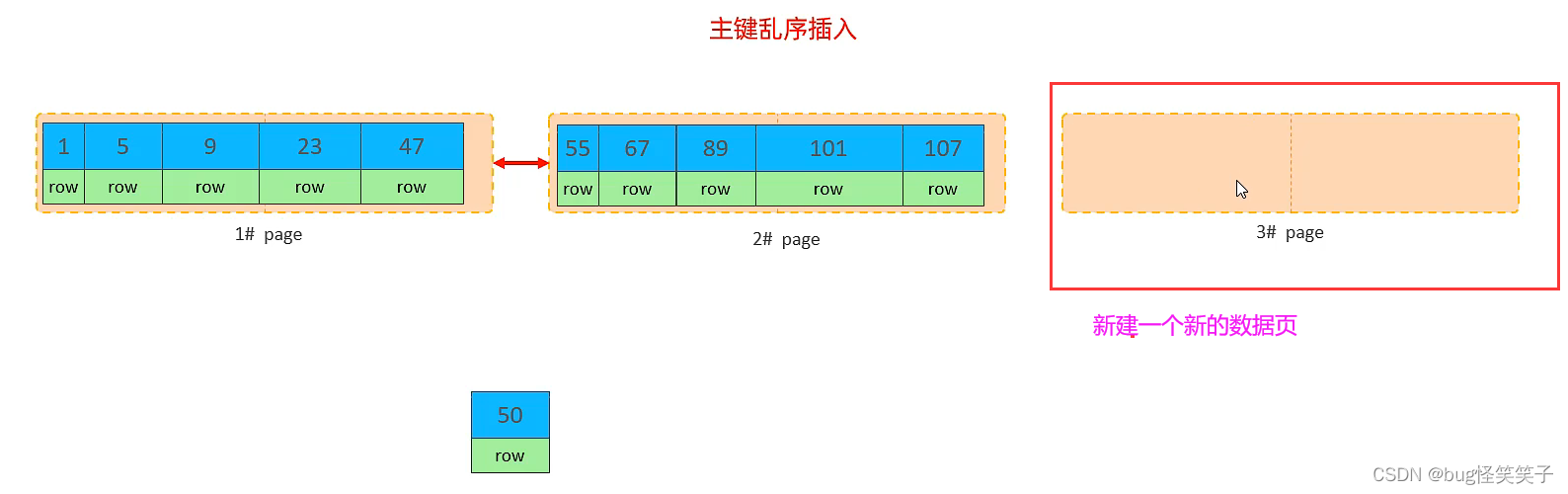
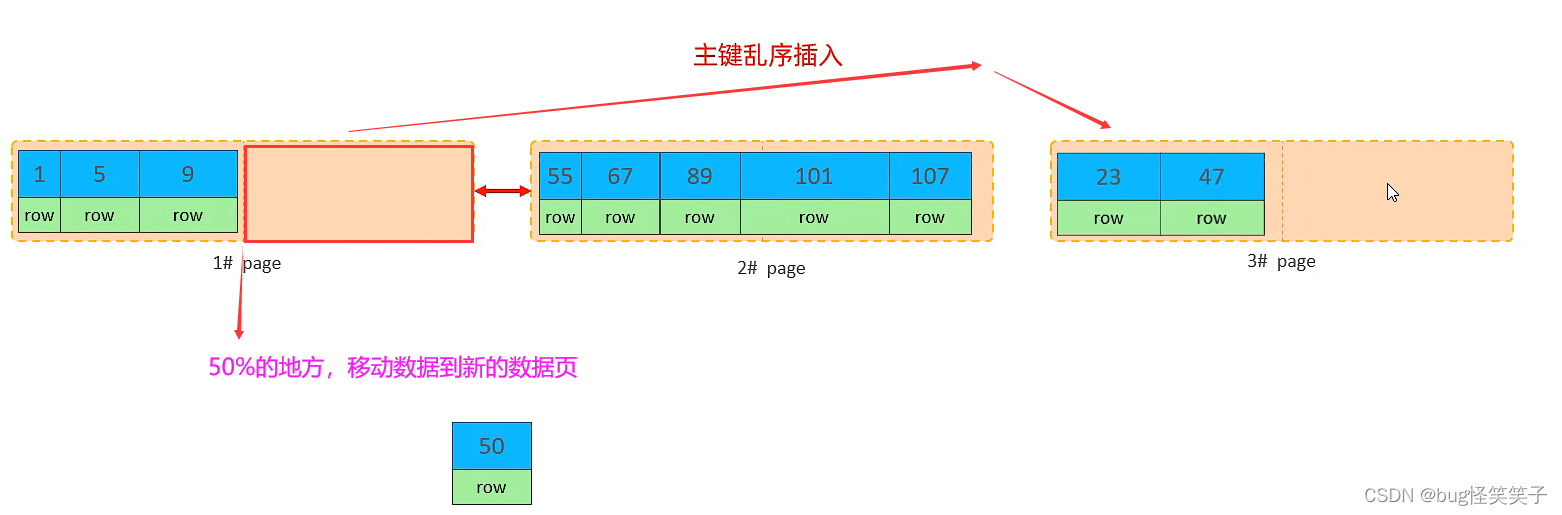
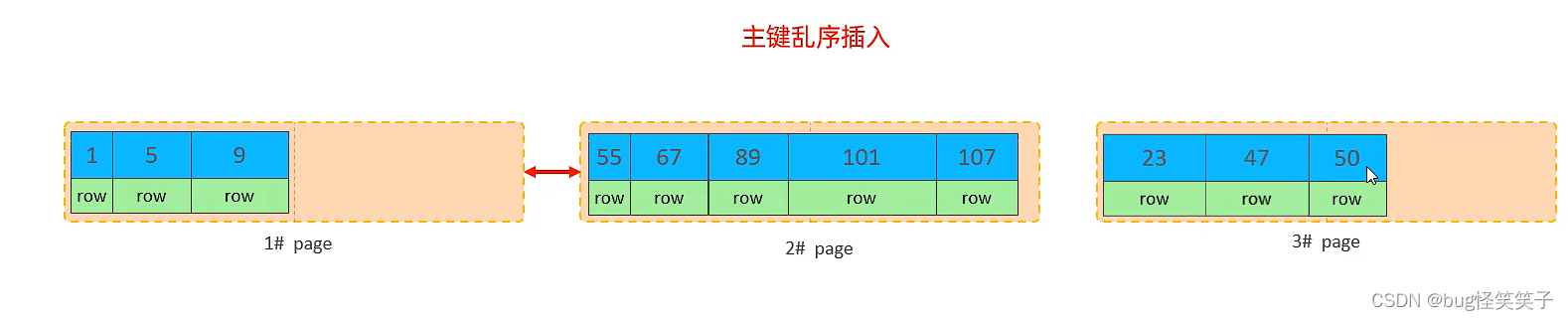
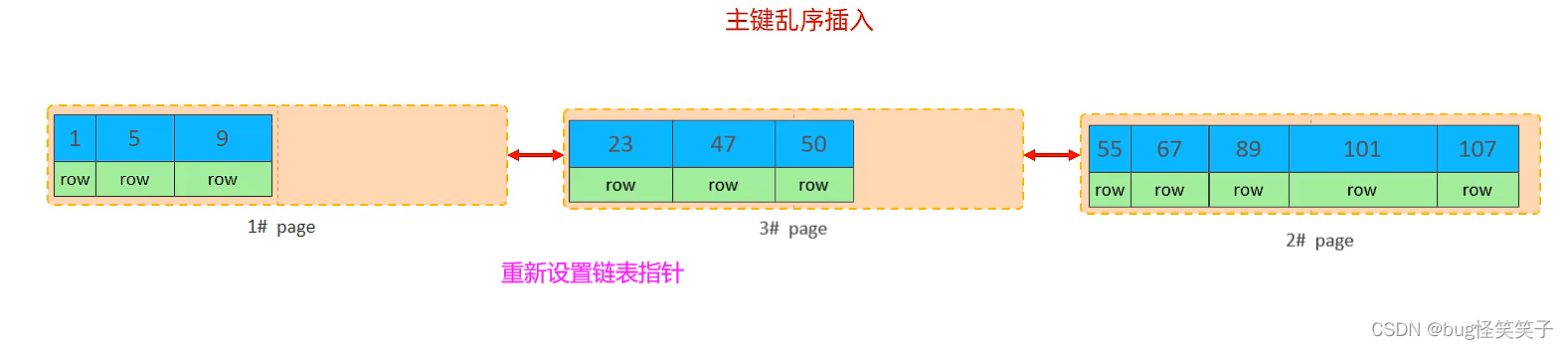
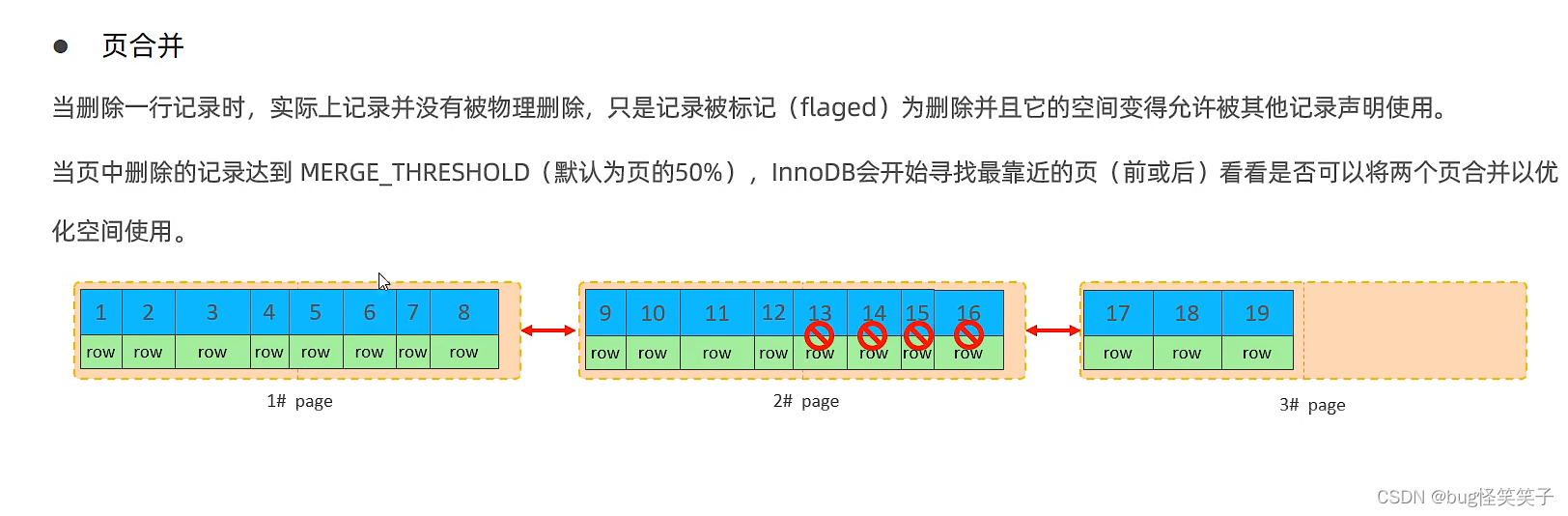
<2>页合并
当我们的数据页出现删除的情况,且删除数据后,剩余空间大于等于50%的数据页空间,mysql就会检查这个数据也两边的数据页,看是否能合并数据页。例如下图,我们发现3号页的空闲空间也超过了50%,所以可以合并。


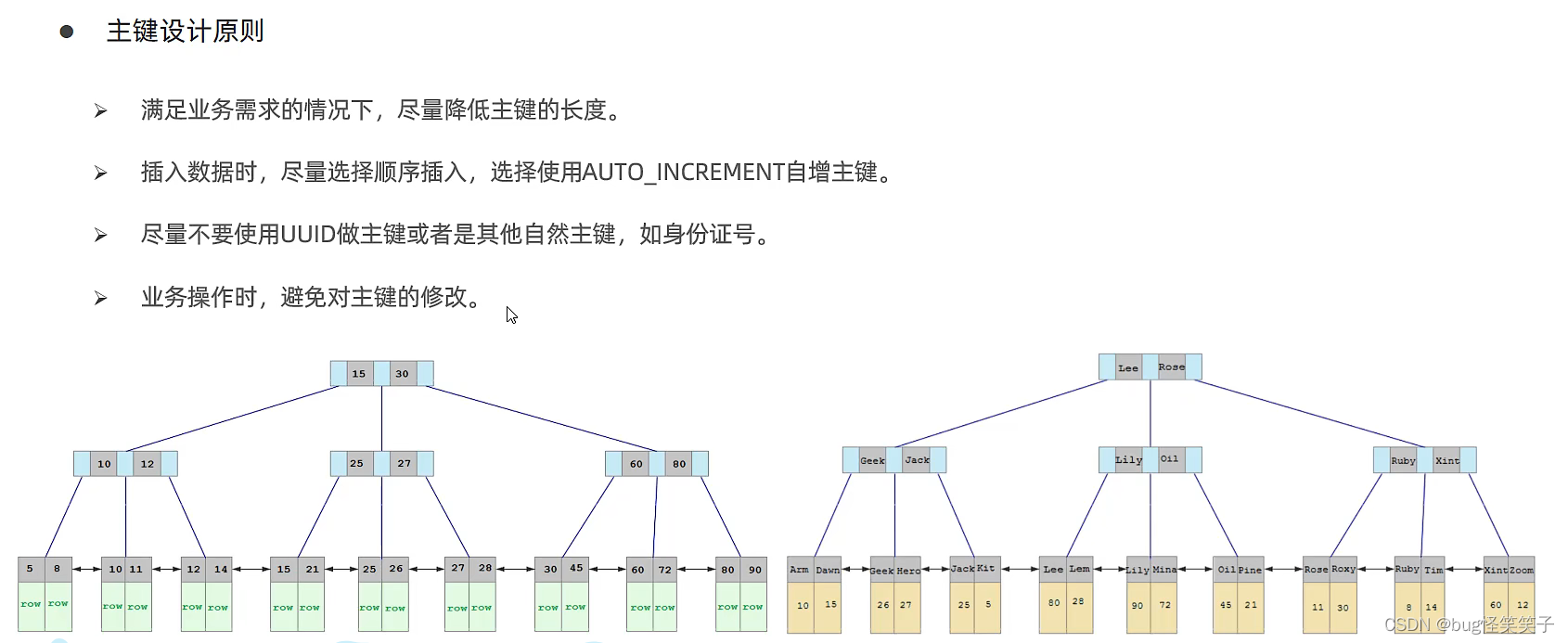
<3>设计原则

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









