




 本文深入讲解Java中的核心概念和技术,包括equals与==的区别、hashCode与equals的配合使用、集合类如HashSet的工作原理、Spring框架的Bean生命周期及自动装配机制、面向对象编程特性等。
本文深入讲解Java中的核心概念和技术,包括equals与==的区别、hashCode与equals的配合使用、集合类如HashSet的工作原理、Spring框架的Bean生命周期及自动装配机制、面向对象编程特性等。
一.==和equals()
1.==比较的是内存地址,它可以比较简单类型的数据也可以比较引用类型的数据。在equals()方法没重写前,它属于Object类的方法,内部其实也是==号,但是它的参数规定了他只能比较引用类型的数据。
2.再重写equals()之后我们将他它和==作比较的时候,就需要看equals()重写之后的代码逻辑卷。例String类里面的equals()就已经重写了,他比较的是两个字符串里面的每一个字符是否相等。它和==就已经是不一样的了。
前置知识点:set集合和list集合的基础和底层原理




hashset去重复:只要对象内容相同,hsah值就行同。

ArrayList原理 :
基于数组
创建长度为10的数组,没存入一个数据,size后移一位,当插入的位置与数组的长度相同就会自动扩容1.5倍,然后迁移数据到新的数组。
按索引查询快,增删慢。
主要是插入数据或者删除数据后,数组中的数据会迁移补齐空缺。
LinkedList底层原理:
基于双链表
增删相对较快,查询慢,对首尾的操作极快。可以作为队列和栈来使用。
Treeset底层原理:
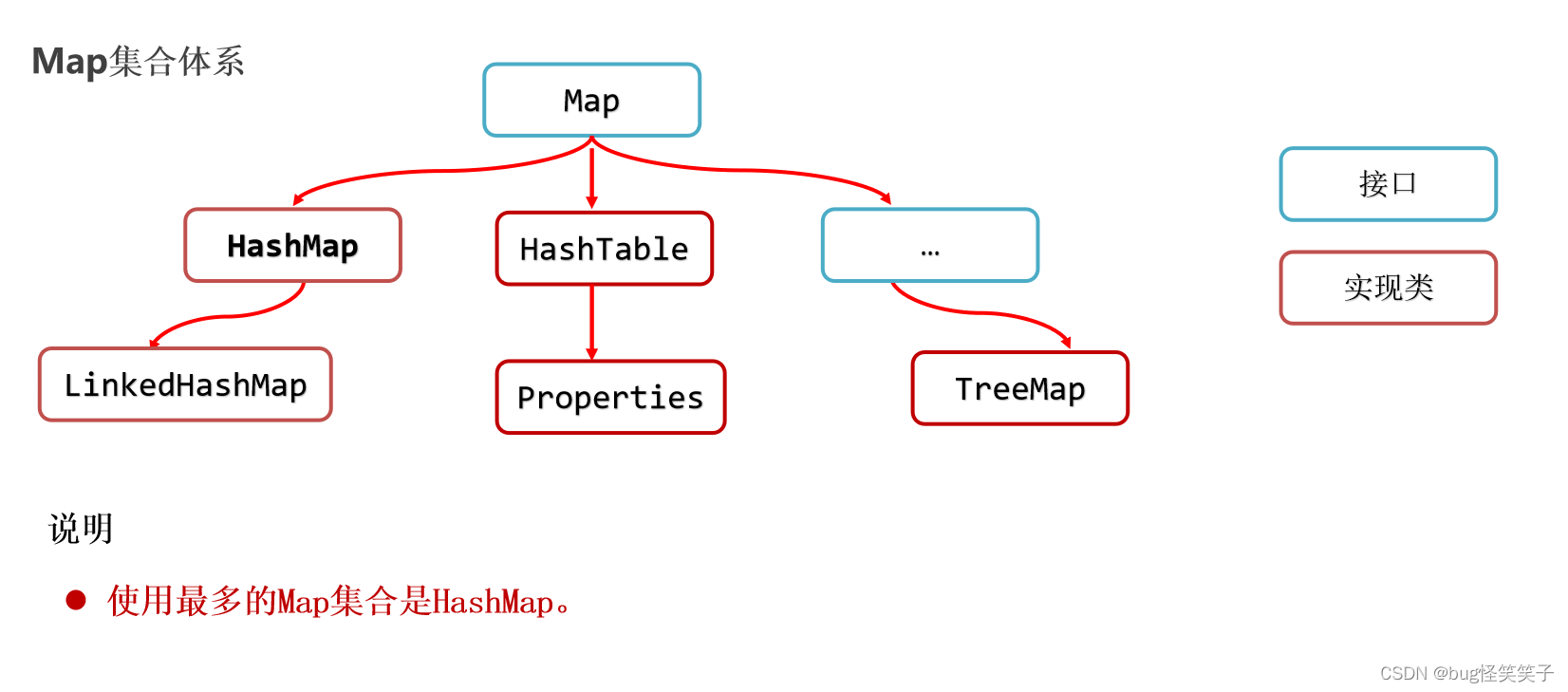
二.HashCode和equal()的区别
1.HashCode()的作用获取当前对象的哈希码也就是散列码。这个散列码的作用是获取当前对象在哈希表中的位置,以方便用索引快速找到它。它属于object类每个类都有这个方法。哈希码就像指纹一样独一无二,但是在java中不能完全做到。
所以就有:相同的对象哈希值一定相同。
哈希值相同,两个对象不一定是同一个对象。
哈希值不同,肯定是两个不同对象。
2.equals()重写前后差距很大,不多说了。
那么为什么重写HashCode()一定也要重写equal()方法呢?
举例子说明吧:很多时候只有两个都重写才能让我们的set集合正常工作也就是set的去重复原理。我们知道set集合很多集合是无序,无索引,不重复的。
如何做到不重复呢?就用到了重写的HashCode和equals(),我们知道HashSet集合底层原理是基于哈希算法的数组和链表加红黑树,一开始先创建了长度为16的数组,我们存数据时首先算hash值然后除以数组长度取余,确定存放位置,然后用equals()方法比较数组位置的链表上是否有相同属性的数据啊,没有就存。而且不重写Hashcode导致内容相同的不同对象出现在set集合,导致有重复。
3.两个对象比较是否相同通常想先用hashcode(),因比较起来容易。equals()逻辑多比较起来相对复杂。
三、重载和重写的区别
1、重载发生在一个类中,要求方法名必须相同,参数类型,个数,顺序可以不同,其次重载和返回值类型和修饰符无关,这两个变动,编译直接问报错。
2.重写发生在父子类之中,要求重写的方法方法名,参数列表必须相同。返回值类型小于等于父类抛出异常的范围小于等于父类,访问修饰符的权限大于等于父类,其次用private修饰的方法不能重写。
四、抽象类和接口的区别
1.两者都不实例化对象。抽象类里面既可以有抽象方法,也可以有写好的方法。其次抽象类的成员变量类型与普通的类一样多,而接口的成员变量只能是private static final 修饰的常量。
2.抽象类是先有子类再有父类,抽象类是把子类都有的方法提取出来做成抽象类,可以增加代码的复用性。抽象类和它的子类是is a的关系比如宝马是汽车,汽车是父类,宝马是子类。
3.接口和他的实现类更像是like a的关系。它更加偏向约束行为,比如飞机像小鸟。飞机和小鸟一样都有飞行的能力。
4.抽象类单继承,接口可以多实现。
五、Spring Bean的生命周期


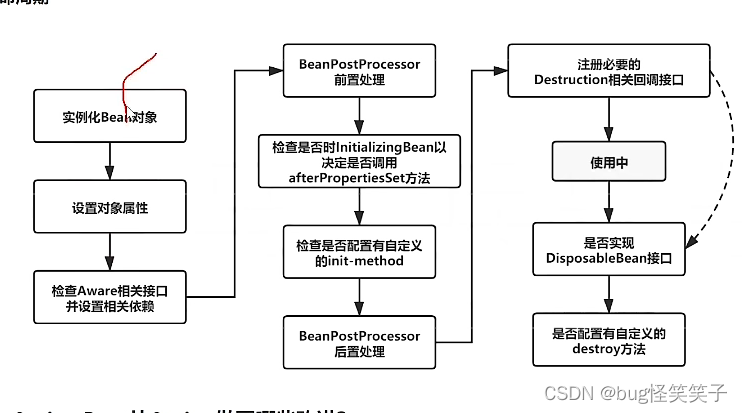
1.实例化bean:用反射的方式生成对象
2.填充bean的属性:用到了populateBean()方法
3.调用aware接口相关方法:调用invokeAwareMethod相关方法,完成对BeanName,BeanFactory,BeanClassLoader对象属性的设置。
4.调用BeanPostProcessor中的前置方法:使用较多的有(ApplicationContextPostProcessor,设置ApplicstionContext,Environment,ResourceLoader,EmbeddValueResolver等对象)
5.判断是否实现initializingBean接口,如果有,就调用afterProperties方法没有就不调用。
6.执行初始化方法
7.调用BeanPostProcessor的后置处理方法:springAOP就在此处实现的
8.使用bean
9.销毁:1;判断是否实现了DispoableBean来判断是否为单例bean
2;再调用destrorytMethod方法

六、Spring的事务
1.事物的概念其实是数据库的概念,spring对他进行了扩展,和一些方便程序员使用的方式。
2.spring的事务有两种,一个是编程式的,一个是申明式即使用@Tansaactional。一旦开启事务,事务里的sql就可以统一进行体交和回滚。
3.开启事务:在要开启事物的方法上加上@Transactional的注解,spring会基于该类产生一个代理对象,并将该代理对象作为Bean放入Spring的容器中。当使用代理对象的方法时,代理对象的逻辑如果发现方法上有@Transactional的注解,代理对象的逻辑就会把该方法默认提交设置为false。当执行出现异常时就会回滚,没有异常就正常执行。
spring事物的隔离级别:
1.默认级别
2.read uncommitted (未提交读)
3.read commited (提交读,不可重复读)
4.repeatable read (可重复度)
5. seralizable (可串行化)
七、事务传播机制
A 调用 B
1.REQUIRED(默认传播机制):如果A没有事务,B创建事务,如果A有事务,B就加入事务
2.REQUIRED_NEW(各管各的机制):A没有事务,B创建一个新事物,A有事务,B挂起事务,不加入A
3.SUPPORT(A怎样B怎样):A有事务,B就加入,A没有事务,就按非事务执行。
4.NOT_SUPPORT(不让有事务):非事物方式执行,A有事务B报错。
5. MANDATORY(必须开启事务):A有事务,B加入,A没有事务B抛异常

八、SpringMVC的执行过程
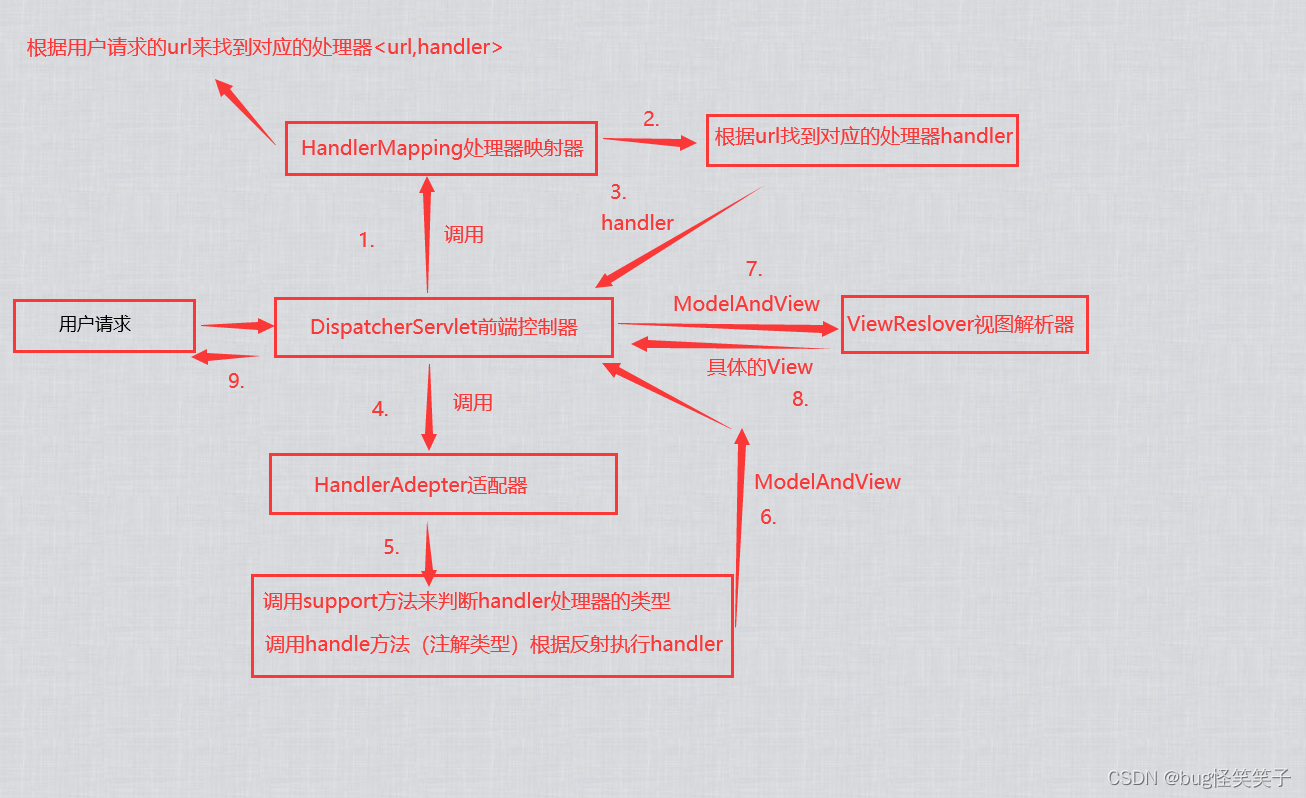
1.用户发数据到前端控制器DispatcherServlet。
2.DispatcherServlet收到请求后,调用HandlerMapping处理器映射器。
3.HndleMapping根据用户发来请求的Url,找到对应的handler处理器,生成处理器和处理器拦截器返回给DispatcherServlet。
4.DispatcherServlet调用HandlerAdpater适配器,适配器来首先调用Support方法来确定handler是什么类型的,举例如果是注解类型,调用handle方法使用反射执行handler。并返回给DispatcherServlet一个ModelAndView。
5.DispatcherServlet把ModelAndView给到ViewReslover试图处理器,然后ViewReslover解析后返回给.DispatcherServlet一个具体的View。
6.DispatcherServlet根据view渲染视图,然后响应用户请求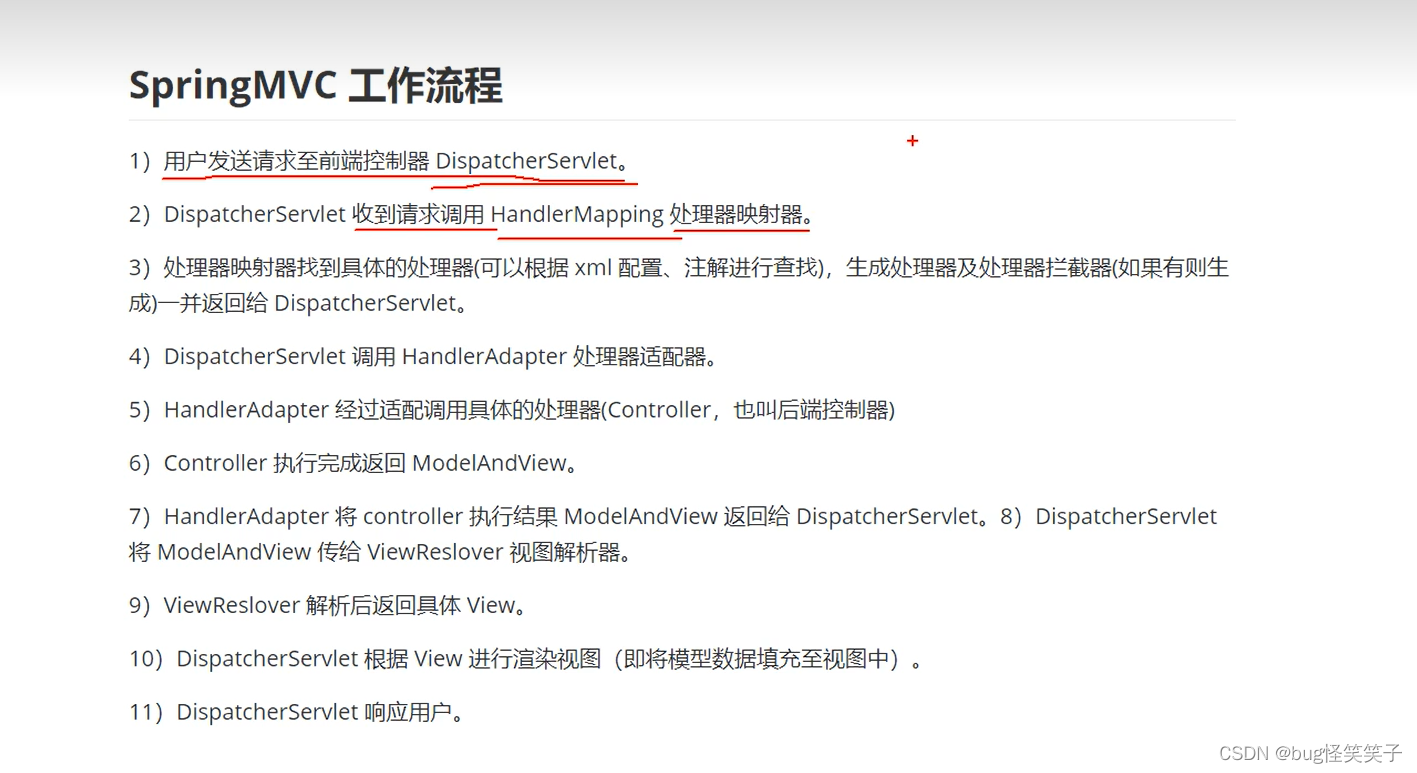

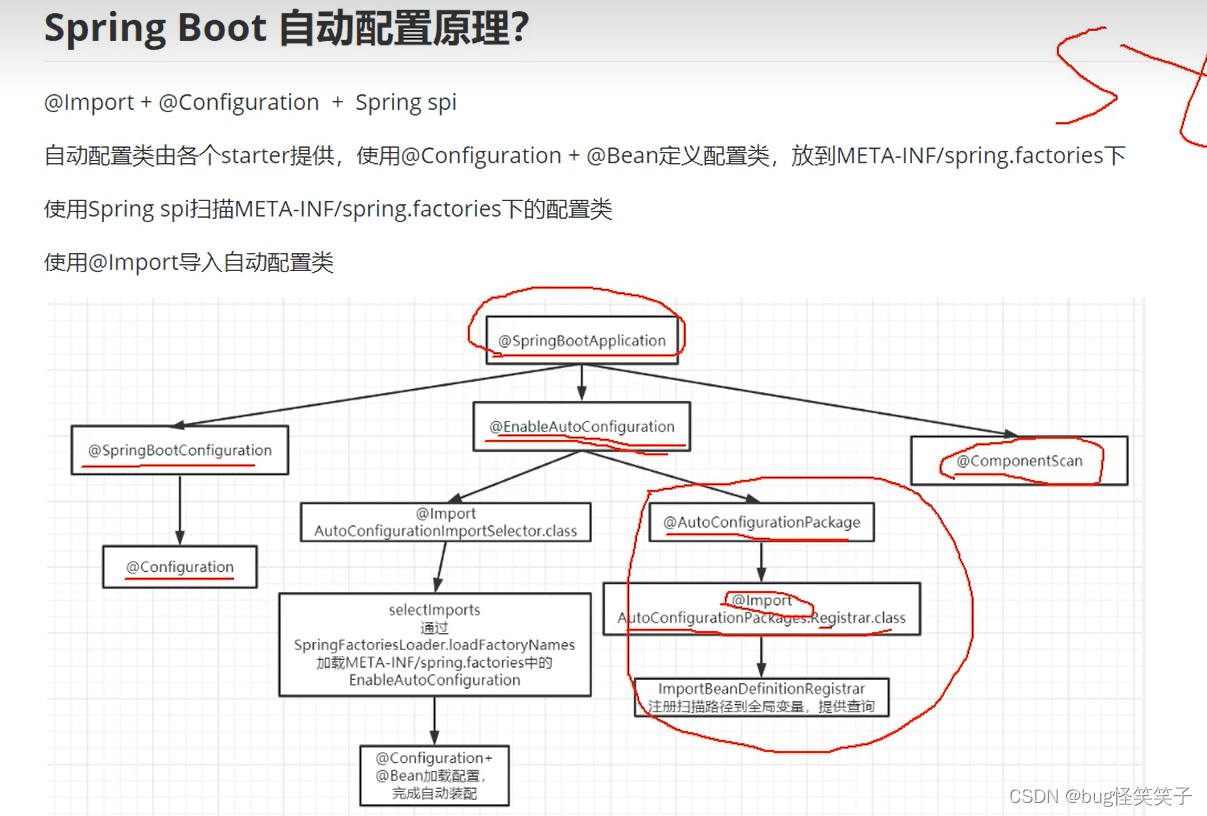
九.springboot的自动装配原理
首先,自动配置类由各个starter来提供,它使用@Configuration和@bean来定义配置类。并且把配置类的全路径名放进MEAT-INF/spring.factories里。自动配置的核心就是如何加载这些配置类。
在@SpringBootApplication下有一个@EnableAutoConfiguration,它里面用@Import导入了一个AutoConfigurationImportSelector.class,这个类里面有一个方法叫做selectImports,这个方法通过spring-spi的机制获取spring.factories里的全路径名,返回一个全是全限定名的字符串类型数组,spring扫描到这些类之后,会通过反射将这些类的对象装进ioc容器中。
十.starter机制
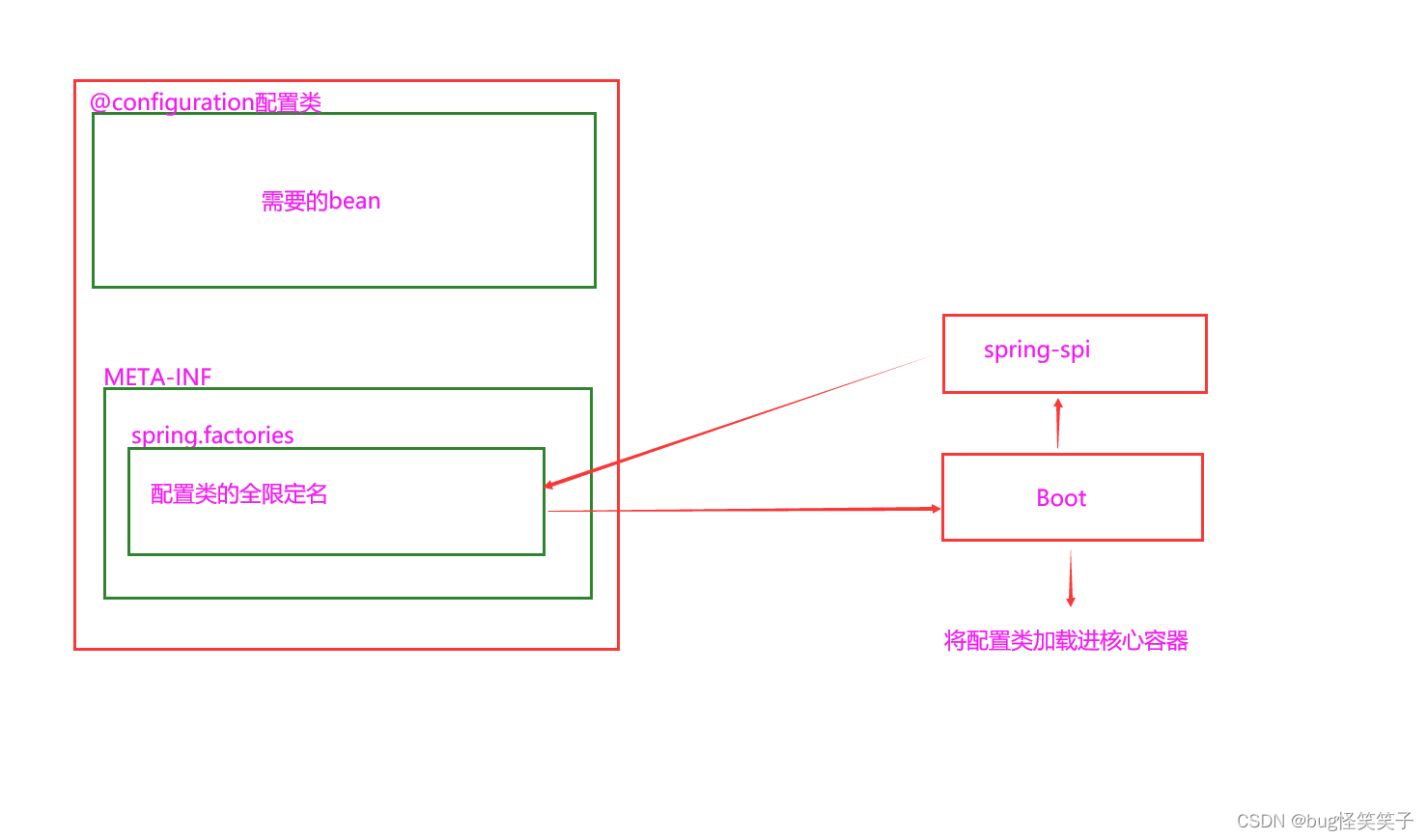
在ssm框架体系里,我们引入Mybatis框架时不仅要在pom文件里导入坐标,还需要定义需要的bean。
starter机制其实就是就是定义一个jar包,把上面的操作提前做好。在jar里写一个@Configuration配置类,把这些需要的bean定义在里面。在starter里面的META-INF/Spring.factories里面存了配置类的全限定名。最后springboot按照约定大于配置加载配置类(利用spring的spi机制来读取spring.factories文件获取配置类信息。)
开发者只需要把starter包导入pom就可以开始开发了。
十一.Aop
我们的系统通常有许多功能模块组合而成,每个模块都有自己负责的核心功能,但是通常我们的功能模块在完成自己的核心功能是通常还会做一些其他功能,比如打日志啊或者是捕获异常啊之类的。我们发现其实很多模块都会做这些相同的工作,这其实造成了代码的冗余。
用了Aop的思想之后就能解决这类问题。例如那些比较打日志功能之类的通用的功能,我们可以给他封装到一个切面里,需要使用得到模块绑定这个切面就可以自动使用里面的功能。Aop是一种无侵入式的功能强化机制,它使用了一种设计模式叫做动态代理。其实我们执行切面方法用到的对象不是,这个类本身的对象,而是他的代理对象。

十二.IOC
三个概念ioc核心容器,依赖注入(DI),控制反转
ioc是一个容器,本质是一个Map集合,spring把所有扫描到的类通过反射的方式把Bean放进这个核心容器中。我们需要用bean时候使用依赖注入来获取bean来使用。、
控制反转:我们在没有使用IOC之前,如果A类对象依赖B类的方法执行,就需要在B类中new一个
B类对象,控制权可以说是在A。而我们使用了IOC之后,我们不再主动new一个对象,当我们需要一个对象是,IOC会把实现准备好的B类对象给我们,此时不难看出控制权已经全权交给了第三方的IOC容器。
依赖注入:其实就是我们实现ioc的手段,我们使用依赖注入的方式,把ioc里的本bean给到需要的类。
十三.什么时面向对象?面向对象有哪些特征?
我们可以和面向过程比较着说。比如人洗衣服这件事。
如果是面向过程是实现的话,就会把这件事拆分成几个步骤,每个步骤就是一个函数,就是写人开洗衣机,放衣服,加洗衣粉,烘干对应的函数,直截了当比较高效。
如果是面向对象来说的话,是会把这件事拆分成人和洗衣机的对象,人类里封装放衣服,放洗衣粉的方法,在洗衣机类里封装开洗衣机,烘干的方法。
虽然面向过程更高效,但是面向对象更利于代码的复用性,可移植性。
面向对象的三大特征:
1.封装
封装的实现是,在一个类里,有些方法可以给外部调用,但是不展示方法的内部细节。就比如我们买电脑,我们只知道怎末用,不需要知道里面是怎么实现的。增加了代码的复用性。
2.继承
把子类里共有的重复的方法,都封装到父类里,可以减少冗余代码。父类里面有的方法,子类可以直接调用,子类也可以做自己的扩展。增加了代码的复用性减少冗余代码。
3.多态
同类型的对象在执行同一个行为是会执行不同的特征。比如父类是动物类,它的子类有狗,有鱼,利用多态的方式创建对象后他们执行运动的方法,一个是跑,一个是游泳。增加了代码的复用性和可移植性和健壮性。
十四、jvm
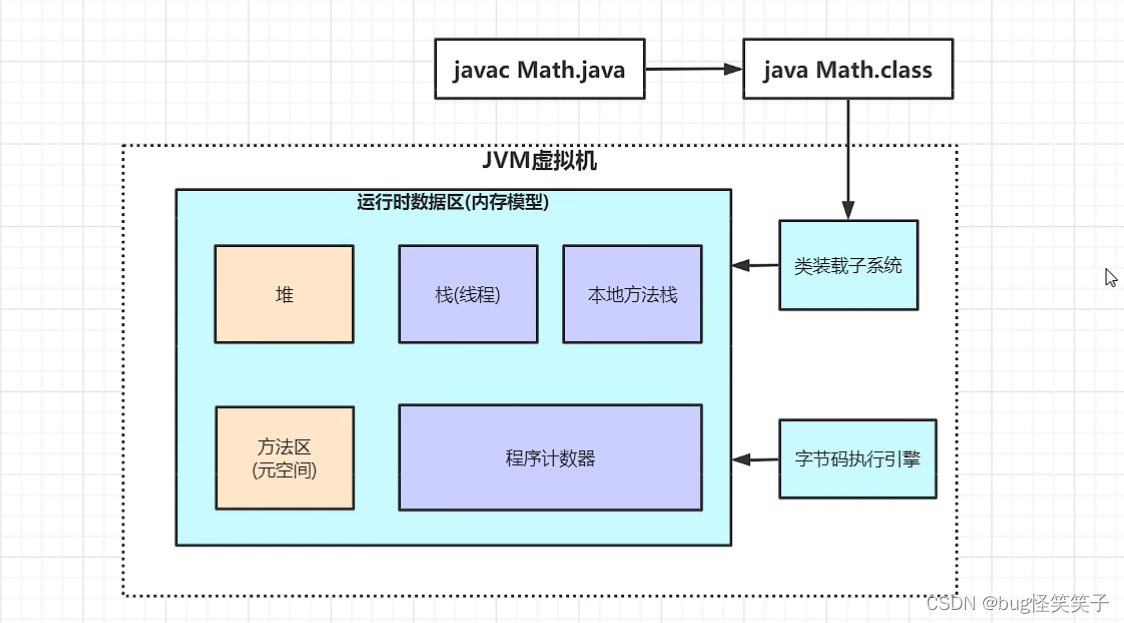
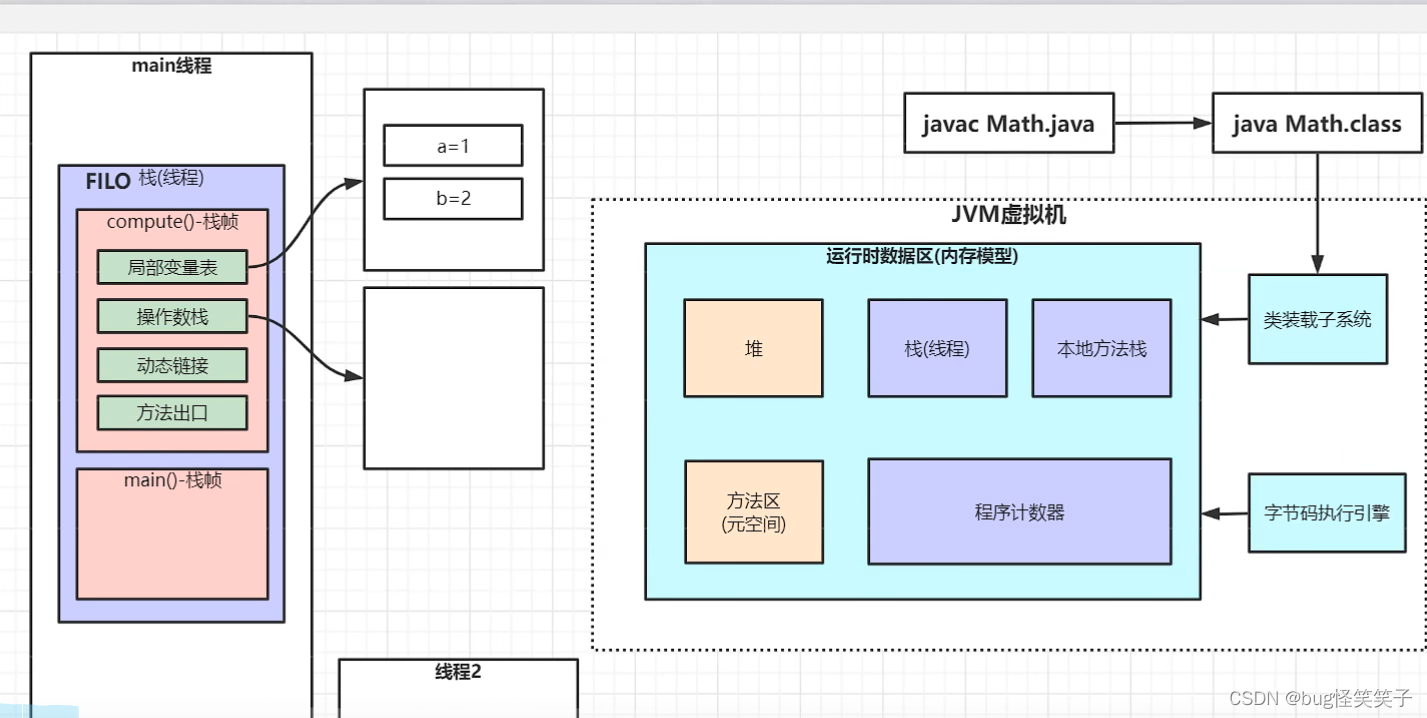
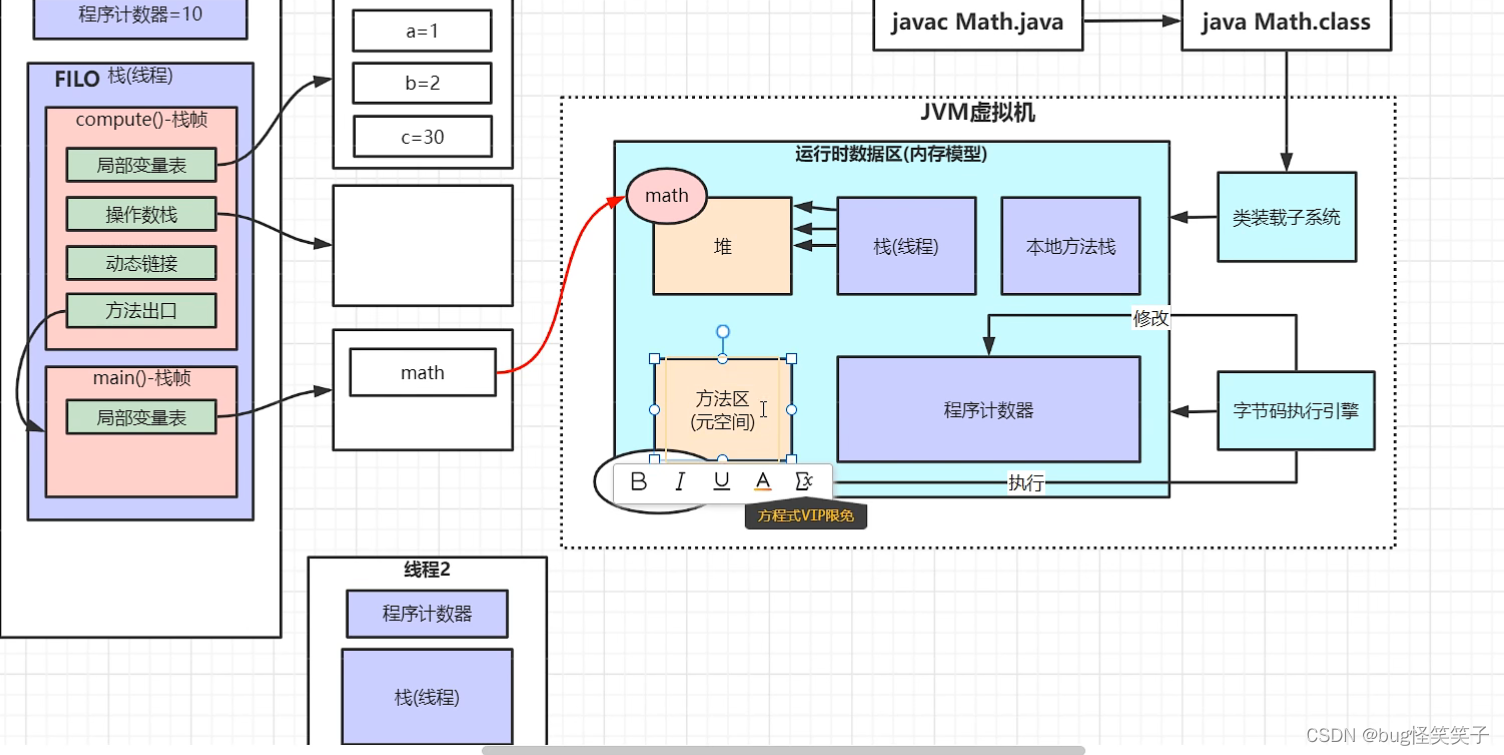
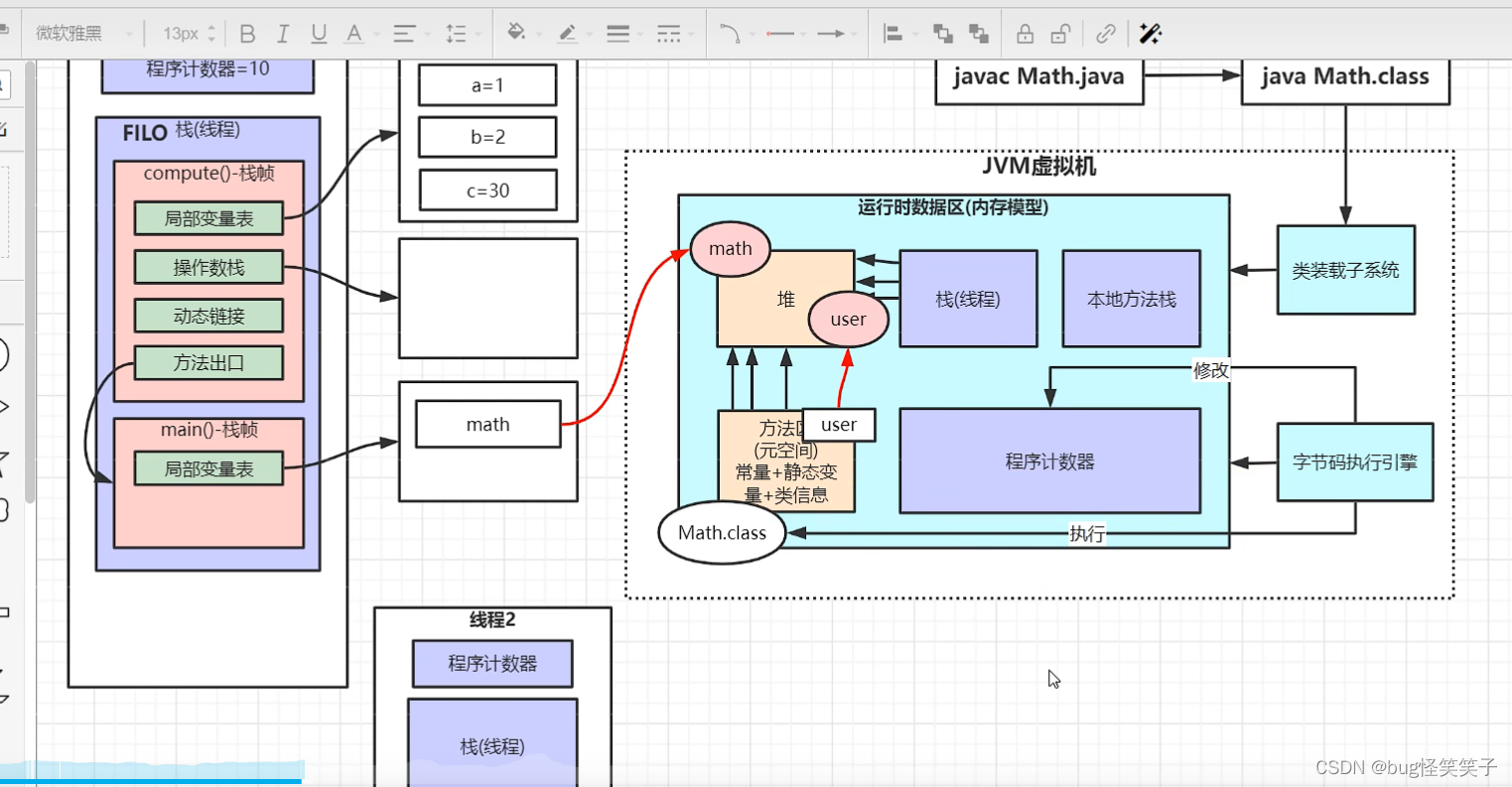
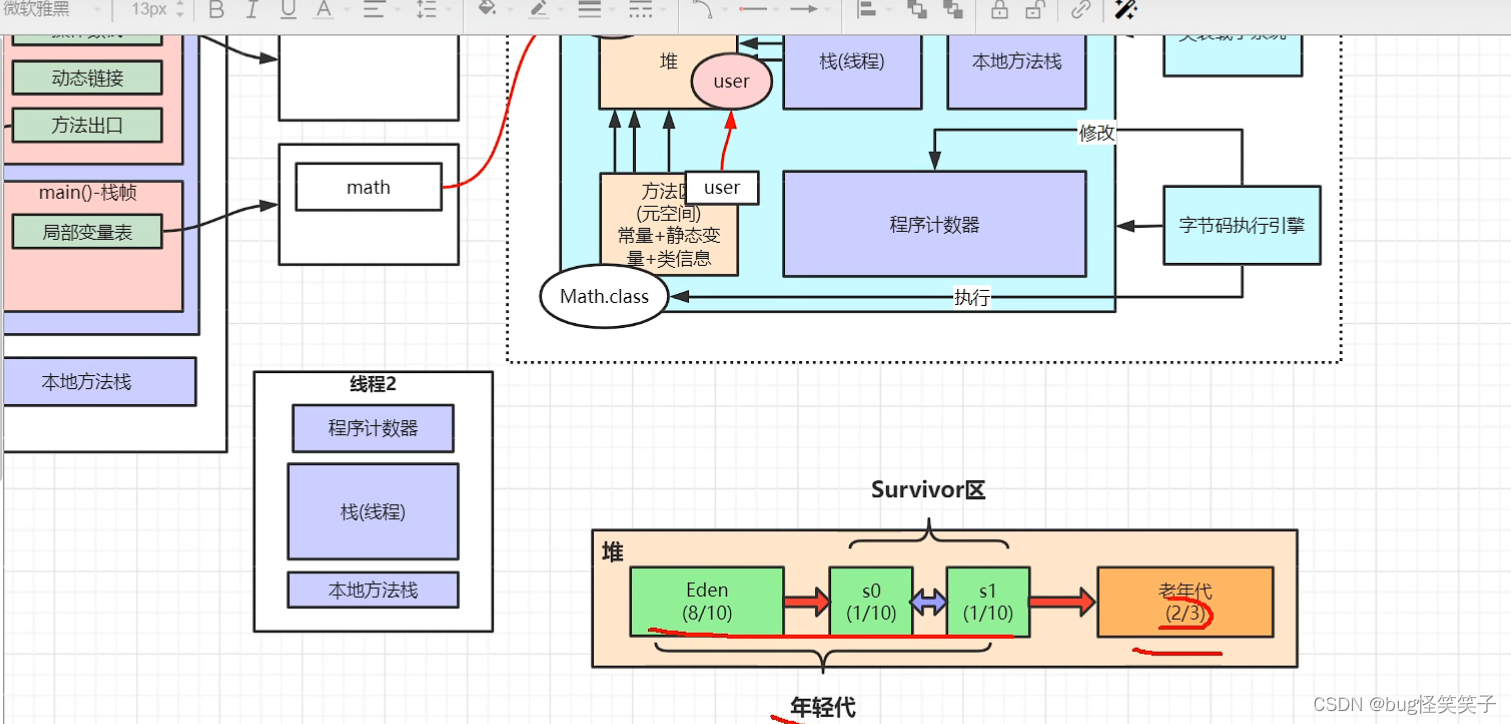
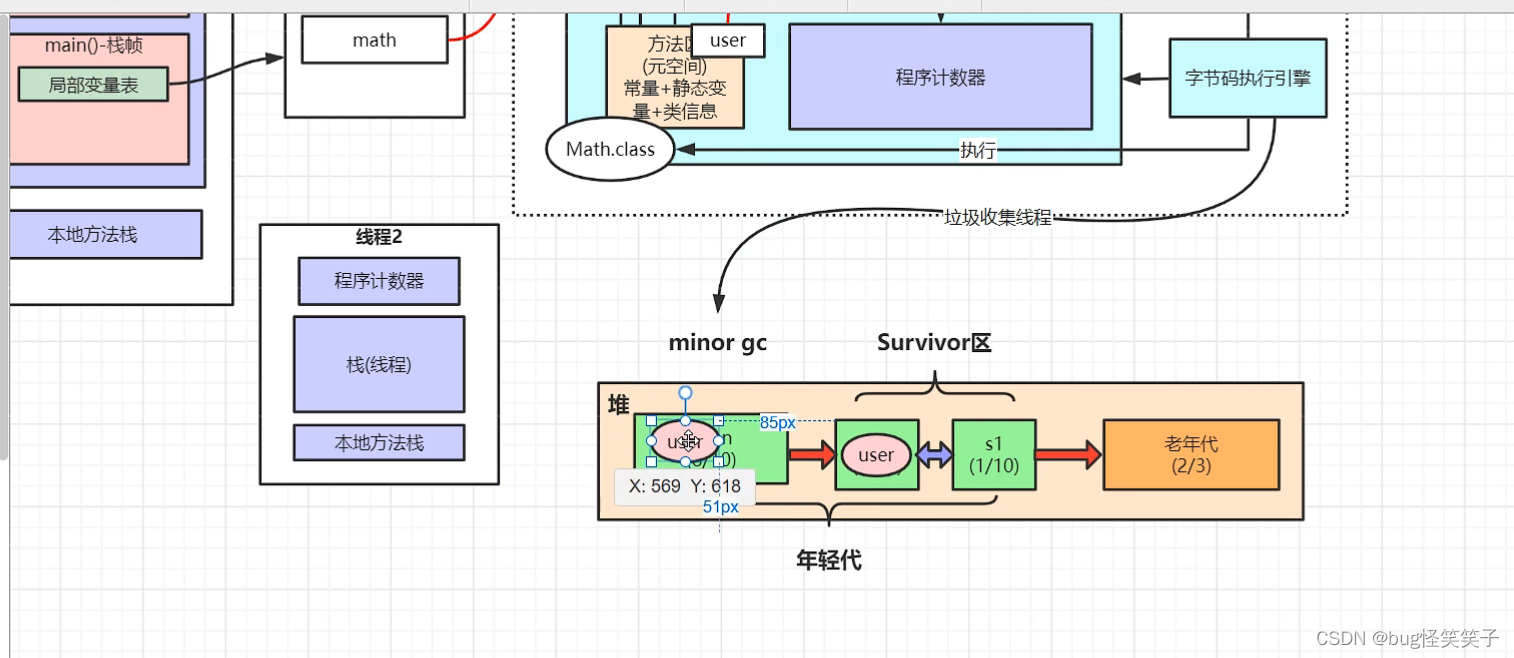
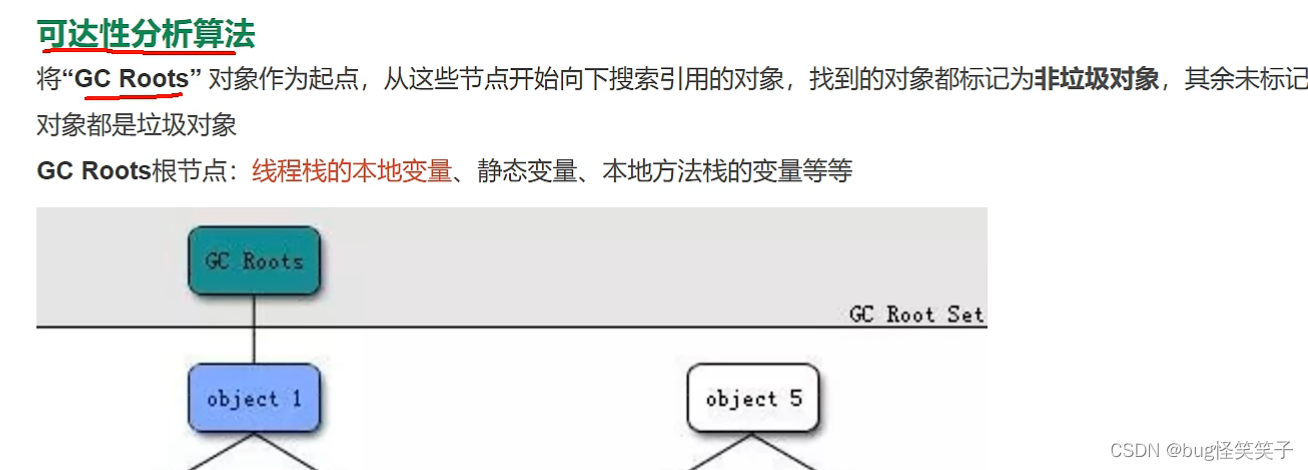
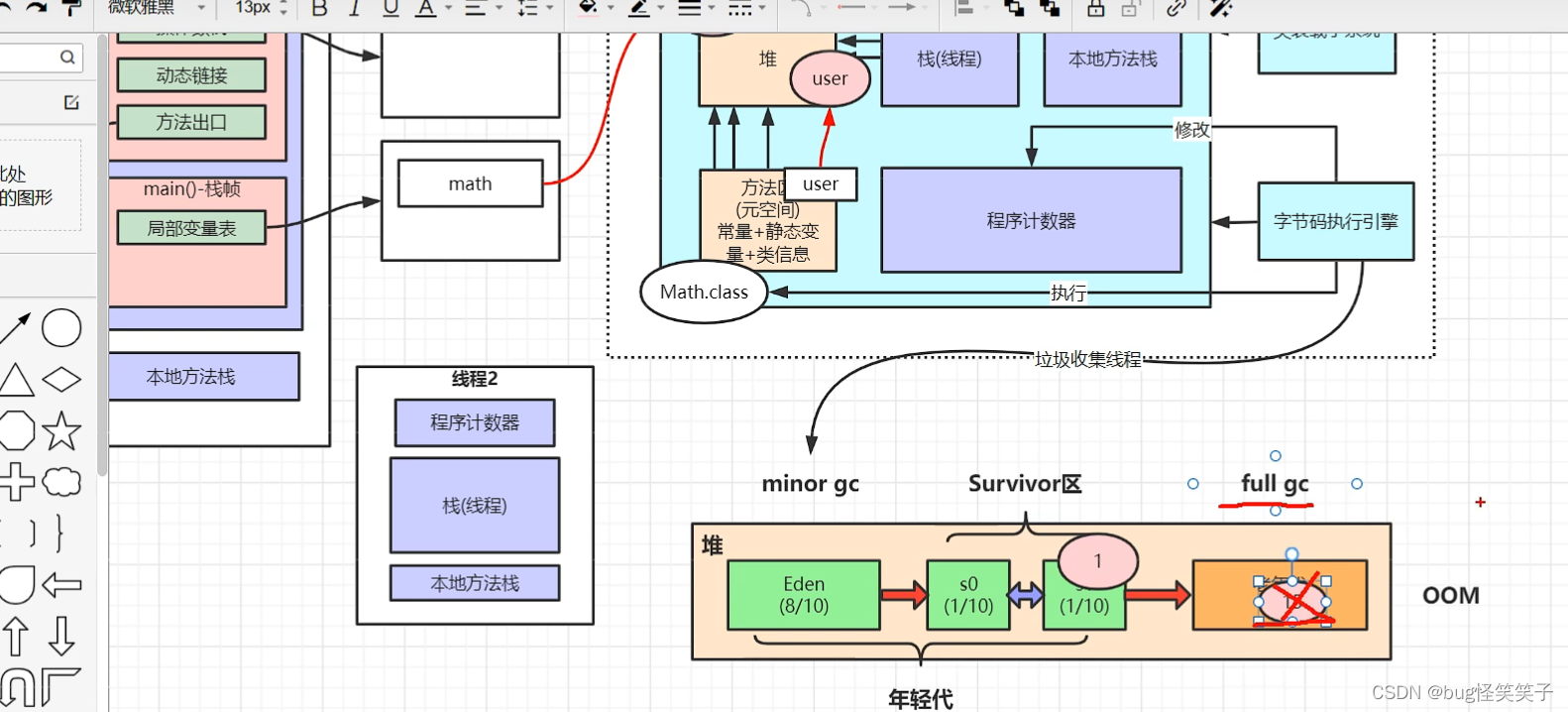
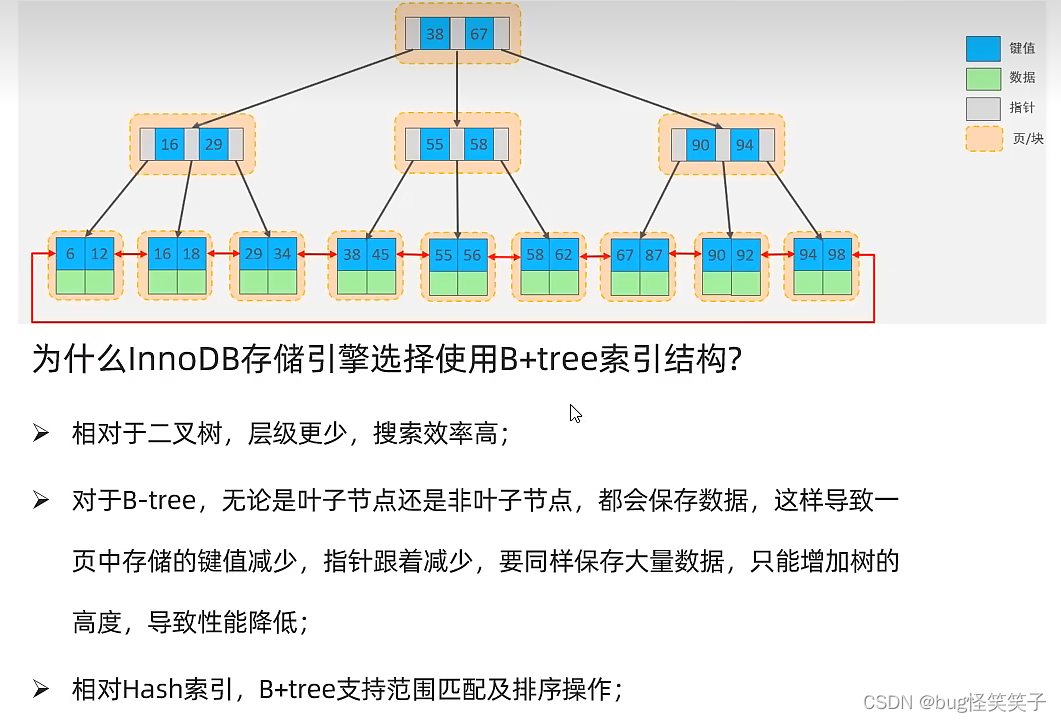
十五、mysql为啥使用B+Tree

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









