







利用Python获取歌曲评论
一、开始前所需要的内容
首先就是得到两个东西,一个是用户的id,一个是所要搜寻评论对应的歌曲的id。
1.1 用户的id获取
用户的id,就是类似于这样的
https://music.163.com/#/user/home?id=XXXXX
就是去用户界面,找到这个 XXXXX
1.2 歌曲的id获取
1.2.1 只有一首歌
如果你只要爬取一首歌的id,那么也一样,去该歌曲主页,得到这个 XXXXX
例如:
https://music.163.com/#/song?id=XXXXX
然后复制 2.1 的代码,并运行。
将得到的用户ID,歌曲ID,依次输入。
等待运行完毕。
1.2.2 有很多首歌曲
如果你要爬取很多歌曲,例如你想知道 她 喜欢的歌单中,评论了什么。那么就要动用批量手段了。
1.2.2.1 通过歌单div获取
当你面对听歌排行的时候,你想知道最近一周听歌记录或者历史听歌记录 中, 她 是否评论了。
这个时候,不要犹豫,直接就是按下F12,找到这个东西 class="j-flag"
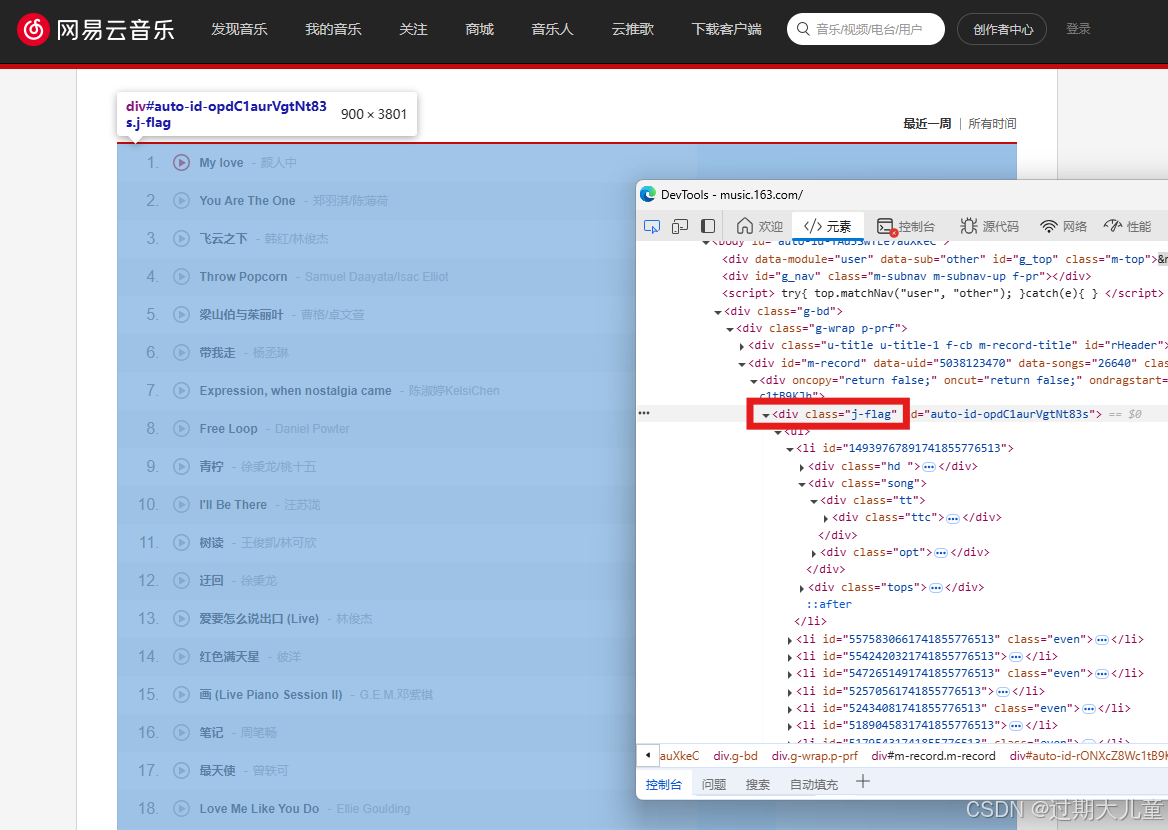
然后,右键,复制,复制元素。
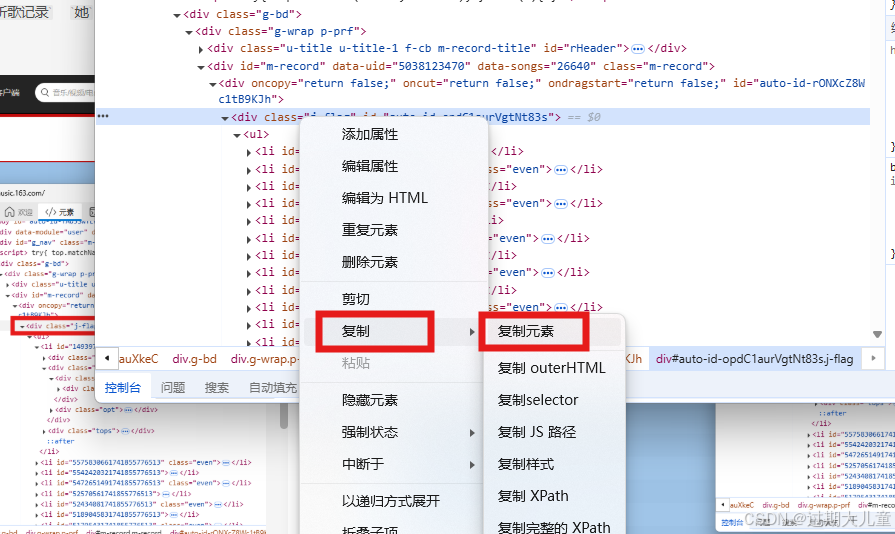
然后在你的目录下建立两个东西,一个是文件 music.html ,另一个是 python 文件。
在div中复制的内容,粘贴到 music.html 的body中,详情见 2.2.1
然后复制 2.2.1 的 python 代码,并运行。
将得到的用户ID输入。
等待运行完毕。
你的项目文件应该有两个东西,一个是
music.html另一个是python文件
1.2.2.2 通过歌单js获取
通过js获取的就是可以直接解析出歌单的歌曲ID的,通过访问相关接口,得到js数据,然后将js保存下来,复制到你的项目之下,运行代码就行。
接口为 https://music.163.com/api/playlist/detail?id={歌单ID}
在浏览器中访问接口,将接口返回的js数据右键保存下来,你可以先保存桌面,然后再将文件移动到你的项目文件目录下。一般默认为 detail.json ,不要改名字,代码中用得到这个名字。
然后复制 2.2.2 的代码,并运行。
将得到的用户ID输入。
等待运行完毕。
你的项目文件应该有两个东西,一个是
detail.json另一个是python文件
1.2.2.3 通过歌单号获取
当前两种方法都没用的时候,就可以放大招了。直接打电话给 她 问。
那肯定是不行的啦!!!
舔狗有舔狗的原则!!!
暗念有暗念的秘密!!!
绝不可以给 她 徒增烦恼!!!
上方法!!!
也是一样,先要知道歌单号,有了歌单号就好解决了。就是类似于这样的:
https://music.163.com/api/playlist/detail?id={歌单ID}
直接复制 2.2.3 代码,并运行。
将得到的用户ID,歌单ID输入。
等待运行完毕。
二、代码列表
2.1 只有一首歌曲,就像是唯一的定义
import math
import json
import requests
from time import sleep
comment = []
def getHTMLText(url):
kv = {"user-agent": "Mozilla/5.0"}
r = requests.get(url, headers=kv)
r.raise_for_status()
html = r.text
return html
def getpag(url, music_id):
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100)
html = getHTMLText(new_url)
json_dict = json.loads(html) # 利用json方法把json类型转成dict
return json_dict["total"] # 评论数
def clib(userid, music_id):
url = "https://music.163.com/api/v1/resource/comments/R_SO_4_" + music_id
print("开始探寻 "+music_id + " 的内容")
pag = math.ceil(getpag(url, music_id)/100) # 页面数
print("共 "+str(pag)+" 页")
for i in range(pag + 1): # 爬取页面数
if i%100 == 49:
sleep(5)
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100 * i)
# print(new_url)
html = getHTMLText(new_url)
json_dict = json.loads(html) # 利用json方法把json类型转成dict
comments = json_dict['comments']
for item in comments:
try:
if item['user']['userId'] in userid : # 用户id
comment.append([music_id, item['user']['nickname'], item['content']])
# print(item['user']['nickname'] + "评论了:" + item['content'])
except:
print("特殊字符打印失败!!!")
if comment:
print(" 昵称:" + comment[1] + ",在音乐id:" + comment[0] + " 评论了:" + comment[2] + "\n")
else:
print("什么,竟然还没评论这首歌曲!!!")
def main():
userid = input("用户id")
music_id = input("歌曲id")
clib(userid, music_id)
if __name__ == '__main__':
main()
2.2 歌单好几首歌,就像是自己的一切
2.2.1 通过div获取的代码
你的项目文件应该有两个东西,一个是
music.html另一个是python文件
music.html 代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--在这里粘贴你复制的内容-->
<!--就是你 div 中复制的内容-->
</body>
</html>
python文件代码
import math
import json
import requests
from time import sleep
from bs4 import BeautifulSoup
import re
errorlist = []
commentlist = []
def openfile():
with open('music.html', 'r', encoding='utf-8') as file:
page_source = file.read()
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(page_source, 'html.parser')
# 查找所有包含歌曲信息的 li 标签
songs = soup.find_all('li')
musicids = []
# 提取歌曲 ID、歌曲名称和歌手信息
for song in songs:
# 提取歌曲名称
song_name_tag = song.find('b')
# 提取歌手名称
artist_name_tag = song.find('a', class_='s-fc8')
# 提取歌曲 ID,正则匹配 href 中的 id 值
song_id_tag = song.find('a', href=re.compile(r'/song\?id=\d+'))
if song_name_tag and artist_name_tag and song_id_tag:
song_name = song_name_tag.text.strip()
artist_name = artist_name_tag.text.strip()
# 从 href 属性中提取歌曲 ID
song_id = re.search(r'id=(\d+)', song_id_tag['href']).group(1)
musicids.append(song_id)
print(f"歌曲ID: {song_id} - 歌曲: {song_name} - 歌手: {artist_name}")
print("所有id")
return musicids
def getHTMLText(url):
kv = {"user-agent": "Mozilla/5.0"}
r = requests.get(url, headers=kv)
r.raise_for_status()
html = r.text
return html
def fillList(music_id, url, commentlist, pag, userid):
for i in range(pag + 1): # 爬取页面数
bk = -1
if i % 100 == 49:
sleep(5)
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100 * i)
# print(new_url)
try:
html = getHTMLText(new_url)
except:
errorlist.append(music_id)
print(f"准备跳过 {music_id} 了")
bk = 1
if bk == 1:
break
json_dict = json.loads(html) # 利用json方法把json类型转成dict
comments = json_dict['comments']
for item in comments:
try:
if item['user']['userId'] in userid: # 用户id
commentlist.append([music_id, item['user']['nickname'], item['content']])
# print(item['user']['nickname'] + "评论了:" + item['content'])
except:
print("特殊字符打印失败!!!")
if commentlist:
print(commentlist)
save(commentlist, path="全部的评论.txt")
def save(commentlist, path):
with open(path, 'a', encoding='utf-8') as f:
for comment in commentlist:
# f.write(comment[0] + "评论了: " + comment[1] + "\n") #comment[0]是用户名 comment[1]是用户评论
f.write("音乐id:" + comment[0] + " 昵称:" + comment[1] + " 评论内容:" + comment[2] + "\n")
f.close()
print(f"数据保存成功")
def getpag(url, music_id):
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100)
html = getHTMLText(new_url)
json_dict = json.loads(html) # 利用json方法把json类型转成dict
return json_dict["total"] # 评论数
def clib(userid, music_ids):
url = "https://music.163.com/api/v1/resource/comments/R_SO_4_"
i = 1
for music_id in music_ids:
if i % 4 == 0:
sleep(20)
i += 1
print("开始探寻 " + music_id + " 的内容")
pag = math.ceil(getpag(url, music_id) / 100) # 页面数
print("共 " + str(pag) + " 页")
fillList(music_id, url, commentlist, pag, userid)
def main():
userid = input("用户id")
music_ids = openfile()
clib(userid, music_ids)
while errorlist:
music_ids = errorlist
errorlist.clear()
clib(userid,music_ids)
print("\n\n\n####################################")
print("程序运行结束,希望找到了你想要的东西。♥")
if __name__ == '__main__':
main()
2.2.2 通过js获取的代码
你的项目文件应该有两个东西,一个是
detail.json另一个是python文件
detail.json是你复制js时候,默认的名字,如果改了的话,下面代码中也要改with open('detail.json', 'r', encoding='utf-8') as file:
python文件代码
import json
import math
from time import sleep
import requests
datalist = []
errorlist = []
commentlist = []
def getHTMLText(url):
kv = {"user-agent": "Mozilla/5.0"}
r = requests.get(url, headers=kv)
r.raise_for_status()
return r.text
def findFromJs():
with open('detail.json', 'r', encoding='utf-8') as file:
json_dict = json.load(file)
comments = json_dict['result']['tracks']
for item in comments:
try:
datalist.append(str(item['id']))
except:
print("特殊字符打印失败!!!")
return datalist
def fillList(music_id, url, commentlist, pag, userid):
for i in range(pag + 1): # 爬取页面数
bk = -1
if i%100 == 49:
sleep(5)
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100 * i)
# print(new_url)
try:
html = getHTMLText(new_url)
except:
errorlist.append(music_id)
print(f"准备跳过 {music_id} 了")
bk = 1
if bk == 1:
break
json_dict = json.loads(html) # 利用json方法把json类型转成dict
comments = json_dict['comments']
for item in comments:
try:
if item['user']['userId'] in userid : # 用户id
commentlist.append([music_id, item['user']['nickname'], item['content']])
# print(item['user']['nickname'] + "评论了:" + item['content'])
except:
print("特殊字符打印失败!!!")
print(commentlist)
save(commentlist, path="全部的评论.txt")
def save(commentlist, path):
with open(path, 'a', encoding='utf-8') as f:
for comment in commentlist:
# f.write(comment[0] + "评论了: " + comment[1] + "\n") #comment[0]是用户名 comment[1]是用户评论
f.write("音乐id:"+comment[0] +" 昵称:"+comment[1]+" 评论内容:"+comment[2]+ "\n")
f.close()
print("数据保存成功")
def getpag(url, music_id):
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100)
html = getHTMLText(new_url)
json_dict = json.loads(html) # 利用json方法把json类型转成dict
return json_dict["total"] # 评论数
def clib(userid, music_ids):
url = "https://music.163.com/api/v1/resource/comments/R_SO_4_"
i = 1
for music_id in music_ids:
if i % 4 == 0 :
sleep(20)
i+=1
print("开始探寻 "+music_id + " 的内容")
pag = math.ceil(getpag(url, music_id)/100) # 页面数
print("共 "+str(pag)+" 页")
fillList(music_id, url, commentlist, pag, userid)
def main():
userid = input("用户id")
music_ids = findFromJs()
clib(userid, music_ids)
while errorlist:
music_ids = errorlist
errorlist.clear()
clib(userid,music_ids)
print("\n\n\n####################################")
print("程序运行结束,希望找到了你想要的东西。♥")
if __name__ == '__main__':
main()
2.2.3 通过歌单号获取的代码
import json
import math
import re
from time import sleep
import requests
datalist = []
errorlist = []
commentlist = []
def getHTMLText(url):
kv = {"user-agent": "Mozilla/5.0"}
r = requests.get(url, headers=kv)
r.raise_for_status()
return r.text
def findByPlaylistId(playlist_id):
if not playlist_id.isdigit():
print("歌单ID必须为数字")
return
api_urls = [
"https://meting.qjqq.cn/?type=playlist&id=",
"https://api.injahow.cn/meting/?type=playlist&id=",
"https://meting-api.mnchen.cn/?type=playlist&id=",
"https://meting-api.mlj-dragon.cn/meting/?type=playlist&id="
]
selected_api = None
data = None
music_ids = []
for api_url in api_urls:
try:
new_url = api_url + playlist_id
response = requests.get(f"{new_url}", timeout=10)
response.raise_for_status()
data = response.json()
selected_api = new_url
if 'error' in data:
error = data.get("error", "")
print("出错了...")
print(f"错误详细:{error}")
return
break
except requests.exceptions.RequestException as e:
print(f"API {api_url} 请求失败:{e}")
continue
if not data:
print("所有API都无法获取数据")
return None
print(f"Meting API: {selected_api}")
total_songs = len(data)
print(f"歌单共有 {total_songs} 首歌曲")
for idx, item in enumerate(data, start=1):
url_id = re.search(r'\d+', item['url']).group()
music_ids.append(url_id)
return music_ids
def fillList(music_id, url, commentlist, pag, userid):
for i in range(pag + 1): # 爬取页面数
bk = -1
if i % 100 == 49:
sleep(5)
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100 * i)
# print(new_url)
try:
html = getHTMLText(new_url)
except:
errorlist.append(music_id)
print(f"准备跳过 {music_id} 了")
bk = 1
if bk == 1:
break
json_dict = json.loads(html) # 利用json方法把json类型转成dict
comments = json_dict['comments']
for item in comments:
try:
if item['user']['userId'] in userid: # 用户id
commentlist.append([music_id, item['user']['nickname'], item['content']])
# print(item['user']['nickname'] + "评论了:" + item['content'])
except:
print("特殊字符打印失败!!!")
print(commentlist)
save(commentlist, path="全部的评论.txt")
def save(commentlist, path):
with open(path, 'a', encoding='utf-8') as f:
for comment in commentlist:
# f.write(comment[0] + "评论了: " + comment[1] + "\n") #comment[0]是用户名 comment[1]是用户评论
f.write("音乐id:" + comment[0] + " 昵称:" + comment[1] + " 评论内容:" + comment[2] + "\n")
f.close()
print("数据保存成功")
def getpag(url, music_id):
new_url = url + "{0}?limit=100&offset={1}".format(music_id, 100)
html = getHTMLText(new_url)
json_dict = json.loads(html) # 利用json方法把json类型转成dict
return json_dict["total"] # 评论数
def clib(userid, music_ids):
url = "https://music.163.com/api/v1/resource/comments/R_SO_4_"
i = 1
for music_id in music_ids:
if i % 4 == 0:
sleep(20)
i += 1
print("开始探寻 " + music_id + " 的内容")
pag = math.ceil(getpag(url, music_id) / 100) # 页面数
print("共 " + str(pag) + " 页")
fillList(music_id, url, commentlist, pag, userid)
def main():
userid = input("用户id")
playlist_id = input("歌单ID:")
music_ids = findByPlaylistId(playlist_id)
clib(userid, music_ids)
while errorlist:
music_ids = errorlist
errorlist.clear()
clib(userid, music_ids)
print("\n\n\n####################################")
print("程序运行结束,希望找到了你想要的东西。♥")
if __name__ == '__main__':
main()
三、总结
上述文章的几种方法,有时候可以得到你要的内容,有时候得不到。
就像人生一样,处处充满了不确定性,得到与得不到的强求不了。
所以亲爱的你,如果找不到评论,不要强求。就当打发时间了,不要上头了。
如果很想它,就给它发个消息吧。
是风就该自由,要什么归宿呢?来去皆是自由风,该相逢时终相逢!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









